文章目錄
- 1.完整的容器分類法
- 2.填充容器
- 復制同一個物件參考來填充容器
- 一種Generator解決方案
- Map生成器
- 使用Abstract類
- 3.Collection的功能方法
- 4.可選操作
- 5.List的功能方法
- 6.Set和存盤順序
- 型別
- 從輸出看出
- SortedSet
- 7.佇列
- 優先級佇列
- 雙向佇列
- 8.理解Map
- 標準的Java類別庫中包含了Map的幾種基本實作,包括:
- 實作Map介面
- SortedMap
- LinkedHashMap
- 9.散列與散列碼
- 為速度而散列
- 覆寫hashCode()
- 10.選擇介面的不同實作
- 例如List介面
- Set介面
- 對List的選擇
- 對Set的選擇
- 對Map的選擇
- 11.實用方法
- List的排序和查詢
- 設定Collection或Map為不可修改
- Collection或Map的同步控制
- 12.持有參考
- 13.Java 1.0/1.1 的容器
- Vector和Enumeration

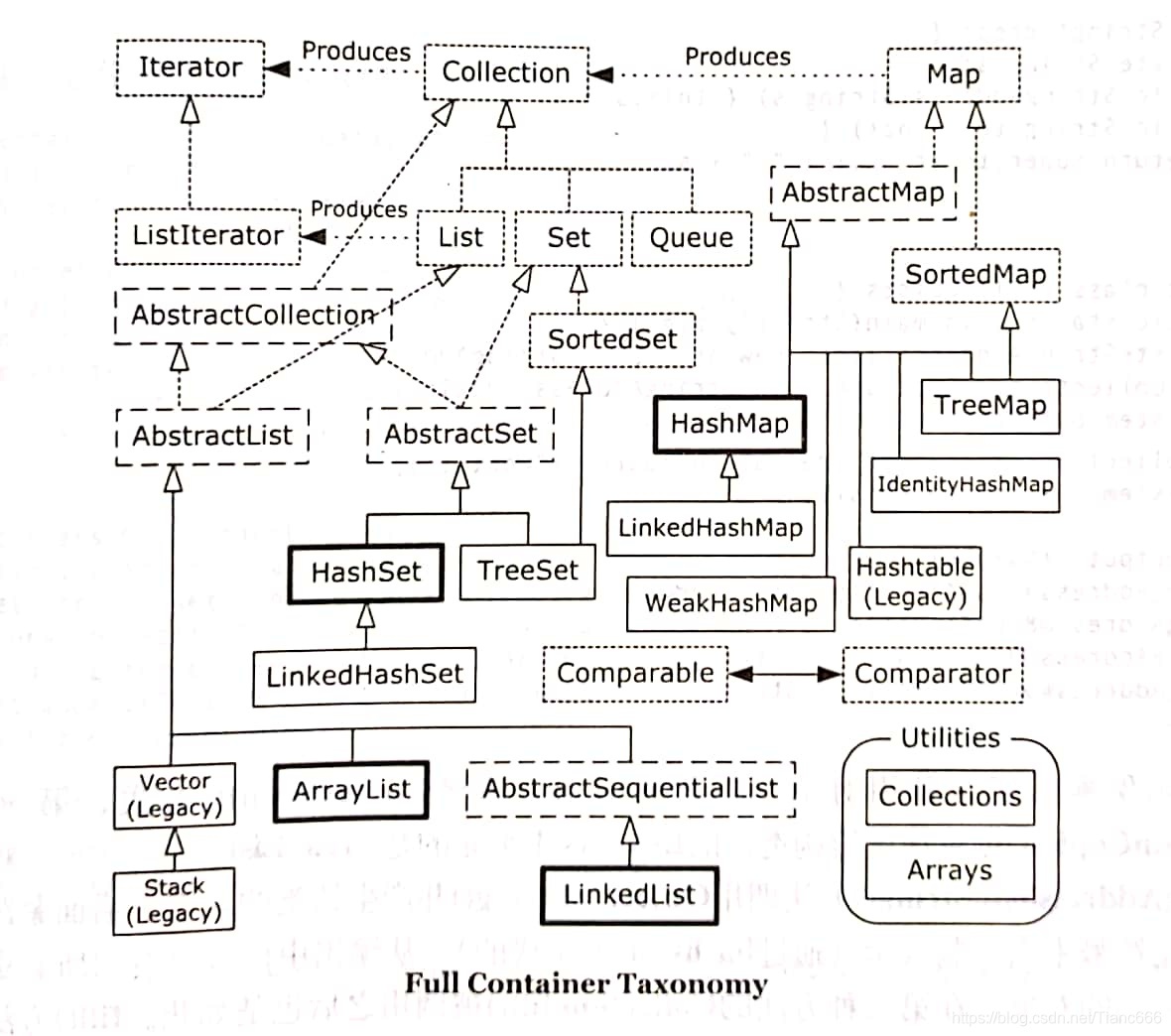
1.完整的容器分類法
2.填充容器
-
復制同一個物件參考來填充容器
- (1) Collections.nCopies()
- (2) Collections.fill()
-
toString():回傳類名+散列碼的無符號十六進制
-
一種Generator解決方案
- (1) 所有的Collection子型別都有一個接收另一個Collection物件的構造器,用所接收的Collection物件中的元素來填充新的容器
- (2) 泛型便利方法(例如addAll())可以減少在使用類時所必需的型別檢查數量
-
Map生成器
- (1) 例
package Chapter17.Example;
import java.util.*;
import net.mindview.util.*;
import static net.mindview.util.Print.*;
class Letters implements Generator<Pair<Integer, String>>,
Iterable<Integer> {
private int size = 9;
private int number = 1;
private char letter = 'A';
public Pair<Integer, String> next() {
return new Pair<Integer, String>(
number++, "" + letter++);
}
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
public Integer next() {
return number++;
}
public boolean hasNext() {
return number < size;
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
}
package Chapter17.Example;
import net.mindview.util.Generator;
import java.util.Iterator;
import java.util.LinkedHashMap;
public class MapData<K, V> extends LinkedHashMap<K, V> {
public MapData(Generator<Pair<K, V>> gen, int quantity) {
for(int i = 0; i < quantity; ++i) {
Pair<K, V> p = (Pair)gen.next();
this.put(p.key, p.value);
}
}
public MapData(Generator<K> genK, Generator<V> genV, int quantity) {
for(int i = 0; i < quantity; ++i) {
this.put(genK.next(), genV.next());
}
}
public MapData(Generator<K> genK, V value, int quantity) {
for(int i = 0; i < quantity; ++i) {
this.put(genK.next(), value);
}
}
public MapData(Iterable<K> genK, Generator<V> genV) {
Iterator var4 = genK.iterator();
while(var4.hasNext()) {
K key = (K) var4.next();
this.put(key, genV.next());
}
}
public MapData(Iterable<K> genK, V value) {
Iterator var4 = genK.iterator();
while(var4.hasNext()) {
K key = (K) var4.next();
this.put(key, value);
}
}
public static <K, V> MapData<K, V> map(Generator<Pair<K, V>> gen, int quantity) {
return new MapData(gen, quantity);
}
public static <K, V> MapData<K, V> map(Generator<K> genK, Generator<V> genV, int quantity) {
return new MapData(genK, genV, quantity);
}
public static <K, V> MapData<K, V> map(Generator<K> genK, V value, int quantity) {
return new MapData(genK, value, quantity);
}
public static <K, V> MapData<K, V> map(Iterable<K> genK, Generator<V> genV) {
return new MapData(genK, genV);
}
public static <K, V> MapData<K, V> map(Iterable<K> genK, V value) {
return new MapData(genK, value);
}
}
package Chapter17.Example;
import net.mindview.util.CountingGenerator;
import net.mindview.util.RandomGenerator;
import static net.mindview.util.Print.print;
public class MapDataTest {
public static void main(String[] args) {
// Pair Generator:
print(MapData.map(new Letters(), 11));
// Two separate generators:
print(MapData.map(new CountingGenerator.Character(),
new RandomGenerator.String(3), 8));
// A key Generator and a single value:
print(MapData.map(new CountingGenerator.Character(),
"Value", 6));
// An Iterable and a value Generator:
print(MapData.map(new Letters(),
new RandomGenerator.String(3)));
// An Iterable and a single value:
print(MapData.map(new Letters(), "Pop"));
}
}
package Chapter17.Example;
public class Pair<K, V> {
public final K key;
public final V value;
public Pair(K k, V v) {
key = k;
value = v;
}
}
- (2) 創建一個Pair<V,K>類,再呼叫Generator.next()方法來組裝Map
- (3) Map配接器可以使用各種不同的Generator、Iterator和常量值的組合來填充Map初始化物件
- (4) 通過產生一個Iterator還實作了Iterable,
-
使用Abstract類
- (1) 例:
package Chapter17.Test5;
import java.util.*;
public class CountingMapData extends AbstractMap<Integer, String> {
private int size;
private static String[] chars = "A B C D E F G H I J K L M N O P Q R S T U V W X Y Z".split(" ");
public CountingMapData(int size) {
if (size < 0) this.size = 0;
this.size = size;
}
private class Entry implements Map.Entry<Integer, String> {
int index;
Entry(int index) {
this.index = index;
}
public boolean equals(Object o) {
return o instanceof Entry && index == ((Entry) o).index;
}
public Integer getKey() {
return index;
}
public String getValue() {
return chars[index % chars.length] + Integer.toString(index / chars.length);
}
public String setValue(String value) {
throw new UnsupportedOperationException();
}
public int hashCode() {
return Integer.valueOf(index).hashCode();
}
}
class EntrySet extends AbstractSet<Map.Entry<Integer, String>> {
public int size() {
return size;
}
private class Iter implements Iterator<Map.Entry<Integer, String>> {
private Entry entry = new Entry(-1);
public boolean hasNext() {
return entry.index < size - 1;
}
public Map.Entry<Integer, String> next() {
entry.index++;
return entry;
}
public void remove() {
throw new UnsupportedOperationException();
}
}
public Iterator<Map.Entry<Integer, String>> iterator() {
return new Iter();
}
}
private Set<Map.Entry<Integer, String>> entries =
new EntrySet();
public Set<Map.Entry<Integer, String>> entrySet() {
return entries;
}
}
package Chapter17.Test5;
public class Test5 {
public static void main(String[] args) {
System.out.println(new CountingMapData(60));
}
}
- (1) 產生容器的測驗資料:創建定制的Collection和Map實作
- (2) 享元設計模式:在普通的解決方案需要過多的物件,或者產生普通物件太占用空間時使用享元
- (3) 為了創建只讀的Map,可以繼承AbstractMap并實作entrySet(),為了創建只讀的Set,可以繼承AbstractSet并實作iterator()和size()
3.Collection的功能方法
- boolean add(T):像容器添加內容添加失敗回傳false
- boolean addAll(Collection<? extends E> c):添加引數中所有元素,有任意元素添加成功則回傳true
- void clear():移除容器中所有元素
- boolean contains(T):如果容器已經持有泛型型別T的引數,則回傳true
- boolean containsAll(Collection<?>):如果容器中持有引數中所有元素回傳true
- boolean isEmpty():容器中沒有元素,回傳true
- Iterator iterator():回傳一個Iterator,可用來遍歷容器中的元素
- boolean remove(Object o):如果元素再容器中,則移除一個元素實體,如果做了移除動作,則回傳true
- boolean removeAll(Collection<?> c):一處引數中所有元素,如果有移除動作,則回傳true
- boolean retainAll(Collection<?> c):只保存引數中元素,Collection發生改變回傳true
- int size():回傳容器中元素數目
- Object[] toArray():回傳一個陣列,該陣列包含容器中所有元素
- T[] toArray(T[] a):回傳一個包含所有容器內元素的陣列,但回傳型別為T而不簡單是Object
4.可選操作
- 執行各種不同的添加和移除的方法在Collection介面中都是可選操作,這意味著實作類并不需要為這些方法提供功能定義
- “可選操作”可以防止設計中出現介面爆炸的情況
- 容器應該易學易用,未獲得支持的操作時一種特例,可以延遲到需要時再實作
- 如果一個操作未獲得支持,那么實作介面會導致UnsupportedOperationException例外
- 未獲支持的操作
- (1) 最常見的未獲支持的操作,都是源于背后由固定尺寸的資料結構支持的容器
- (2) 任何會引起對底層資料結構的尺寸進行修改的方法都會產生一個UnsupportedOperationException例外,以表示對未獲支持操作的呼叫(一個編程錯誤)
- (3) 未獲支持的操作只有在運行時才能檢測到,因此它們表示動態型別檢查
5.List的功能方法
- 基本的List很容易使用:大多數時候只是呼叫add()添加物件,使用get()一次取出一個元素,以及呼叫iterator()獲取用于該序列的Iterator
package Chapter17.Example2;
import java.util.*;
import net.mindview.util.*;
import static net.mindview.util.Print.*;
public class Lists {
private static boolean b;
private static String s;
private static int i;
private static Iterator<String> it;
private static ListIterator<String> lit;
public static void basicTest(List<String> a) {//包含每個List都可執行的操作
a.add(1, "x"); // Add at location 1
a.add("x"); // Add at end
// Add a collection:
a.addAll(Countries.names(25));
// Add a collection starting at location 3:
a.addAll(3, Countries.names(25));
b = a.contains("1"); // Is it in there?
// Is the entire collection in there?
b = a.containsAll(Countries.names(25));
// Lists allow random access, which is cheap
// for ArrayList, expensive for LinkedList:
s = a.get(1); // Get (typed) object at location 1
i = a.indexOf("1"); // Tell index of object
b = a.isEmpty(); // Any elements inside?
it = a.iterator(); // Ordinary Iterator
lit = a.listIterator(); // ListIterator
lit = a.listIterator(3); // Start at loc 3
i = a.lastIndexOf("1"); // Last match
a.remove(1); // Remove location 1
a.remove("3"); // Remove this object
a.set(1, "y"); // Set location 1 to "y"
// Keep everything that's in the argument
// (the intersection of the two sets):
a.retainAll(Countries.names(25));
// Remove everything that's in the argument:
a.removeAll(Countries.names(25));
i = a.size(); // How big is it?
a.clear(); // Remove all elements
}
public static void iterMotion(List<String> a) {//使用Iterator遍歷元素
ListIterator<String> it = a.listIterator();
b = it.hasNext();
b = it.hasPrevious();
s = it.next();
i = it.nextIndex();
s = it.previous();
i = it.previousIndex();
}
public static void iterManipulation(List<String> a) {//使用Iterator修改元素
ListIterator<String> it = a.listIterator();
it.add("47");
// Must move to an element after add():
it.next();
// Remove the element after the newly produced one:
it.remove();
// Must move to an element after remove():
it.next();
// Change the element after the deleted one:
it.set("47");
}
public static void testVisual(List<String> a) {//查看List的操作效果
print(a);
List<String> b = Countries.names(25);
print("b = " + b);
a.addAll(b);
a.addAll(b);
print(a);
// Insert, remove, and replace elements
// using a ListIterator:
ListIterator<String> x = a.listIterator(a.size() / 2);
x.add("one");
print(a);
print(x.next());
x.remove();
print(x.next());
x.set("47");
print(a);
// Traverse the list backwards:
x = a.listIterator(a.size());
while (x.hasPrevious())
printnb(x.previous() + " ");
print();
print("testVisual finished");
}
// There are some things that only LinkedLists can do:
public static void testLinkedList() {//LinkedList專用的操作
LinkedList<String> ll = new LinkedList<String>();
ll.addAll(Countries.names(25));
print(ll);
// Treat it like a stack, pushing:
ll.addFirst("one");
ll.addFirst("two");
print(ll);
// Like "peeking" at the top of a stack:
print(ll.getFirst());
// Like popping a stack:
print(ll.removeFirst());
print(ll.removeFirst());
// Treat it like a queue, pulling elements
// off the tail end:
print(ll.removeLast());
print(ll);
}
public static void main(String[] args) {
// Make and fill a new list each time:
basicTest(
new LinkedList<String>(Countries.names(25)));
basicTest(
new ArrayList<String>(Countries.names(25)));
iterMotion(
new LinkedList<String>(Countries.names(25)));
iterMotion(
new ArrayList<String>(Countries.names(25)));
iterManipulation(
new LinkedList<String>(Countries.names(25)));
iterManipulation(
new ArrayList<String>(Countries.names(25)));
testVisual(
new LinkedList<String>(Countries.names(25)));
testLinkedList();
}
} /* (Execute to see output) *///:~
6.Set和存盤順序
-
不同的Set實作不僅具有不同的行為,而且對于可以在特定的Set中放置的元素的型別也有不同的要求
-
型別
- (1) Set(interface):存入Set的每個元素都必須是唯一的,因為Set不保存重復元素,加入Set的元素必須定義equals()方法以確保物件的唯一性,
- (2) HashSet:為快速查找而設計的Set,存入HashSet的元素必須定義hashCode()
- (3) TreeSet:保持次序的Set,底層為樹結構,使用它可以從set中提取有序的序列,元素必須實作Comparable介面
- (4) LinkedHashSet:具有HashSet的查詢速度,且內部使用鏈表維護元素的順序,元素也必須實作hashCode()方法
-
從輸出看出
- (1) HashSet以某種神秘的順序保存所有的元素
- (2) LinkedHashSet按照元素插入的順序保存元素
- (3) 而TreeSet按照排序順序維護元素(按照CompareTo()的實作方式)
-
SortedSet
- (1) SortedSet中的元素可以保證處于排序狀態
- (2) SortSet:按物件的比較函式對元素排列
- (3) Comparator comparator() 回傳當前Set使用的Comparator;或者回傳null,表示以自然方式排序
- (4) Object first() 回傳容器中第一個元素
- (5) Object last()回傳容器最后一個元素
- (6) SortedSet subSet(from,to)生成此Set子集,范圍從from(包含)到 to(不包含)
- (7) SortSet headSet(to) 生成此Set子集,由 小于 to的元素組成
- (8) SortSet tailSet(to) 生成此Set子集,由 大于或等于 from的元素組成
7.佇列
-
Queue在Java SE5中僅有的兩個實作是LInkedList和PriorityQueue(優先佇列,不保證輸出順序),他們的差異在于排序行為而不是性能
-
優先級佇列
- (1)
package Chapter17.Example3;
import java.util.*;
/**
* @author:YiMing
* @version:1.0
*/
class ToDoList extends PriorityQueue<ToDoList.ToDoItem> {
static class ToDoItem implements Comparable<ToDoItem> {
private char primary;
private int secondary;
private String item;
public ToDoItem(String td, char pri, int sec) {
primary = pri;
secondary = sec;
item = td;
}
/**
* compareable介面里面就是這么申明的,比較兩個數,
* 1.大于0就是說明是大于的關系,
* 2.小于0就說明是小于的關系,
* 3.等于0就說明是相等的關系
* @param arg
* @return
*/
public int compareTo(ToDoItem arg) {
if (primary > arg.primary)
return +1;
if (primary == arg.primary)
if (secondary > arg.secondary)
return +1;
else if (secondary == arg.secondary)
return 0;
return -1;
}
public String toString() {
return Character.toString(primary) +
secondary + ": " + item;
}
}
public void add(String td, char pri, int sec) {
super.add(new ToDoItem(td, pri, sec));
}
public static void main(String[] args) {
ToDoList toDoList = new ToDoList();
toDoList.add("Empty trash", 'C', 4);
toDoList.add("Feed dog", 'A', 2);
toDoList.add("Feed bird", 'B', 7);
toDoList.add("Mow lawn", 'C', 3);
toDoList.add("Water lawn", 'A', 1);
toDoList.add("Feed cat", 'B', 1);
while (!toDoList.isEmpty()) System.out.println(toDoList.remove());
}
} /* Output:
A1: Water lawn
A2: Feed dog
B1: Feed cat
B7: Feed bird
C3: Mow lawn
C4: Empty trash
*///:~
- (2) 優先佇列通過實作Comparable進行控制
-
雙向佇列
- (1)
package Chapter17.Example4;
import java.util.LinkedList;
public class Deque<T> {
private LinkedList<T> deque = new LinkedList();
public Deque() {
}
public void addFirst(T e) {
this.deque.addFirst(e);
}
public void addLast(T e) {
this.deque.addLast(e);
}
public T getFirst() {
return this.deque.getFirst();
}
public T getLast() {
return this.deque.getLast();
}
public T removeFirst() {
return this.deque.removeFirst();
}
public T removeLast() {
return this.deque.removeLast();
}
public int size() {
return this.deque.size();
}
public String toString() {
return this.deque.toString();
}
}
package Chapter17.Example4;
import static net.mindview.util.Print.*;
public class DequeTest {
static void fillTest(Deque<Integer> deque) {
for (int i = 20; i < 27; i++)
deque.addFirst(i);
for (int i = 50; i < 55; i++)
deque.addLast(i);
}
public static void main(String[] args) {
Deque<Integer> di = new Deque<Integer>();
fillTest(di);
print(di);
while (di.size() != 0)
printnb(di.removeFirst() + " ");
print();
fillTest(di);
while (di.size() != 0)
printnb(di.removeLast() + " ");
}
} /* Output:
[26, 25, 24, 23, 22, 21, 20, 50, 51, 52, 53, 54]
26 25 24 23 22 21 20 50 51 52 53 54
54 53 52 51 50 20 21 22 23 24 25 26
*///:~
- (2) 雙向佇列可以在任何一端添加或移除元素
- (3) 可以使用組合來創建一個Deque類,并直接從LinkedList中暴露相關的方法
8.理解Map
-
標準的Java類別庫中包含了Map的幾種基本實作,包括:
- (1) HashMap
- (2) TreeMap
- (3) LinkedHashMap
- (4) WeakHashMap
- (5) ConcurrentHashMap
- (6) IdentityHashMap
-
它們都有同樣的基本介面Map,但是行為特性各不相同,這表現在效率、鍵值對的保存及呈現次序、物件的保存周期、映射表如何在多執行緒程式中作業和判定“鍵”等價的策略等方面
-
實作Map介面
- (1) HashMap
- Map基于散串列的實作(取代了Hashtable),插入和查詢鍵值對的開銷是固定的,可以i通過構造器設定容量和負載因子,以調整容器的性能
- (2) LinkedHashMap
- 類似于HashMap,但是迭代遍歷它時,取得“鍵值對”的順序是其插入次序,或者是最近最少使用(LRU)次序,只比HashMap慢一點,而在迭代訪問時反而更快,因為它使用鏈表維護內部次序
- (3) TreeMap
- 基于紅黑樹實作,查看“鍵”或“鍵值對”時,他們會被排序(次序由Comparable或Comparator決定)TreeMap的特點在于,所得到的結果是經過排序的,TreeMap是唯一帶有subMap()方法的Map,他回傳一個子樹
- (4) WeakHashMap
- 弱鍵 映射,允許釋放映射所指向的物件;這是為解決某類特殊問題而設計的,如果映射之外沒有參考指向某個“鍵”,則此“鍵”可以被垃圾收集器回收
- (5) ConcurrentHashMap
- 一種執行緒安全的Map,它不涉及同步枷鎖,
- (6) IdentityHashMap
- 使用==代替equals()對“鍵”進行比較的散列映射
-
散列是映射中存盤元素時最常用的方式
-
鍵必須是唯一的,而值可以有重復
-
SortedMap
- (1) 使用SortedMap(TreeMap是其現階段的唯一實作),可以確保鍵處于排序狀態
- (2) Comparator comparator():回傳當前Map使用的Comparator;或者回傳null,以表示自然排序
- (3) T firstKey():回傳Map中的第一個鍵
- (4) T lastKey():回傳Map中的最后一個鍵
- (5) SortMap subMap(fromKet,toKey):生成此Map的子集,范圍從fromKey(包含)到toKey(不包含)的鍵確定
- (6) SortMap headMap(toKey):生成此Map的子集,由鍵 小于toKey的所有鍵值對組成
- (7) SortMap tailMap(fromKey):生成此Map的子集,由鍵 大于或等于 fromeKey的所有鍵值對組成
-
LinkedHashMap
- (1) 為了提高速度,LinkedHashMap散列化所有的元素,但是在遍歷鍵值對時,卻又以元素的插入順序回傳鍵值對
- (2) 可以在構造器中設定LinkedHashMap,使之采用基于訪問最近最少使用演算法,于是沒有被訪問過的元素就會出現在佇列的前面
- (3)
package Chapter17.Example5;
import java.util.*;
import net.mindview.util.*;
import static net.mindview.util.Print.*;
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer, String> linkedMap =
new LinkedHashMap<Integer, String>(
new CountingMapData(9));
print(linkedMap);
// Least-recently-used order:
linkedMap =
new LinkedHashMap<Integer, String>(16, 0.75f, true);
linkedMap.putAll(new CountingMapData(9));
print(linkedMap);
for (int i = 0; i < 6; i++) // Cause accesses:
linkedMap.get(i);//訪問前五個后,就被放在最后面了,最后的6,7,8被提前了
print(linkedMap);
linkedMap.get(0);//訪問過“0“后也被放到了最后
print(linkedMap);
}
} /* Output:
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 6=G0, 7=H0, 8=I0}
{6=G0, 7=H0, 8=I0, 0=A0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0}
{6=G0, 7=H0, 8=I0, 1=B0, 2=C0, 3=D0, 4=E0, 5=F0, 0=A0}
*///:~
9.散列與散列碼
- hashMap使用equals()判斷當前的鍵是否與表中存在的鍵相同
2 ###### 正確的equals()方法必須滿足下面5個條件:
- (1) 自反性,對任意x,x.equals(x)一定回傳true,
- (2) 對稱性,對任意x和y,如果y.equals(x)回傳true,則x.equals(y)也回傳true,
- (3) 傳遞性,對任意x,y,z,如果有x.equals(y)回傳true,y.equals(z)回傳true,則x.equals(z)一定回傳true,
- (4) 一致性,對任意x和y,如果物件中用于等價比較資訊沒有改變,那么無論呼叫x.equals(y)多少次,回傳結果保持一致,
- (5) 對任何不是null的x,x.equals(null)一定回傳false,
- 如果要使用自己的類作為HashMap的鍵,必須同時多載hashCode()和equals()
- 理解hashCode()
- 使用散列的目的在于:想要使用一個物件來查找另一個物件
-
為速度而散列
- (1)
package Chapter17.Example6;
import Chapter17.Test15.MapEntry;
import net.mindview.util.Countries;
import java.util.*;
public class SimpleHashMap<K,V> extends AbstractMap<K,V> {
// Choose a prime number for the hash table
// size, to achieve a uniform distribution:
static final int SIZE = 997;
// You can't have a physical array of generics,
// but you can upcast to one:
@SuppressWarnings("unchecked")
LinkedList<MapEntry<K,V>>[] buckets =
new LinkedList[SIZE];
public V put(K key, V value) {
V oldValue = null;
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null)
buckets[index] = new LinkedList<MapEntry<K,V>>();
LinkedList<MapEntry<K,V>> bucket = buckets[index];
MapEntry<K,V> pair = new MapEntry<K,V>(key, value);
boolean found = false;
ListIterator<MapEntry<K,V>> it = bucket.listIterator();
while(it.hasNext()) {
MapEntry<K,V> iPair = it.next();
if(iPair.getKey().equals(key)) {
oldValue = iPair.getValue();
it.set(pair); // Replace old with new
found = true;
break;
}
}
if(!found)
buckets[index].add(pair);
return oldValue;
}
public V get(Object key) {
int index = Math.abs(key.hashCode()) % SIZE;
if(buckets[index] == null) return null;
for(MapEntry<K,V> iPair : buckets[index])
if(iPair.getKey().equals(key))
return iPair.getValue();
return null;
}
public Set<Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> set= new HashSet<Map.Entry<K,V>>();
for(LinkedList<MapEntry<K,V>> bucket : buckets) {
if(bucket == null) continue;
for(MapEntry<K,V> mpair : bucket)
set.add(mpair);
}
return set;
}
public static void main(String[] args) {
SimpleHashMap<String,String> m =
new SimpleHashMap<String,String>();
m.putAll(Countries.capitals(25));
System.out.println(m);
System.out.println(m.get("ERITREA"));
System.out.println(m.entrySet());
}
}
- (2) 散列的價值在于速度:散列使得查詢得以快速進行
- (3) 陣列并不保存鍵本身,而是通過鍵物件生成一個數字,將其作為陣列的下標,這個數字就是散列碼,由定義在Object中的、且可能由你的類覆寫的hashCode()方法生成
- (4) HashMap快的原因:不是查詢整個list,而是快速地跳到陣列的某個位置,只對很少的元素進行比較
- (5) 由于散串列中的“槽位”(slot)通常稱為桶位(bucket),因此我們將表示實際散串列的陣列命名為bucket,為使散列分布均勻,同的數量通常使用質數
- (6) 為了能夠自動處理沖突,使用一個LinkedList的陣列;每一個新的元素只是直接添加到list末尾的某個特定桶中
-
覆寫hashCode()
-
(1) 你無法控制bucket陣列的下標值的產生,這個值依賴于具體的HashMap物件的容量,而容量的改變與容器的充滿程度和負載因子有關
-
(2) 設計hashCode()是最重要的因素是:無論何時,對同一個物件呼叫hasCode()都應該生成個同樣的值
-
(3) 如果你的hashCode()方法依賴于物件中易變的資料,因此資料發生變化時,hashCode()就會生成一個不同的散列碼,相當于產生了一個不同的鍵
-
(4) 不應該使hashCode()依賴于具有唯一型的物件資訊,尤其是使用this值,這只能產生很糟糕的hashCode(),應為這樣無法生成一個新的鍵,使之與put()中源氏鍵值相同
-
(5) String有個特點:如果程式中有多個String物件,都包含相同的字串序列,那么這些String物件都映射到同一塊記憶體區域
-
(6) 怎樣寫出一份像樣的hashCode基本指導
-
i.
package Chapter17.Example7; import java.util.*; import static net.mindview.util.Print.*; public class CountedString { private static List<String> created = new ArrayList<String>(); private String s; private int id = 0; public CountedString(String str) { s = str; created.add(s); // id is the total number of instances // of this string in use by CountedString: for(String s2 : created) if(s2.equals(s)) id++; } public String toString() { return "String: " + s + " id: " + id + " hashCode(): " + hashCode(); } public int hashCode() { // The very simple approach: // return s.hashCode() * id; // Using Joshua Bloch's recipe: int result = 17; result = 37 * result + s.hashCode(); result = 37 * result + id; return result; } public boolean equals(Object o) { return o instanceof CountedString && s.equals(((CountedString)o).s) && id == ((CountedString)o).id; } public static void main(String[] args) { Map<CountedString,Integer> map = new HashMap<CountedString,Integer>(); CountedString[] cs = new CountedString[5]; for(int i = 0; i < cs.length; i++) { cs[i] = new CountedString("hi"); map.put(cs[i], i); // Autobox int -> Integer } print(map); for(CountedString cstring : cs) { print("Looking up " + cstring); print(map.get(cstring)); } } } /* Output: (Sample) {String: hi id: 4 hashCode(): 146450=3, String: hi id: 1 hashCode(): 146447=0, String: hi id: 3 hashCode(): 146449=2, String: hi id: 5 hashCode(): 146451=4, String: hi id: 2 hashCode(): 146448=1} Looking up String: hi id: 1 hashCode(): 146447 0 Looking up String: hi id: 2 hashCode(): 146448 1 Looking up String: hi id: 3 hashCode(): 146449 2 Looking up String: hi id: 4 hashCode(): 146450 3 Looking up String: hi id: 5 hashCode(): 146451 4 *///:~ -
ii.給int變數result賦予某個非零值常量,例如17
-
iii.為物件內每個有意義的域f計算一個int散列碼c:
- boolean
- c=(f?0:1)
- byte,char,short或int
- c=(int)f
- long
- c=(int)(f^(f>>>32))
- float
- c=Float.float.ToIntBits(f)
- double
- long l=Doule.doubleToLongBits(f);c=(int)(l^(l>>>32))
- object,其equals()呼叫這個域的equals()
- c=f.hashCode()
- 陣列
- 對每個元素應用上述規則
- boolean
-
iv.回傳result
-
v.檢查hashCode()最后生成結果,確保相同的物件有相同的散列碼,
-
-
(7) compareTo()方法有一個比較結構,因此它會產生一個排序序列,排序規則首先按照實際型別排序,然后如果有名字按名字排序,最后按創建順序排序:
package Chapter17.Example7; import typeinfo.pets.Individual; import typeinfo.pets.Pet; import java.util.*; public class IndividualTest { public static void main(String[] args) { Set<Individual> pets = new TreeSet<Individual>(); for(List<? extends Pet> lp : MapOfList.petPeople.values()) for(Pet p : lp) pets.add(p); System.out.println(pets); } } /* Output: [Cat Elsie May, Cat Pinkola, Cat Shackleton, Cat Stanford aka Stinky el Negro, Cymric Molly, Dog Margrett, Mutt Spot, Pug Louie aka Louis Snorkelstein Dupree, Rat Fizzy, Rat Freckly, Rat Fuzzy] *///:~
10.選擇介面的不同實作
-
盡管實際上只有4種容器:Map,List,Set,Queue,但是每種介面都有不止一個實作版本
-
容器之間的區別:所使用的介面是由什么樣的資料結構實作的
-
例如List介面
- (1) ArrayList(底層由陣列支持)
- (2) LinkedList(底層由雙向鏈表實作)
-
Set介面
- (1) HashSet(查詢速度最快)
- (2) LinkedHashSet(保持元素插入順序)
- (3) TreeSet(基于TreeMap,生成一個總是處于排序狀態的Set)
- 性能測驗框架
package Chapter17.Example8;
// Framework for performing timed tests of containers.
public abstract class Test<C> {
String name;
public Test(String name) { this.name = name; }
// Override this method for different tests.
// Returns actual number of repetitions of test.
abstract int test(C container, TestParam tp);
} ///:~
package Chapter17.Example8;
// Applies Test objects to lists of different containers.
import java.util.*;
public class Tester<C> {
public static int fieldWidth = 8;
public static TestParam[] defaultParams= TestParam.array(
10, 5000, 100, 5000, 1000, 5000, 10000, 500);
// Override this to modify pre-test initialization:
protected C initialize(int size) { return container; }
protected C container;
private String headline = "";
private List<Test<C>> tests;
private static String stringField() {
return "%" + fieldWidth + "s";
}
private static String numberField() {
return "%" + fieldWidth + "d";
}
private static int sizeWidth = 5;
private static String sizeField = "%" + sizeWidth + "s";
private TestParam[] paramList = defaultParams;
public Tester(C container, List<Test<C>> tests) {
this.container = container;
this.tests = tests;
if(container != null)
headline = container.getClass().getSimpleName();
}
public Tester(C container, List<Test<C>> tests,
TestParam[] paramList) {
this(container, tests);
this.paramList = paramList;
}
public void setHeadline(String newHeadline) {
headline = newHeadline;
}
// Generic methods for convenience :
public static <C> void run(C cntnr, List<Test<C>> tests){
new Tester<C>(cntnr, tests).timedTest();
}
public static <C> void run(C cntnr,
List<Test<C>> tests, TestParam[] paramList) {
new Tester<C>(cntnr, tests, paramList).timedTest();
}
private void displayHeader() {
// Calculate width and pad with '-':
int width = fieldWidth * tests.size() + sizeWidth;
int dashLength = width - headline.length() - 1;
StringBuilder head = new StringBuilder(width);
for(int i = 0; i < dashLength/2; i++)
head.append('-');
head.append(' ');
head.append(headline);
head.append(' ');
for(int i = 0; i < dashLength/2; i++)
head.append('-');
System.out.println(head);
// Print column headers:
System.out.format(sizeField, "size");
for(Test test : tests)
System.out.format(stringField(), test.name);
System.out.println();
}
// Run the tests for this container:
public void timedTest() {
displayHeader();
for(TestParam param : paramList) {
System.out.format(sizeField, param.size);
for(Test<C> test : tests) {
C kontainer = initialize(param.size);
long start = System.nanoTime();
// Call the overriden method:
int reps = test.test(kontainer, param);
long duration = System.nanoTime() - start;
long timePerRep = duration / reps; // Nanoseconds
System.out.format(numberField(), timePerRep);
}
System.out.println();
}
}
} ///:~
package Chapter17.Example8;
// A "data transfer object."
public class TestParam {
public final int size;
public final int loops;
public TestParam(int size, int loops) {
this.size = size;
this.loops = loops;
}
// Create an array of TestParam from a varargs sequence:
public static TestParam[] array(int... values) {
int size = values.length/2;
TestParam[] result = new TestParam[size];
int n = 0;
for(int i = 0; i < size; i++)
result[i] = new TestParam(values[n++], values[n++]);
return result;
}
// Convert a String array to a TestParam array:
public static TestParam[] array(String[] values) {
int[] vals = new int[values.length];
for(int i = 0; i < vals.length; i++)
vals[i] = Integer.decode(values[i]);
return array(vals);
}
} ///:~
-
對List的選擇
package Chapter17.Example9;
// Demonstrates performance differences in Lists.
// {Args: 100 500} Small to keep build testing short
import java.util.*;
import net.mindview.util.*;
public class ListPerformance {
static Random rand = new Random();
static int reps = 1000;
static List<Test<List<Integer>>> tests =
new ArrayList<Test<List<Integer>>>();
static List<Test<LinkedList<Integer>>> qTests =
new ArrayList<Test<LinkedList<Integer>>>();
static {
tests.add(new Test<List<Integer>>("add") {
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
int listSize = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
for(int j = 0; j < listSize; j++)
list.add(j);
}
return loops * listSize;
}
});
tests.add(new Test<List<Integer>>("get") {
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops * reps;
int listSize = list.size();
for(int i = 0; i < loops; i++)
list.get(rand.nextInt(listSize));
return loops;
}
});
tests.add(new Test<List<Integer>>("set") {
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops * reps;
int listSize = list.size();
for(int i = 0; i < loops; i++)
list.set(rand.nextInt(listSize), 47);
return loops;
}
});
tests.add(new Test<List<Integer>>("iteradd") {
int test(List<Integer> list, TestParam tp) {
final int LOOPS = 1000000;
int half = list.size() / 2;
ListIterator<Integer> it = list.listIterator(half);
for(int i = 0; i < LOOPS; i++)
it.add(47);
return LOOPS;
}
});
tests.add(new Test<List<Integer>>("insert") {
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
for(int i = 0; i < loops; i++)
list.add(5, 47); // Minimize random-access cost
return loops;
}
});
tests.add(new Test<List<Integer>>("remove") {
int test(List<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
while(list.size() > 5)
list.remove(5); // Minimize random-access cost
}
return loops * size;
}
});
// Tests for queue behavior:
qTests.add(new Test<LinkedList<Integer>>("addFirst") {
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
for(int j = 0; j < size; j++)
list.addFirst(47);
}
return loops * size;
}
});
qTests.add(new Test<LinkedList<Integer>>("addLast") {
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
for(int j = 0; j < size; j++)
list.addLast(47);
}
return loops * size;
}
});
qTests.add(
new Test<LinkedList<Integer>>("rmFirst") {
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
while(list.size() > 0)
list.removeFirst();
}
return loops * size;
}
});
qTests.add(new Test<LinkedList<Integer>>("rmLast") {
int test(LinkedList<Integer> list, TestParam tp) {
int loops = tp.loops;
int size = tp.size;
for(int i = 0; i < loops; i++) {
list.clear();
list.addAll(new CountingIntegerList(size));
while(list.size() > 0)
list.removeLast();
}
return loops * size;
}
});
}
static class ListTester extends Tester<List<Integer>> {
public ListTester(List<Integer> container,
List<Test<List<Integer>>> tests) {
super(container, tests);
}
// Fill to the appropriate size before each test:
@Override protected List<Integer> initialize(int size){
container.clear();
container.addAll(new CountingIntegerList(size));
return container;
}
// Convenience method:
public static void run(List<Integer> list,
List<Test<List<Integer>>> tests) {
new ListTester(list, tests).timedTest();
}
}
public static void main(String[] args) {
if(args.length > 0)
Tester.defaultParams = TestParam.array(args);
// Can only do these two tests on an array:
Tester<List<Integer>> arrayTest =
new Tester<List<Integer>>(null, tests.subList(1, 3)){
// This will be called before each test. It
// produces a non-resizeable array-backed list:
@Override protected
List<Integer> initialize(int size) {
Integer[] ia = Generated.array(Integer.class,
new CountingGenerator.Integer(), size);
return Arrays.asList(ia);
}
};
arrayTest.setHeadline("Array as List");
arrayTest.timedTest();
Tester.defaultParams= TestParam.array(
10, 5000, 100, 5000, 1000, 1000, 10000, 200);
if(args.length > 0)
Tester.defaultParams = TestParam.array(args);
ListTester.run(new ArrayList<Integer>(), tests);
ListTester.run(new LinkedList<Integer>(), tests);
ListTester.run(new Vector<Integer>(), tests);
Tester.fieldWidth = 12;
Tester<LinkedList<Integer>> qTest =
new Tester<LinkedList<Integer>>(
new LinkedList<Integer>(), qTests);
qTest.setHeadline("Queue tests");
qTest.timedTest();
}
} /* Output: (Sample)
--- Array as List ---
size get set
10 130 183
100 130 164
1000 129 165
10000 129 165
--------------------- ArrayList ---------------------
size add get set iteradd insert remove
10 121 139 191 435 3952 446
100 72 141 191 247 3934 296
1000 98 141 194 839 2202 923
10000 122 144 190 6880 14042 7333
--------------------- LinkedList ---------------------
size add get set iteradd insert remove
10 182 164 198 658 366 262
100 106 202 230 457 108 201
1000 133 1289 1353 430 136 239
10000 172 13648 13187 435 255 239
----------------------- Vector -----------------------
size add get set iteradd insert remove
10 129 145 187 290 3635 253
100 72 144 190 263 3691 292
1000 99 145 193 846 2162 927
10000 108 145 186 6871 14730 7135
-------------------- Queue tests --------------------
size addFirst addLast rmFirst rmLast
10 199 163 251 253
100 98 92 180 179
1000 99 93 216 212
10000 111 109 262 384
*///:~
注:由于篇幅問題,代碼中的Test、Tester、TestParam類見:Chapter17\Example9
- (1) 對于背后是陣列支撐的List和ArrayList,無論串列大小如何,這些訪問都快速一致,而對于LinkedList訪問時間對于較大的串列明顯增加,如果需要執行大量隨機訪問,鏈接鏈表不會是一種好的選擇
- (2) 使用迭代器在串列中間插入新的元素,對于ArrayList,當串列變大時,其開銷將變得高昂,但是對于LinkedList,相對來說比較低廉,并且不隨串列尺寸而發生變化,這是因為ArrayList在插入時,必須創建空間并將它的所有參考向前移動,這會隨ArrayList的尺寸增加而產生高昂的代價,LinkedList自需要鏈接新的元素,而不必修改串列中剩余的元素,一次你可以認為串列尺寸如果變化,其代價大致相同
- (3) LinkedList對List端點會進行特殊處理——這使得在將LinkedList用作Queue時,速度可以得到提高
- (4) 在LinkedList中的插入和移除代價相當低廉,并且不隨串列尺寸發生變化,但是對于ArrayList,插入操作代價很高昂,并且不隨串列尺寸的增加而增加
- (5) 從Queue測驗中,可以看到LinkedList可以多么快速的從串列的端點插入和移除元素,這正是對Queue行為所做的優化
- (6) 將ArrayList作為默認首選,只有你需要使用額外的功能,或者當程式的性能因為經常從表中間進行插入和洗掉而變差的時候,才去選擇LinkedList,如果使用的是固定數量的元素,那么既可以使用背后有支撐的List,也可以選擇真正的陣列
- (7) CopyOnWriteArrayList是List的一個特殊實作,專門用于并發編程
- 微基準測驗的危險
- Math.random()的輸出中的,其范圍是[0,1)
-
對Set的選擇
- (1) HashSet的性能基本上總是比TreeSet的好,特別是在添加和查詢元素時,而這兩個操作是最重要的操作,TreeSet存在的唯一原因是它可以維持元素的排序狀態
- (2) 對于插入操作,LinkedHashSet比HashSet的代價更高,這是由維護鏈表所帶來額外開銷造成的
-
對Map的選擇
- (1) 所有的Map實作的插入操作都會隨著Map尺寸的變大明顯變慢,但是查找的代價比插入小很多,
- (2) Hashtable的性能大體和HashMap相當,因為HashMap是用來替代Hashtable的,因此它們使用了相同的底層存盤和查找機制
- (3) TreeMap
- i.TreeMap是一種創建有序串列的方式,樹的行為是:總是保證有序,并且不必進行特殊的排序,一旦你填充了一個TreeMap,就可以呼叫keySet()方法來獲取鍵的Set視圖,然后呼叫toArray()來產生這些鍵構成的陣列,
- ii.可以使用靜態方法Arrays.binarySearch()在排序陣列中快速查找物件
- iii.只有你要求Map始終保持有序時,才需要使用TreeMap
- (4) LingkedHashMap在插入時比HashMap慢一點,因為它維護散列資料結構的同時還要維護鏈表,就是因為這個串列,使得其迭代速度更快
- (5) IdentityHashMap則具有完全不同的性能,因為它使用==而不是equals()來比較元素
- (6) HashMap的性能因子,可以通過手工調整HashMap來提高性能,從而滿足我們特定應用的需求:
- i.容量:表中的桶位數
- ii.初始容量:表在創建時所擁有的桶位數
- iii.尺寸:表中當前存盤的項數
- iv.負載因子:尺寸/容量,負載輕的表產生的可能性小,因此對于插入和查找都是最理想的
- (7) HashMap使用的默認負載因子時0.75,這個因子在時間和空間代價之間達到了平衡,更高的負載因子可以降低表所需空間,但是會增加查找代價
11.實用方法
-

-
List的排序和查詢
- (1) List排序和查詢所使用的方法與物件陣列所使用的相應方法有相同的名字與語法,只是用Collections的static方法代替Arrays的方法而已
- (2) 如果使用Comparator進行排序,那么binarySearch()必須使用相同的Comparator
-
設定Collection或Map為不可修改
- (1) Collections.unmodifiableCollection()用于創建“不可修改”的容器(回傳值是容器的只讀版本),任何修改容器內的操作(例如add()、put())都會引起UnsupportedOperationException例外
- (2) 在將容器設為只讀之前,必須填入有意義的資料,裝在資料后就不可修改了
-
Collection或Map的同步控制
- (1) 直接將新生成的容器傳遞給適當的同步方法
- Collections.synchronizedCollection(
new ArrayList()); - Collections.synchronizedList(
new ArrayList()); - Collections.synchronizedSet(
new HashSet()); - Collections.synchronizedSortedSet(
new TreeSet()); - Collections.synchronizedMap(
new HashMap<String,String>()) - Collections.synchronizedSortedMap(
new TreeMap<String,String>())
- Collections.synchronizedCollection(
- (2) 快速報錯
- Java容器有一種保護機制,能夠防止多個行程同時修改同一個容器的內容
- Java容器類類別庫采用快速報錯機制,它會探查容器上的任何除了你行程所進行的操作以外的所有變化,一旦發現其他行程修改了容器,就會拋出ConcurrentModificationException例外
- ConcurrentHashMap、CopyOnWriteArrayList和CopyOnWriteArrayList都使用了可以避免ConcurrentModificationException例外
12.持有參考
- java.lang.ref類別庫包含了一組類,這些類為垃圾回收提供了更大的靈活性
- 有三個繼承自抽象類Reference的類:SoftReference、WeakReference和PhantomReference,當垃圾回收器正在考察的物件只能通過某個Reference物件才“可獲得”時,上述這些不同的派生類為垃圾回收器提供了不同級別的間接性指示
- 使用Renference物件,可以繼續使用該物件,而在記憶體消耗殆盡的時候由允許釋放該物件
- Soft reference:用以實作記憶體敏感的高速快取
- Weak reference:是為實作“規范映射”而設計的,它不妨礙垃圾回收映射的“鍵”(或“值”)
- Phantom reference:用以呼叫回收前的清理作業,它比Java終止機制更靈活
- WeakHashMap:容器類中有一種特殊的Map,即WeakHashMap,它被用來保存WeakReference
13.Java 1.0/1.1 的容器
-
Vector和Enumeration
- Vector是唯一可以自我擴展的序列
- Enumeration只是介面而不是實作
- boolean hasMoreElement():如果此列舉包含更多元素,該方法就回傳true
- Object nextElement():該方法回傳此列舉中的下一個元素(如果該有下一個元素),否則拋出例外
- Collection.emumeration():從Collection生成一個Enumeration
- Hashtable
- 在新程式中,應使用HashMap
- Stack
- Stack繼承了Vector,它擁有Vector所有的特點和行為,在加上一些額外的Stack行為
- BitSet
- 如果想要高效率地存盤大量“開/關”資訊,BitSet是很好的選擇,不過它的效率僅是對空間而言;如果需要高效的訪問時間,BitSet比本地陣列稍微慢一點
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/169727.html
標籤:java
上一篇:完美解決ArcGIS10.x柵格空間插值報錯無法進行和匯出插值柵格結果出錯的問題
下一篇:DAY2_前端入門準備篇(二)