內容不涉及演算法相關內容,paxos演算法,zab協議等網路上已經有很多優秀的文章,這里就不獻丑了

什么是Zookeeper
ZooKeeper是分布式應用程式的分布式協調服務,是Google的Chubby一個開源的實作,是Hadoop和Hbase的重要組件,它是一個為分布式應用提供一致性服務的軟體,提供的功能包括:配置維護、域名服務、分布式同步、集群管理等
為什么需要zookeeper
隨著業務發展,單機系統處理能力達到上限,就需要對系統進行擴展,假設我們需要將資料庫擴展為主從結構,客戶端需要知道資料庫節點中主節點的位置,而當主節點發生故障時我們需要將從節點設定為新的主節點,就像redis一樣,類似的場景有很多; 而在分布式系統中,需要協調的資訊很多,比如某個服務的地址,狀態,服務的名稱,或是集群間狀態同步等等......
若不使用zookeeper:
解決辦法也簡單,比如使用一個map來存盤相關的資訊,需要訪問的時候從記憶體中取出即可,但由于資訊可能需要在不同機器的行程中共享,還需要撰寫socket通訊,另一方面這樣的方式存在單點故障,如果存盤資訊的服務器宕機,整個系統全部癱瘓;
為了解決單點故障,需要將這個存盤資訊的服務設計為分布式的;但是這又產生了新的問題,資料如何在分布式系統中保持一致?
這就需要一致性演算法Paxos來保證,而由于Paxos存在活鎖問題zookeeper使用ZAB協議來同步資料,并保證了一致性;
zookeeper為我們實作了上述的資料存盤,分布式服務,高可用性等基礎功能,利用zookeeper可以很方便的協調分布式應用程式;
使用場景
zookeeper的使用場景比較多,以下例舉其最常用的場景
服務注冊/訂閱
在分布式服務中,通常都需要使用統一的命名,即將一些復雜不方便記憶,容易出錯的資訊對應到一個唯一的簡潔的名稱,zookeeper可以很容易實作名稱的唯一性,并在這個唯一的名稱下存盤一些資料;在訪問提供方啟動后將資訊放到zookeeper中,客戶端通過相同的服務名稱從zookeeper訂閱需要的服務名稱,從而獲取服務提供方的資訊
配置管理(Configuration Management)
在分布式系統中經常有某些服務的呼叫非常頻繁,由于單點壓力大所以將其部署為集群,當需要對這個服務的配置進行修改時,以往需要逐個修改,效率低且容易出錯,得益于zookeeper提供的watch(監視)機制可以實作集中式配置管理,當配置發生變化zookeeper可以通知所有節點,這樣節點就可以訪問zookeeper獲取并應用最新的配置;
組管理(Group Management)
當需要自己搭建主從結構時,需要能夠選舉出master,同時當slave上線或是下線時master能夠立即感知(利用臨時順序節點,選取最小作為master);當master宕機后,slave要選出新的master,并通知其他slave(利用watch機制實作)
分布式鎖(Distribution Lock)
在同一臺機器實作互斥鎖是比較簡單的,因為執行緒或行程之間可以直接利用記憶體或檔案進行狀態的同步,但是在分布式環境中,行程運行在不同的計算節點上,無法像單機那樣直接通過記憶體同步,利用zookeeper的watch,多個行程可以監視同一個資料(代表鎖),當資料狀態發生變化時行程可以知道當前鎖的狀態;
zookeeper的特性
高可用
ZooKeeper已實作主從復制,像它協調的分布式行程一樣,ZooKeeper本身也可以在一組主機上進行主從復制,從而避免單點故障并提高性能;
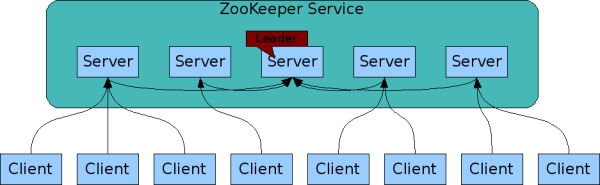
組成ZooKeeper集群的服務器都彼此了解,它們共同維護記憶體中的資料,以及持久存盤中的事務日志和快照,只要及群眾大多數服務器可用,ZooKeeper服務將可用,
客戶端連接到單個ZooKeeper服務器,客戶端維護一個TCP連接,通過它發送請求,獲取回應,獲取監視事件并發送心跳檢測,如果與服務器的TCP連接斷開,客戶端將連接到其他服務器,
高性能
在“讀取為主”的作業負載中,zookeeper非常快,ZooKeeper應用程式可在數千臺計算機上運行,并且在讀取比寫入更為常見的情況下,其性能最佳,比率約為10:1,
提供的保證
- 順序一致性-來自客戶端的更新將按照其發送順序進行處理,
- 原子性-更新成功或失敗,不會產生部分結果,
- 單個資料視圖-無論客戶端連接到哪個服務器,客戶端都將看到相同的資料視圖,也就是說,即使客戶端故障轉移到具有相同會話的其他服務器,客戶端也永遠不會看到系統的較舊資料,(一致性體現)
- 可靠性-資料被更新后,此更新將一直持續到客戶端重新覆寫更新為止,否則將永久生效
- 及時性-確保系統的客戶看到的資料在特定時間范圍內是最新的,(最終一致性)
zookeeper的相關概念
1.節點znode
Zookeeper會保存任務的分配、完成情況,等共享資訊,那么ZooKeeper是如何保存的呢?在 ZooKeeper中,這些資訊被保存在一個個資料節點上,這些節點被稱為znode,它采用了類似檔案系統 的層級樹狀結構進行管理,見下圖示例:
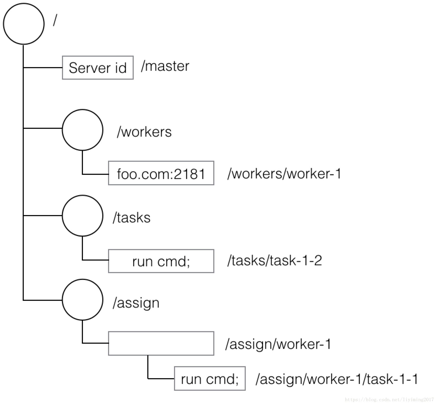
根節點/包含4個子節點,其中三個擁有下一級節點,有的葉子節點存盤了資訊, 節點上沒有存盤資料,也有著重要的含義,比如在主從模式中,當/master節點沒有資料時,代表分布式應用的主節點還沒有選舉出來,
znode節點存盤的資料為位元組陣列bytes,存盤資料的格式zookeeper不做限制,也不提供決議,需要應用自 己實作,
持久節點
持久節點只能通過delete洗掉,zookeeper會將操作以日志的形式寫入到磁盤,當日志變大時,會將所有znodes當前狀態的快照寫入檔案系統,并生成新的事務日志檔案;當zookeeper啟動時將從日志恢復資料;
臨時節點
臨時節點在創建該節點的客戶端崩潰或關閉時,自動被洗掉,在當前版本,由于臨時znode會因為創建者會話過期被刪 除,所以不允許臨時節點擁有子節點,
前面 例子中的/master應該使用臨時節點,這樣當主節點失效或者退出時,該znode被洗掉,其他節點 知道主節點崩潰了,開始進行選舉的邏輯,另外/works/worker-1也應該是臨時節點,在此從節點 失效的時候,該臨時節點自動洗掉,
節點版本
Znodes還維護一個資料結構,其中包括用于資料更改,ACL(訪問控制串列)更改和時間戳的版本號,znode的資料每次更改時,版本號都會增加,例如,每當客戶端檢索資料時,會接收資料的版本,當客戶端發起寫入操作時則需提供與服務器上一致的版本號,否則將更新失敗;
每個znode上的資料都被原子地讀取和寫入,讀取操作將獲取與znode關聯的所有資料,而寫入將替換所有資料,每個節點都有一個訪問控制串列(ACL),用于限制誰可以執行操作,
有序節點
znode可以被設定為有序(sequential)節點,有序znode節點被分配唯一一個單調遞增的序號, 序號的格式為%010d,即10位數字,不足的填充為0,零如果創建了個一有序節點為/workers/worker-,zookeeper會自動分配一個序號1,追加在名字后面,znode名稱為/workers/worker-0000000001,通過這種方式,可以創建唯一名稱znode,并且可以直觀 的看到創建的順序,
znode常見操作及暴露的API:
- ls /path 查看節點的所有子節點
- create /path data :創建一個名為/path的znode,資料為data,
- -e 臨時節點(當前客戶端關閉后/或當前節點重啟后失效)
- -s 有序節點(在節點名稱后面添加節點自增的序號)
- set /path data :設定名為/path的znode的資料為data
- get /path :回傳名為/path的znode的資料、
API
- delete:洗掉節點
- exists:測驗某個位置是否存在節點
- get children :獲取節點子節點的串列
- sync:等待資料在所用節點完成同步
注意:上述列出的指令部分用于zkCli部分用于javaAPI;
2.觀察與通知(watch)
分布式應用需要及時知道zookeeper中znode的變化,從而了解到分布式應用整體的狀況,如果采用輪 詢方式,代價太大,絕大多數查詢都是無效的,因此,zookeeper采用了通知的機制,客戶端向 zookeeper請求,在特定的znode設定觀察點(watcher),Watcher是Zookeeper中的一個很重要的 特性,Zookeeper允許用戶在指定節點上注冊一些Watcher,并且在一些特定事件觸發的時候, ZooKeeper服務端會將事件通知到感興趣的客戶端上去,該機制是Zookeeper實作分布式協調服務的重要支撐,、
wtahc的主要特性:
- 當監聽器監聽的事件被觸發,服務端會發送通知給客戶端,但通知資訊中不包括事件的具體內容,以監聽ZNode結點資料變化為例,當Znode的資料被改變,客戶端會收到事件型別為 NodeDataChanged的通知,但該Znode的資料改變成了什么客戶端無法從通知中獲取,需要客戶端 在收到通知后手動去獲取,
- Watcher是一次性的,一旦被觸發將會失效,
- 3.6.0中的新增功:客戶端可以在znode上設定永久性的監視,這些監視在觸發時不會洗掉,并且會以遞回方式觸發注冊znode以及所有子znode的通知,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/170356.html
標籤:Java
上一篇:學習筆記之方法參考