1. codecs字串編碼和解碼
codecs模塊提供了流介面和檔案介面來完成文本資料不同表示之間的轉換,通常用于處理Unicode文本,不過也提供了其他編碼來滿足其他用途,
1.1 Unicode入門
CPython 3.x區分了文本(text)和位元組(byte)串,bytes實體使用一個8位位元組值序列,與之不同,str串在內部作為一個Unicode碼點(code point)序列來管理,碼點值使用2位元組或4位元組表示,這取決于編譯Python時指定的選項,
輸出str值時,會使用某種標準機制編碼,以后可以將這個位元組序列重構為同樣的文本串,編碼值的位元組不一定與碼點值完全相同,編碼只是定義了兩個值集之間轉換的一種方式,讀取Unicode資料時還需要知道編碼,這樣才能把接收到的位元組轉換為unicode類使用的內部表示,
西方語言最常用的編碼是UTF-8和UTF-16,這兩種編碼分別使用單位元組和兩位元組值序串列示各個碼點,對于其他語言,由于大多數字符都由超過兩位元組的碼點表示,所以使用其他編碼來存盤可能更為高效,
要了解編碼,最好的方法就是采用不同方法對相同的串進行編碼,并查看所生成的不同的位元組序列,下面的例子使用以下函式格式化位元組串,使之更易讀,
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) if __name__ == '__main__': print(to_hex(b'abcdef', 1)) print(to_hex(b'abcdef', 2))
這個函式使用binascii得到輸入位元組串的十六進制表示,在回傳這個值之前每隔nbytes位元組就插入一個空格,

第一個編碼示例首先使用unicode類的原始表示來列印文本'francais',后面是Unicode資料庫中各個字符的名,接下來兩行將這個字串分別編碼為UTF-8和UTF-16,并顯示編碼得到的十六進制值,
import unicodedata import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'fran?ais' print('Raw : {!r}'.format(text)) for c in text: print(' {!r}: {}'.format(c, unicodedata.name(c, c))) print('UTF-8 : {!r}'.format(to_hex(text.encode('utf-8'), 1))) print('UTF-16: {!r}'.format(to_hex(text.encode('utf-16'), 2)))
對一個str編碼的結果是一個bytes物件,

給定一個編碼位元組序列(作為一個bytes實體),decode()方法將其轉換為碼點,并作為一個str實體回傳這個序列,
import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) text = 'fran?ais' encoded = text.encode('utf-8') decoded = encoded.decode('utf-8') print('Original :', repr(text)) print('Encoded :', to_hex(encoded, 1), type(encoded)) print('Decoded :', repr(decoded), type(decoded))
選擇使用哪一種編碼不會改變輸出型別,

1.2 處理檔案
處理I/O操作時,編碼和解碼字串尤其重要,不論是寫至一個檔案、套接字還是其他流,資料都必須使用適當的編碼,一般來講,所有文本資料在讀取時都需要由其位元組表示解碼,寫資料時則需要從內部值編碼為一種特定的表示,程式可以顯式的編碼和解碼資料,不過取決于所用的編碼,要想確定是否已經讀取足夠的位元組來充分解碼資料,這可能并不容易,codecs提供了一些類來管理資料編碼和解碼,所以應用不再需要做這個作業,
codecs提供的最簡單的介面可以替代內置open()函式,這個新版本的函式與內置函式的做法很相似,不過增加了兩個引數來指定編碼和所需的錯誤處理技術,
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Writing to', filename) with codecs.open(filename, mode='w', encoding=encoding) as f: f.write('fran?ais') # Determine the byte grouping to use for to_hex() nbytes = { 'utf-8': 1, 'utf-16': 2, 'utf-32': 4, }.get(encoding, 1) # Show the raw bytes in the file print('File contents:') with open(filename, mode='rb') as f: print(to_hex(f.read(), nbytes))
這個例子首先處理一個包含?的unicode串,使用指定的編碼將這個文本保存到一個檔案,

用open()讀資料很簡單,但有一點要注意:必須提前知道編碼才能正確的建立解碼器,盡管有些資料格式(如XML)會在檔案中指定編碼,但是通常都要由應用來管理,codecs只是取一個編碼引數,并假設這個編碼是正確的,
import binascii import codecs def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) encodings = ['utf-8','utf-16','utf-32'] for encoding in encodings: filename = encoding + '.txt' print('Reading from', filename) with codecs.open(filename, mode='r', encoding=encoding) as f: print(repr(f.read()))
這個例子讀取上一個程式創建的檔案,并把得到的unicode物件的表示列印到控制臺,

1.3 位元組序
在不同的計算機系統之間傳輸資料時(可能直接復制一個檔案,或者使用網路通信來完成傳輸),多位元組編碼(如UTF-16和UTF-32)會帶來一個問題,不同系統中使用的高位元組和低位元組的順序不同,資料的這個特性被稱為位元組序(endianness),這取決于硬體體系結構等因素,還取決于作業系統和應用開發人員做出的選擇,通常沒有辦法提前知道給定的一組資料要使用哪一個位元組序,所以多位元組編碼還包含一個位元組序標志(Byte-Order Marker,BOM),這個標志出現在編碼輸出的前幾個位元組,例如,UTF-16定義0xFFFE和0xFEFF不是合法字符,可以用于指示位元組序,codecs定義了UTF-16和UTF-32所用的位元組序標志的相應常量,
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) BOM_TYPES = [ 'BOM', 'BOM_BE', 'BOM_LE', 'BOM_UTF8', 'BOM_UTF16', 'BOM_UTF16_BE', 'BOM_UTF16_LE', 'BOM_UTF32', 'BOM_UTF32_BE', 'BOM_UTF32_LE', ] for name in BOM_TYPES: print('{:12} : {}'.format( name, to_hex(getattr(codecs, name), 2)))
取決于當前系統的原生位元組序,BOM、BOM_UTF16和BOM_UTF32會自動設定為適當的大端(big-endian)或小端(little-endian)值,

可以由codecs中的解碼器自動檢測和處理位元組序,也可以在編碼時顯式的指定位元組序,
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Pick the nonnative version of UTF-16 encoding if codecs.BOM_UTF16 == codecs.BOM_UTF16_BE: bom = codecs.BOM_UTF16_LE encoding = 'utf_16_le' else: bom = codecs.BOM_UTF16_BE encoding = 'utf_16_be' print('Native order :', to_hex(codecs.BOM_UTF16, 2)) print('Selected order:', to_hex(bom, 2)) # Encode the text. encoded_text = 'fran?ais'.encode(encoding) print('{:14}: {}'.format(encoding, to_hex(encoded_text, 2))) with open('nonnative-encoded.txt', mode='wb') as f: # Write the selected byte-order marker. It is not included # in the encoded text because the byte order was given # explicitly when selecting the encoding. f.write(bom) # Write the byte string for the encoded text. f.write(encoded_text)
首先得出原生位元組序,然后顯式的使用替代形式,以便下一個例子可以在展示讀取時自動檢測位元組序,

程式打開檔案時沒有指定位元組序,所以解碼器會使用檔案前兩個位元組中的BOM值來確定位元組序,
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Look at the raw data with open('nonnative-encoded.txt', mode='rb') as f: raw_bytes = f.read() print('Raw :', to_hex(raw_bytes, 2)) # Re-open the file and let codecs detect the BOM with codecs.open('nonnative-encoded.txt', mode='r', encoding='utf-16', ) as f: decoded_text = f.read() print('Decoded:', repr(decoded_text))
由于檔案的前兩個位元組用于位元組序檢測,所以它們并不包含在read()回傳的資料中,
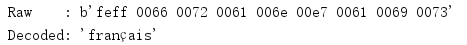
1.4 錯誤處理
前幾節指出,讀寫Unicode檔案時需要知道所使用的編碼,正確的設定編碼很重要,這有兩個原因:首先,如果讀檔案時未能正確的配置編碼,就無法正確的解釋資料,資料有可能被破壞或無法解碼,就會產生一個錯誤,可能丟失資料,
類似于str的encode()方法和bytes的decode()方法,codecs也使用了同樣的5個錯誤處理選項,
| 錯誤模式 | 描述 |
|---|---|
strict |
如果無法轉換資料,則會引發例外, |
replace |
將特殊的標記字符替換為無法編碼的資料, |
ignore |
跳過資料, |
xmlcharrefreplace |
XML字符(僅編碼) |
backslashreplace |
轉義序列(僅編碼) |
1.4.1 編碼錯誤
最常見的錯誤是在向一個ASCII輸出流(如一個常規檔案或sys.stdout)寫Unicode資料時接收到一個UnicodeEncodeError,
import codecs error_handlings = ['strict','replace','ignore','xmlcharrefreplace','backslashreplace'] text = 'fran?ais' for error_handling in error_handlings: try: # Save the data, encoded as ASCII, using the error # handling mode specified on the command line. with codecs.open('encode_error.txt', 'w', encoding='ascii', errors=error_handling) as f: f.write(text) except UnicodeEncodeError as err: print('ERROR:', err) else: # If there was no error writing to the file, # show what it contains. with open('encode_error.txt', 'rb') as f: print('File contents: {!r}'.format(f.read()))
第一種選項,要確保應用顯式的為所有I/O操作設定正確的編碼,strict模式是最安全的選擇,但是產生一個例外時,這種模式可能導致程式崩潰,
第二種選項,replace確保不會產生錯誤,其代價是一些無法轉換為所需編碼的資料可能會丟失,pi(π)的Unicode字符仍然無法用ASCII編碼,但是采用這種錯誤處理模式時,并不是產生一個例外,而是會在輸出中將這個字符替換為?,
第三種選項,無法編碼的資料都會被丟棄,
第四種選項,會把字符替換為標準中定義的一個與該編碼不同的候選表示,xmlcharrefreplace使用一個XML字符參考作為替代,
第五種選項,和第四種一樣會把字符替換為標準中定義的一個與該編碼不同的候選表示,它生成的輸出格式類似于列印unicode物件的repr()時回傳的值,Unicode字符會被替換為\u以及碼點的十六進制值,

1.4.2 編碼錯誤
資料編碼時也有可能遇到錯誤,特別是如果使用了錯誤的編碼,
import codecs import binascii def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) error_handlings = ['strict','ignore','replace'] text = 'fran?ais' for error_handling in error_handlings: print('Original :', repr(text)) # Save the data with one encoding with codecs.open('decode_error.txt', 'w', encoding='utf-16') as f: f.write(text) # Dump the bytes from the file with open('decode_error.txt', 'rb') as f: print('File contents:', to_hex(f.read(), 1)) # Try to read the data with the wrong encoding with codecs.open('decode_error.txt', 'r', encoding='utf-8', errors=error_handling) as f: try: data = f.read() except UnicodeDecodeError as err: print('ERROR:', err) else: print('Read :', repr(data))
與編碼一樣,如果不能正確的節碼位元組流,則strict錯誤處理模式會產生一個例外,在這里,產生UnicodeDecodeError的原因是嘗試使用UTF-8解碼器將UTF-16BOM部分轉換為一個字符,
切換到ignore會讓解碼器跳過不合法的位元組,不過,結果仍然不是原來指望的結果,因為其中包括嵌入的null位元組,
采用replace模式時,非法的位元組會被替換為\uFFFD,這是官方的Unicode替換字符,看起來像是一個有黑色背景的菱形,其中包含一個白色的問號,

1.5 編碼轉換
盡管大多數應用都在內部處理str資料,將資料解碼或編碼作為I/O操作的一部分,但有些情況下,可能需要改變檔案的編碼而不繼續堅持這種中間資料格式,這可能很有用,EncodedFile()取一個使用某種編碼打開的檔案句柄,用一個類包裝這個檔案句柄,有I/O操作時它會把資料轉換為另一種編碼,
import binascii import codecs import io def to_hex(t, nbytes): """Format text t as a sequence of nbyte long values separated by spaces. """ chars_per_item = nbytes * 2 hex_version = binascii.hexlify(t) return b' '.join( hex_version[start:start + chars_per_item] for start in range(0, len(hex_version), chars_per_item) ) # Raw version of the original data. data = https://www.cnblogs.com/liuhui0308/p/'fran?ais' # Manually encode it as UTF-8. utf8 = data.encode('utf-8') print('Start as UTF-8 :', to_hex(utf8, 1)) # Set up an output buffer, then wrap it as an EncodedFile. output = io.BytesIO() encoded_file = codecs.EncodedFile(output, data_encoding='utf-8', file_encoding='utf-16') encoded_file.write(utf8) # Fetch the buffer contents as a UTF-16 encoded byte string utf16 = output.getvalue() print('Encoded to UTF-16:', to_hex(utf16, 2)) # Set up another buffer with the UTF-16 data for reading, # and wrap it with another EncodedFile. buffer = io.BytesIO(utf16) encoded_file = codecs.EncodedFile(buffer, data_encoding='utf-8', file_encoding='utf-16') # Read the UTF-8 encoded version of the data. recoded = encoded_file.read() print('Back to UTF-8 :', to_hex(recoded, 1))
這個例子顯示了如何讀寫EncodedFile()回傳的不同句柄,不論這個句柄用于讀還是寫,file_encoding總是指示總是指示打開檔案句柄所用的編碼(作為第一個引數傳入),data_encoding值則指示通過read()和write()呼叫傳遞資料時所用的編碼,

1.6 非Unicode編碼
盡管之前大多數例子都使用Unicode編碼,但實際上codecs還可以用于很多其他資料轉換,例如,Python包含了處理base-64、bzip2、ROT-13、ZIP和其他資料格式的codecs,
import codecs import io buffer = io.StringIO() stream = codecs.getwriter('rot_13')(buffer) text = 'abcdefghijklmnopqrstuvwxyz' stream.write(text) stream.flush() print('Original:', text) print('ROT-13 :', buffer.getvalue())
如果轉換可以被表述為有單個輸入引數的函式,并且回傳一個位元組或Unicode串,那么這樣的轉換都可以注冊為一個codec,對于'rot_13'codec,輸入應當是一個Unicode串;輸出也是一個Unicode串,
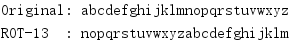
使用codecs包裝一個資料流,可以提供比直接使用zlib更簡單的介面,
import codecs import io buffer = io.BytesIO() stream = codecs.getwriter('zlib')(buffer) text = b'abcdefghijklmnopqrstuvwxyz\n' * 50 stream.write(text) stream.flush() print('Original length :', len(text)) compressed_data = buffer.getvalue() print('ZIP compressed :', len(compressed_data)) buffer = io.BytesIO(compressed_data) stream = codecs.getreader('zlib')(buffer) first_line = stream.readline() print('Read first line :', repr(first_line)) uncompressed_data = first_line + stream.read() print('Uncompressed :', len(uncompressed_data)) print('Same :', text == uncompressed_data)
并不是所有壓碩訓編碼系統都支持使用readline()或read()通過流介面讀取資料的一部分,因為這需要找到壓縮段的末尾來完成解壓縮,如果一個程式無法在記憶體中保存整個解壓縮的資料集,那么可以使用壓縮庫的增量訪問特性,而不是codecs,

1.7 增量編碼
目前提供的一些編碼(特別是bz2和zlib)在處理資料流時可能會顯著改變資料流的長度,對于大的資料集,這些編碼采用增量方式可以更好的處理,即一次只處理一個小資料塊,IncrementalEncoder/IncreamentalDecoder API就是為此而設計,
import codecs import sys text = b'abcdefghijklmnopqrstuvwxyz\n' repetitions = 50 print('Text length :', len(text)) print('Repetitions :', repetitions) print('Expected len:', len(text) * repetitions) # Encode the text several times to build up a # large amount of data encoder = codecs.getincrementalencoder('bz2')() encoded = [] print() print('Encoding:', end=' ') last = repetitions - 1 for i in range(repetitions): en_c = encoder.encode(text, final=(i == last)) if en_c: print('\nEncoded : {} bytes'.format(len(en_c))) encoded.append(en_c) else: sys.stdout.write('.') all_encoded = b''.join(encoded) print() print('Total encoded length:', len(all_encoded)) print() # Decode the byte string one byte at a time decoder = codecs.getincrementaldecoder('bz2')() decoded = [] print('Decoding:', end=' ') for i, b in enumerate(all_encoded): final = (i + 1) == len(text) c = decoder.decode(bytes([b]), final) if c: print('\nDecoded : {} characters'.format(len(c))) print('Decoding:', end=' ') decoded.append(c) else: sys.stdout.write('.') print() restored = b''.join(decoded) print() print('Total uncompressed length:', len(restored))
每次將資料傳遞到編碼器或解碼器時,其內部狀態都會更新,狀態一致時(按照codec的定義),會回傳資料并重置狀態,在此之前,encode()或decode()呼叫并不回傳任何資料,傳入最后一位資料時,引數final應當設定為True,這樣codec就能知道需要重繪輸出所有余下的緩沖資料,

1.8 定義定制編碼
由于Python已經提供了大量標準codecs,所以應用一般不太可能需要定義定制的編碼器或解碼器,不過,如果確實有必要,codecs中的很多基類可以幫助你更容易的定義定制編碼,
第一步是了解編碼描述的轉換性質,這一節中的例子將使用一個“invertcaps”編碼,它把大寫字母轉換為小寫,把小寫字母轉換為大寫,下面是一個編碼函式的簡單定義,它會對輸入字串完成這個轉換,
import string def invertcaps(text): """Return new string with the case of all letters switched. """ return ''.join( c.upper() if c in string.ascii_lowercase else c.lower() if c in string.ascii_uppercase else c for c in text ) if __name__ == '__main__': print(invertcaps('ABCdef')) print(invertcaps('abcDEF'))
在這里,編碼器和解碼器都是同一個函式(與ROT-13類似),

盡管很容易理解,但這個實作效率不高,特別是對于非常大的文本串,幸運的是,codecs包含一些輔助函式,可以創建基于字符映射(character map)的codecs,如invertcaps,字符映射編碼由兩個字典構成,編碼映射(encoding map)將輸入串的字符值轉換為輸出中的位元組值,解碼映射(decoding map)則相反,首先創建解碼映射,然后使用make_encoding_map()把它轉換為一個編碼映射,C函式charmap_encode()和charmap_decode()可以使用這些映射高效的轉換輸入資料,
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) if __name__ == '__main__': print(codecs.charmap_encode('abcDEF', 'strict', encoding_map)) print(codecs.charmap_decode(b'abcDEF', 'strict', decoding_map)) print(encoding_map == decoding_map)
盡管invertcaps的編碼和解碼映射是一樣的,但并不總是如此,有時會把對各輸入字符編碼為相同的輸出位元組,make_encoding_map()會檢測這些情況,并把編碼值替換為None,以標志編碼為未定義,

字符映射編碼器和解碼器支持前面介紹的所有標準錯誤處理方法,所以不需要做任何額外的作業來支持這部分API,
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) text = 'pi: \u03c0' for error in ['ignore', 'replace', 'strict']: try: encoded = codecs.charmap_encode( text, error, encoding_map) except UnicodeEncodeError as err: encoded = str(err) print('{:7}: {}'.format(error, encoded))
由于π的Unicode碼點不再編碼映射中,所以采用strict錯誤處理模式時會產生一個例外,

定義了編碼和解碼映射之后,還需要建立一些額外的類,另外要注冊編碼,register()向注冊表增加一個搜索函式,使得當用戶希望使用這種編碼時,codecs能夠找到它,這個搜索函式必須有一個字串引數,其中包含編碼名,如果它知道這個編碼則回傳一個CodecInfo物件,否則回傳None,
import codecs def search1(encoding): print('search1: Searching for:', encoding) return None def search2(encoding): print('search2: Searching for:', encoding) return None codecs.register(search1) codecs.register(search2) utf8 = codecs.lookup('utf-8') print('UTF-8:', utf8) try: unknown = codecs.lookup('no-such-encoding') except LookupError as err: print('ERROR:', err)
可以注冊多個搜索函式,每個搜索函式將依次呼叫,直到一個搜索函式回傳一個CodecInfo,或者所有搜索函式都已經呼叫,codecs注冊的內部搜索函式知道如何加裝標準codecs,如encodings的UTF-8,所以這些編碼名不會傳遞到定制搜索函式,

搜索函式回傳的CodecInfo實體告訴codecs如何使用所支持的各種不同機制來完成編碼和解碼,包括:無狀態編碼、增量式編碼和流編碼,codecs包括一些基類來幫助建立字符映射編碼,下面這個例子集成了所有內容,它會注冊一個搜索函式,并回傳為invertcaps codec配置的一個CodecInfo實體,
import codecs import string # Map every character to itself decoding_map = codecs.make_identity_dict(range(256)) # Make a list of pairs of ordinal values for the lower # and uppercase letters pairs = list(zip( [ord(c) for c in string.ascii_lowercase], [ord(c) for c in string.ascii_uppercase], )) # Modify the mapping to convert upper to lower and # lower to upper. decoding_map.update({ upper: lower for (lower, upper) in pairs }) decoding_map.update({ lower: upper for (lower, upper) in pairs }) # Create a separate encoding map. encoding_map = codecs.make_encoding_map(decoding_map) class InvertCapsCodec(codecs.Codec): "Stateless encoder/decoder" def encode(self, input, errors='strict'): return codecs.charmap_encode(input, errors, encoding_map) def decode(self, input, errors='strict'): return codecs.charmap_decode(input, errors, decoding_map) class InvertCapsIncrementalEncoder(codecs.IncrementalEncoder): def encode(self, input, final=False): data, nbytes = codecs.charmap_encode(input, self.errors, encoding_map) return data class InvertCapsIncrementalDecoder(codecs.IncrementalDecoder): def decode(self, input, final=False): data, nbytes = codecs.charmap_decode(input, self.errors, decoding_map) return data class InvertCapsStreamReader(InvertCapsCodec, codecs.StreamReader): pass class InvertCapsStreamWriter(InvertCapsCodec, codecs.StreamWriter): pass def find_invertcaps(encoding): """Return the codec for 'invertcaps'. """ if encoding == 'invertcaps': return codecs.CodecInfo( name='invertcaps', encode=InvertCapsCodec().encode, decode=InvertCapsCodec().decode, incrementalencoder=InvertCapsIncrementalEncoder, incrementaldecoder=InvertCapsIncrementalDecoder, streamreader=InvertCapsStreamReader, streamwriter=InvertCapsStreamWriter, ) return None codecs.register(find_invertcaps) if __name__ == '__main__': # Stateless encoder/decoder encoder = codecs.getencoder('invertcaps') text = 'abcDEF' encoded_text, consumed = encoder(text) print('Encoded "{}" to "{}", consuming {} characters'.format( text, encoded_text, consumed)) # Stream writer import io buffer = io.BytesIO() writer = codecs.getwriter('invertcaps')(buffer) print('StreamWriter for io buffer: ') print(' writing "abcDEF"') writer.write('abcDEF') print(' buffer contents: ', buffer.getvalue()) # Incremental decoder decoder_factory = codecs.getincrementaldecoder('invertcaps') decoder = decoder_factory() decoded_text_parts = [] for c in encoded_text: decoded_text_parts.append( decoder.decode(bytes([c]), final=False) ) decoded_text_parts.append(decoder.decode(b'', final=True)) decoded_text = ''.join(decoded_text_parts) print('IncrementalDecoder converted {!r} to {!r}'.format( encoded_text, decoded_text))
無狀態編碼器/解碼器的基類是Codec,要用新實作來覆寫encode()和decode()(在這里分別呼叫了charmap_encode()和charmap_decode()),這些方法必須分別回傳一個元組,其中包含轉換的資料和已消費的輸入位元組或字符數,charmap_encode()和charmap_decode()已經回傳了這個訊息,所以很方便,
IncrementalEncoder和incrementalDecoder可以作為增量式編碼介面的基類,增量來的encode()和decode()方法被定義為只回傳真正的轉換資料,緩沖的有關訊息都作為內部狀態來維護,invertcaps編碼不需要緩沖資料(它使用一種一對一映射),如果編碼根據所處理的資料會生成不同數量的輸出,如壓縮演算法,那么對于這些編碼,BufferedIncrementalEncoder和BufferedIncrementalDecoder將是更合適的基類,因為它們可以管理輸入中未處理的部分,
StreamReader和StreamWriter也需要encode()和decode()方法,而且因為它們往往回傳與Codec中相應方法同樣的值,所以實作時可以使用多重繼承,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/170383.html
標籤:Python
上一篇:Python常用內置物件
下一篇:python的常量與變數