前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!??¤
QQ群:961562169
開發工具
- python 3.6.5
- pycharm
import requests
import parsel
相關模塊可pip安裝
分析目標網頁
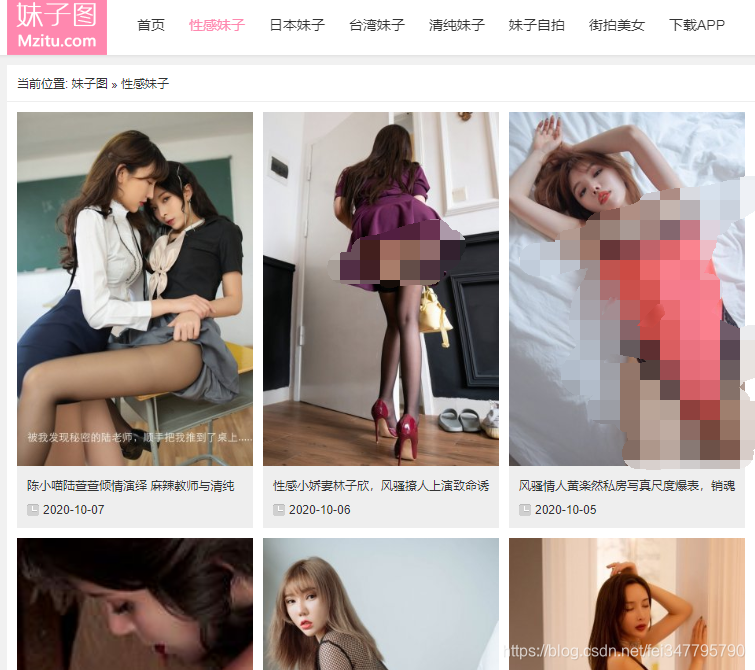
![]() ?
?
請求網頁獲取串列頁
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
lis = selector.css('#pins li a::attr(href)').getall()
for li in lis:
page_id = li.split('/')[-1]
獲取詳情頁下一頁url
def netx_url(url, page_id):
response_2 = requests.get(url=url, headers=headers)
selector = parsel.Selector(response_2.text)
last_num = selector.css('.pagenavi a:nth-child(7) span::text').get()
for i in range(1, int(last_num) + 1):
new_url = 'https://www.mzitu.com/{}/{}'.format(page_id, i)
保存資料
def download(url):
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
title = selector.css('body > div.main > div.content > h2::text').get() # 圖片標題
img_url = selector.css('.main-image p img::attr(src)').get() # 圖片地址
path = 'D:\\python\\demo\\妹子圖\\img\\' + title + '.jpg'
download_response = requests.get(url=img_url, headers=headers)
with open(path, mode='wb') as f:
f.write(download_response.content)
print(title, img_url)
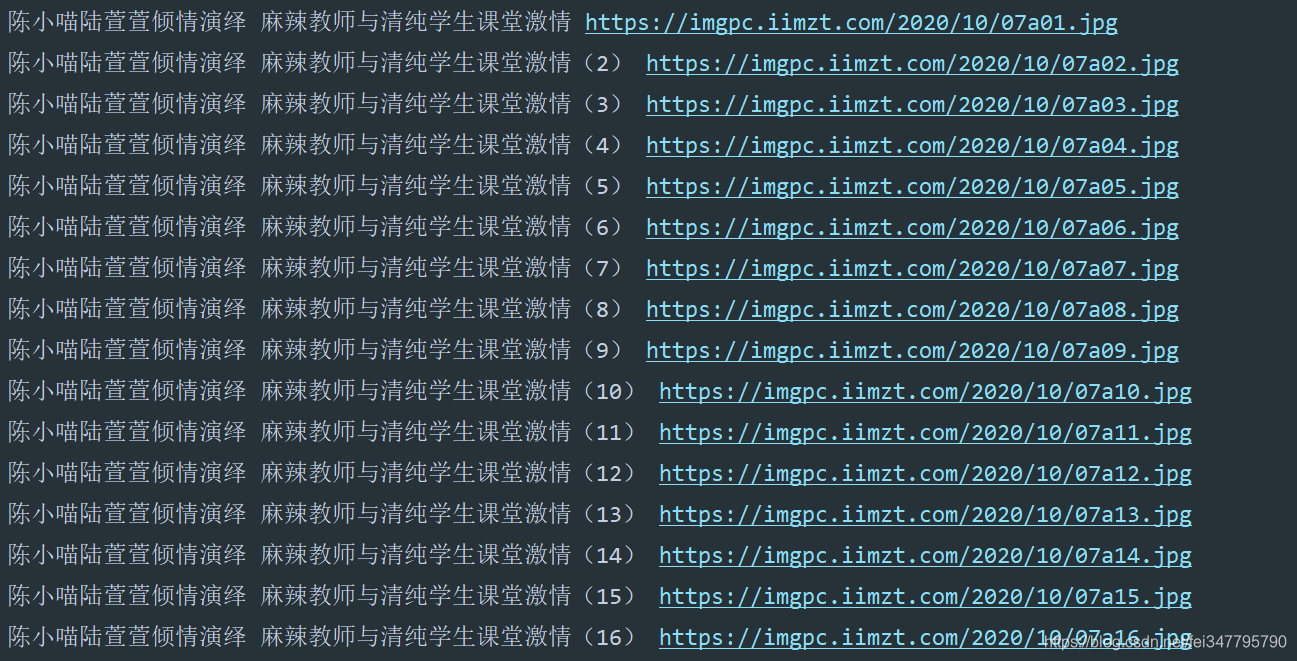
![]() ?
?
![]() ?
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/173123.html
標籤:Python