前景介紹
上期文章介紹TensorFlow入門基礎篇,本意就是給介紹強化學習做一篇前置,
本期我們將嘗試利用深度強化學習來讓神經網路學習自動地玩一款經典的吃豆人小游戲,讓我們愉快地開始吧~
吃豆人小游戲的介紹與pygame實作方式參見:Pygame吃豆人小游戲制作
本文實作的版本與上文中實作的版本略有不同,算是上文中實作版本的改進版,
開發工具
Python版本3.7.7
相關模塊:
- pygame(1.9.6)
- pytorch(0.4.1)
- torchvision(0.2.2)
- opencv-python
- numpy
- matplotlib
- 以及一些python自帶的模塊,
原理簡介
一、DQN 簡介
DQN,即Deep Q Network,
1.1 強化學習(RL)
要介紹DQN,就得先介紹強化學習,強化學習,說白了,就是讓AI通過不斷地試錯來學習,直接上圖說明:
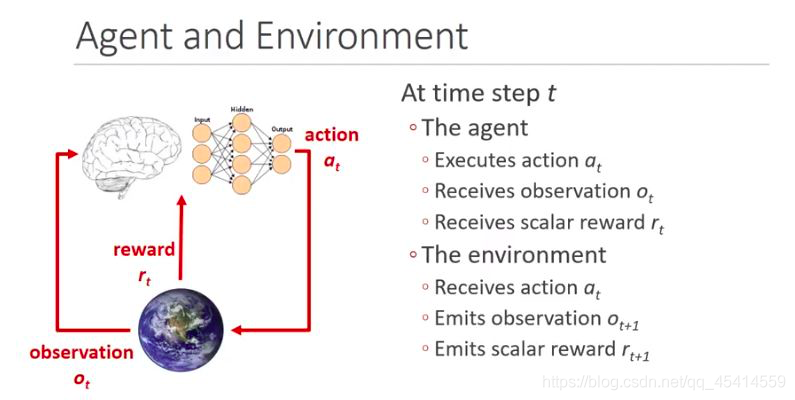
先解釋圖中比較關鍵的單詞吧:
- agent:智能體
- observation:觀察
- reward:獎勵
- action:動作
- environment:環境
上圖中,大腦代表智能體,地球代表環境,其中只有一部分可被大腦觀察到,獎勵為環境提供給大腦的反饋,動作為智能體根據環境和獎勵做出的行動,強化學習的最終目的,就是找到一個好的策略,可以讓自己根據這個策略做出的行動獲得的獎勵最多,
舉個例子,現在我們有一個機器手臂(agent),我們想讓它實作抓娃娃這個任務,那么機器手臂周圍的物體就是環境(environment),而機器手臂可以通過例如攝像頭來觀察(observation)當前的環境,不過由于只是一個攝像頭,所以機器手臂只能觀察到環境的一部分,現在,機器手臂根據當前觀察到的環境開始了抓娃娃的行動(policy),如果機器手臂離娃娃變近了,那么當前行動帶來的環境變化是有利于我們利用機器手臂去抓娃娃的,這時機器手臂獲得的獎勵(reward)應當是正的,反之就應當是負的,
一般地,我們假設agent所處的狀態s為當前觀察到的環境,agent根據當前觀察到的環境做出的行動為a,從s到a的程序則可稱為一個策略π,也即:a=π(s)或者π(a|s),
1.2 馬爾可夫程序(MDP)
馬爾可夫程序,即MDP(Markov Decision Process),其基本假設為“未來只取決于當前”,數學上表示為:
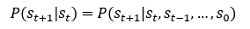
其中,P為概率,St代表某時刻的狀態,當然,這里的狀態代表的是整個環境,而非observation到的環境,慢著,我們不是在討論DQN嗎,咋扯到了MDP?是這樣的,強化學習問題都可以模型化為MDP問題,Why?一個簡單的解釋就是如果預測模型把之前所有的狀態都考慮進來去估計下一個狀態,那建立的這個模型也未免太大了,如果將強化學習問題模型化為MDP問題,那么agent只需要根據現在的狀態來預測未來的狀態,而知道了未來,agent也就有可能找到最好的行動方式了,換而言之,對于每個未來狀態,agent都有一個最佳行動與之對應,
1.3 價值函式(Value Function)
接下來,我們考慮這樣一個問題:如何定量地描述狀態或者說狀態的好壞,從而根據狀態好壞來確定接下來的行動?首先,我們假設t時刻的狀態將獲得的回報Gt為:
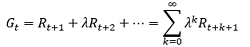
其中,R代表reward;λ代表折扣因子(discount factor),一般小于1,以體現越是未來所給的reward,對現在的影響越小,上面那個式子看上去可以很好地刻畫t時刻狀態的好壞,未來的回報越大,這個狀態顯然越好嘛,然而,上面那個式子存在一個致命的問題:我們必須等到未來所有的時間全部結束之后才能計算出Gt,此時,我們就需要引入一個概念,即價值函式(value function),以更好地刻畫t時刻狀態未來的潛在價值,其數學形式表示為:
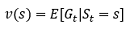
其含義為狀態s對未來reward的期望,reward的期望越高,價值自然也就越大,由此,我們就可以通過估計價值函式來間接優化策略π了,即我們知道了每一種狀態的優劣,也就知道該如何做出決策了,
當然我們也可以直接優化策略π,我們這里只關注間接優化策略π是因為DQN是基于該思想的,
1.4 貝爾曼方程(Bellman Equation)
貝爾曼方程,也稱“動態規劃方程”,此處引入貝爾曼方程,是為了估算價值函式的需要,我們把1.3中給出的價值函式展開:
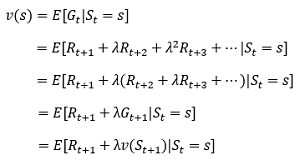
也就是說,當前狀態的價值和當前的reward以及下一狀態的價值有關,換句話說,價值函式是可以通過迭代來求解的,
1.5 動作價值函式(Action-Value Function)
現在,我們來考慮動作(action),對于t時刻的狀態,我們一般有很多種動作可以選擇,每個動作之后的t+1時刻的狀態是不同的,顯然,如果知道了每個動作的價值,那么我們就可以選擇價值最大的那個動作去執行了,這就是動作價值函式,其數學形式為:
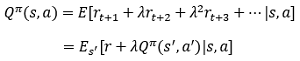
這里的r為reward,表示在狀態s時執行完動作a后得到的reward,π為策略,代表該動作價值函式為在策略π下的動作價值函式,這很好理解,因為對于每個動作,都需要由策略根據當前的狀態生成,由于動作價值函式更加直觀,應用方便,因此我們一般使用動作價值函式而非價值函式,
1.6 最優價值函式(Optimal Value Function)
如前所述,我們只要找到最優的價值函式,自然也就找到了最優策略,(當然最優策略的求解方法不止這一種,因為DQN是基于此思想的,所以我們只關注該求解方法,)數學形式上很好定義最優動作價值函式:
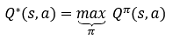
也就是最優的動作價值函式就是所有策略下的動作價值函式的最大值,顯然,最優動作價值函式具有唯一性,應用貝爾曼方程,易得:
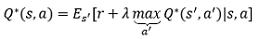
顯然,當a’取得最大Q值時,Q值為最優值,
基于Bellman方程有兩種最基本的演算法,策略迭代和價值迭代,策略迭代本質上就是使用當前策略獲得新的樣本,然后根據新的樣本估計當前策略的價值,從而更新當前策略;而價值迭代更新的是價值,最后收斂得到的是當前狀態下的最優價值,我們將介紹的DQN是基于價值迭代演算法的,
1.7 Q-Learning
Q-Learning的思想基于價值迭代,直觀地理解就是每次利用新得到的reward和原本的Q值來更新現在的Q值,其數學形式表示為:
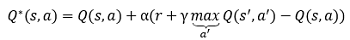
這里并沒有直接將估計的Q值作為新的Q值,而是采用類似梯度下降的方式,每次朝target邁近一小步,而步長取決于α,這有利于減少估計誤差造成的影響,類似于隨機梯度下降,最后將收斂到最優Q值,
具體而言,Q-Learning演算法表述如下:

在上面的演算法中,我們需要某個策略來生成動作(action),一般而言,我們可以選取以下兩種策略:
- 隨機生成一個動作;
- 根據當前的Q值計算出一個最優動作,
第二種策略也稱為貪心策略,數學形式表示為:
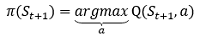
舉例而言,假設我們現在在走迷宮,我向上走的Q值為2,向下走的Q值為3,向左走的Q值為5,向右走的Q值為1,那么我們就向左走,
一般而言,我們稱第一種策略(隨機行動)為exploration;稱第二種策略(貪心)為exploitation;將兩種策略結合起來就是?-greedy策略,即以概率?進行exploration,以概率1-?進行exploitation,且?一般是一個很小的值,
現在我們來考慮另外一個問題,那就是演算法中Q[s, a]如何存盤的問題,顯然我們可以建立一個二維的表格,類似這樣:

但這存在維度災難問題,比如輸入為90*90像素的圖片,對于8bit影像,每個像素點都有256種選擇,那么總狀態數就有256^(8100)種,顯然,我們有必要對狀態的維度進行壓縮,因為我們不可能通過表格來存盤如此多的狀態,這時就需要引入價值函式近似這個概念,簡單而言,價值函式近似就是用一個函式來表示Q(s, a),即:
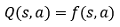
這樣,我們就可以不用去考慮s的表格存盤問題了,每次只需要輸入當前的狀態s和行動a,通過簡單的矩陣運算就可以直接得到所需的Q值了,當然,這個近似是存在誤差的,因為我們并不知道Q值的實際分布情況,我們再仔細考慮一下,發現動作一般都是低維資料,其實沒有必要一起輸入到近似函式f中,于是我們有:
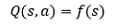
即只把狀態作為輸入,輸出值為每個動作的Q值,即輸出值是一個向量:
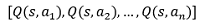
1.8 DQN
前面我們說到,我們可以使用近似函式f來計算Q值,顯然,這個函式就可以用神經網路來近似啊!!!換句話說,就是用神經網路來表示Q值,那么這樣的網路我們就可以稱其為Q-Network了,
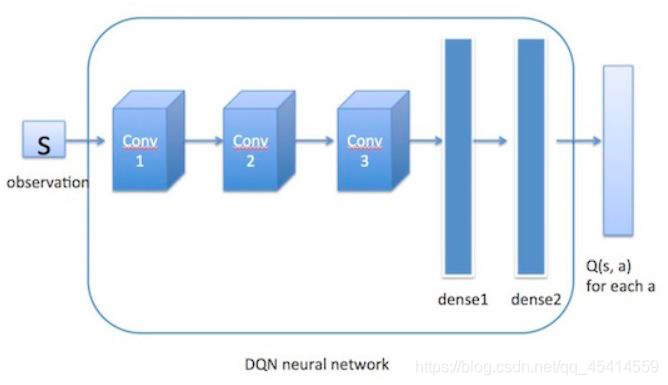
那么問題又來了,神經網路都是需要訓練的呀,Q網路自然也不例外,于是現在的問題變成了:如何為Q網路提供有標簽的樣本進行訓練呢?重新考察Q值更新公式:
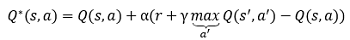
我們發現,Q值的更新依靠的是目標Q值這部分:
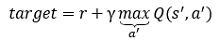
因此,我們直接把它當作標簽不就行了么,因為我們的最終目標就是要讓Q值趨近于目標Q值呀,因此,Q網路的訓練損失函式就是:
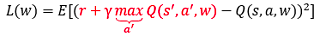
接下來,我們來看看DQN的演算法描述:

這里我們就講講原版本的吧(即NeurIPS 2013版本),演算法看起來很簡單,其本質其實就是反復實驗,并存盤實驗資料,當實驗資料足夠多時,就從中隨機采樣資料,利用梯度下降演算法訓練Q網路,換句話說,在DQN中,增強學習Q-Learning演算法和深度學習的SGD訓練是同步進行的,也即通過Q-Learning獲取訓練樣本,然后對神經網路進行訓練,
這里涉及到一個問題,那就是為什么需要先存盤足夠多的實驗資料才能開始網路的訓練?其實很簡單,由于采集的樣本是一個時間序列,樣本之間具有連續性,如果每次一得到樣本就更新Q網路,那么受樣本分布的影響,訓練效果是不會好的(深度學習一般要求訓練樣本滿足獨立同分布),因此,一個很直接的想法就是把樣本先存起來,當樣本足夠多時,再對其進行隨機采樣,這個方法就是所謂的Experience Reply,
DQN玩吃豆人
-
游戲介紹:
參見:Pygame吃豆人小游戲制作 -
逐步實作DQN:
(1)游戲實作
首先,當然是實作吃豆人小游戲啦!這個開篇就講了,實作思路和之前的差不多,做了一些簡單的改進,完整源代碼在相關檔案里的gameAPI檔案夾下,gameAPI提供了三個可呼叫的函式:- nextFrame:用于模型訓練和模型測驗,玩家不可控制Pacman,由電腦自動操作,函式將回傳游戲每幀的資料
- reset:用于游戲重置
這里稍微講下nextFrame的實作,nextFrame回傳了每幀游戲的畫面以及自己設計的reward資料等模型訓練必要的資料,代碼實作如下:
def nextFrame(self, action=None):
if action is None:
action = random.choice(self.actions)
pygame.event.pump()
pressed_keys = pygame.key.get_pressed()
if pressed_keys[pygame.K_q]:
sys.exit(-1)
pygame.quit()
is_win = False
is_gameover = False
reward = 0
self.pacman_sprites.update(action, self.wall_sprites, None)
for pacman in self.pacman_sprites:
food_eaten = pygame.sprite.spritecollide(pacman, self.food_sprites, True)
capsule_eaten = pygame.sprite.spritecollide(pacman, self.capsule_sprites, True)
nonscared_ghost_sprites = pygame.sprite.Group()
dead_ghost_sprites = pygame.sprite.Group()
for ghost in self.ghost_sprites:
if ghost.is_scared:
if pygame.sprite.spritecollide(ghost, self.pacman_sprites, False):
reward += 6
dead_ghost_sprites.add(ghost)
else:
nonscared_ghost_sprites.add(ghost)
for ghost in dead_ghost_sprites:
ghost.reset()
del dead_ghost_sprites
reward += len(food_eaten) * 2
reward += len(capsule_eaten) * 3
if len(capsule_eaten) > 0:
for ghost in self.ghost_sprites:
ghost.is_scared = True
self.ghost_sprites.update(self.wall_sprites, None, self.config.ghost_action_method, self.pacman_sprites)
self.screen.fill(self.config.BLACK)
self.wall_sprites.draw(self.screen)
self.food_sprites.draw(self.screen)
self.capsule_sprites.draw(self.screen)
self.pacman_sprites.draw(self.screen)
self.ghost_sprites.draw(self.screen)
# get frame
frame = pygame.surfarray.array3d(pygame.display.get_surface())
frame = cv2.transpose(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
self.config.frame_size = frame.shape[0]//4, frame.shape[1]//4, frame.shape[2]
frame = cv2.resize(frame, self.config.frame_size[:2])
# show the score
self.score += reward
text = self.font.render('SCORE: %s' % self.score, True, self.config.WHITE)
self.screen.blit(text, (2, 2))
pygame.display.update()
# judge whether game over
if len(self.food_sprites) == 0 and len(self.capsule_sprites) == 0:
is_win = True
is_gameover = True
reward = 10
if pygame.sprite.groupcollide(self.pacman_sprites, nonscared_ghost_sprites, False, False):
is_win = False
is_gameover = True
reward = -15
if reward == 0:
reward = -2
return frame, is_win, is_gameover, reward, action
(2)模型實作
網路模型采用的是resnet18,就把最后的fc層輸出從1000改成了4,具體而言,代碼實作如下:
'''DQN'''
class DQNet(nn.Module):
def __init__(self, config, **kwargs):
super(DQNet, self).__init__()
self.resnet18 = torchvision.models.resnet18()
self.resnet18.conv1 = nn.Conv2d(in_channels=config.num_continuous_frames*3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)
self.resnet18.fc = nn.Linear(in_features=512, out_features=4)
def forward(self, x):
x = self.resnet18(x)
return x
損失函式如何定義已經在前面DQN的原理介紹部分詳細說明了,這里就不再多說了,其代碼實作如下:
q_t = self.dqn_net(images_input_torch)
q_t = torch.max(q_t, dim=1)[0]
loss = self.mse_loss(torch.Tensor(rewards).type(FloatTensor) + (1 - torch.Tensor(is_gameovers).type(FloatTensor)) * (0.95 * q_t),
(self.dqn_net(images_prev_input_torch) * torch.Tensor(actions).type(FloatTensor)).sum(1))
(3)config.py檔案說明
config.py檔案里是一些預定義的引數,主要包括模型訓練和模型測驗以及游戲實作所需要的引數,默認訓練次數為十萬幀,每一萬幀存盤一次,如下所示:
'''訓練'''
batch_size = 32 # 批次大小
max_explore_iterations = 5000 # 最大迭代大小
max_memory_size = 100000 # 最大記憶體大小
max_train_iterations = 1000000 # 最大訓練次數
save_interval = 10000 # 訓練pkl保存間隔
save_dir = 'model_saved' # 訓練pkl保存路徑
frame_size = None # 框架尺寸根據布局自動計算
num_continuous_frames = 1 # 連續幀
logfile = 'train.log' # 日志檔案保存位置
use_cuda = torch.cuda.is_available() # 使用cuda檢測存在性
eps_start = 1.0 # 開始探索點
eps_end = 0.1 # 結束探索點
eps_num_steps = 10000 # 探索步數
'''測驗'''
weightspath = os.path.join(save_dir, str(max_train_iterations)+'.pkl') # 呼叫訓練集
全部代碼
因為代碼量過大以及之前寫過吃豆人的代碼,在這里不重新寫入
百度網盤: 百度網盤鏈接 ,密碼: bvb6
此次代碼為DQN的完整代碼:
import os
import sys
import time
import torch
import random
import numpy as np
import torch.nn as nn
from collections import deque
'''DQN'''
class DQNet(nn.Module):
def __init__(self, config, **kwargs):
super(DQNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=config.num_element_types*config.num_continuous_frames, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(in_features=config.frame_size[0]*config.frame_size[1]*32, out_features=256)
self.fc2 = nn.Linear(in_features=256, out_features=4)
self.relu = nn.ReLU(inplace=True)
self.__initWeights()
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.relu(x).view(x.size(0), -1)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
def __initWeights(self):
nn.init.normal_(self.conv1.weight, std=0.01)
nn.init.normal_(self.conv2.weight, std=0.01)
nn.init.normal_(self.fc1.weight, std=0.01)
nn.init.normal_(self.fc2.weight, std=0.01)
nn.init.constant_(self.conv1.bias, 0.1)
nn.init.constant_(self.conv2.bias, 0.1)
nn.init.constant_(self.fc1.bias, 0.1)
nn.init.constant_(self.fc2.bias, 0.1)
'''agent實作'''
class DQNAgent():
def __init__(self, game_pacman_agent, dqn_net, config, **kwargs):
self.game_pacman_agent = game_pacman_agent
self.dqn_net = dqn_net
self.config = config
self.game_memories = deque()
self.mse_loss = nn.MSELoss(reduction='elementwise_mean')
'''訓練'''
def train(self):
# 準備階段
if not os.path.exists(self.config.save_dir):
os.mkdir(self.config.save_dir)
if self.config.use_cuda:
self.dqn_net = self.dqn_net.cuda()
FloatTensor = torch.cuda.FloatTensor if self.config.use_cuda else torch.FloatTensor
# 開始訓練
frames = []
optimizer = torch.optim.Adam(self.dqn_net.parameters())
num_iter = 0
image = None
image_prev = None
action_pred = None
score_best = 0
num_games = 0
num_wins = 0
while True:
if len(self.game_memories) > self.config.max_memory_size:
self.game_memories.popleft()
frame, is_win, is_gameover, reward, action = self.game_pacman_agent.nextFrame(action=action_pred)
score_best = max(self.game_pacman_agent.score, score_best)
if is_gameover:
self.game_pacman_agent.reset()
if len(self.game_memories) >= self.config.max_explore_iterations:
num_games += 1
num_wins += int(is_win)
frames.append(frame)
if len(frames) == self.config.num_continuous_frames:
image_prev = image
image = np.concatenate(frames, -1)
exprience = (image, image_prev, reward, self.formatAction(action, outformat='networkformat'), is_gameover)
frames.pop(0)
if image_prev is not None:
self.game_memories.append(exprience)
# 探索
if len(self.game_memories) < self.config.max_explore_iterations:
self.__logging('[狀態]: explore, [記憶體]: %d' % len(self.game_memories), self.config.logfile)
# 訓練
else:
num_iter += 1
images_input = []
images_prev_input = []
is_gameovers = []
actions = []
rewards = []
for each in random.sample(self.game_memories, self.config.batch_size):
image_input = each[0].astype(np.float32)
image_input.resize((1, *image_input.shape))
images_input.append(image_input)
image_prev_input = each[1].astype(np.float32)
image_prev_input.resize((1, *image_prev_input.shape))
images_prev_input.append(image_prev_input)
rewards.append(each[2])
actions.append(each[3])
is_gameovers.append(each[4])
images_input_torch = torch.from_numpy(np.concatenate(images_input, 0)).permute(0, 3, 1, 2).type(FloatTensor)
images_prev_input_torch = torch.from_numpy(np.concatenate(images_prev_input, 0)).permute(0, 3, 1, 2).type(FloatTensor)
# 損失函式
optimizer.zero_grad()
q_t = self.dqn_net(images_input_torch).detach()
q_t = torch.max(q_t, dim=1)[0]
loss = self.mse_loss(torch.Tensor(rewards).type(FloatTensor) + (1 - torch.Tensor(is_gameovers).type(FloatTensor)) * (0.95 * q_t),
(self.dqn_net(images_prev_input_torch) * torch.Tensor(actions).type(FloatTensor)).sum(1))
loss.backward()
optimizer.step()
# 做下步決定
prob = max(self.config.eps_start-(self.config.eps_start-self.config.eps_end)/self.config.eps_num_steps*num_iter, self.config.eps_end)
if random.random() > prob:
with torch.no_grad():
self.dqn_net.eval()
image_input = image.astype(np.float32)
image_input.resize((1, *image_input.shape))
image_input_torch = torch.from_numpy(image_input).permute(0, 3, 1, 2).type(FloatTensor)
action_pred = self.dqn_net(image_input_torch).view(-1).tolist()
action_pred = self.formatAction(action_pred, outformat='oriactionformat')
self.dqn_net.train()
else:
action_pred = None
self.__logging('[狀態]: training, [重復]: %d, [損失值]: %.3f, [行動]: %s, [最高分]: %d, [訓練程度]: %d/%d' % (num_iter, loss.item(), str(action_pred), score_best, num_wins, num_games), self.config.logfile)
if num_iter % self.config.save_interval == 0 or num_iter == self.config.max_train_iterations:
torch.save(self.dqn_net.state_dict(), os.path.join(self.config.save_dir, '%s.pkl' % num_iter))
if num_iter == self.config.max_train_iterations:
self.__logging('訓練完成', self.config.logfile)
sys.exit(-1)
'''訓練'''
def test(self):
if self.config.use_cuda:
self.dqn_net = self.dqn_net.cuda()
self.dqn_net.eval()
FloatTensor = torch.cuda.FloatTensor if self.config.use_cuda else torch.FloatTensor
frames = []
action_pred = None
while True:
frame, is_win, is_gameover, reward, action = self.game_pacman_agent.nextFrame(action=action_pred)
if is_gameover:
self.game_pacman_agent.reset()
frames.append(frame)
if len(frames) == self.config.num_continuous_frames:
image = np.concatenate(frames, -1)
if random.random() > self.config.eps_end:
with torch.no_grad():
image_input = image.astype(np.float32)
image_input.resize((1, *image_input.shape))
image_input_torch = torch.from_numpy(image_input).permute(0, 3, 1, 2).type(FloatTensor)
action_pred = self.dqn_net(image_input_torch).view(-1).tolist()
action_pred = self.formatAction(action_pred, outformat='oriactionformat')
else:
action_pred = None
frames.pop(0)
print('[行動]: %s' % str(action_pred))
def formatAction(self, action, outformat='networkformat'):
if outformat == 'networkformat':
if action == [-1, 0]:
return [1, 0, 0, 0]
elif action == [1, 0]:
return [0, 1, 0, 0]
elif action == [0, -1]:
return [0, 0, 1, 0]
elif action == [0, 1]:
return [0, 0, 0, 1]
elif outformat == 'oriactionformat':
idx = action.index(max(action))
if idx == 0:
return [-1, 0]
elif idx == 1:
return [1, 0]
elif idx == 2:
return [0, -1]
elif idx == 3:
return [0, 1]
def __logging(self, message, savefile=None):
content = '%s %s' % (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), message)
if savefile:
f = open(savefile, 'a')
f.write(content + '\n')
f.close()
print(content)
運行代碼
模型訓練: 根據自己的需要修改config.py檔案(可以不修改),然后運行train.py檔案即可,
模型測驗: 根據自己的需要修改config.py檔案(可以不修改),然后運行demo.py檔案即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/173327.html
標籤:java