通過User-Agent來控制訪問
無論是瀏覽器還是爬蟲程式,在向服務器發起網路請求的時候,都會發過去一個頭檔案:headers,比如知乎的requests headers
很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!??¤
QQ群:623406465
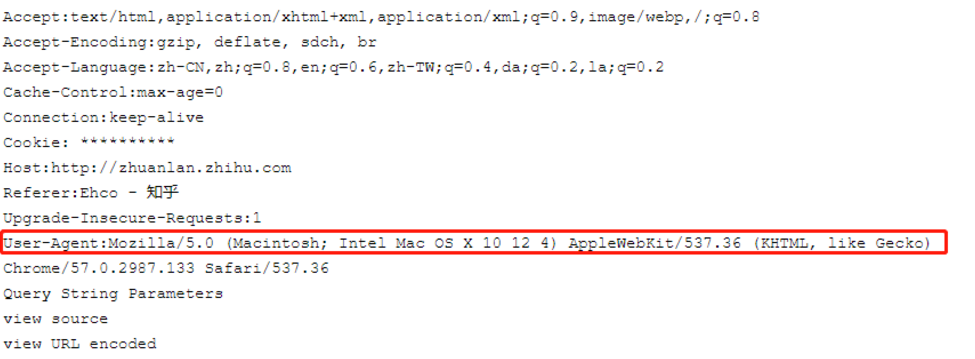
這里面的大多數的欄位都是瀏覽器向服務器”表明身份“用的
對于爬蟲程式來說,最需要注意的欄位就是:User-Agent
很多網站都會建立 user-agent白名單,只有屬于正常范圍的user-agent才能夠正常訪問,
爬蟲方法:
可以自己設定一下user-agent,或者更好的是,可以從一系列的user-agent里隨機挑出一個符合標準的使用,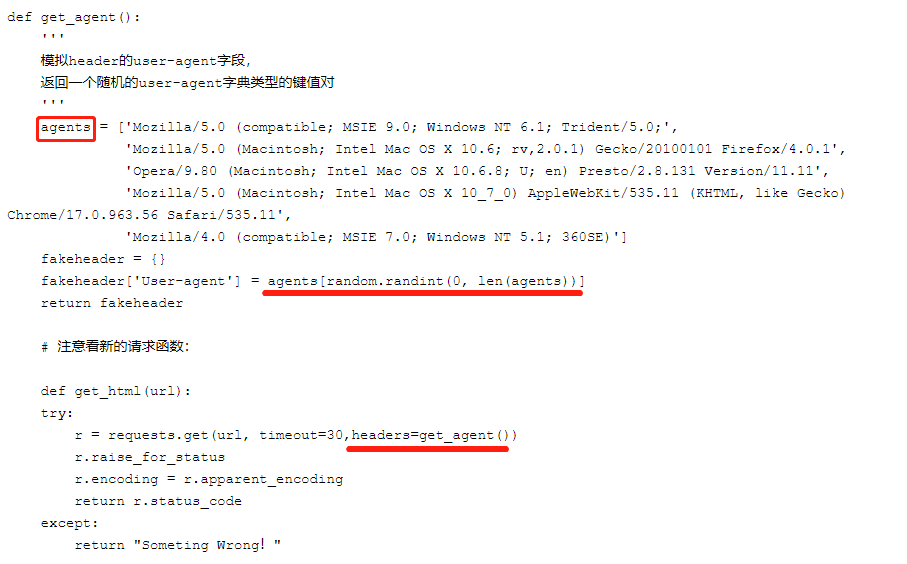
缺點:
容易容易偽造頭部,github上有人分享開源庫fake-useragent
實作難度:★
IP限制
如果一個固定的ip在短暫的時間內,快速大量的訪問一個網站,后臺管理員可以撰寫IP限制,不讓該IP繼續訪問,
爬蟲方法:
比較成熟的方式是:IP代理池
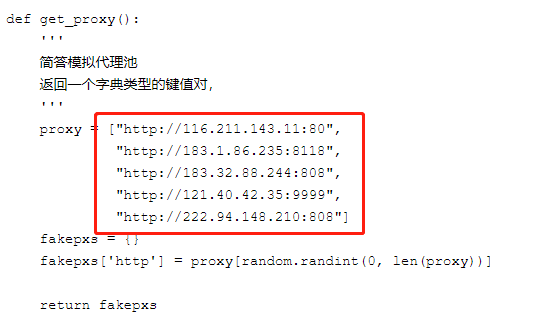
簡單的說,就是通過ip代理,從不同的ip進行訪問,這樣就不會被封掉ip了,
可是ip代理的獲取本身就是一個很麻煩的事情,網上有免費和付費的,但是質量都層次不齊,如果是企業里需要的話,可以通過自己購買集群云服務來自建代理池,
缺點:
可以使用免費/付費代理,繞過檢測,
實作難度:★
SESSION訪問限制
后臺統計登錄用戶的操作,比如短時間的點擊事件,請求資料事件,與正常值比對,用于區分用戶是否處理例外狀態,如果是,則限制登錄用戶操作權限,
缺點:
需要增加資料埋點功能,閾值設定不好,容易造成誤操作,
爬蟲方法:
注冊多個賬號、模擬正常操作,
實作難度:★★★
Spider Trap
蜘蛛陷阱導致網路爬蟲進入無限回圈之類的東西,這會浪費蜘蛛的資源,降低其生產力,并且在撰寫得不好的爬蟲的情況下,可能導致程式崩潰,禮貌蜘蛛在不同主機之間交替請求,并且不會每隔幾秒鐘從同一服務器請求多次檔案,這意味著“禮貌”網路爬蟲比“不禮貌”爬蟲的影響程度要小得多,
反爬方式:
- 創建無限深度的目錄結構
HTTP://example.com/bar/foo/bar/foo/bar/foo/bar /
- 動態頁面,為網路爬蟲生成無限數量的檔案,如由演算法生成雜亂的文章頁面,
- 檔案中填充了大量字符,使決議檔案的詞法分析器崩潰,
此外,帶蜘蛛陷阱的網站通常都有robots.txt告訴機器人不要進入陷阱,因此合法的“禮貌”機器人不會陷入陷阱,而忽視robots.txt設定的“不禮貌”機器人會受到陷阱的影響,
爬蟲方法:
把網頁按照所參考的css檔案進行聚類,通過控制類里最大能包含的網頁數量防止爬蟲進入trap后出不來,對不含css的網頁會給一個penalty,限制它能產生的鏈接數量,這個辦法理論上不保證能避免爬蟲陷入死回圈,但是實際上這個方案作業得挺好,因為絕大多數網頁都使用了css,動態網頁更是如此,
缺點:
反爬方式1,2會增加很多無用目錄或檔案,造成資源浪費,也對正常的SEO十分不友好,可能會被懲罰,
實作難度:★★★
驗證碼驗證
驗證碼(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自動區分計算機和人類的圖靈測驗)的縮寫,是一種區分用戶是計算機還是人的公共全自動程式,可以防止:惡意破解密碼、刷票、論壇灌水,有效防止某個黑客對某一個特定注冊用戶用特定程式暴力破解方式進行不斷的登陸嘗試,實際上用驗證碼是現在很多網站通行的方式,我們利用比較簡易的方式實作了這個功能,這個問題可以由計算機生成并評判,但是必須只有人類才能解答,由于 計算機無法解答CAPTCHA的問題,所以回答出問題的用戶就可以被認為是人類,
1. 圖片驗證碼
- 復雜型
打碼平臺雇傭了人力,專門幫人識別驗證碼,識別完把結果傳回去,總共的程序用不了幾秒時間,這樣的打碼平臺還有記憶功能,圖片被識別為“鍋鏟”之后,那么下次這張圖片再出現的時候,系統就直接判斷它是“鍋鏟”,時間一長,圖片驗證碼服務器里的圖片就被標記完了,機器就能自動識別了,
- 簡單型

![]()
上面兩個不用處理直接可以用OCR識別技術(利用python第三方庫--tesserocr)來識別,

背景比較糊
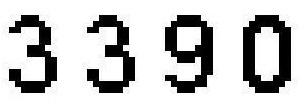
清晰可見
經過灰度變換和二值化后,由模糊的驗證碼背景變成清晰可見的驗證碼,

容易迷惑人的圖片驗證碼
對于在這種驗證碼,語言一般自帶圖形庫,添加上扭曲就成了這個樣子,我們可以利用9萬張圖片進行訓練,完成類似人的精準度,到達識別驗證碼的效果
2. 短信驗證碼
用Webbrowser技術,模擬用戶打開短信的行為,最侄訓取短信驗證碼,
3. 計算題圖片驗證碼


把所有可能出現的漢字都人工取出來,保存為黑白圖片,把驗證碼按照字體顏色二值化,去除噪點,然后將所有圖片依次與之進行像素對比,計算出相似值,找到最像的那張圖片
4. 滑動驗證碼

對于滑動驗證碼
我們可以利用圖片的像素作為線索,確定好基本屬性值,查看位置的差值,對于差值超過基本屬性值,我們就可以確定圖片的大概位置,
5. 圖案驗證碼
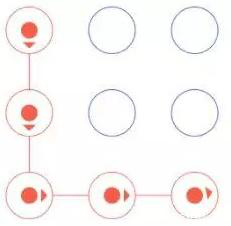
對于這種每次拖動的順序不一樣,結果就不一樣,我們怎么做來識別呢?
- 利用機器學習所有的拖動順序,利用1萬張圖片進行訓練,完成類似人的操作,最終將其識別
- 利用selenium技術來模擬人的拖動順序,窮盡所有拖動方式,這樣達到是別的效果
6. 標記倒立文字驗證碼

我們不妨分析下:對于漢字而言,有中華五千年龐大的文字庫,加上文字的不同字體、文字的扭曲和噪點,難度更大了,
方法:首先點擊前兩個倒立的文字,可確定7個文字的坐標, 驗證碼中7個漢字的位置是確定的,只需要提前確認每個字所在的坐標并將其放入串列中,然后人工確定倒立文字的文字序號,將串列中序號對應的坐標即可實作成功登錄,
爬蟲方法:
接入第三方驗證碼平臺,實時破解網站的驗證碼,
缺點:
影響正常的用戶體驗操作,驗證碼越復雜,網站體驗感越差,
實作難度:★★
通過robots.txt來限制爬蟲
robots.txt(統一小寫)是一種存放于網站根目錄下的ASCII編碼的文本檔案,它通常告訴網路搜索引擎的漫游器(又稱網路蜘蛛),此網站中的哪些內容是不應被搜索引擎的漫游器獲取的,哪些是可以被漫游器獲取的,因為一些系統中的URL是大小寫敏感的,所以robots.txt的檔案名應統一為小寫,robots.txt應放置于網站的根目錄下,如果想單獨定義搜索引擎的漫游器訪問子目錄時的行為,那么可以將自定的設定合并到根目錄下的robots.txt,或者使用robots元資料(Metadata,又稱元資料),
robots.txt協議并不是一個規范,而只是約定俗成的,所以并不能保證網站的隱私,注意robots.txt是用字串比較來確定是否獲取URL,所以目錄末尾有與沒有斜杠“/”表示的是不同的URL,robots.txt允許使用類似"Disallow: *.gif"這樣的通配符,
itunes的robots.txt
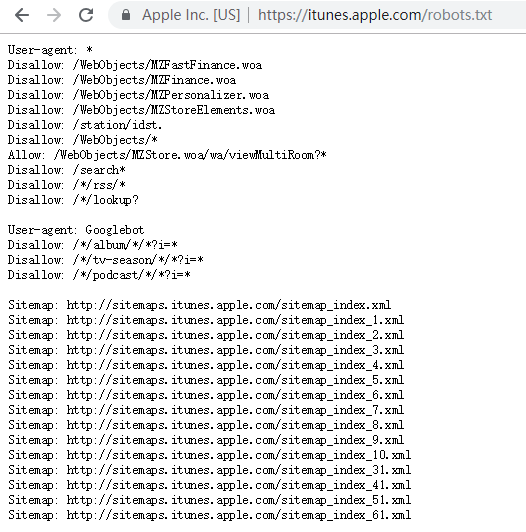
缺點:
只是一個君子協議,對于良好的爬蟲比如搜索引擎有效果,對于有目的性的爬蟲不起作用
爬蟲方法:
如果使用scrapy框架,只需將settings檔案里的ROBOTSTXT_OBEY 設定值為 False
實作難度:★
資料動態加載
python的requests庫只能爬取靜態頁面,爬取不了動態加載的頁面,使用JS加載資料方式,能提高爬蟲門檻,
爬蟲方法:
- 抓包獲取資料url
通過抓包方式可以獲取資料的請求url,再通過分析和更改url引數來進行資料的抓取,
示例:
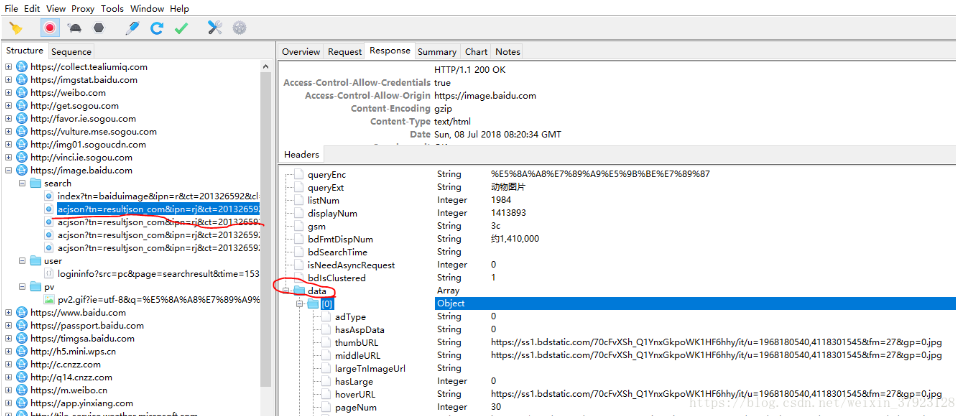
- 看 https://image.baidu.com 這部分的包,可以看到,這部分包里面,search下面的那個 url和我們訪問的地址完全是一樣的,但是它的response卻包含了js代碼,
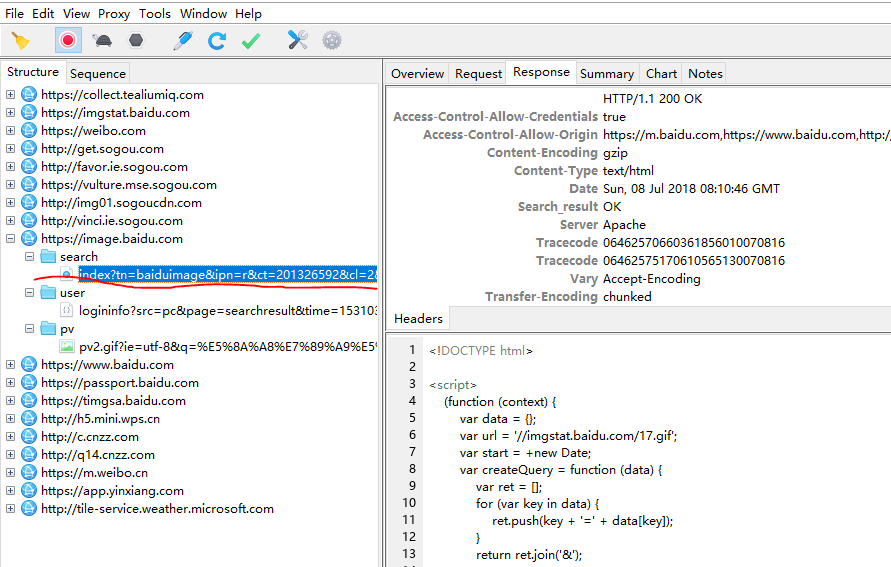 2. 當在動物圖片首頁往下滑動頁面,想看到更多的時候,更多的包出現了,從圖片可以看到,下滑頁面后得到的是一連串json資料,在data里面,可以看到thumbURL等字樣,它的值是一個url,這個就是圖片的鏈接,
2. 當在動物圖片首頁往下滑動頁面,想看到更多的時候,更多的包出現了,從圖片可以看到,下滑頁面后得到的是一連串json資料,在data里面,可以看到thumbURL等字樣,它的值是一個url,這個就是圖片的鏈接,
 3. 打開一個瀏覽器頁面,訪問thumbURL="https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1968180540,4118301545&fm=27&gp=0.jpg" 發現搜索結果里的圖片,
3. 打開一個瀏覽器頁面,訪問thumbURL="https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=1968180540,4118301545&fm=27&gp=0.jpg" 發現搜索結果里的圖片,
4. 根據前面的分析,就可以知道,請求
URL="https://image.baidu.com/search/acjsontn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf8&oe=utf8&adpicid=&st=-1&z=&ic=0&word=%E5%8A%A8%E7%89%A9%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=30&rn=30&gsm=1e&1531038037275=",用瀏覽器訪問這個鏈接確定他是公開的,
5. 最后就可以尋找URL的規律,對URL進行構造便可獲取所有照片,
- 使用selenium
通過使用selenium來實作模擬用戶操作瀏覽器,然后結合BeautifulSoup等包來決議網頁通過這種方法獲取資料,簡單,也比較直觀,缺點是速度比較慢,
缺點:
如果資料API沒做加密處理,容易曝光介面,讓爬蟲用戶更容易獲取資料,
實作難度:★
資料加密-使用加密演算法
- 前端加密
通過對查詢引數、user-agent、驗證碼、cookie等前端資料進行加密生成一串加密指令,將加密指令作為引數,再進行服務器資料請求,該加密引數為慷訓者錯誤,服務器都不對請求進行回應,
- 服務器端加密
在服務器端同樣有一段加密邏輯,生成一串編碼,與請求的編碼進行匹配,匹配通過則會回傳資料,
爬蟲方法:
JS加密破解方式,就是要找到JS的加密代碼,然后使用第三方庫js2py在Python中運行JS代碼,從而得到相應的編碼,
案例參考:
https://blog.csdn.net/lsh19950928/article/details/81585881
缺點:
加密演算法明文寫在JS里,爬蟲用戶還是可以分析出來,
實作難度:★★★
資料加密-使用字體檔案映射
服務器端根據字體映射檔案先將客戶端查詢的資料進行變換再傳回前端,前端根據字體檔案進行逆向解密,
映射方式可以是數字亂序顯示,這樣爬蟲可以爬取資料,但是資料是錯誤的,
破解方式:
其實,如果能看懂JS代碼,這樣的方式還是很容易破解的,所以需要做以下幾個操作來加大破解難度,
- 對JS加密
- 使用多個不同的字體檔案,然后約定使用指定字體檔案方式,比如時間戳取模,這樣每次爬取到的資料映射方式都不一樣,映射結果就不一樣,極大提高了破解的難度,
該種方式相比使用加密演算法方式難度更高,因為加密演算法是固定的幾種,對方很容易獲取并破解,而字體檔案映射可以按任意規則映射,正常的資料使之錯誤顯示,爬蟲不容易察覺,
參考案例:https://www.jianshu.com/p/f79d8e674768
缺點:
需要生成字體檔案,增加網站加載資源的體量,
實作難度:★★★★
非可視區域遮擋
此方式主要針對使用senlium進行的爬蟲,如果模擬界面未進入可視區域,則對未見資料進行遮擋,防止senlium的click()操作,這種方式只能稍稍降低爬蟲的爬取速度,并不能阻止繼續進行資料爬取,
實作難度:★
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/174403.html
標籤:其他