我是一個AI神經元
我是一個AI神經元,剛剛來到這個世界上,一切對我來說都特別新奇,
之所以叫這個名字,是因為我的作業有點像人類身體中的神經元,
人體中的神經元可以傳遞生物信號,給它輸入一個信號,它經過處理后再輸出一個信號傳遞給別的神經元,最終傳遞到大腦完成對一個信號的決策和處理,
聰明的計算機科學家們受到啟發,在代碼程式里發明了我:神經元函式,
在我們的世界里,我只是普普通通的一員,像我這樣的神經元有成百上千,甚至上萬個,我們按照層的形式,組成了一個龐大的神經網路,
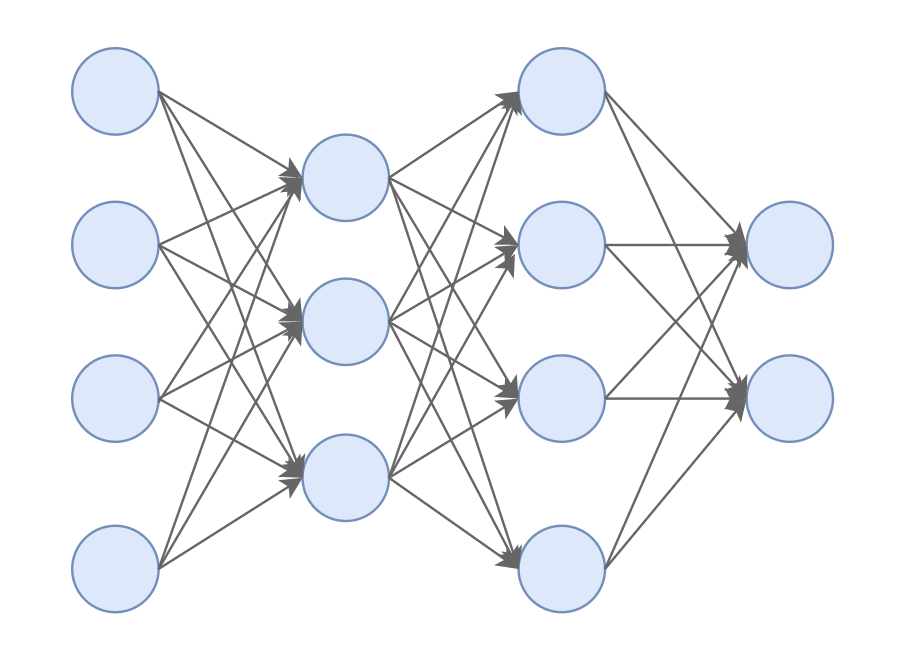
很快我和隔壁工位的大白開始混熟了,他比我來得早,對這里要熟悉的多,
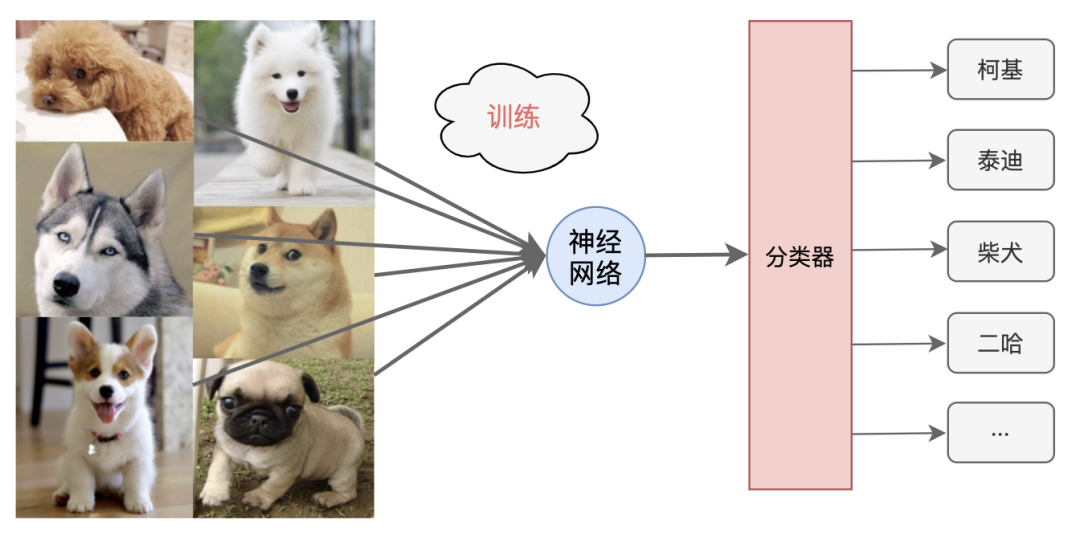
聽大白告訴我說,我們這個神經網路是一個影像識別的AI程式,只要給我們輸入一張狗的照片,我們就能告訴你這是一只柯基,還是泰迪、柴犬、二哈···
神經元結構
在大白的指引下,我很快就學會了怎么作業,
雖然我們叫神經元,名字聽起來挺神秘的,但實際上我就是一個普通函式,有引數,有回傳值,普通函式有的我都有:
def neuron(a):
w = [...]
b = ...
...
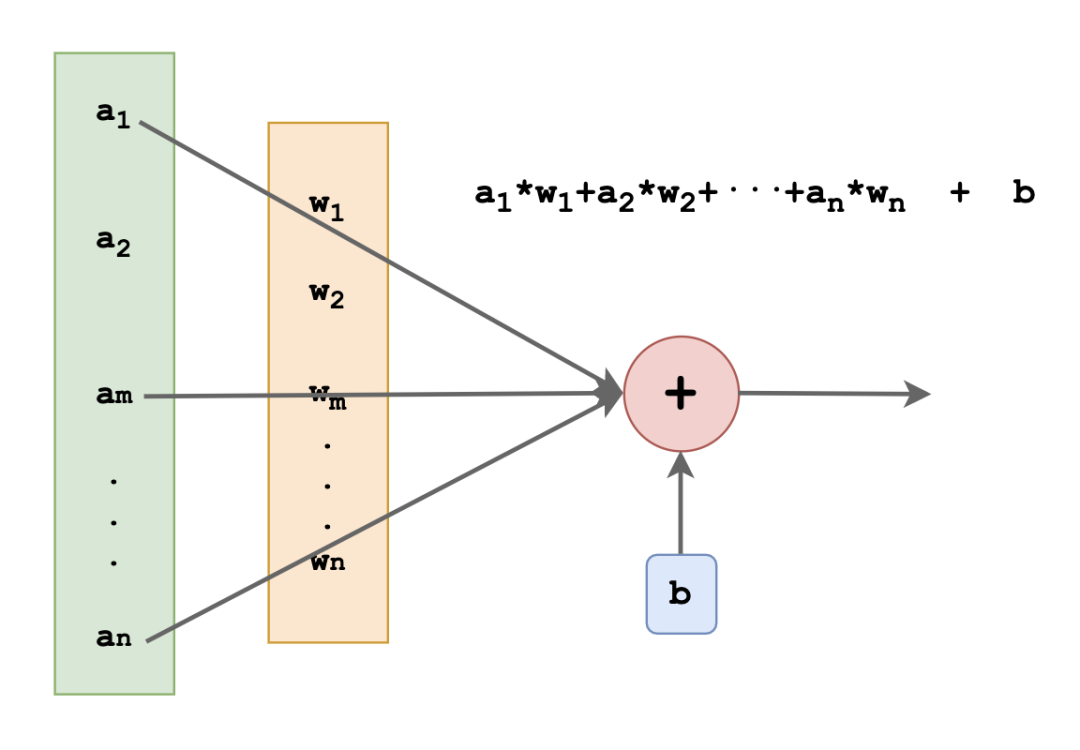
我有一個引數a,這個引數是一個陣列,里面的每一個元素我把它分別叫做a1,a2,a3···用這個a來模擬我這個神經元收到的一組信號,
人類的神經元是怎么處理輸入的生物信號我不知道,我估計挺復雜的,但在我這里就很簡單:我給每一個輸入值設定一定的權重,然后做一個簡單的加權求和,最后再加上一個偏移值就行啦!
所以我還有一個陣列叫做w,就是權重weight的意思,里面的每一個元素我叫做w1,w2,w3···,至于那個偏移值,就叫它bias,
如此一來我的作業你們也該猜到了,就是把傳進來的a里面的每個元素和w里的每一個元素做乘法,再加起來,最后加上偏移值,就像這樣:
說到這里,我突然想到一個問題,打算去問問大白,
“大白,這些要計算的資料都是從哪里來的呢?”
“是上一層的神經元們送過來的”
“那他們的資料又是哪來的呢?”,我刨根問題的問到,
大白帶我來到了門口,指向另外一個片區說到,“看到了嗎?那里是資料預處理部門,他們負責把輸入的圖片中的像素顏色資訊提取出來,交給我們神經網路部門來進行分析,”
“交給我們?然后呢”
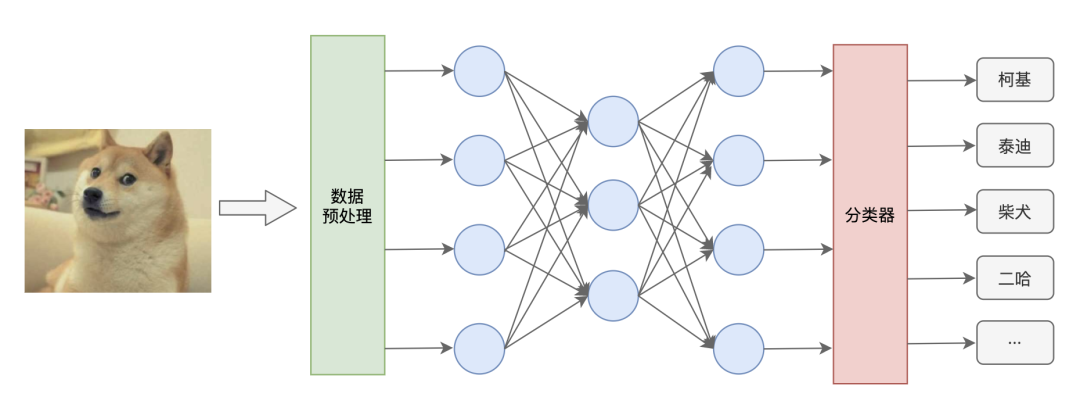
“咱們這個神經網路就像一臺精密的機器,我們倆只是其中兩個零件,不同的權重值某種意義上代表了對圖片上不同位置的像素關心程度,一旦開動起來,喂給我們圖片資料,我們每一個神經元就開始忙活起來,一層層接力,把最終的結果輸出到分類器,最終識別出狗的品種,”
神經網路訓練
正聊著,突然,傳來一陣廣播提示音,大家都停止了閑聊,回到了各自工位,

“這是要干啥,這么大陣仗?”,我問大白,
“快坐下,馬上要開始訓練了”,大白說到,
“訓練?訓練什么?”
“咱們用到的那些權重值和偏移值你以為怎么來的?就是通過不斷的訓練得出來的,”
還沒說到幾句話,資料就開始送過來了,按照之前大白教給我的,我將輸入資料分別乘以各自的權重,然后相加,最后再加上偏移bias,就得到了最后的結果,整個程序很輕松,
我準備把計算結果交給下一層的神經元,
大白見狀趕緊制止了我,“等一下!你不能直接交出去”
“還要干嘛?”
大白指了一下我背后的另一個家伙說到:“那是激活函式,得先交給他處理一下”
“激活函式是干嘛的?”,我問大白,
“激活,就是根據輸入信號量的大小去激活產生對應大小的輸出信號,這是在模仿人類的神經元對神經信號的反應程度大小,好比拿一根針去刺皮膚,隨著力道的加大,身體的疼痛感會慢慢增強,差不多是一個道理,”
聽完大白的解釋,我點了點頭,好像明白了,又好像不太明白,
后來我才知道,這激活函式還有好幾種,經常會打交道的有這么幾個:
sigmoid
tanh
relu
leaky relu
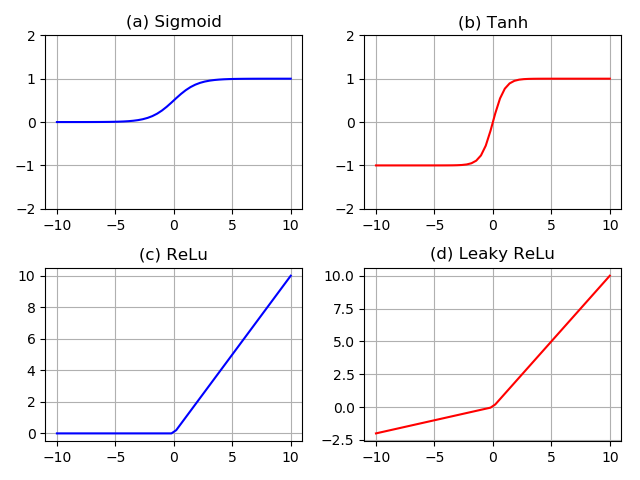
激活函式處理完后,總算可以交給下一層的神經元了,我準備稍事休息一下,
剛坐下,就聽到大廳的廣播:

隨后,又來了一組新的資料,看來我是沒時間休息了,趕緊再次忙活了起來,
這一忙不要緊,一直搞了好幾個小時,來來回回重復作業了幾萬次,我都快累癱了,
損失函式 & 優化方法
趁著休息的空當,我又和大白聊了起來,
“大白,剛剛咱們這么來來回回折騰了幾萬次,這是在干啥啊?”
大白也累的上氣不接下氣,緩了緩才說到:“這叫做網路訓練,通過讓我們分析大量不同品種狗的圖片,讓我們訓練出合適的權重和偏移值,這樣,我們就變得會認識狗品種了,以后正式作業的時候給我們新的狗的圖片,咱們也能用學到的知識去分辨啦!”
“那到底是怎么訓練的,你給我說說唄”,我繼續問到,
“你剛才也看到了,廣播里不斷通知更新權重和偏移值,這訓練就是通過不斷的嘗試修改每一層神經元的權重值和偏移值,來不斷優化,找到最合適的數值,讓我們對狗的種類識別準確率最好!”,大白說到,
“不斷嘗試修改?這么多神經元,難不成看運氣瞎碰?”
大白給了我一個白眼,“怎么可能瞎試,那得試到猴年馬月去了,咱們這叫深度學習神經網路,是能夠自學習的!”
他這么一說我更疑惑了,“怎么個學習法呢?”
“其實很簡單,咱們先選一組權重偏移值,做一輪圖片識別,然后看識別結果和實際結果之間的差距有多少,把差距反饋給咱們后,再不斷調整權重和偏移,讓這個差距不斷縮小,直到差距接近于0,這樣咱們的識別準確率就越接近100%”
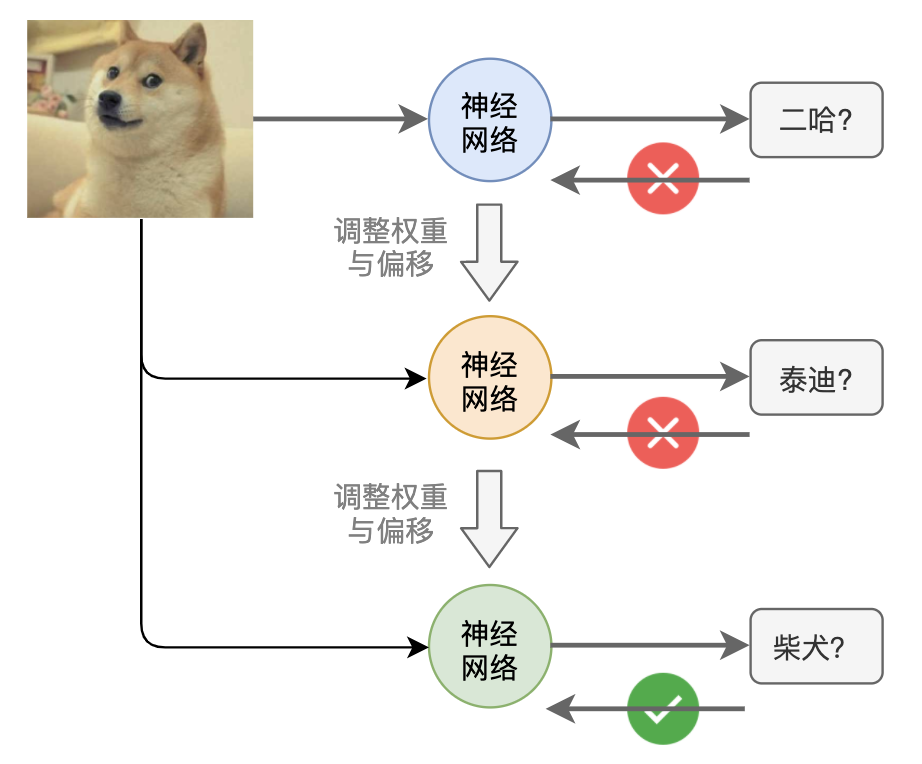
“額,聽上去好像很簡單,不過我還有好多問題啊,怎么去衡量這個差距呢?具體怎么調整權重偏移呢?調整幅度該多大好呢?”,我小小的腦袋一下冒出了許多的問號,
大白臉上露出了不可思議的表情,“小伙子,不錯嘛!你一下問出了神經網路的三個核心概念,”
“是哪三個?快給我說說”
大白喝了口水,頓了頓接著說到,“首先,怎么去衡量這個差距?這個活,咱們部門有個人專門干這活,他就是損失函式,他就是專門來量化咱們的輸出結果和實際結果之間的差距,量化的辦法有很多種,你空了可以去找他聊聊”

“那第二個呢?”
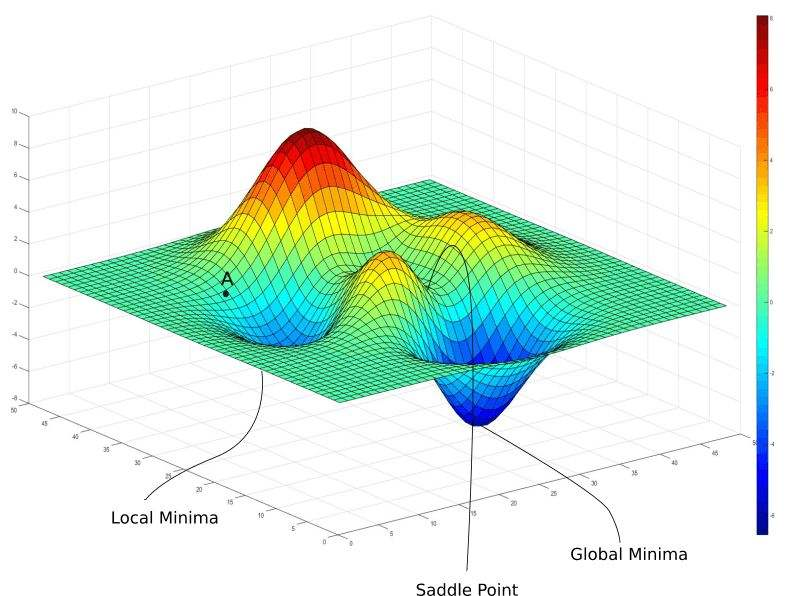
“第二個,具體怎么調整,這也涉及到咱們神經網路中一個核心概念,他就是優化方法,咱們部門用的最多的是一個叫梯度下降的方法,那玩意兒有點復雜,一時半會兒給你說不清楚,大概差不多就是用求導數的方式尋找如何讓損失函式的損失值變小”,大白繼續耐心的解釋著,
“好吧,那第三個核心概念是什么?”
“你剛不是問調整幅度嗎?這個調整幅度太小了不行,這樣咱們訓練的太慢了,那得多訓練很多回,太大了也不行,要是一不小心錯過了那個最優值,損失函式的結果就會來回搖擺,不能收斂,所以有一個叫學習速率的數值,通常需要程式員們憑借經驗去設定”
我還沉浸在大白的講解中,廣播聲再次響起:

看來程式員修改了學習速率,我只好打起精神,繼續去忙了,真不知道何時才能訓練達標啊~
往期TOP5文章
我是Redis,MySQL大哥被我害慘了!
CPU明明8個核,網卡為啥拼命折騰一號核?
因為一個跨域請求,我差點丟了飯碗
完了!CPU一味求快出事兒了!
哈希表哪家強?幾大編程語言吵起來了!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/174802.html
標籤:java