Redis(Remote Dictionary Server),即遠程字典服務,是一個開源的使用ANSI C語言撰寫、高性能的key-value資料庫,是當前使用最廣泛的NoSQL之一,
1、簡介
Redis是一個開源(BSD許可)的,記憶體中的資料結構存盤系統,它可以用作資料庫、快取和訊息中間件, 它支持多種型別的資料結構,如 字串(strings), 散列(hashes), 串列(lists), 集合(sets), 有序集合(sorted sets) 與范圍查詢,bitmaps,hyperloglogs和地理空間(geospatial) 索引半徑查詢, Redis內置了復制(replication),LUA腳本(Lua scripting), LRU驅動事件(LRU eviction),事務(transactions)和不同級別的磁盤持久化(persistence), 并通過Redis哨兵(Sentinel)和自動磁區(Cluster)提供高可用性(high availability),
2、模式
2.1、單機模式
該模式只安裝一個節點,一般用于測驗學習,
2.2、主從模式
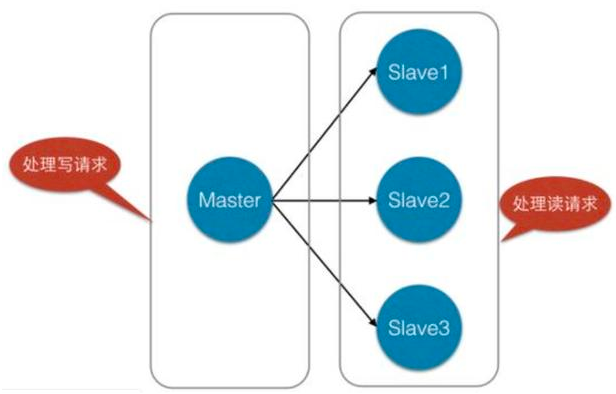
主節點處理寫請求,從節點處理都請求;可以達到讀寫分離、backup等目的,
2.3、哨兵模式
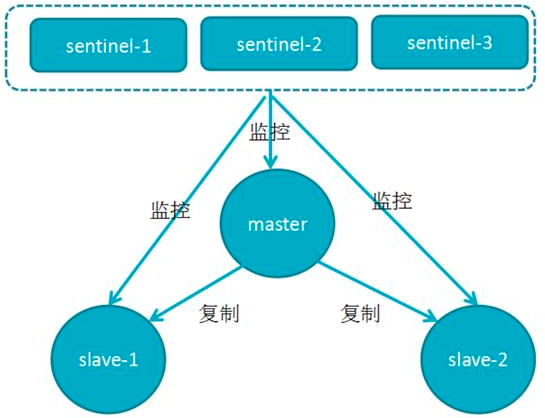
為了保證redis的高可用,哨兵模式在組從模式的基礎上引入哨兵(Sentinel)來管理Redis的主從節點:
1.監控(Monitoring):Sentinel會不斷地檢查你的主服務器和從服務器是否運作正常,
2.提醒(Notification):當被監控的某個Redis服務器出現問題時,Sentinel可以通過API向管理員或者其他應用程式發送通知,
3.自動故障遷移(Automatic failover):當一個主服務器不能正常作業時,Sentinel會開始一次自動故障遷移操作,它會將其中一個從服務器升級為新的主服務器,并讓其他的從服務器改為復制新的主服務器;當客戶端試圖連接失效的主服務器時,集群也會向客戶端回傳新主服務器的地址,使得集群可以使用新主服務器代替失效服務器,
2.3、集群模式(cluster)
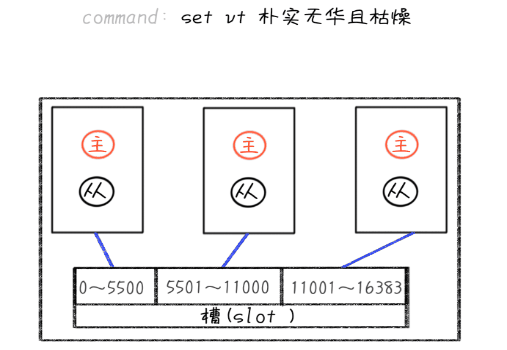
當快取資料量增加以后,無法用單體服務器承載快取服務時,需要把快取的資料切分成不同的磁區,將資料磁區放到不同的服務器中,用分布式的快取來承載高并發的快取訪問,Redis Cluster是官方在3.0版本后推出的分布式方案,
Redis Cluster 采用虛擬槽磁區演算法來對資料進行拆分,槽是用來存放快取資訊的單位,在Redis中將存盤空間分成了16384個槽,也就是說Redis Cluster槽的范圍是0 -16383(2^4 * 2^10),快取資訊通常是用Key-Value的方式來存放的,在存盤資訊的時候,集群會對Key進行CRC16校驗并對16384取模(slot=CRC16(key)%16383),得到的結果就是Key-Value所放入的槽,從而實作自動分割資料到不同的節點上,然后再將這些槽分配到不同的快取節點中保存,
3、持久化
3.1、RDB持久化
RDB持久化是指在指定的時間間隔內將記憶體中的資料集快照寫入磁盤,實際操作程序是fork一個子行程,先將資料集寫入臨時檔案,寫入成功后,再替換之前的檔案,用二進制壓縮存盤,redis.conf中配置如下:
save 900 1 #在900秒(15分鐘)之后,如果至少有1個key發生變化,則dump記憶體快照, save 300 10 #在300秒(5分鐘)之后,如果至少有10個key發生變化,則dump記憶體快照, save 60 10000 #在60秒(1分鐘)之后,如果至少有10000個key發生變化,則dump記憶體快照,
dbfilename dump.rdb #快照檔案名稱
3.2、AOF持久化
AOF持久化以日志的形式記錄服務器所處理的每一個寫、洗掉操作,查詢操作不會記錄,以文本的方式記錄,可以打開檔案看到詳細的操作記錄,redis.conf中配置如下:
appendonly no #是否開啟aof appendfilename "appendonly.aof" #日志檔案名稱 #appendfsync always #每次有資料修改發生時都會寫入AOF檔案 appendfsync everysec #每秒鐘同步一次,該策略為AOF的預設策略 #appendfsync no #從不同步,高效但是資料不會被持久化
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/177279.html
標籤:Java
上一篇:Java生鮮電商平臺-生鮮電商中配送訂單解決方案(小程式/APP)
下一篇:笨方法學python準備作業