一、知識儲備
1、三大核心硬體——CPU,記憶體,硬碟
所有軟體都是運行硬體之上的,與運行軟體相關的三大核心硬體為cpu、記憶體、硬碟
#1、軟體運行前,軟體的代碼及其相關資料都是存放于硬碟中的
#2、任何軟體的啟動都是將資料從硬碟中讀入記憶體,然后cpu從記憶體中取出指令并執行
#3、軟體運行程序中產生的資料最先都是存放于記憶體中的,若想永久保存軟體產生的資料,則需要將資料由記憶體寫入硬碟
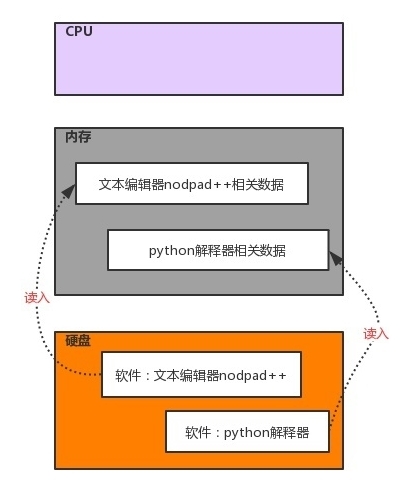
2、文本編輯器讀取檔案內容的流程
#階段1、啟動一個檔案編輯器(文本編輯器如nodepad++,pycharm,word)
#階段2、檔案編輯器會將檔案內容從硬碟讀入記憶體
#階段3、文本編輯器會將剛剛讀入記憶體中的內容顯示到螢屏上
3、Python解釋器執行檔案的流程
以python test.py為例,執行流程如下:
#階段1、啟動python解釋器,此時就相當于啟動了一個文本編輯器
#階段2、python解釋器相當于文本編輯器,從硬碟上將test.py的內容讀入到記憶體中
#階段3、python解釋器解釋執行剛剛讀入的記憶體的內容,開始識別python語法
4、總結—Python解釋器&文本編輯器的異同
#1、相同點:
前兩個階段二者完全一致,都是將硬碟中檔案的內容讀入記憶體,詳解如下 python解釋器是解釋執行檔案內容的,因而python解釋器具備讀py檔案的功能,這一點與文本編輯器一樣
#2、不同點:
在階段3時,針對記憶體中讀入的內容處理方式不同,詳解如下——
文本編輯器將檔案內容讀入記憶體后,是為了顯示或者編輯,根本不去理會python的語法,而python解釋器將檔案內容讀入記憶體后,可不是為了給你瞅一眼python代碼寫的啥,而是為了執行python代碼、會識別python語法)
二、字符編碼
1、什么是字符編碼
人類在與計算機互動時,用的都是人類能讀懂的字符,如中文字符、英文字符、日文字符等 而計算機只能識別二進制數,
解釋如下:
二進制數即由0和1組成的數字,例如 010010101010,
計算機是基于電作業的,電的特性即高低電平,
人類從邏輯層面將高電平對應為數字1,低電平對應為數字0,
這直接決定了計算機可以識別的是由0和1組成的數字
由人類的字符到計算機中的數字,必須經歷一個程序:

翻譯的程序必須參照一個特定的標準,該標準稱之為字符編碼表,
該表上存放的就是字符與數字一 一對應的關系,
字符編碼中的編碼指的是翻譯或者轉換的意思,即將人能理解的字符翻譯成計算機能識別的數字
2、字符編碼表的發展史 (了解)
字符編碼的發展經歷了三個重要的階段——
2.1 階段一:一枝獨秀——ASCII(american standard code for information interchange,美國資訊交換標準代碼)
現代計算機起源于美國,所以最先考慮僅僅是讓計算機識別英文字符,于是誕生了ascii表
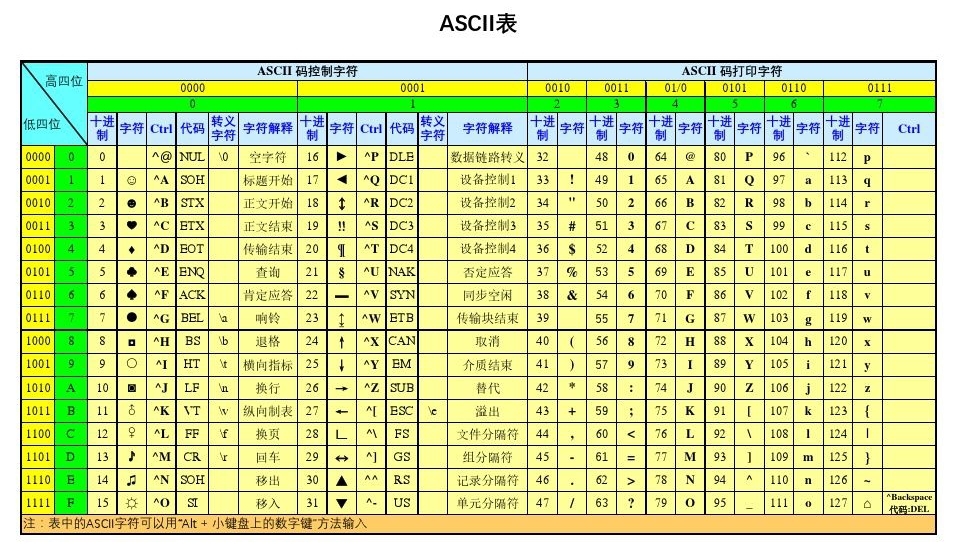
ascii第一次以規范標準的型別發表是在1967年,最后一次更新則是在1986年,共定義了128個字符,
# ascii表的特點: 1、只有英文字符與數字的一一對應關系 2、一個英文字符對應1bytes,1bytes=8bit,8bit最多包含256個數字, 可以對應256個字符,足夠表示所有英文字符
2.2 階段二:百花齊放,百家爭鳴——GBK,Shift_JIS,Euc-kr
為了讓計算機能夠識別中文和英文,中國人定制了GBK
# gbk表的特點:
1、只有中文字符、英文字符與數字的一一對應關系
2、一個英文字符對應1bytes 一個中文字符對應2bytes
補充說明:
1bytes=8bit,8bit最多包含256個數字,可以對應256個字符,足夠表示所有英文字符
2bytes=16bit,16bit最多包含65536個數字,可以對應65536個字符,足夠表示所有中文字符
每個國家都各自的字符,為讓計算機能夠識別自己國家的字符外加英文字符,各個國家都制定了自己的字符編碼表:
# 日本——Shift_JIS表的特點:
1、只有日文字符、英文字符與數字的一一對應關系
# 韓國——Euc-kr表的特點:
1、只有韓文字符、英文字符與數字的一一對應關系
此時——
美國人用的計算機里使用字符編碼標準是ascii、
中國人用的計算機里使用字符編碼標準是gbk、
日本人用的計算機里使用字符編碼標準是shift_jis,如下圖所示:
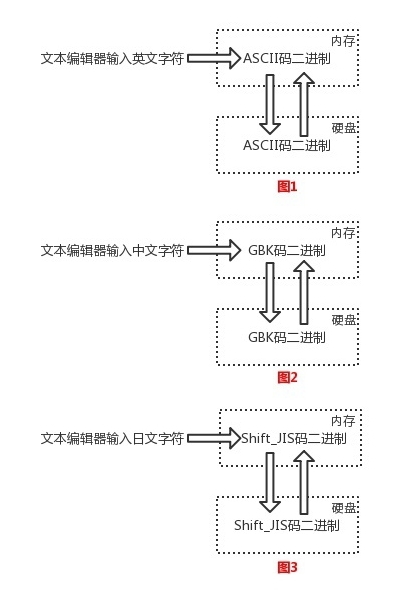
文本編輯存取檔案的原理如下:
文本檔案內容全都為字符,無論存取都是涉及到字符編碼問題 #1、存文本檔案 人類通過文本編輯器輸入的字符會被轉化成ASCII格式的二進制存放于記憶體中,如果需要永久保存,則直接將記憶體中的ASCII格式的二進制寫入硬碟 #2、讀文本檔案 直接將硬碟中的ASCII格式的二進制讀入記憶體,然后通過ASCII表反解成英文字符
不同國家的字符編碼標準不同,只支持本國語言以及英文,但是若一臺美國電腦想要存盤日文檔案,就無法識別,出現亂碼,
2.3 階段三:和諧統一 ——unicode
unicode碼擴展自ascii字元集,是一個編碼方案,unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一并且唯一的二進制編碼,以滿足跨語言、跨平臺進行文本轉換、處理的要求,
unicode 編碼共有三種具體實作,分別為utf-8,utf-16,utf-32,其中utf-8占用一到四個位元組,utf-16占用二或四個位元組,utf-32占用四個位元組,unicode 碼在全球范圍的資訊交換領域均有廣泛的應用,
unicode于1990年開始研發,1994年正式公布,具備兩大特點:
#1. 存在所有語言中的所有字符與數字的一一對應關系,即兼容萬國字符
#2. 與傳統的字符編碼的二進制數都有對應關系
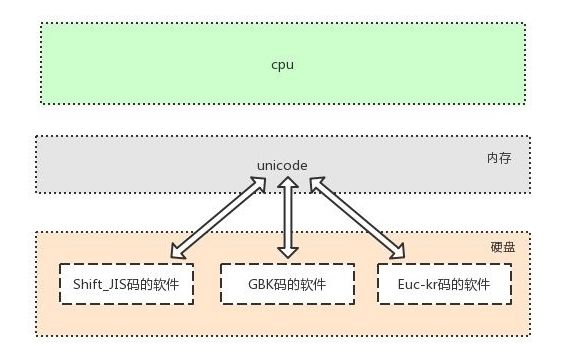
文本編輯器輸入任何字符都是最先存在于記憶體中,使用的是unicode編碼,存放于硬碟中,
則可以轉換成任意其他編碼,只要該編碼可以支持相應的字符,
# 英文字符可以被ascii識別
英文字符--->unciode格式的數字--->ascii格式的數字
# 中文字符、英文字符可以被gbk識別
中文字符、英文字符--->unicode格式的數字--->gbk格式的數字
# 日文字符、英文字符可以被shift-jis識別
日文字符、英文字符--->unicode格式的數字--->shift-jis格式的數字
3、編碼與解碼
3.1 由字符轉換成記憶體中的unicode,以及由unicode轉換成其他編碼的程序,都稱為編碼encode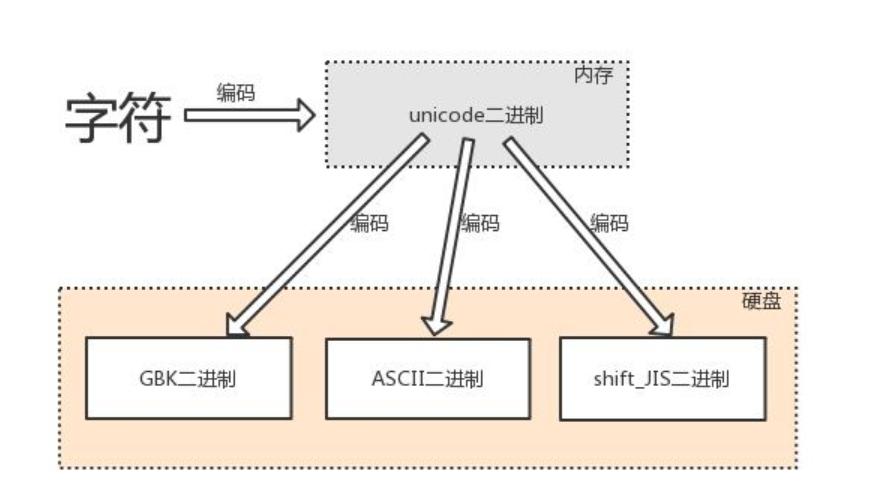
3.2 由記憶體中的unicode轉換成字符,以及由其他編碼轉換成unicode的程序,都稱為解碼decode
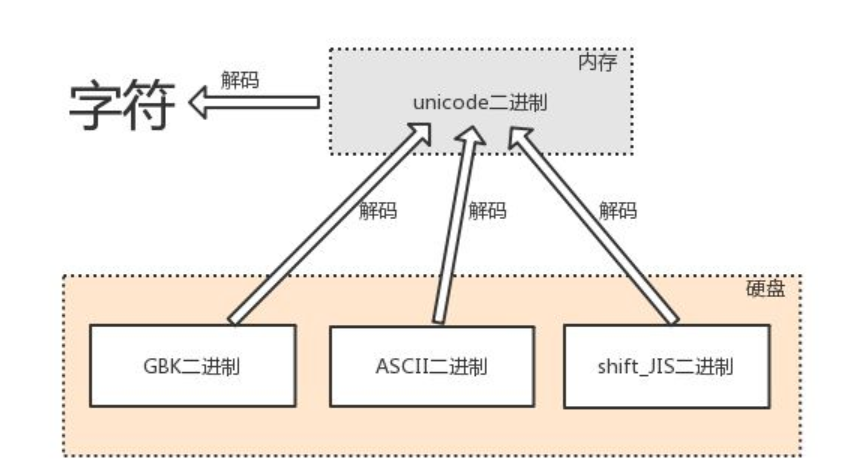
在諸多檔案型別中,只有文本檔案的記憶體是由字符組成的,因而文本檔案的存取也涉及到字符編碼的問題
4、utf-8的由來
如果保存到硬碟的是gbk格式二進制,當初用戶輸入的字符只能是中文或英文,
同理如果保存到硬碟的是shift_jis格式二進制,當初用戶輸入的字符只能是日文或英文
如果是多國字符混雜的檔案,該用什么格式的二進制 存入硬碟呢?

理論上是可以將記憶體中unicode格式的二進制直接存放于硬碟中的,但有兩大缺點——
=1=更費空間
由于unicode固定使用兩個位元組來存盤一個字符,如果多國字符中包含大量的英文字符時,使用unicode格式存放會額外占用一倍空間(英文字符其實只需要用一個位元組存放即可)
=2=更耗時間
空間占用并不是最致命的問題,最致命地是當我們由記憶體寫入硬碟時會額外耗費一倍的時間
所以將記憶體中的unicode二進制寫入硬碟或者基于網路傳輸時必須將其轉換成一種精簡的格式,
這種格式即utf-8(全稱unicode transformation format,即unicode的轉換格式)

那為何在記憶體中不直接使用utf-8呢?
utf-8是針對Unicode的可變長度字符編碼:一個英文字符占1Bytes,一個中文字符占3Bytes,生僻字用更多的Bytes存盤
unicode更像是一個過渡版本,我們新開發的軟體或檔案存入硬碟都采用utf-8格式,
等過去幾十年,所有老編碼的檔案都淘汰掉之后,會出現一個令人開心的場景——
即 硬碟里放的都是utf-8格式,此時unicode便可以退出歷史舞臺,記憶體里也改用utf-8
三、字符編碼的應用
前面一大串的鋪墊,只為了解決這個問題——為了存取字符時不發生亂碼問題
#1、記憶體中固定使用unicode無論輸入任何字符都不會發生亂碼
#2、我們能夠修改的是存/取硬碟的編碼方式,如果編碼設定不正確將會出現亂碼問題,
亂碼問題分為兩種:存亂了,讀亂了
#2.1 存亂了:
如果用戶輸入的內容中包含中文和日文字符,如果單純以shift_jis存,日文可以正常寫入硬碟,而由于中文字符在shift_jis中沒有找到對應關系而導致存亂了
#2.2 讀亂了:
如果硬碟中的資料是shift_jis格式存盤的,采gbk格式讀入記憶體就讀亂了
因此:
#1. 保證存的時候不亂:在由記憶體寫入硬碟時,必須將編碼格式設定為支持所輸入字符的編碼格式
#2. 保證讀的時候不亂:在由硬碟讀入記憶體時,必須采用與寫入硬碟時相同的編碼格式
3.1 文本編輯器nodpad++存取文本檔案
文本編輯器存取的都是文本檔案,而文本檔案中包含的內容全為字符,所以存取文本檔案都涉及到字符編碼的問題,
3.2 python解釋器執行檔案
Python3中,特殊情況比如輸入字串,默認的設定就能保住不亂碼,
第一階段——讀取檔案到硬碟
第二階段——在記憶體里默認直接存為Unicode
第三階段——讀檔案,硬碟里默認使用utf-8存盤,讀取到記憶體后轉為Unicode
但是如果事先指定了存檔案的編碼(比如:gbk),怎么保證第三個階段讀檔案時不亂碼——修改檔案頭,為一開始指定的編碼即可:
#coding:gbk
Python2中,
=保證Python程式前兩個階段不亂碼的方法——
避免讀取檔案亂碼的現象: 先搞清楚 檔案存的時候用的是什么編碼,讀的時候就要用什么編碼,
檔案頭:在檔案開頭宣告存檔案時使用的編碼,讓Python解釋器不要再使用默認的編碼(Python3—默認utf-8;Python2—默認ASCII)來讀檔案,而是用檔案頭宣告的編碼—— 例如,存代碼時,使用的是gbk編碼,則在檔案第一行宣告
#coding:gbk
=保證第三階段不亂碼—— 輸入字串,記得加小u
x=u'上' print(x)
3.3 字串encode編碼與decode解碼的使用
# 1、unicode格式------編碼encode-------->其它編碼格式
>>> x='上' # 在python3在'上'被存成unicode
>>> res=x.encode('utf-8')
>>> res,type(res) # unicode編碼成了utf-8格式,而編碼的結果為bytes型別,可以當作直接當作二進制去使用 (b'\xe4\xb8\x8a', <class 'bytes'>)
# 2、其它編碼格式------解碼decode-------->unicode格式
>>> res.decode('utf-8')
參考資料:
https://zhuanlan.zhihu.com/p/108805502
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/178319.html
標籤:Python