@
目錄- 資料結構
- quicklist
- quicklistNode
- quicklist的操作
- 創建
- 頭插和尾插
- 特定位置插入
- 資料洗掉
- 其他API
- 參考資料
何為quicklist,上次說到ziplist每次變更的時間復雜度都非常高,因為必須要重新生成一個新的ziplist來作為更新后的list,如果一個list非常大且更新頻繁,那就會給redis帶來非常大的負擔,如何既保留ziplist的空間高效性,又能不讓其更新復雜度過高? redis的作者給出的答案就是quicklist,
其實說白了就是把ziplist和普通的雙向鏈表結合起來,每個雙鏈表節點中保存一個ziplist,然后每個ziplist中存一批list中的資料(具體ziplist大小可配置),這樣既可以避免大量鏈表指標帶來的記憶體消耗,也可以避免ziplist更新導致的大量性能損耗,將大的ziplist化整為零,
資料結構
quicklist
一圖勝千言,我們來看下一個實際的quicklist在記憶體中長啥樣,
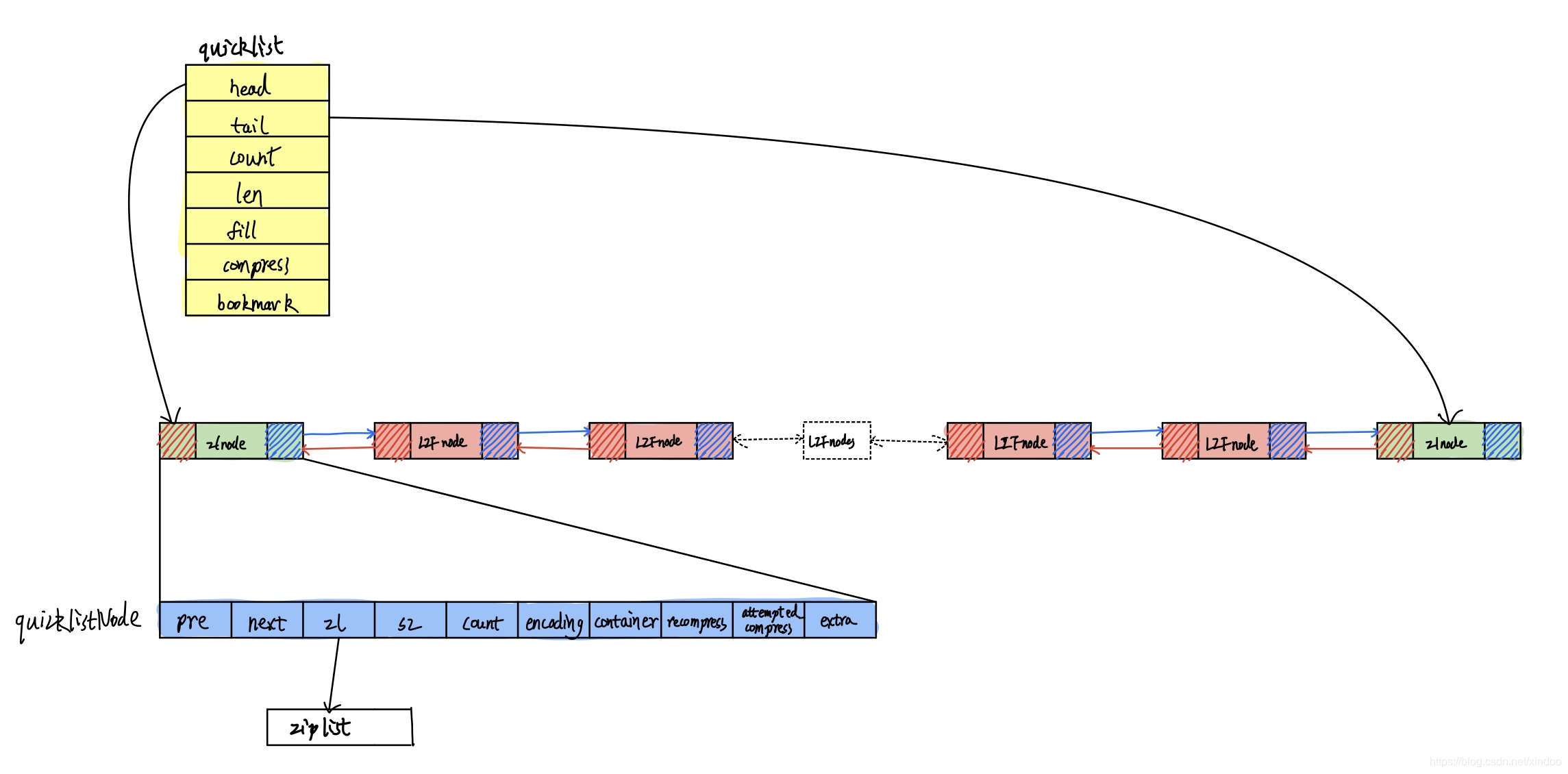
大致介紹下上圖中不同的節點,所有redis中list其實都是quicklist,所以像pop push等命令中的list引數都是quicklist,quicklist各欄位及其含義如下,
typedef struct quicklist {
quicklistNode *head; /* 頭結點 */
quicklistNode *tail; /* 尾結點 */
unsigned long count; /* 在所有的ziplist中的entry總數 */
unsigned long len; /* quicklist節點總數 */
int fill : QL_FILL_BITS; /* 16位,每個節點的最大容量 */
unsigned int compress : QL_COMP_BITS; /* 16位,quicklist的壓縮深度,0表示所有節點都不壓縮,否則就表示從兩端開始有多少個節點不壓縮 */
unsigned int bookmark_count: QL_BM_BITS; /*4位,bookmarks陣列的大小,bookmarks是一個可選欄位,用來quicklist重新分配記憶體空間時使用,不使用時不占用空間*/
quicklistBookmark bookmarks[];
} quicklist;
可以看出quicklist其實就是簡單的雙鏈表,但這里多出來幾個欄位,先重點介紹下compress,在上圖中我用了兩種不同顏色的節點,其中綠色是普通的ziplist節點,而紅色是被壓縮后的ziplist節點(LZF節點),LZF是種無損壓縮演算法,redis為了節省記憶體空間,會將quicklist的節點用LZF壓縮后存盤,但這里不是全部壓縮,可以配置compress的值,compress為0表示所有節點都不壓縮,否則就表示從兩端開始有多少個節點不壓縮,像我上圖圖示中,compress就是1,表示從兩端開始,有1個節點不做LZF壓縮,**compress默認是0(不壓縮),具體可以根據你們業務實際使用場景去配置, **
為什么不全部節點都壓縮,而是流出compress這個可配置的口子呢?其實從統計而已,list兩端的資料變更最為頻繁,像lpush,rpush,lpop,rpop等命令都是在兩端操作,如果頻繁壓碩訓解壓碩訓代碼不必要的性能損耗,從這里可以看出 redis其實并不是一味追求性能,它也在努力減少存盤占用、在存盤和性能之間做trade-off,
這里還有個fill欄位,它的含義是每個quicknode的節點最大容量,不同的數值有不同的含義,默認是-2,當然也可以配置為其他數值,具體數值含義如下:
- -1: 每個quicklistNode節點的ziplist所占位元組數不能超過4kb,(建議配置)
- -2: 每個quicklistNode節點的ziplist所占位元組數不能超過8kb,(默認配置&建議配置)
- -3: 每個quicklistNode節點的ziplist所占位元組數不能超過16kb,
- -4: 每個quicklistNode節點的ziplist所占位元組數不能超過32kb,
- -5: 每個quicklistNode節點的ziplist所占位元組數不能超過64kb,
- 任意正數: 表示:ziplist結構所最多包含的entry個數,最大為215215,
quicklistNode
quicklistNode就是雙鏈表的節點封裝了,除了前后節點的指標外,這里還包含一些本節點的其他資訊,比如是否是LZF壓縮的節點、ziplist相關資訊…… 具體如下:
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; /* quicklist節點對應的ziplist */
unsigned int sz; /* ziplist的位元組數 */
unsigned int count : 16; /* ziplist的item數*/
unsigned int encoding : 2; /* 資料型別,RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* 這個節點以前壓縮過嗎? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* 未使用到的10位 */
} quicklistNode;
從上文中我們已經了解了一個quicklist某個時刻在記憶體中的樣子,接下我們來看下它是如何在資料插入洗掉時變化的,
quicklist的操作
創建
/* 創建一個新的quicklist.
* 使用quicklistRelease()釋放quicklist. */
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
quicklist->bookmark_count = 0;
return quicklist;
}
create就沒啥好說的了,但這里需要提醒下,fill值默認是-2,也就是說每個quicklistNode中的ziplist最長是8k位元組,可以更具自己業務需求調整具體配置,
頭插和尾插
對于list而已,頭部或者尾部插入是最常見的操作了,但其實頭插和尾插還算是比較簡單,
/* 在quicklist的頭部插入一條資料
* 如果在已存在節點插入,回傳0
* 如果是在新的頭結點插入,回傳1 */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD); // 在頭結點對應的ziplist中插入
quicklistNodeUpdateSz(quicklist->head);
} else { // 否則新建一個頭結點,然后插入資料
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/* 在quicklist的尾部插入一條資料
* 如果在已存在節點插入,回傳0
* 如果是在新的頭結點插入,回傳1 */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
頭插和尾插都呼叫了_quicklistNodeAllowInsert先判斷了是否能直接在當前頭|尾節點能插入,如果能就直接插入到對應的ziplist里,否則就需要新建一個新節點再操作了, 還記得上文中我們說的fill欄位嗎,_quicklistNodeAllowInsert其實就是根據fill的具體值來判斷是否已經超過最大容量,
特定位置插入
頭插尾插比較簡單,但quicklist在非頭尾插入就比較繁瑣了,因為需要考慮到插入位置、前節點、后節點的存盤情況,
/* 在一個已經存在的entry前面或者后面插入一個新的entry
* 如果after==1表示插入到后面,否則是插入到前面 */
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node;
quicklistNode *new_node = NULL;
if (!node) {
/* 如果entry中未填node,則重新創建一個node并插入到quicklist中 */
D("No node given!");
new_node = quicklistCreateNode();
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
__quicklistInsertNode(quicklist, NULL, new_node, after);
new_node->count++;
quicklist->count++;
return;
}
/* 檢查要插入的節點是否是滿的 */
if (!_quicklistNodeAllowInsert(node, fill, sz)) {
D("Current node is full with count %d with requested fill %lu",
node->count, fill);
full = 1;
}
if (after && (entry->offset == node->count)) {
D("At Tail of current ziplist");
at_tail = 1;
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {
D("Next node is full too.");
full_next = 1;
}
}
if (!after && (entry->offset == 0)) {
D("At Head");
at_head = 1;
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) {
D("Prev node is full too.");
full_prev = 1;
}
}
/* 不確定把新元素插到哪 */
if (!full && after) { // 如果當前節點不滿,就直接插入
D("Not full, inserting after current position.");
quicklistDecompressNodeForUse(node);
unsigned char *next = ziplistNext(node->zl, entry->zi);
if (next == NULL) {
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);
} else {
node->zl = ziplistInsert(node->zl, next, value, sz);
}
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (!full && !after) {
D("Not full, inserting before current position.");
quicklistDecompressNodeForUse(node);
node->zl = ziplistInsert(node->zl, entry->zi, value, sz);
node->count++;
quicklistNodeUpdateSz(node);
quicklistRecompressOnly(quicklist, node);
} else if (full && at_tail && node->next && !full_next && after) {
/* 如果當前節點是滿的,要插入的位置是當前節點的尾部,且后一個節點有空間,那就插到后一個節點的頭部,*/
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && at_head && node->prev && !full_prev && !after) {
/* 如果當前節點是滿的,要插入的位置是當前節點的頭部,且前一個節點有空間,那就插到前一個節點的尾部, */
D("Full and head, but prev isn't full, inserting prev node tail");
new_node = node->prev;
quicklistDecompressNodeForUse(new_node);
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
quicklistRecompressOnly(quicklist, new_node);
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
/* 如果當前節點是滿的,前后節點也都是滿的,那就創建一個新的節點插進去 */
D("\tprovisioning new node...");
new_node = quicklistCreateNode();
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
} else if (full) {
/* 否則,當前節點是滿的,我們需要把它分裂成兩個新節點,一般用于插入到當前節點ziplist中間某個位置時 */
D("\tsplitting node...");
quicklistDecompressNodeForUse(node);
new_node = _quicklistSplitNode(node, entry->offset, after);
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL);
new_node->count++;
quicklistNodeUpdateSz(new_node);
__quicklistInsertNode(quicklist, node, new_node, after);
_quicklistMergeNodes(quicklist, node);
}
quicklist->count++;
}
代碼比較長,總結如下:
- 如果當前被插入節點不滿,直接插入,
- 如果當前被插入節點是滿的,要插入的位置是當前節點的尾部,且后一個節點有空間,那就插到后一個節點的頭部,
- 如果當前被插入節點是滿的,要插入的位置是當前節點的頭部,且前一個節點有空間,那就插到前一個節點的尾部,
- 如果當前被插入節點是滿的,前后節點也都是滿的,要插入的位置是當前節點的頭部或者尾部,那就創建一個新的節點插進去,
- 否則,當前節點是滿的,且要插入的位置在當前節點的中間位置,我們需要把當前節點分裂成兩個新節點,然后再插入,
資料洗掉
資料洗掉相對于插入而言應該是反著來的,看完下面的代碼后你就會發現不完全是:
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {
quicklistNode *prev = entry->node->prev;
quicklistNode *next = entry->node->next;
int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,
entry->node, &entry->zi);
/* after delete, the zi is now invalid for any future usage. */
iter->zi = NULL;
/* If current node is deleted, we must update iterator node and offset. */
if (deleted_node) {
if (iter->direction == AL_START_HEAD) {
iter->current = next;
iter->offset = 0;
} else if (iter->direction == AL_START_TAIL) {
iter->current = prev;
iter->offset = -1;
}
}
}
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p) {
int gone = 0;
node->zl = ziplistDelete(node->zl, p);
node->count--;
if (node->count == 0) {
gone = 1;
__quicklistDelNode(quicklist, node);
} else {
quicklistNodeUpdateSz(node);
}
quicklist->count--;
/* If we deleted the node, the original node is no longer valid */
return gone ? 1 : 0;
}
洗掉相對于插入而言簡單多了,我先看的插入邏輯,插入中有節點的分裂,但洗掉里卻沒有節點的合并,quicklist有節點最大容量,但沒有最小容量限制,
其他API
理解了quicklist資料結構的設計,也基本就能猜測到每個api的具體實作了,這里我就不再羅列代碼了,有興趣可以自行查閱,
quicklist *quicklistCreate(void); // 創建quicklist
quicklist *quicklistNew(int fill, int compress); // 用一些指定引數創建一個新的quicklist
void quicklistSetCompressDepth(quicklist *quicklist, int depth); // 設定壓縮深度
void quicklistSetFill(quicklist *quicklist, int fill); // 設定容量上限
void quicklistSetOptions(quicklist *quicklist, int fill, int depth);
void quicklistRelease(quicklist *quicklist); // 釋放quicklist
int quicklistPushHead(quicklist *quicklist, void *value, const size_t sz); // 頭部插入
int quicklistPushTail(quicklist *quicklist, void *value, const size_t sz); // 尾部插入
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where); // 指定頭部或者尾部插入
void quicklistAppendZiplist(quicklist *quicklist, unsigned char *zl); // 把一個ziplist放到quicklist中
quicklist *quicklistAppendValuesFromZiplist(quicklist *quicklist,
unsigned char *zl); // 把ziplist中的所有資料放到quicklist中
quicklist *quicklistCreateFromZiplist(int fill, int compress,
unsigned char *zl); // 從ziplist生成一個quicklist
void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *node,
void *value, const size_t sz);
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *node,
void *value, const size_t sz);
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry); // 資料洗掉
int quicklistReplaceAtIndex(quicklist *quicklist, long index, void *data,
int sz); // 資料替換
int quicklistDelRange(quicklist *quicklist, const long start, const long stop); // 范圍洗掉
quicklistIter *quicklistGetIterator(const quicklist *quicklist, int direction); // 迭代器
quicklistIter *quicklistGetIteratorAtIdx(const quicklist *quicklist,
int direction, const long long idx); // 從指定位置開始的迭代器
int quicklistNext(quicklistIter *iter, quicklistEntry *node); // 迭代器下一個位置
void quicklistReleaseIterator(quicklistIter *iter); // 釋放迭代器
quicklist *quicklistDup(quicklist *orig); // 去重
int quicklistIndex(const quicklist *quicklist, const long long index,
quicklistEntry *entry); // 找到entry的下標索引
void quicklistRewind(quicklist *quicklist, quicklistIter *li);
void quicklistRewindTail(quicklist *quicklist, quicklistIter *li);
void quicklistRotate(quicklist *quicklist); // 選擇quicklist
int quicklistPopCustom(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *sval,
void *(*saver)(unsigned char *data, unsigned int sz));
int quicklistPop(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *slong); // 資料pop
unsigned long quicklistCount(const quicklist *ql);
int quicklistCompare(unsigned char *p1, unsigned char *p2, int p2_len); // 比較大小
size_t quicklistGetLzf(const quicklistNode *node, void **data); // LZF節點
參考資料
- men_wen Redis原始碼剖析和注釋(七)--- 快速串列(quicklist)
- 張鐵蕾 Redis內部資料結構詳解(5)——quicklist
本文是Redis原始碼剖析系列博文,同時也有與之對應的Redis中文注釋版,有想深入學習Redis的同學,歡迎star和關注,
Redis中文注解版倉庫:https://github.com/xindoo/Redis
Redis原始碼剖析專欄:https://zxs.io/s/1h
如果覺得本文對你有用,歡迎一鍵三連,
本文來自https://blog.csdn.net/xindoo
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/179022.html
標籤:其他