1. statistics統計計算
statistics模塊實作了很多常用的統計公式,允許使用Python的各種數值型別(int、float、Decimal和Fraction)來完成高效計算,
1.1 平均值
共支持3種形式的平均值:均值(mean),中值或中位數(median),以及眾數(mode),可以用mean()計算算術平均值,
from statistics import * data = [1, 2, 2, 5, 10, 12] print('{:0.2f}'.format(mean(data)))
對于整數和浮點數,這個函式的回傳值總是float,對于Decimal和Fraction輸入資料,結果與輸入的型別相同,
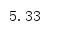
可以使用mode()計算一個資料集中最常見的資料點,
from statistics import * data = [1, 2, 2, 5, 10, 12] print(mode(data))
其回傳值總是輸入資料集的一個成員,由于mode()把輸入處理為一個離散值集合,并且統計出現次數,所以實際上輸入不必是數值,
計算中值(或中位數)有4種變形, 前三種是一般演算法的簡單版本,只是在處理元素個數為偶數的資料集時采用了不同方法,
from statistics import * data = [1, 2, 2, 5, 10, 12] print('median : {:0.2f}'.format(median(data))) print('low : {:0.2f}'.format(median_low(data))) print('high : {:0.2f}'.format(median_high(data)))
median()會查找中間的值,如果資料集包含偶數個值,則取兩個中間元素的平均值,median_low()總是回傳輸入資料集中的一個值,對于有偶數個元素的資料集,會回傳兩個中間元素中較小的一個,median_high()與之類似,不過會回傳兩個中間元素中較大的一個,

中值計算的第4個版本是median_grouped(),它會把輸入看作連續資料,這個函式計算50%百分位數(即中值)的做法是首先是要所提供的間隔寬度找出中值區間,然后使用落入該區間的資料集中的具體值位置在該區間中插值,
from statistics import * data = [10, 20, 30, 40] print('1: {:0.2f}'.format(median_grouped(data, interval=1))) print('2: {:0.2f}'.format(median_grouped(data, interval=2))) print('3: {:0.2f}'.format(median_grouped(data, interval=3)))
隨著間隔寬度的增加,為相同資料集計算的中值會改變,

1.2 方差
統計使用兩個值描述一個值集相對于均值的分散度,方差(variance)是各個值與均值之差平方的平均,標準偏差或標準差(standard deviation)是方差的平方根(這很有用,因為取平方根可以使標準差與輸入資料有相同的單位),如果方差或標準差的值很大,這說明一個資料集是分散的,而如果這個值很小,則說明資料在靠近均值聚集,
import statistics x =[1,2,3,4,5,10,9,8,7,6] y1 = statistics.pvariance(x) print(y1) y2 = statistics.pstdev(x) print(y2) y3 = statistics.variance(x) print(y3) y4 = statistics.stdev(x) print(y4)
Python包括兩組函式來計算方差和標準差,具體取決于資料集是表示總體還是總體中的一個樣本,這個例子首先pvariance()和pstdev()計算總體的方差和標準哈,然后使用variance()和stdev()計算一個子集的樣本方差和標準差,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/179264.html
標籤:Python