0x00前言
大家好,相信點進來看的小伙伴都對爬蟲非常感興趣(絕對不是因為封面 ), 博主也是一樣的, 最近由于疫情的原因,大家都不能出門玩耍,所以博主準備分享一些有趣的學習經歷給大家,
), 博主也是一樣的, 最近由于疫情的原因,大家都不能出門玩耍,所以博主準備分享一些有趣的學習經歷給大家,
昨天,博主逛B站時偶然(非常偶然~)發現了一個不同尋常的教程
揍是下面這個
教程鏈接:
https://www.bilibili.com/video/av75562300?from=search&seid=5460455189191720379
學習完之后,可以說是識訓滿滿啊, 所以今天也給大家安利一下這個教程,順便也整理一下自己學的知識,
0x01準備作業
目標站點:
https://www.vmgirls.com
robots.txt
為了避免不必要的麻煩,在我們開始爬取某個網站時第一個要關注的事情是這個網站有哪些頁面或者哪些資訊允許我們爬取的, 那么我們如何知道網站有哪些東西是可以爬取的呢?
這里我們要了解一個協議---Robots協議
Robots協議(又稱爬蟲協議或者機器人協議)是網站告訴搜索引擎哪些頁面可以抓取,哪些頁面不能抓取,
Robots協議是國際互聯網界通行的道德規范,這也就是說Robots協議是一個行業的潛規則,并不是什么法律規定,
但是遵守這個潛規則能夠讓我們避免很多麻煩,
在這里給大家附一個GITHUB鏈接,這個專案收錄了所有中國大陸爬蟲開發者涉訴與違規相關的新聞、資料與法律法規,
https://github.com/HiddenStrawberry/Crawler_Illegal_Cases_In_China
那么我們如何查看一個網站的Robots協議呢?
要想解決這個問題我們得先知道爬蟲協議是以什么形式存在的,
Robots協議是以一個robots.txt檔案的形式存放在網站的根目錄的,在這個檔案中會明確的標出有哪些頁面或資訊是可以爬取的,
如果網站中不存在這個檔案那么我們可以爬取所有的沒有被口令保護的頁面,
下面是今天我們的目標網站的協議內容
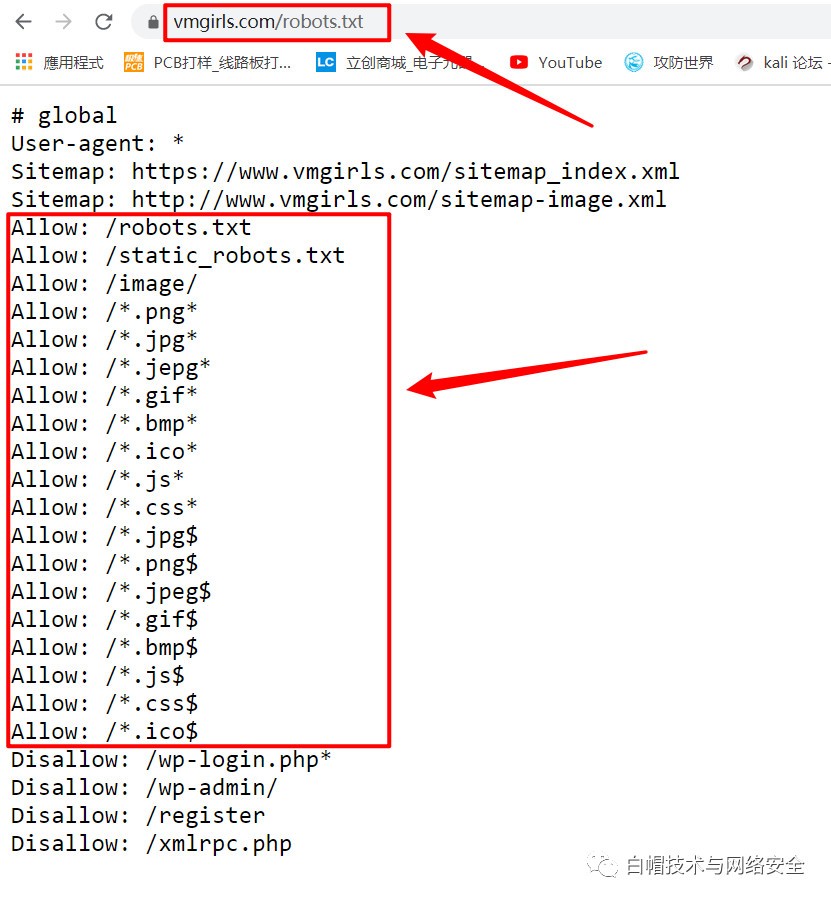
因為我們今天是爬取這個網站的圖片,所以根據這個資訊就可以判斷我們今天的行為是被網站允許的, 所以大家可以放心操作,
0x02頁面下載與決議
排除了法律風險后我們開始正式的作業
第一步 分析目標頁面
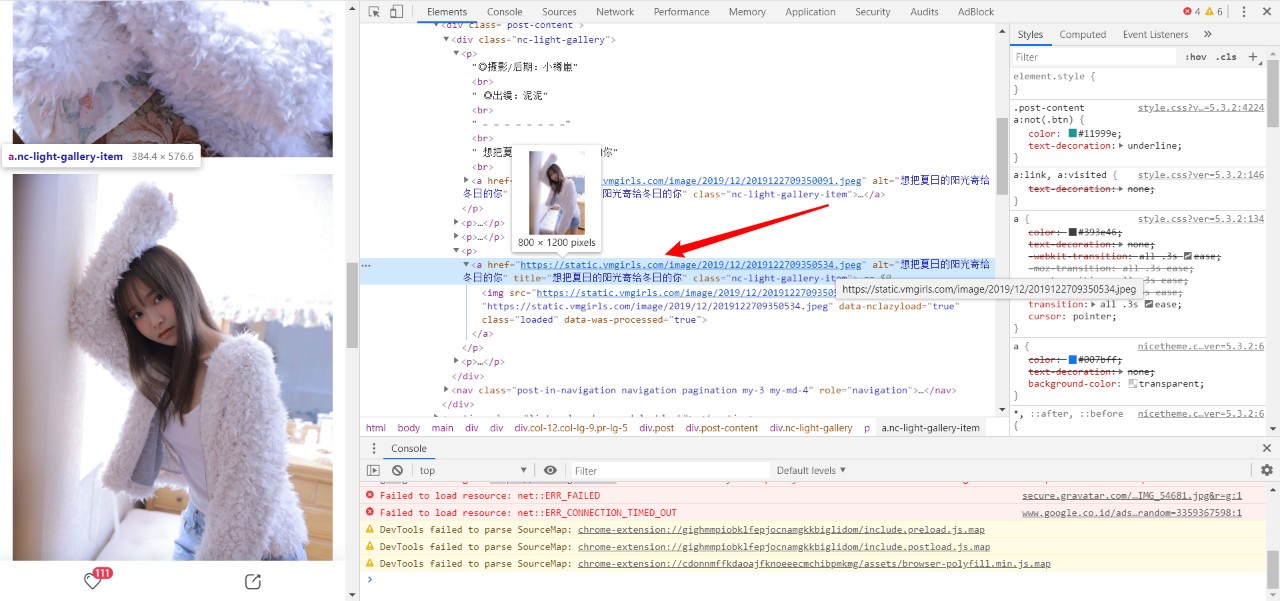
這一步的目的是找到我們要下載圖片的資源鏈接所在的標簽,
打開我們的目標網站后,首先要定位到我們想要爬取的那個頁面, 下面我們以這個頁面為例,


按F12查看網頁的源代碼,找到圖片所在的標簽,復制下來
第二步 下載目標頁面
我們先通過requests模塊把頁面下載下來代碼如下:
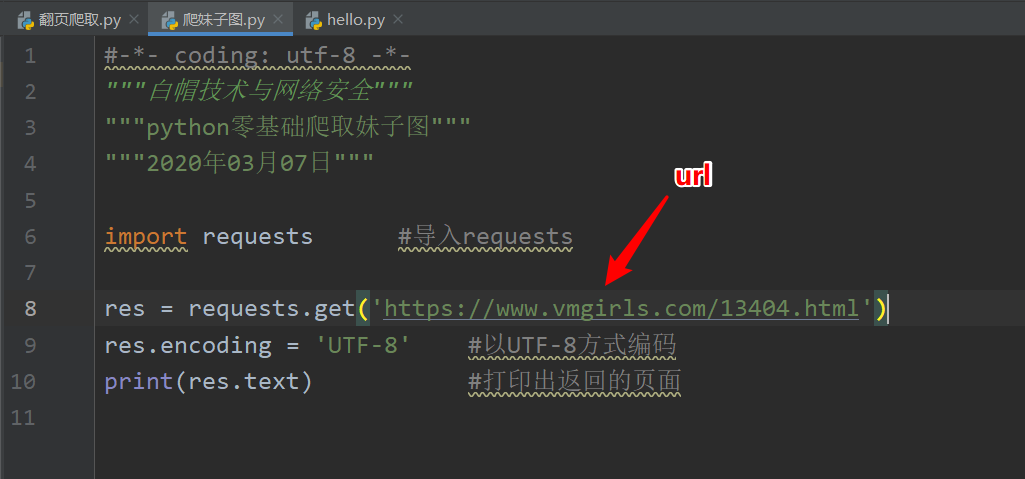
回傳的結果如下:
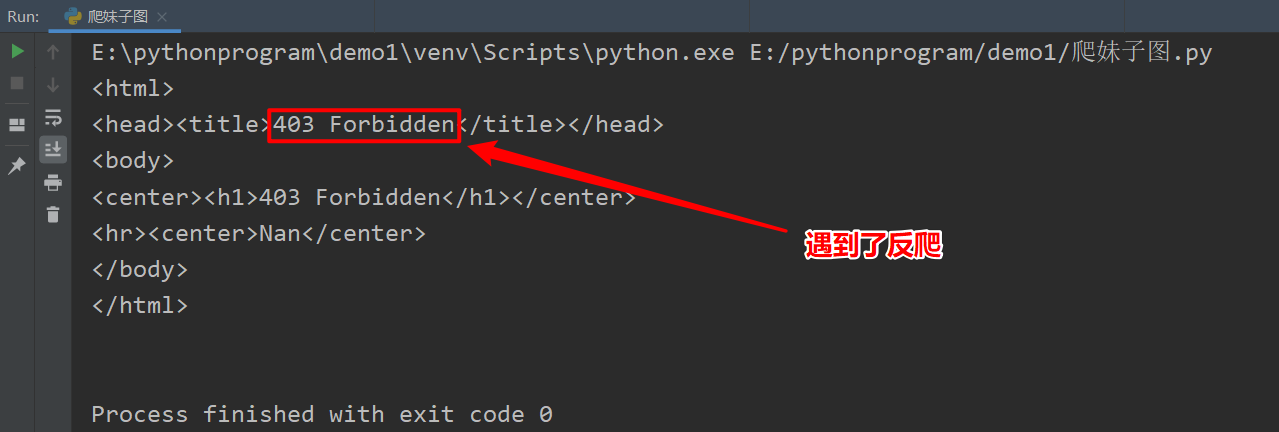
不出意外的網站給我們回傳了403頁面,
這種問題很常見,因為網站檢測到我們是通過python訪問的,所以直接拒絕了我們的訪問,
我們先查看一下請求頭,
代碼如下:
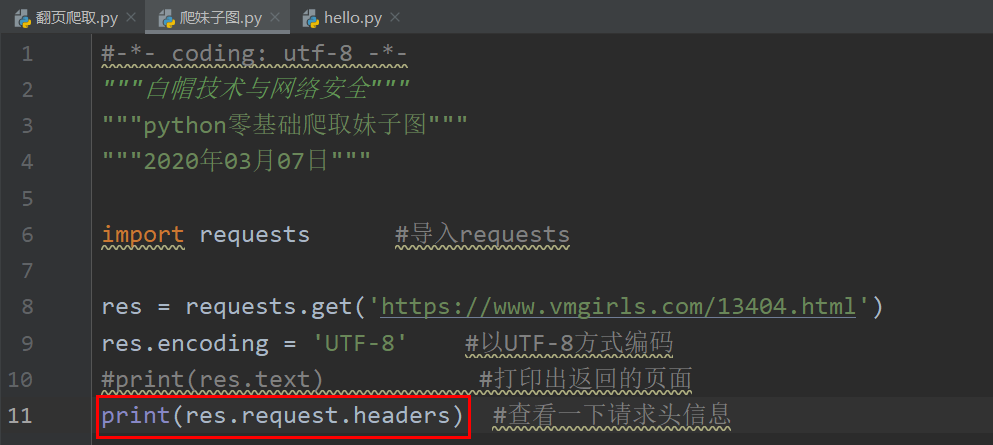
回傳結果:

(不知道這個知識點的可以看我的另一篇文章《一篇有點長的HTTP協議詳解》
鏈接:
https://blog.csdn.net/weixin_46245322/article/details/104416654)
在這里可以看到我們的User-Agent欄位 告訴了人家我們是通過python訪問的, 我的解決方法就是偽造一個User-Agent欄位, 要想偽造我們就得先知道正常訪問請求的User-Agent欄位長啥樣,
具體操作步驟如下:
-
瀏覽器頁面按F12
-
選擇Network欄
-
重繪一下頁面
-
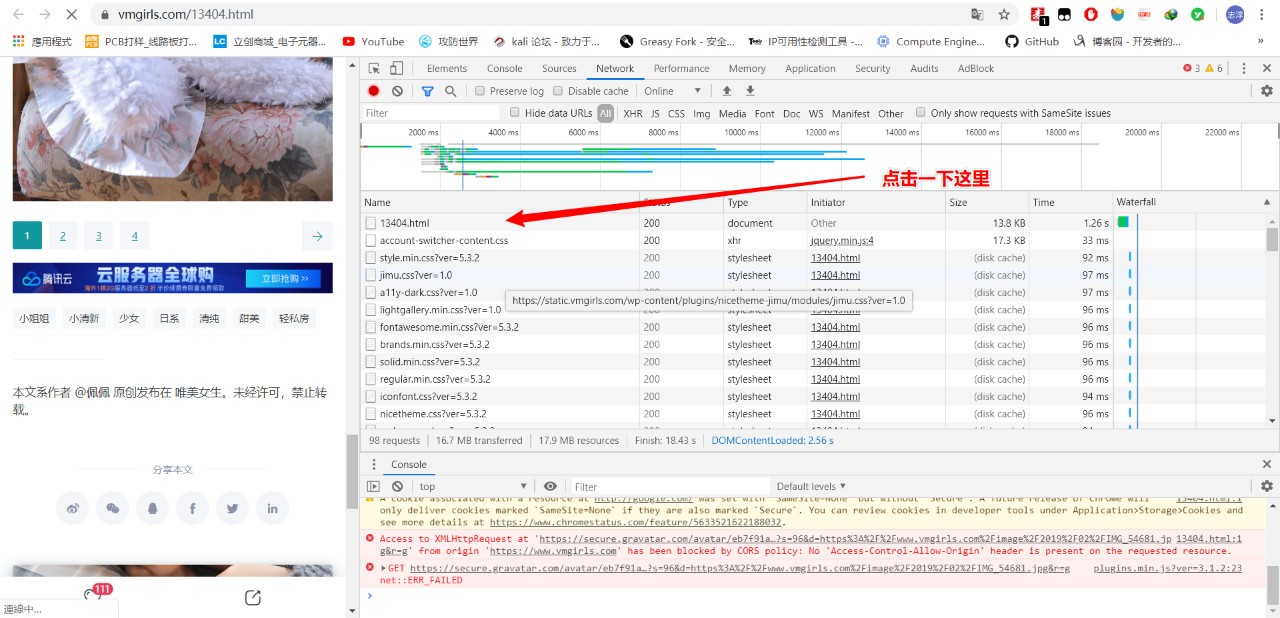
點擊一個HTML檔案
-
在Headers里找到User-Agent欄位的資訊
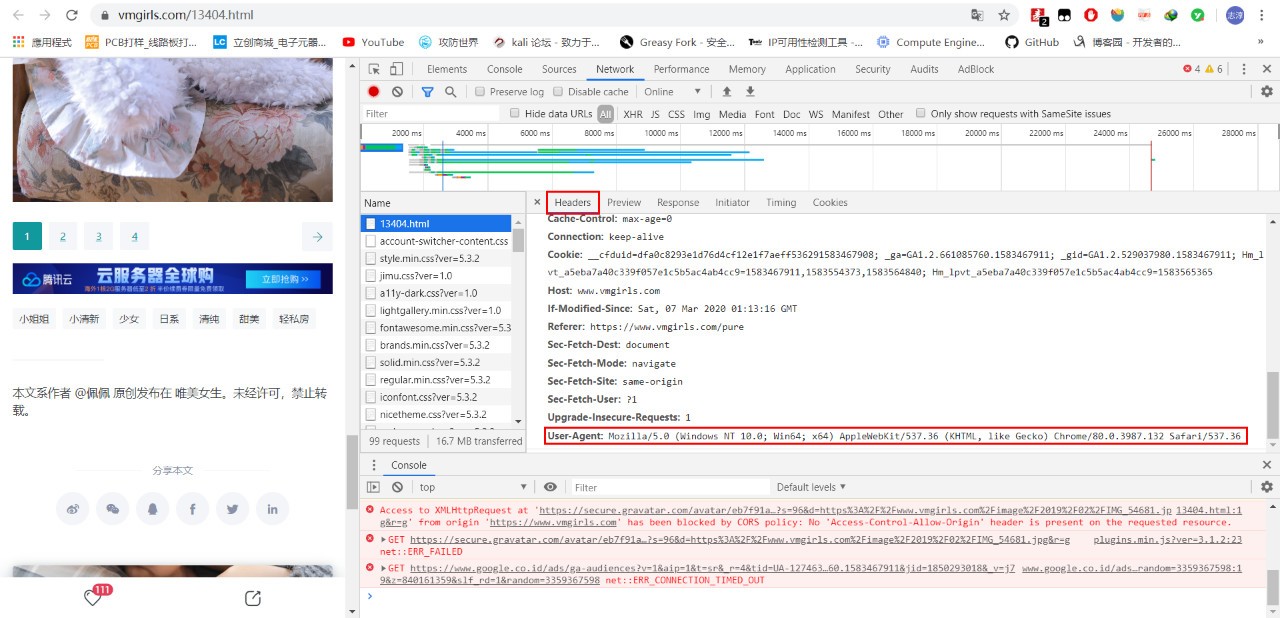
拿到這個資訊后我們再回到我們的代碼中,我們在請求中加入自己偽造的欄位資訊:
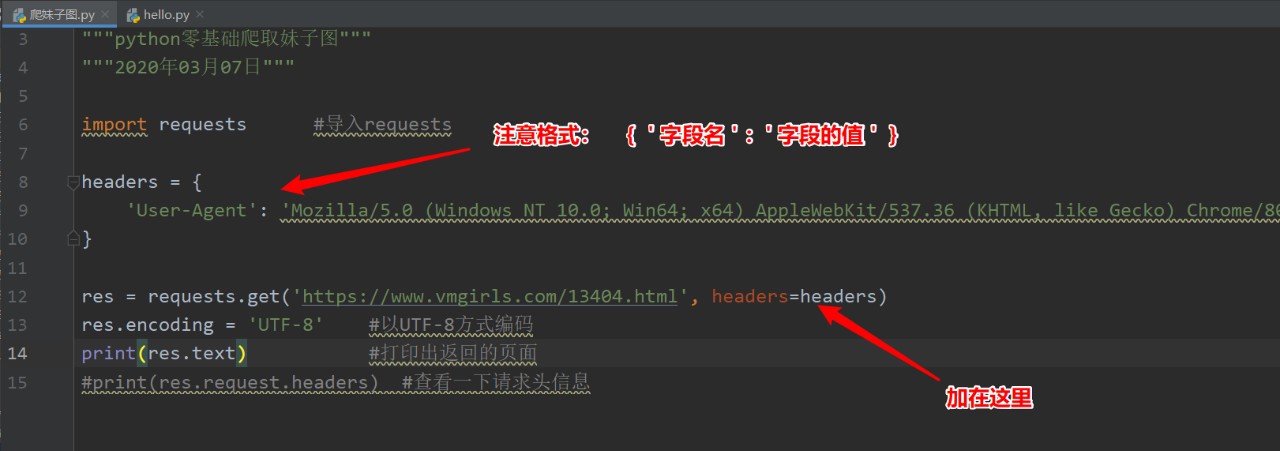
回傳結果:
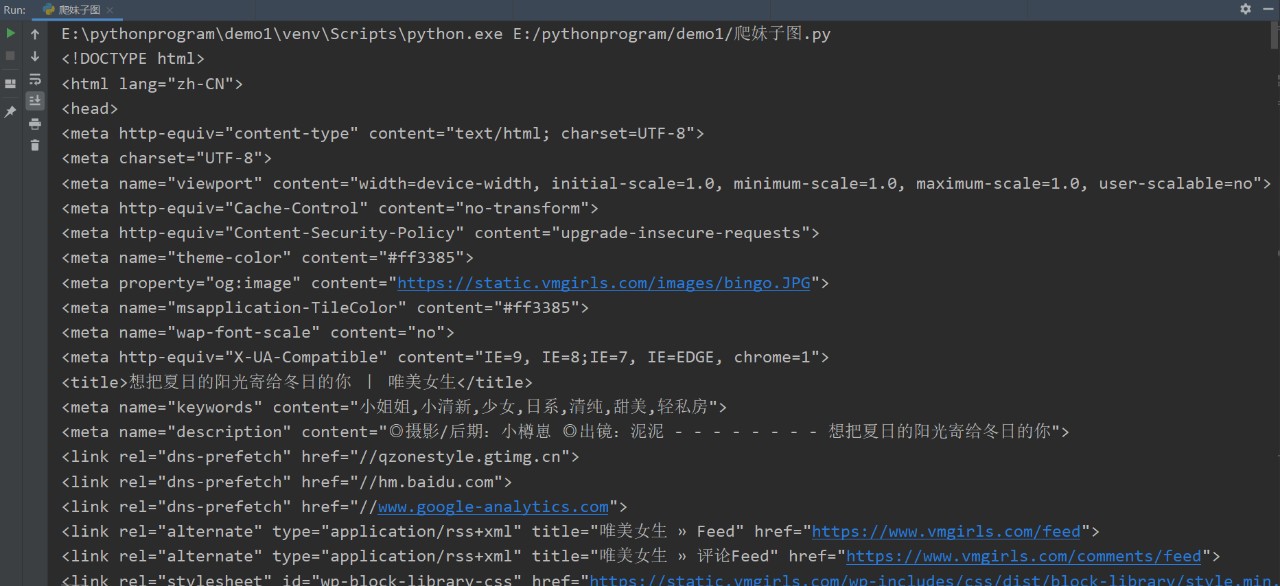
到這里我們已經可以成功把頁面下載下來
第三步正則匹配獲取圖片鏈接
利用re模塊進行正則匹配
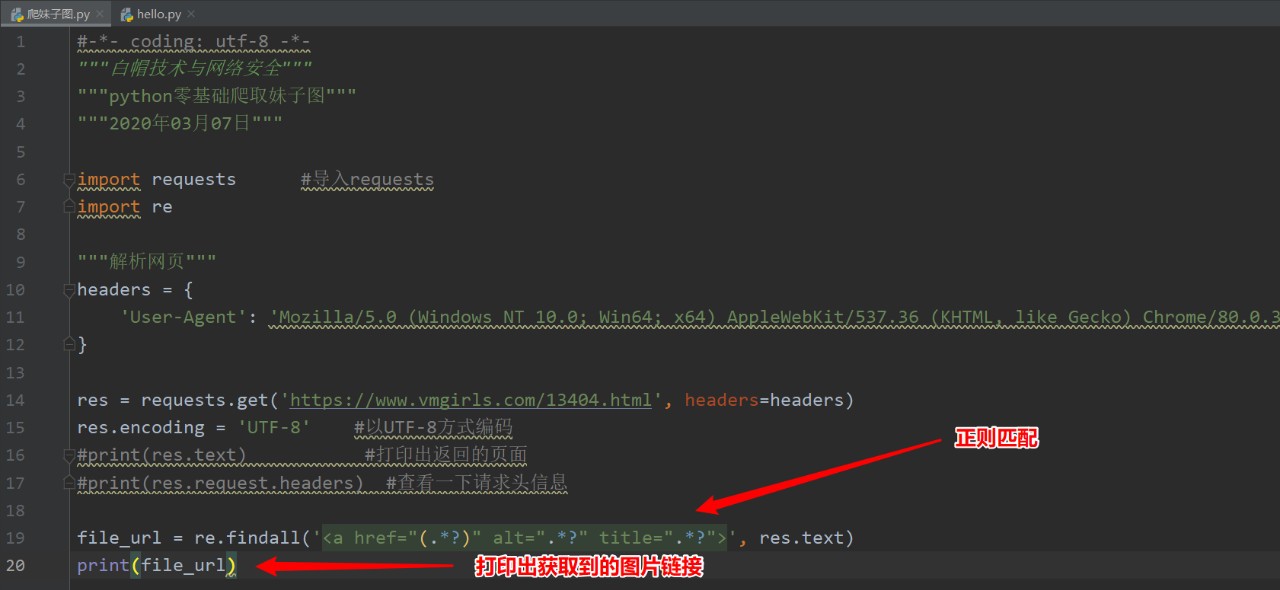
成功獲取到圖片鏈接:

0x03下載小姐姐美圖
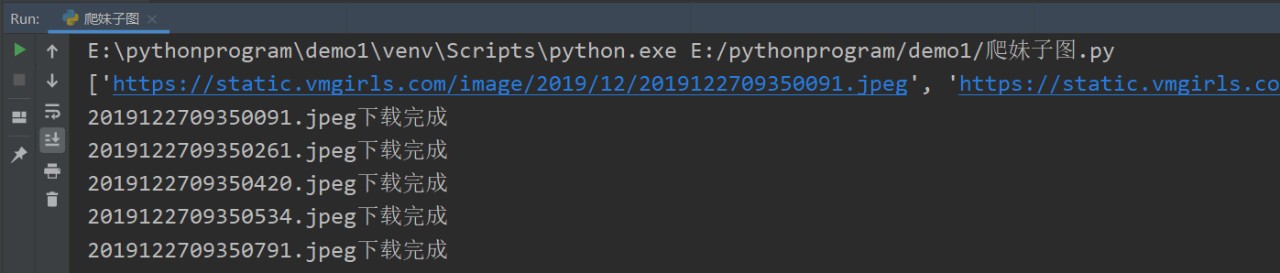
通過以上步驟我們已經可以獲得圖片的鏈接,下面我們就可以著手下載圖片:
這里我們要重點說一下,我們要在回圈里加一個time.sleep(1)函式,加這個函式是防止把網站爬崩潰了,
下載完成
0x04總結
寫到這里我們已經可以
把小姐姐下載下來了,但是這還遠遠不夠,我們現在下載的圖片只是隨意的分布在程式的目錄里,如何實作下載檔案時自動創建檔案夾并把圖片存到里面呢?
并且我們下載的只是當前頁面的圖片,如何實作下載下一頁的檔案呢?
這就有待于小伙伴們自學去解決啦~
0x05代碼
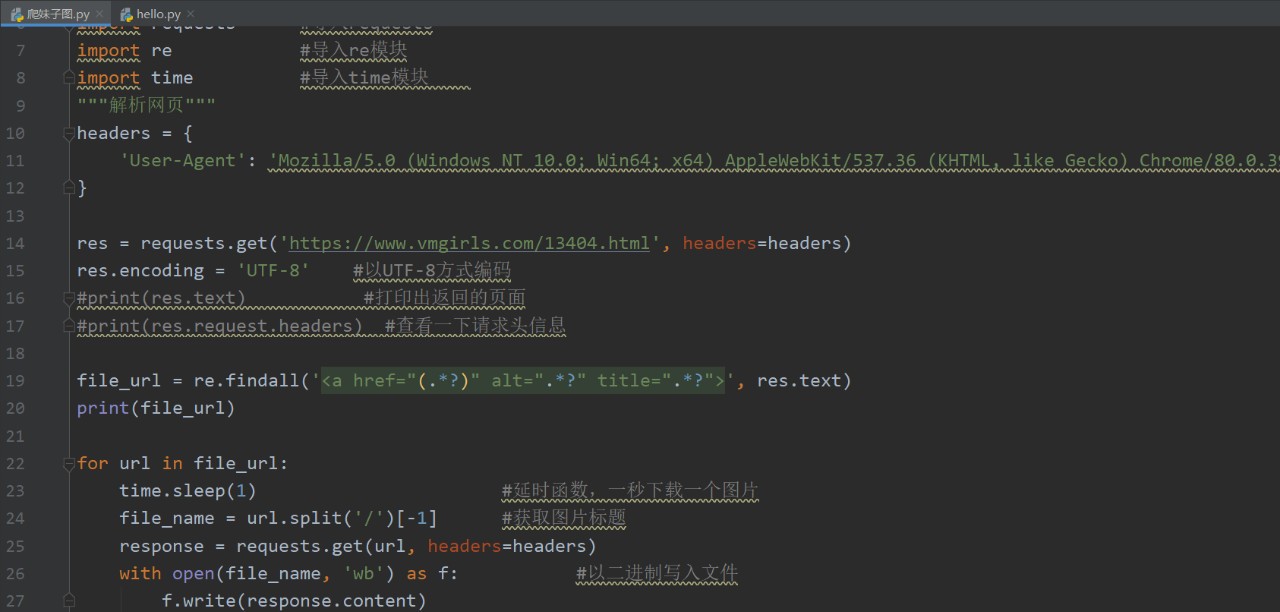
#-*- coding: utf-8 -*- """白帽技術與網路安全""" """python零基礎爬取妹子圖""" """2020年03月07日""" import requests #匯入requests import re #匯入re模塊 import time #匯入time模塊 """決議網頁""" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' } res = requests.get('https://www.vmgirls.com/13404.html', headers=headers) res.encoding = 'UTF-8' #以UTF-8方式編碼 #print(res.text) #列印出回傳的頁面 #print(res.request.headers) #查看一下請求頭資訊 file_url = re.findall('<a href="https://www.cnblogs.com/0pen1/p/(.*?)" alt=".*?" title=".*?">', res.text) print(file_url) for url in file_url: time.sleep(1) #延時函式,一秒下載一個圖片 file_name = url.split('/')[-1] #獲取圖片標題 response = requests.get(url, headers=headers) with open(file_name, 'wb') as f: #以二進制寫入檔案 f.write(response.content) print(file_name+'下載完成')

本作品采用知識共享署名-非商業性使用 4.0 國際許可協議進行許可,
更多技術干貨請關注“白帽技術與網路安全”公眾號,限時免費領取海量視頻教程

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/181242.html
標籤:Python