前面知道NumPy是 Python 語言的一個擴展程式庫,支持大量的維度陣列與矩陣運算,也針對陣列運算提供大量的數學函式庫,numpy是基于c語言開發,所以這使得numpy的運行速度很快,高效率運行就是numpy的一大優勢,但numpy的特長并不是在于資料處理,而是在于能非常方便地實作科學計算,所以對資料進行處理時用的numpy情況并不是很多,因為需要處理的資料一般都是帶有列標簽和index索引的,而numpy并不支持這些,這時就需要pandas了,Pandas的主要作業就是做資料分析,pandas繼承了numpy 我們要使用的是pandas而不是numpy,Pandas是基于Numpy構建的庫,在資料處理方面可以把它理解為numpy加強版 ,
資料分析中:樣本是(行) 特征是(列),
pandas的優缺點,優點:pandas相比于Excel,matlab,tableau等更加的靈活,處理大資料的問題上更加有優勢,讀取excel檔案的時候,pandas更加快,處理速度快,缺點:操控方面相對比較僵硬,pandas當中的函式要清晰使用,statsmodels統計庫(bug百出,官網提供的檔案大部分不友好),scipy高數(stats,使用方法太繁瑣),
pandas的處理速度,為什么不用mysql? 慢:檔案操作慢;pandas:快在于將資料加載到記憶體了,
資料分析使用的庫:numpy作為依賴庫;pandas資料分析庫;matplotlib直觀的資料可視化庫;seaborn輔助庫(庫中含有調色板),圖形更加豐富;pyecharts:簡易的資料可視化庫,電商中比較常用;,,,,
pandas中有兩大資料型別,Series 級數(索引是有序的,一維的);DataFrame 結構化資料(二維的表),
1. Series級數
Series是一種類似一維陣列的資料結構,由一組資料和與之相關的index組成,即由values:一組資料(ndarray型別) 和 key:相關的資料索引標簽兩個部分組成,這個結構一看似乎與dict字典差不多,我們知道字典是一種無序的資料結構,而pandas中的Series的資料結構不一樣,它相當于定長有序的字典,并且它的index和value之間是獨立的,兩者的索引還是有區別的,Series的index是可變的,而dict字典的key值是不可變的,Series是將 序列 和 hash 融合在一起了,序列:索引有序,索引是列舉型別;hash:鍵是無序的,鍵是關聯型別的,pandas中的兩大資料型別都可以使用物件和屬性的方式來獲取值和賦值,在pandas中,string也是object,

Series的創建 :
可由串列或numpy陣列創建:默認索引為0到N-1的整數型索引,(list,tuple,dict,ndarry)強制轉換為Series型別 ,
1 # 由串列創建,默認索引為0到4的整數型索引 2 s0 = Series([1,2,3,4,5]) 3 s0[1] # 2
4 # 由numpy陣列創建 5 s1 = Series(np.array(list('ABCD'))) 6 7 # 由字典(hash)創建,字典的key會被Series當作是index 8 s2 = Series({'A':1,"B":2,"C":3}) 9 10 # 通過設定index引數指定索引 --> {a:甲,b:乙,c:} 11 s3 = Series(data=https://www.cnblogs.com/bonheur/p/list('甲乙丙丁'),index=list('abcd'))
Series的索引和切片:
1). 常規索引:可以使用中括號取單個索引(此時回傳的是元素型別),或者中括號里一個串列取多個索引(此時回傳的仍然是一個Series型別),
2). 顯式索引:
- 使用index中的關聯型別作為索引值;- 使用.loc[](推薦),可以理解為pandas是ndarray的升級版,但是Series也是dict的升級版
3). 隱式索引:
- 使用整數作為索引值;- 使用.iloc[](推薦)
1 # 常規索引 2 s3[0] # ‘甲’ 3 s3['a'] # ‘甲’? 4 5 # 顯式索引 6 s3.loc['a'] # ‘甲’ 7 ? 8 # 隱式索引 9 s3.iloc[0] # ‘甲’
4). 切片:
1 # 常規切片,左閉右開 2 s3[0:-1] 3 # a 甲 4 # b 乙 5 # c 丙 6 # Name: username, dtype: object 7 8 # 顯式切片,全閉區間 9 s3.loc['a':'d'] 10 # a 甲 11 # b 乙 12 # c 丙 13 # d 丁 14 # Name: username, dtype: object 15 16 # 隱式切片,左閉右開 17 s3.iloc[0:-1] 18 # a 甲 19 # b 乙 20 # c 丙 21 # Name: username, dtype: object
Series的屬性:
可以把Series看成一個定長的有序字典,
1 ''' 2 ndim:維度 3 shape:形狀 4 size:獲取元素的長度 5 dtype:資料型別 6 index:獲取所有的索引 7 values:獲取所有的值 8 name:獲取名稱 9 head():快速查看Series物件的樣式,獲取前5條資料 10 tail():快速查看Series物件的樣式,獲取最后5條資料 11 '''
代碼演示示例:
1 s3.shape # (4,) 2 s3.size # 4 3 s3.ndim # 1 4 s3.name # 'username' 5 s3.dtype # dtype('O') 表示字串型別 6 s3.index # Index(['a', 'b', 'c', 'd'], dtype='object') 7 s3.keys() # Index(['a', 'b', 'c', 'd'], dtype='object') 8 s3.valuse # array(['甲', '乙', '丙', '丁'], dtype=object) 9 s3.head(n=5) 10 s3.tail(n=5)
檢測缺失資料:
當索引沒有對應的值時,可能出現缺失資料顯示NaN(not a number)的情況,注意:np.NaN != np.NaN;可以使用pd.isnull(),pd.notnull(),或自帶isnull(),notnull()函式檢測缺失資料,
1 # 造一含有NaN值的Series資料 2 s5 = Series(data=https://www.cnblogs.com/bonheur/p/range(4),index=list('abcd')) # NaN是float 3 s5['c'] = np.nan # 將索引c 的值變為nan 4 s5 5 # a 0.0 6 # b 1.0 7 # c NaN 8 # d 3.0 9 # dtype: float64 10 11 # 檢測缺失資料 12 cond = pd.isnull(s5) # 相當于s5.isnull() 13 cond 14 # a False 15 # b False 16 # c True 17 # d False 18 # dtype: bool 19 # 檢查到NaN值之后,將nan值的資料變成 0 20 s5[cond]= 0 21 # a 0.0 22 # b 1.0 23 # c 0.0 24 # d 3.0 25 # dtype: float64 26 27 s5['c'] = np.nan # 將索引c 的值變為nan 28 29 # 檢測缺失資料 30 cond_fa = s5.notnull() # 相當于pd.notnull(s5) 31 cond_fa 32 # a True 33 # b True 34 # c False 35 # d True 36 # dtype: bool 37 # 檢查到NaN值之后,將nan值篩選掉 38 s5[cond_fa] 39 # a 0.0 40 # b 1.0 41 # d 3.0 42 # dtype: float64
Series之間的運算:
NaN+任何值都是NaN,在運算中自動對齊不同索引的資料,如果索引不對應,則補NaN,
1 s5 * 3 2 # a 0.0 3 # b 3.0 4 # c 0.0 5 # d 9.0 6 # dtype: float64 7 8 s6 = Series(range(5),list('bcdef')) 9 10 s5.add(s6) # 相當于 s5+s6 11 # a NaN 12 # b 1.0 13 # c 1.0 14 # d 5.0 15 # e NaN 16 # f NaN 17 # dtype: float64
2. DataFrame
DataFrame是一個【表格型】的資料結構,可以看做是【由Series組成的字典】(共用同一個索引),DataFrame由按一定順序排列的多列資料組成,設計初衷是將Series的使用場景從一維拓展到多維,DataFrame既有行索引,也有列索引,行索引:index;列索引:columns;值:values(numpy的二維陣列),我們的 訓練集(一些二維的資料)都是二維的,那么Series滿足不了這個條件,xy軸,軸上的一點(0,0),DataFrame每一列可以是不同型別的值集合,所以DataFrame你也可以把它視為不同資料型別同一index的Series集合,
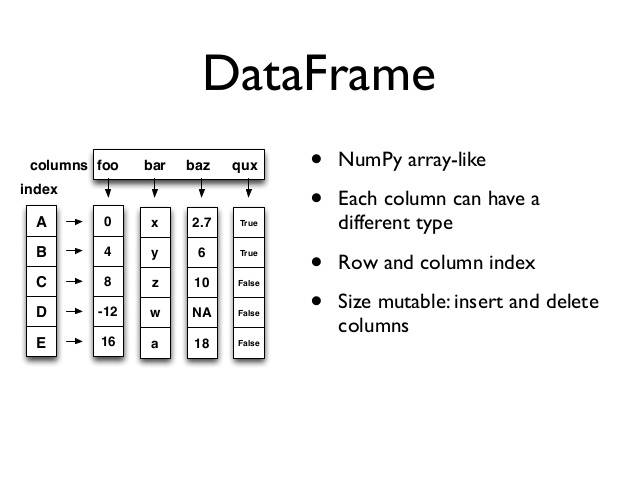
DataFrame的創建:
最常用的方法是傳遞一個字典來創建,DataFrame以字典的鍵作為每一【列】的名稱,以字典的值(一個陣列)作為每一列的值,此外,DataFrame會自動加上每一行的索引(和Series一樣),同Series一樣,若傳入的列與字典的鍵不匹配,則相應的值為NaN,
1 df1 = DataFrame(data=https://www.cnblogs.com/bonheur/p/{'數學':[10,20,30,40,50], 2 '語文':[1,2,3,4,5], 3 '英語':[10,11,12,13,14]}, 4 index=['Tom','Jhon','Jack','Marry','Jurray'], 5 columns=['英語','數學','語文']) 6
# 英語 數學 語文 7 # Tom 10 10 1 8 # Jhon 11 20 2 9 # Jack 12 30 3 10 # Marry 13 40 4 11 # Jurray 14 50 5
DataFrame屬性:
values、columns、index、shape、ndim、dtypes,
1 # 行索引 2 df1.index # Index(['雷軍', '不知妻美', '不知爹富', '馬云', '羅太軍'], dtype='object') 3 4 # 列索引 5 df1.columns # Index(['英語', '數學', '語文'], dtype='object') 6 7 df1.dtypes 8 # 英語 int64 9 # 數學 int64 10 # 語文 int64 11 # dtype: object 12 13 df1.size # 15
14 df1.ndim # 2
DataFrame的索引:
1). 對列進行索引(獲取某一列): [ ] 默認只能取列索引,- 通過類似字典的方式;- 通過屬性的方式,可以將DataFrame的列獲取為一個Series,回傳的Series擁有原DataFrame相同的索引,且name屬性也已經設定好了,就是相應的列名,
df1['語文'] ---> 獲取‘語文’列
2). 對行進行索引(獲取某一行):- 使用.loc[]加index來進行行索引;- 使用.iloc[]加整數來進行行索引,同樣回傳一個Series,index為原來的columns,
df1.loc['Tom'] ---> 獲取‘Tom’行
df1.iloc[0] ---> 獲取第0行,等于‘Tom’行
3). 對元素進行索引(獲取某一個元數/值):- 使用列索引;- 使用行索引(iloc[3,1]相當于兩個引數;iloc[[3,3]] 里面的[3,3]看做一個引數);- 使用values屬性(二維numpy陣列)
df1.loc['Tom','英語'] ---> 獲取‘Tom’行,‘英語’列的這個元素的值
df1.iloc[0,0] ---> 獲取第0行,第0列的這個元素的值,和df1.loc['Tom','英語']結果一樣
1 # 對列進行索引, [ ] 默認只能取列索引 2 df1['語文'] # 獲取為一個Series ,相當于【 df1.語文 】 3 # Tom 1 4 # Jhon 2 5 # Jack 3 6 # Marry 4 7 # Jurray 5 8 # Name: 語文, dtype: int64 9 10 df1.語文 # 不建議這樣獲取列 11 df1['Tom'] # 會報錯 12 13 14 # 對行進行索引 15 df1.loc['Tom'] # 顯式loc 16 # 英語 10 17 # 數學 10 18 # 語文 1 19 # Name: Tom, dtype: int64 20 21 df1.iloc[0] # 隱式iloc 22 # 英語 10 23 # 數學 10 24 # 語文 1 25 # Name: Tom, dtype: int64 26 27 # 對元素進行索引 28 df1.loc['Tom','英語'] # 10 29 30 df1.iloc[0,0] # 10
4). 切片操作:
獲取某些行和某些列的值,可以是多個值
1 # 使用行索引顯式loc切片,全閉區間 2 df1.loc['Tom':'Jack'] # 獲取Tom到Jack行的資料,針對行 3 # 英語 數學 語文 4 # Tom 10 10 1 5 # Jhon 11 20 2 6 # Jack 12 30 3 7 8 df1.loc['Tom':'Jack','英語':'數學'] # 獲取Tom到Jack行,英語到數學列的資料 9 # 英語 數學 10 # Tom 10 10 11 # Jhon 11 20 12 # Jack 12 30 13 14 15 # 使用行索引隱式iloc切片,左開右閉 16 df1.iloc[1:2] # 獲取第1行到第2行的資料(不包含第2行),針對行 17 # 英語 數學 語文 18 # Jhon 11 20 2 19 20 df1.iloc[0:2 , 0:2] # 獲取第0行到第2行,第0列到第2列的資料(不包含第2行和第2列) 21 # 英語 數學 22 # Tom 10 10 23 # Jhon 11 20
DataFrame的運算:
Dataframe的運算同Series一樣,
下圖是Python 運算子與pandas操作函式的對應表:

Series與DataFrame之間的運算:
使用pandas操作函式:axis=0:以列為單位操作(引數必須是列),對所有列都有效;axis=1:以行為單位操作(引數必須是行),對所有行都有效,
列方向:df1.add(s) #默認列相加;行方向: (df1.T + s).T,
聚合操作:
所謂的聚合操作:平均數,標準方差,最大值,最小值……
1 df1.sum() # 默認是對列進行操作 2 df1.mean() # 默認是對列進行操作 3 df1.max() # 求列的最大值 4 df1.var() # 樣本方差,表示的資料的波動性 5 df1.std() # 樣本標準差
pandas的拼接操作:
pandas的拼接分為兩種:級聯:pd.concat, pd.append;合并:pd.merge, pd.join,
回顧numpy的級聯:
1 np.concatenate([np.random.randint(0,100,(5,4)),np.random.rand(5,4),np.random.randn(5,4)],axis=1)
1). 簡單級聯:
行合并:pd.concat([df1,df2],axis=0),和np.concatenate一樣,優先增加行數(默認axis=0),注意index在級聯時可以重復,
列合并:pd.concat([df1,df2],axis=1),不建議用,concat它不是聯表查詢,只擅長當union(垂直的 axis=0),水平合并一定不要用,
1 # 垂直的內連接,join='inner' ,會洗掉含有NaN的行或列 2 pd.concat([df1,df2],axis=0,join='inner') # index在級聯時可以重復 3 4 # 水平內連接 5 pd.concat([df1,df2],axis=1,join='inner') 6 7 # 外連接,不匹配的項補NaN 8 pd.concat([df1,df2],axis=0,join='outer') 9 10 # ignore_index=True忽略重復索引 11 pd.concat([df1,df2],axis=0,join='outer',ignore_index=True) 12 13 # 使用多層索引 keys ,解決重復問題 14 pd.concat([df1,df2],axis=0,join='outer',keys=['df1','df2']) 15 # a b c 16 # df1 0 a0 b0 c0 17 # 1 a1 b1 c1 18 # 2 a2 b2 c2 19 # df2 2 a2 b2 c2 20 # 3 a3 b3 c3 21 # 4 a4 b4 c4
2). 不匹配級聯:
不匹配指的是級聯的維度的索引不一致,例如縱向級聯時列索引不一致,橫向級聯時行索引不一致;有3種連接方式:
- 外連接:補NaN(默認模式)
- 內連接:只連接匹配的項
-連接指定軸 join_axes 顯示某一格dataframe 中的列
3).使用append()函式添加:
由于在后面級聯的使用非常普遍,因此有一個函式append專門用于在后面添加,append 和 concat 相似,只能直接做垂直:df1.append(df2)
4). 使用pd.merge()合并:
merge與concat的區別在于,merge需要依據某一共同的行或列來進行合并,使用pd.merge()合并時,會自動根據兩者相同column名稱的那一列,作為key來進行合并,注意每一列元素的順序不要求一致
pd.merge(DataFrame1,DataFrame2, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=(’_x’, ‘_y’))
pd.merge(DataFrame1,DataFrame2) == DataFrame1.merge(DataFrame2)
引數:
how:默認為inner,可設為inner/outer/left/right
on:根據某個欄位進行連接,必須存在于兩個DateFrame中(若未同時存在,則需要分別使用left_on和right_on來設定)
left_on:左連接,以DataFrame1中用作連接鍵的列
right_on:右連接,以DataFrame2中用作連接鍵的列
left_index:將DataFrame1行索參考作連接鍵
right_index:將DataFrame2行索參考作連接鍵
sort:根據連接鍵對合并后的資料進行排列,默認為True
suffixes:對兩個資料集中出現的重復列,新資料集中加上后綴_x,_y進行區別
代碼演示區別:
1 pd.DataFrame({'lkey':['foo','bar','baz','foo'], 'value':[1,2,3,4]}) 2 # lkey value 3 # 0 foo 1 4 # 1 bar 2 5 # 2 baz 3 6 # 3 foo 4 7 8 pd.DataFrame({'rkey':['foo','bar','qux','bar'], 'value':[5,6,7,8]}) 9 # rkey value 10 # 0 foo 5 11 # 1 bar 6 12 # 2 qux 7 13 # 3 bar 8 14 15 # inner鏈接 16 dataDf1.merge(dataDf2, left_on='lkey',right_on='rkey') 17 # lkey value_x rkey value_y 18 # 0 foo 1 foo 5 19 # 1 foo 4 foo 5 20 # 2 bar 2 bar 6 21 # 3 bar 2 bar 8 22 23 # Outer鏈接 24 dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey', how='outer') 25 # lkey value_x rkey value_y 26 # 0 foo 1.0 foo 5.0 27 # 1 foo 4.0 foo 5.0 28 # 2 bar 2.0 bar 6.0 29 # 3 bar 2.0 bar 8.0 30 # 4 baz 3.0 NaN NaN 31 # 5 NaN NaN qux 7.0 32 33 # left鏈接 34 dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey',how='left') 35 # lkey value_x rkey value_y 36 # 0 foo 1 foo 5.0 37 # 1 bar 2 bar 6.0 38 # 2 bar 2 bar 8.0 39 # 3 baz 3 NaN NaN 40 # 4 foo 4 foo 5.0 41
41 # right鏈接 42 dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey',how='right') 43 # lkey value_x rkey value_y 44 # 0 foo 1.0 foo 5 45 # 1 foo 4.0 foo 5 46 # 2 bar 2.0 bar 6 47 # 3 bar 2.0 bar 8 48 # 4 NaN NaN qux 7
【注意】1).當有多個key相同時使用,使用on=顯式指定哪一列為key;當左右兩邊的key都不相等時,使用left_on和right_on指定左右兩邊的列作為key,
2).內合并:只保留兩者都有的key(默認模式);外合并 how='outer':補NaN;左合并、右合并:how='left',how='right',
列沖突的解決:
當列沖突時,即有多個列名稱相同時,需要使用on=來指定哪一個列作為key,配合suffixes指定沖突列名,可以使用suffixes=自己指定后綴,
1 dataDf1.merge(dataDf2, left_on='lkey', right_on='rkey', how='right', suffixes=('_df1', '_df2')) 2 # lkey value_df1 rkey value_df2 3 # 0 foo 1.0 foo 5 4 # 1 foo 4.0 foo 5 5 # 2 bar 2.0 bar 6 6 # 3 bar 2.0 bar 8 7 # 4 NaN NaN qux 7
行重新設定:
Dataframe.set_index('id',inplace=True)
1 dataDf1
2 # lkey value
3 # 0 foo 1
4 # 1 bar 2
5 # 2 baz 3
6 # 3 foo 4
7
8 dataDf1.set_index(['value'],inplace=True) # 將'value'設定為index
9 dataDf1
10 # lkey
11 # value
12 # 1 foo
13 # 2 bar
14 # 3 baz
15 # 4 foo
16
17 dataDf1.reset_index(inplace=True) # 將index回傳回dataframe中
18 dataDf1
19 # value lkey
20 # 0 1 foo
21 # 1 2 bar
22 # 2 3 baz
23 # 3 4 foo
設定缺失值:
df1.loc['Tom','英語'] = np.NaN
df1.loc['Jack','數學'] = np.NaN
pandas 中對于空/缺失值的操作:
空值:在pandas中的空值是 ' ';缺失值:在dataframe中為nan或者naT(缺失時間),在series中為none或者nan即可,
1). DataFrame.isna() / DataFrame.isnull:判斷是不是缺失值,True表示是,False表示不是,
2). DataFrame.notnull(): 判斷是不是缺失值,True表示不是,False表示是,
1 # 構造一個dataframe 2 df = pd.DataFrame([[np.nan, 2, np.nan, 0], 3 [3, 4, "", 1], 4 [np.nan, np.nan, np.nan, 5], 5 [np.nan, 3, "", 4]], 6 columns=list('ABCD')) 7 8 # A B C D 9 # 0 NaN 2.0 NaN 0 10 # 1 3.0 4.0 1 11 # 2 NaN NaN NaN 5 12 # 3 NaN 3.0 4 13 14 # 檢測缺失值(針對所有資料) 15 df.isnull() 16 df.isna() 17 df.notnull() 18 19 # 檢查哪些列有缺失值,含有NaN的列顯示True 20 df.isnull().any() 21 # A True 22 # B True 23 # C True 24 # D False 25 # dtype: bool 26 27 # 統計每列有缺失值的個數 28 df.isnull().sum() 29 # A 3 30 # B 1 31 # C 2 32 # D 0 33 # dtype: int64 34 35 # 查看某列缺失值情況 36 df['A'].isnull()
3). DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False):過濾丟失資料,洗掉含有缺失值的行或列,
axis:維度,axis=0表示index行,axis=1表示columns列,默認為0;
how:"all"表示這一行或列中的元素全部缺失(為nan)才洗掉這一行或列,"any"表示這一行或列中只要有元素缺失,就洗掉這一行或列;
thresh:一行或一列中至少出現了thresh個才洗掉;
subset:在某些列的子集中選擇出現了缺失值的列洗掉,不在子集中的含有缺失值得列或行不會洗掉(有axis決定是行還是列);
inplace:對原資料有影響,默認False,
1 # 默認引數:洗掉行,只要有空值就會洗掉,不替換 2 df.dropna() 3 df.dropna(axis=0, how='any', inplace=False) 4 df.dropna(axis="index", how='any', inplace=False) 5 6 # 洗掉掉全是空值的行,不替換 7 df.dropna(how='all') 8 df.dropna(axis=0, how='all', inplace=False) 9 df.dropna(axis="index", how='all', inplace=False) 10 11 # 洗掉掉全是空值的列,替換 12 df.dropna(axis=1, how='all', inplace=True) 13 df.dropna(axis="columns", how='all', inplace=True) 14 15 # 洗掉掉至少出現過兩個缺失值的行 16 df.dropna(thresh=2) 17 18 # 洗掉這個subset中的含有缺失值的行 19 print df.dropna(subset=['name', 'born'])
4). DataFrame.fillna(value=https://www.cnblogs.com/bonheur/p/None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs):填充缺失值,
value:用于缺失值位置填充的值,可以是單個值,或者字典(key是列名,value是值);
axis:填充維度,從行開始或是從列開始;
method:{'backfill', 'bfill', 'pad', 'ffill', None}, default None,定義了填充空值的方法, pad / ffill表示用前面行/列的值,填充當前行/列的空值,如果axis =1,那么就是橫向的前面的值替換后面的缺失值,如果axis=0,那么則是上面的值替換下面的缺失值,backfill / bfill表示用后面行/列的值,填充當前行/列的空值,缺失值后面的一個值代替前面的缺失值,注意method這個引數不能與value同時出現;
limit:確定填充的個數,如果limit=2,則只填充兩個缺失值,如果method被指定,對于連續的空值,這段連續區域,最多填充前 limit 個空值(如果存在多段連續區域,每段最多填充前 limit 個空值),如果method未被指定, 在該axis下,最多填充前 limit 個空值(不論空值連續區間是否間斷);
downcast:dict, default is None,字典中的項為,為型別向下轉換規則,或者為字串“infer”,此時會在合適的等價型別之間進行向下轉換,比如float64 to int64 if possible,
1 # 橫向用缺失值前面的值替換缺失值 2 df.fillna(axis=1,method='ffill') 3 4 # 縱向用缺失值上面的值替換缺失值 5 df.fillna(axis=0,method='ffill') 6 7 # 所有缺失值填充為10 8 df.fillna(10) 9 10 # 不同的列用不同的值填充 11 values = {'A':0,'B':1,'C':2,'D':3} 12 df.fillna(value=https://www.cnblogs.com/bonheur/p/values) 13 14 # 只將'D'列的缺失值填充為0 15 df.fillna({"D":0})
空值替換:缺失值是NAN,空值是沒有顯示,即' ',替換空值,需要把含有空值的那一列提出來單獨處理,然后在放進去就好,
1 # 1.C列有空值,先把C列的缺失值填充為0 2 df_= df['C'].fillna(0) 3 4 # 2.將C列的空值,即 ' ' 替換成1 5 df_[df_==' '] = 1 6 7 # 3.把填充完成的C列重新放到df中 8 df['C'] = df_
9 # 或者一步到位,將C列的空值,即 ' ' 替換成1
10 df.loc[df['C']=='','C'] = 1
資料分析:洗掉行比較合適,行代表的是一條資料,列會影響到所有的資料,機器學習:如果是行當中的空值比較多那就刪行,列中空值比較多就刪列,
pandas(非空)洗掉操作:
Dataframe.drop(labels=0,axis=0,inplace=True):labels=0表示 第0行 ,inplace=True表示對原資料 產生影響,
1 df1.drop(labels=0,axis=0,inplace=True) # 洗掉第0行 2 df1.drop(0) # 洗掉第0行 3 df1.drop([0,1]) # 洗掉第0,1行
pandas去重操作:
drop_duplicate()方法是對DataFrame格式的資料,去除特定列下面的重復行,回傳DataFrame格式的資料,
data.drop_duplicates(subset=['A','B'],keep='first',inplace=True):
subset : 用來指定特定的列;上面格式中subset對應的值是列名,表示只考慮 'A','B' 兩列,將這兩列對應值相同的行進行去重,默認值為subset=None表示考慮所有列,
keep : {‘first’, ‘last’, False}, default ‘first’,洗掉重復項并保留第一次出現的項
inplace : boolean, default False,是直接在原來資料上修改還是保留一個副本
1 data.duplicated() # 判斷是否是重復的項 2 data.duplicated().sum() # 統計記錄重復數 3 data.drop_duplicates() # 移除重復的項
統計DataFrame中每一列的唯一值,并輸出唯一值的數量
1 df['column'].unique() # 列出該列的唯一值 2 3 df['column'].value_counts() # 統計每個唯一值出現了多少次
pandas資料排序:
1). df.sort_values():既可以根據列資料,也可根據行資料排序,注意必須指定by引數,即必須指定哪幾行或哪幾列;無法根據index名和columns名排序(由.sort_index()執行)
格式:DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默認按照列排序,即縱向排序;如果為1,則是橫向排序,
by:str or list of str;如果axis=0,那么by="列名";如果axis=1,那么by="行名",
ascending:布爾型,True則升序,如果by=['列名1','列名2'],則該引數可以是[True, False],即第一欄位升序,第二個降序,
inplace:布爾型,是否用排序后的資料框替換現有的資料框,
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’,似乎不用太關心,
na_position:{‘first’, ‘last’}, default ‘last’,默認缺失值排在最后面,
1 # 構造dataframe資料 2 df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3]) 3 # b a c 4 # 2 1 4 1 5 # 0 2 3 3 6 # 1 3 2 8 7 # 3 2 1 2 8 9 # 按b列升序排序 10 df.sort_values(by='b') #等同于df.sort_values(by='b',axis=0) 11 # b a c 12 # 2 1 4 1 13 # 0 2 3 3 14 # 3 2 1 2 15 # 1 3 2 8 16 17 # 按行3升序排列 18 df.sort_values(by=3,axis=1) #必須指定axis=1 19 # a b c 20 # 2 4 1 1 21 # 0 3 2 3 22 # 1 2 3 8 23 # 3 1 2 2 24 25 # 先按b列降序,再按a列升序排序 26 df.sort_values(by=['b','a'],axis=0,ascending=[False,True]) 27 # b a c 28 # 1 3 2 8 29 # 3 2 1 2 30 # 0 2 3 3 31 # 2 1 4 1
【注意】指定多列(多行)排序時,先按排在前面的列(行)排序,如果內部有相同資料,再對相同資料內部用下一個列(行)排序,以此類推,如何內部無重復資料,則后續排列不執行,即首先滿足排在前面的引數的排序,再排后面引數,
2). df. sort_index():默認根據行標簽對所有行排序,或根據列標簽對所有列排序,或根據指定某列或某幾列對行排序,注意:df. sort_index()可以完成和df. sort_values()完全相同的功能,但python更推薦用只用df. sort_index()對“根據行標簽”和“根據列標簽”排序,其他排序方式用df.sort_values(),
格式:sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None)
axis:0按照行名排序;1按照列名排序
level:默認None
ascending:默認True升序排列;False降序排列
inplace:默認False,否則排序之后的資料直接替換原來的資料框
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’
na_position:缺失值默認排在最后{"first","last"}
by:按照某一列或幾列資料進行排序
1 # 構造dataframe資料 2 df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3]) 3 # b a c 4 # 2 1 4 1 5 # 0 2 3 3 6 # 1 3 2 8 7 # 3 2 1 2 8 9 # 1.默認按“行標簽”升序排列(推薦) 10 df.sort_index() # 默認按“行標簽”升序排序,或df.sort_index(axis=0, ascending=True) 11 b a c 12 0 2 3 3 13 1 3 2 8 14 2 1 4 1 15 3 2 1 2 16 17 # 2.按“列標簽”升序排列(推薦) 18 df.sort_index(axis=1) # 按“列標簽”升序排序 19 # a b c 20 # 2 4 1 1 21 # 0 3 2 3 22 # 1 2 3 8 23 # 3 1 2 2
資料的簡單保存與讀取:
1 pd.read_csv('test.csv') # 讀取csv檔案 2 3 data.to_csv('test.csv') # 保存csv檔案
補充:基本的統計資料,data. describe() ;data.info(),
pandas‘高級函式’:映射
map:映射 replace:替換值 rename:替換行索引 apply:相同的事情重復做,
代碼演示理解:
1 ''' 2 fillna()填充NaN,只有是nan值的時候 fillna才可以,其他的不行,fillna()只認識nan,下面的 ?? , " "可以用replace:替換值,需要過濾的字符當作key,需要替換成什么寫成val 3 ''' 4 # (1).replace:替換值 5 df = DataFrame({'汽車品牌':['寶馬','奔馳','奧迪','雷車','??'],'游戲機':['小霸王','psp','gameboy','Switch','']}) 6 7 rep = {'??':np.NaN,'':np.NaN} 8 9 df.replace(to_replace=rep).fillna(0) # 替換成0 10 df.replace(to_replace=rep).fillna('國產') # 替換成‘國產’ 11 12 # (2).rename:替換行索引 13 df1 = DataFrame(np.random.randint(0,100,(5,5)),ind1ex=list('東南西北中'),columns=list('金木水火土')) 14 15 rep1 = {'東':'東邪','西':'西毒','南':'南帝','北':'北丐','中':'中神通','東南':'孔雀','西北':'阿寶','西南':'孟獲','東北':'李晶'} 16 17 df1.rename(rep1) # 直接替換(映射) 18 19 df1.T.rename(rep1) # 列能不能替換,可以轉置之后再映射 20 21 # (3).map(function) 逐列進行修改的,所以呼叫的時候都是Series.map() df1['土'].map() Series配合df使用的 22 df1['風'] = df1['土'].map(lambda x : x * 2 -10) # 映射關系:土 × 2 -10 ----> 風 23 24 # 映射關系:風 ----> 山 25 def convert(item): 26 if item <=100: 27 return '垃圾' 28 else: 29 return '大神' 30 df1['山'] = df1['風'].map(convert) 31 32 # (4).transform,和map()比較相似 33 df1['林'] = df1['風'].transform(convert)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/181252.html
標籤:Python