作者:編程迷思
www.importnew.com/25783.html
寫在前面
Java的基類Object提供了一些方法,其中equals()方法用于判斷兩個物件是否相等,hashCode()方法用于計算物件的哈希碼,equals()和hashCode()都不是final方法,都可以被重寫(overwrite),
本文介紹了2種方法在使用和重寫時,一些需要注意的問題,
equal()方法
Object類中equals()方法實作如下:
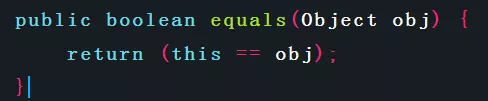
通過該實作可以看出,Object類的實作采用了區分度最高的演算法,即只要兩個物件不是同一個物件,那么equals()一定回傳false,
雖然我們在定義類時,可以重寫equals()方法,但是有一些注意事項;JDK中說明了實作equals()方法應該遵守的約定:
1)自反性:x.equals(x)必須回傳true,
2)對稱性:x.equals(y)與y.equals(x)的回傳值必須相等,
3)傳遞性:x.equals(y)為true,y.equals(z)也為true,那么x.equals(z)必須為true,
4)一致性:如果物件x和y在equals()中使用的資訊都沒有改變,那么x.equals(y)值始終不變,
5)非null:x不是null,y為null,則x.equals(y)必須為false,
hashCode()方法
1、Object的hashCode()

可以看出,hashCode()是一個native方法,而且回傳值型別是整形;實際上,該native方法將物件在記憶體中的地址作為哈希碼回傳,可以保證不同物件的回傳值不同,
與equals()方法類似,hashCode()方法可以被重寫,JDK中對hashCode()方法的作用,以及實作時的注意事項做了說明:
1)hashCode()在哈希表中起作用,如java.util.HashMap,
2)如果物件在equals()中使用的資訊都沒有改變,那么hashCode()值始終不變,
3)如果兩個物件使用equals()方法判斷為相等,則hashCode()方法也應該相等,
4)如果兩個物件使用equals()方法判斷為不相等,則不要求hashCode()也必須不相等;但是開發人員應該認識到,不相等的物件產生不相同的hashCode可以提高哈希表的性能,
2、hashCode()的作用
總的來說,hashCode()在哈希表中起作用,如HashSet、HashMap等,
當我們向哈希表(如HashSet、HashMap等)中添加物件object時,首先呼叫hashCode()方法計算object的哈希碼,通過哈希碼可以直接定位object在哈希表中的位置(一般是哈希碼對哈希表大小取余),如果該位置沒有物件,可以直接將object插入該位置;如果該位置有物件(可能有多個,通過鏈表實作),則呼叫equals()方法比較這些物件與object是否相等,如果相等,則不需要保存object;如果不相等,則將該物件加入到鏈表中,
這也就解釋了為什么equals()相等,則hashCode()必須相等,如果兩個物件equals()相等,則它們在哈希表(如HashSet、HashMap等)中只應該出現一次;如果hashCode()不相等,那么它們會被散列到哈希表的不同位置,哈希表中出現了不止一次,
實際上,在JVM中,加載的物件在記憶體中包括三部分:物件頭、實體資料、填充,其中,物件頭包括指向物件所屬型別的指標和MarkWord,而MarkWord中除了包含物件的GC分代年齡資訊、加鎖狀態資訊外,還包括了物件的hashcode;物件實體資料是物件真正存盤的有效資訊;填充部分僅起到占位符的作用, 原因是HotSpot要求物件起始地址必須是8位元組的整數倍,可以點擊此處查看更多決議JVM記憶體決議,
String中equals()和hashCode()的實作
String類中相關實作代碼如下:

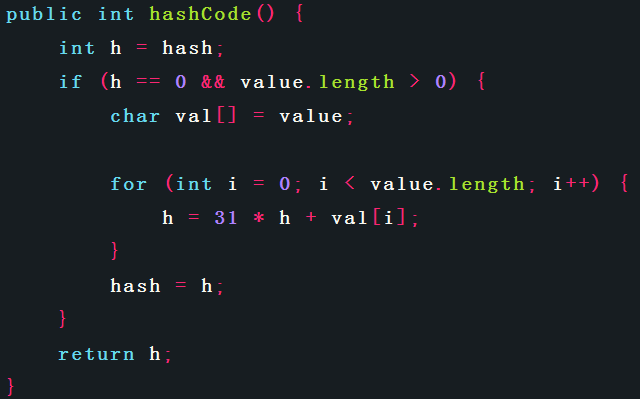
通過代碼可以看出以下幾點:
1、String的資料是final的,即一個String物件一旦創建,便不能修改;形如String s = “hello”; s = “world”;的陳述句,當s = “world”執行時,并不是字串物件的值變為了”world”,而是新建了一個String物件,s參考指向了新物件,
2、String類將hashCode()的結果快取為hash值,提高性能,
3、String物件equals()相等的條件是二者同為String物件,長度相同,且字串值完全相同;不要求二者是同一個物件,
4、String的hashCode()計算公式為:s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
關于hashCode()計算程序中,為什么使用了數字31,主要有以下原因:
1)使用質數計算哈希碼,由于質數的特性,它與其他數字相乘之后,計算結果唯一的概率更大,哈希沖突的概率更小,
2)使用的質數越大,哈希沖突的概率越小,但是計算的速度也越慢;31是哈希沖突和性能的折中,實際上是實驗觀測的結果,
3)JVM會自動對31進行優化:31 * i == (i << 5) – i
如何重寫hashCode()
本節先介紹重寫hashCode()方法應該遵守的原則,再介紹通用的hashCode()重寫方法,
1、重寫hashcode()的原則
通過前面的描述我們知道,重寫hashCode需要遵守以下原則:
1)如果重寫了equals()方法,檢查條件“兩個物件使用equals()方法判斷為相等,則hashCode()方法也應該相等”是否成立,如果不成立,則重寫hashCode ()方法,
2)hashCode()方法不能太過簡單,否則哈希沖突過多,
3)hashCode()方法不能太過復雜,否則計算復雜度過高,影響性能,
2、hashCode()重寫方法
《Effective Java》中提出了一種簡單通用的hashCode演算法
A、初始化一個整形變數,為此變數賦予一個非零的常數值,比如int result = 17;
B、選取equals方法中用于比較的所有域(之所以只選擇equals()中使用的域,是為了保證上述原則的第1條),然后針對每個域的屬性進行計算:
- 如果是boolean值,則計算f ? 1:0;
- 如果是byte\char\short\int,則計算(int)f;
- 如果是long值,則計算(int)(f ^ (f >>> 32));
- 如果是float值,則計算Float.floatToIntBits(f);
- 如果是double值,則計算Double.doubleToLongBits(f),然后回傳的結果是long,再用規則(3)去處理long,得到int;
- 如果是物件應用,如果equals方法中采取遞回呼叫的比較方式,那么hashCode中同樣采取遞回呼叫hashCode的方式,否則需要為這個域計算一個范式,比如當這個域的值為null的時候,那么hashCode 值為0;
- 如果是陣列,那么需要為每個元素當做單獨的域來處理,java.util.Arrays.hashCode方法包含了8種基本型別陣列和參考陣列的hashCode計算,演算法同上,
C、最后,把每個域的散列碼合并到物件的哈希碼中,
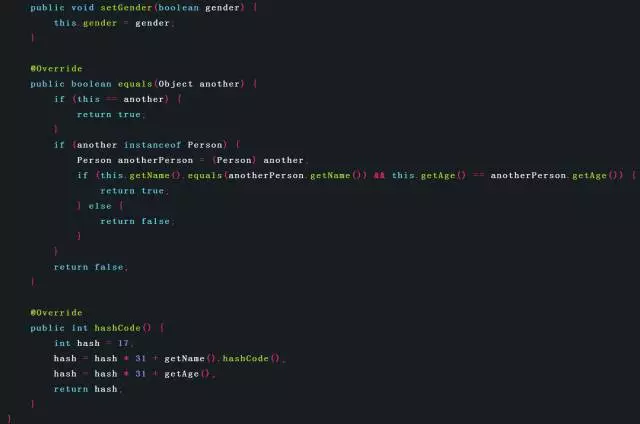
下面通過一個例子進行說明,在該例中,Person類重寫了equals()方法和hashCode()方法,因為equals()方法中只使用了name域和age域,所以hashCode()方法中,也只計算name域和age域,
對于String型別的name域,直接使用了String的hashCode()方法;對于int型別的age域,直接用其值作為該域的hash,

推薦去我的博客閱讀更多:
1.Java JVM、集合、多執行緒、新特性系列教程
2.Spring MVC、Spring Boot、Spring Cloud 系列教程
3.Maven、Git、Eclipse、Intellij IDEA 系列工具教程
4.Java、后端、架構、阿里巴巴等大廠最新面試題
覺得不錯,別忘了點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/181802.html
標籤:Java
上一篇:Spring03_DI