用KNN演算法來進行數字識別,還是用sklearn自帶的digits資料集,
# coding:utf-8
# KNN演算法實作手寫識別
from sklearn import neighbors
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
if __name__ == "__main__":
# 加載資料
digits = load_digits()
x_data = https://www.cnblogs.com/zwdnet/p/digits.data
y_data = digits.target
print(x_data.shape)
print(y_data.shape)
# 劃分訓練測驗集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)
# 訓練
knn = neighbors.KNeighborsClassifier(algorithm ="kd_tree", n_neighbors = 3)
knn.fit(x_train, y_train)
# 準確率評估
predictions = knn.predict(x_test)
print(classification_report(y_test, predictions))
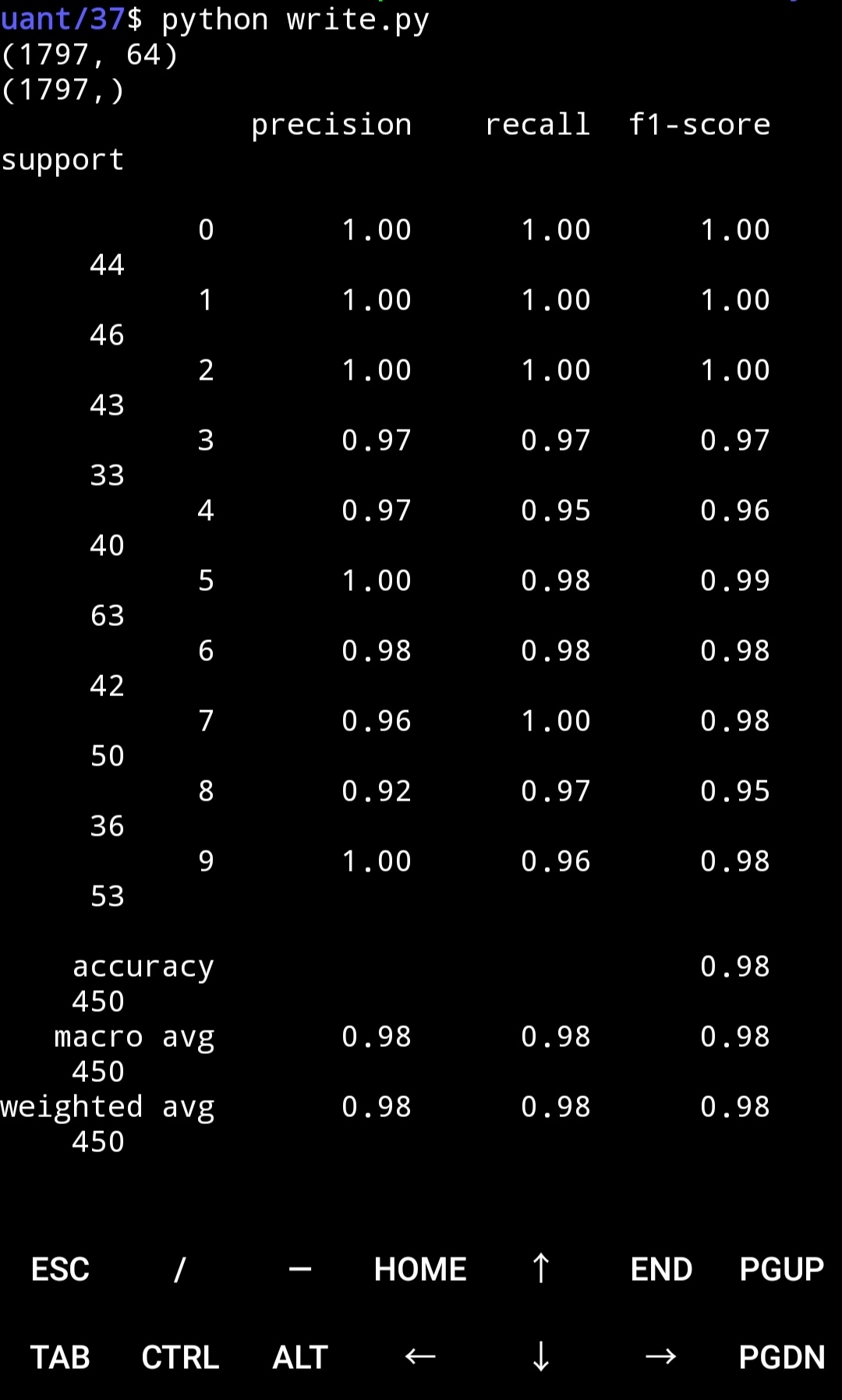
除了訓練那部分,代碼幾乎都是抄前文的,可以看到用sklearn庫非常方便,結果也很好,準確率98%,
KNN的準確率遠高于MLP分類器,原因是MLP在小資料集上容易過擬合,而且MLP對于引數調整比較敏感,
接下來是強化學習,
我發文章的四個地方,歡迎大家在朋友圈等地方分享,歡迎點“在看”,
我的個人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客園博客地址: https://www.cnblogs.com/zwdnet/
我的微信個人訂閱號:趙瑜敏的口腔醫學學習園地
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/183073.html
標籤:Python
上一篇:Pandas的基礎用法