本文根據Jin Liang的《Getting Started with Machine Learning》ver 0.96而寫,基本上就是翻譯,但并不是逐字翻譯,
第一部分 機器學習基礎
01.概述
應用:自動駕駛,面部識別,垃圾郵件識別,信用卡欺詐識別,機器驗傷,銷售預測,語音識別,機器人,
深度學習包含于機器學習包含于人工智能,
機器學習使使計算機程式從已有的資料中學習已預測新的資料,趨勢,
機器學習的流程:
①選擇資料,分成訓練資料,驗證資料,測驗資料,
②資料建模,利用資料的相關特征訓練相關模型,
③驗證模型:使用驗證資料檢驗模型,
④測驗模型:使用測驗資料測驗已驗證的模型,
⑤使用模型:部署整個模型,對新資料進行預測,
⑥改進模型
與傳統方法的區別:傳統方法是人事先制定好所有解決問題的方法,而機器學習是從資料中自己學習解決方法,
與資料挖掘的區別:資料挖掘是從資料中尋找未知的模式和關系的科學,機器學習是應用事先推斷的知識于新的資料以在實際問題中做出決策,
考慮是否需要機器學習?
①你是否需要機器學習?
你是否需要將任務自動化?有復雜的規則和非結構化資料的大量任務是合適的選擇,
②能否將你的問題清晰的用公式表達?
要何種輸入,進行何種預測?
③你是否有合適的例子?
機器學習總是需要資料的,通常來說,資料越多越好,資料需有兩個部分(有監督學習),特征和標簽,
④資料的規則性
機器學習是學習規則和模式
稀少或不規則的資料難以學習,
⑤你能否找到資料的真實意義?
樣本常以特征矩陣的形式出現,成功的機器學習需要好的特征,
⑥你如何定義成功?
評估函式需支持商業目標,
你應當何時使用機器學習?
涉及大量資料,但沒有現成的公式或方程的任務或問題,
如何創建機器學習模型?
將資料劃分為訓練集和測驗集,用訓練集資料進行資料清洗,特征工程,模型選擇,引數優化,最后建立模型,用模型對測驗資料進行預測,最后將預測值與真實值進行對比,
機器學習的基本任務
分類(預測類別):決定資料點屬于哪個類別,
回歸(預測值):計算與樣本點相關的連續值屬性,
02.理解商業
理解你的問題,包括以下任務:
①.定義你的商業目標
②.評估你的形勢
③.定義你的資料挖掘目標
④.制訂你的專案規劃,
資料科學可以回答的五個問題:
①這是A還是B?
②它是怪異的嗎?
③有多少?
④這是如何組織的?
⑤我接下來該做什么?
03.理解資料
收集原始資料
描述資料
探索資料
檢驗資料質量
在考慮能做多好之前先考慮能不能做,
04.資料準備
資料清理準備在整個機器學習程序中耗時最多,約一半以上的時間,
真實世界的資料是臟的,影響資料質量的因素:
①無效資料
②資料格式不一致
③屬性間的依賴關系
④重復資料
⑤資料缺失
⑥書寫錯誤
⑦位置錯誤:一個屬性包含另一個屬性的資料,
資料預處理避免“垃圾進,垃圾出”:資料清洗,資料重構,文本清洗,資料歸一化(normalization),資料離散化,
處理缺失值的方法:洗掉,用空值,平均值,高頻數值,回歸值來填充,
例外值的問題,有的演算法對其很敏感,
對奇異值的處理:保留、拋棄或用鄰近值代替,
這樣處理的點如果少于5%,不會影響假設檢驗,否則可能影響樣本代表性,降低分析的有效性等,可以考慮資料轉換,或使用其它資料處理技術,
資料歸一化:將資料縮小到指定范圍內,
①最大值最小值法
歸一化后的樣本值 = (原值 - 最小樣本值)/(最大樣本值-最小樣本值)
②正態化
z=(樣本值 - 平均值)/標準差
③數值小數點位數改變,
資料描述:可以用可視化等方法,可以用分類方法將連續資料離散化,
資料縮減:樣本再取樣,對屬性取樣,對樣本分組,每組用一個資料代表,
文本清洗,
特征工程:這是機器學習中的關鍵任務,從原始資料中提取特征的程序,它是一種藝術,將資料納入模型與避免較多的資料納入之間存在平衡,引入不相關的變數會增加模型噪音,
特征即輸入,自變數;目標即結果,因變數,
特征工程可以增強你的資料,
為何應該執行特征篩選?
①簡化模型便于研究者/應用者解釋,
②縮短訓練時間減少學習程序,
③避免維度災難(curse of dimensionality)
④通過降低過擬合增強模型的通用性,
維度災難:當維度高于某特定限度后,模型表現反而下降的現象,原因,當維度越高時,平滑填充整個空間的資料需要指數級的增長,但實際中資料的規模是固定的,
現代特征選擇的方法:過濾(filter),封裝(wrapper),嵌入(embedded method),
傳統方法:前向法(逐漸向模型添加特征),后向法(逐漸從模型中排除特征),逐步回歸法,
①過濾法:納入所有特征-選擇最佳子集-學習演算法-檢查模型表現,
通過統計學方法檢驗每個特征與結果的相關性,排序,從而決定納入和排除哪些特征,
該方法傾向于納入多余的變數,因為它不考慮變數間的關系,
②封裝法:通過一個前瞻性的模型來給特征子集評分,
所有特征的集合-產生一個子集,執行學習演算法-反復進行上一步,選出最佳子集-執行,
該方法將特征子集的選擇看做一個搜索程序,用一個前瞻模型來評估子集,這種方法考慮了變數之間的關系,它運算強度比較大,比較耗時,但通常它能給出某個模型的最佳特征子集,
③嵌入演算法:特征選擇是模型建構程序的一部分,
所有特征的集合-產生一個特征子集-運用學習演算法建模-評價表現-重復上面三步,選擇表現最佳的特征子集,最常用的是正則化方法(regularization),
后兩種演算法更耗時,更易產生過擬合,
特征選擇與降維
特征選擇減少了特征數量,但通常不被稱為降維,特征選擇產生一個特征的子集但并不改變其資料,降維方法可以通過改變資料將原有的特征轉化為新特征,
谷歌的特征工程的定義:將原始資料轉換為特征向量的程序,
05.建模
建模是一個綜合資料結構,演算法,數學等以找到資料集中特征與目標的關系的互動性程序,
模型定義了特征與標簽之間的關系,
機器學習程序:獲取原始資料,資料清洗處理,特征工程,建模,模型檢驗,應用,
建模是一個反復試驗調整的程序,
通常在真實值與預測值之間有差異,平均誤差平方(Mean square error,MSE)常用來表示誤差的大小,也被稱為損失函式或成本函式,
模型的訓練是一個尋找最佳引數使得預測誤差最小的迭代程序,
梯度下降法是尋找最佳引數的常用演算法,
引數和超引數
超引數是訓練前指定的(根據經驗等),決定模型的不同,"調參"就是調整這個,引數是從資料中學習到的,
超引數的例子:神經網路的層數,學習率,隨機樹森林里樹的數目,
分類演算法,根據結果有兩分類和多分類,
機器學習分四類:監督學習,無監督學習,半監督學習,增強學習,
需要選擇合適的演算法,不合適的演算法準確度很低,
選擇演算法的因素:
①資料的大小,質量和性質
②可用的計算時間
③任務的緊急程度
④你想用資料做什么?
06.模型評估(Evaluation)
什么是好的模型?
準確度高,可解釋性強,快速,可擴展性強,
在訓練階段表現良好的模型可能在實際中表現很差,
能在新資料中有很好的普遍性的模型很關鍵,
欠擬合和過擬合
模型不能抓住資料中的重要特征叫欠擬合,它甚至在訓練集中表現都很差,這通常意味著使用了一個過度簡單的模型,(高訓練誤差,高測驗誤差)
模型能較準確的擬合訓練資料但在新資料上表現過差叫過擬合,(低訓練誤差,高測驗誤差)
這兩種情況都會導致預測表現太差,
模型檢驗其對新資料的有效性,通過倒置或分割資料以檢驗模型的有效性,在監督學習時抽出一部分資料作為測驗集,使用訓練集訓練模型,使用測驗集測驗模型,
模型檢驗策略:
①hold-out檢驗:將資料分為訓練集和測驗集兩部分,不要拿測驗集訓練模型,不建議采用這種方法,因為這種檢驗不能公平的評估假設的普遍性,
更好的檢驗方法:將資料劃分為訓練集,交叉驗證集和測驗集三部分,使用交叉驗證資料選擇模型,測驗資料來評估模型,這是吳恩達建議的,
對于小資料集,三者的比例約為6:2:2,對于大資料集,三者比例為98:1:1,
②k折交叉驗證(k-fold cross validation)
將資料集均分為k份大小相等的部分,重復進行k次hold-out檢驗,每次,其中一份資料用作測驗集,其余k-1份用作訓練集,計算每次檢驗的的誤差,
這一方法的優點是資料劃分方式對結果的影響很小,每份資料有一次作為測驗資料,有k-1次作為訓練資料,隨著k的增大,誤差減小,
③留一交叉檢驗(leave-one-out cross validation)
上一個方法的特例,k=n,即有多少樣本點,就分成多少份,每次只留一個樣本點做測驗資料,其余資料都作為訓練資料,這種方法需要很大的運算量,
檢驗方法的選擇:大資料集選擇hold-out檢驗,計算量小,適合于深度學習,因為資料量巨大,但傳統的資料劃分如80:20不適合于深度學習,小資料集選擇交叉驗證,10折比較常見,當更小的值也可以選,
評價模型的表現
模型評價矩陣
分類模型
準確性(Accuracy)
精確性(Precision)
召回(Recall)
F值
ROC
AUC
Log Loss
回歸模型
MAE(平均標準差)
MSE(平均方差)
RMSE(平均方差根,Root Mean Square Err)
MAPE(平均絕對誤差百分比)
R2
評估分類演算法
①準確率 = 預測正確例數/總例數
對于偏態資料準確率并不是一個好的指標,比如癌癥檢測,準確率很高的方法可能也是沒用的,
②精確性 = 正確的陽性預測/所有陽性預測,這回答的是預測是陽性的有多大比例是真的陽性,
③召回率 = 正確的陽性預測/(正確的陽性預測+錯誤的陰性預測),它回答的問題是真正的陽性中間有多大比例被預測為陽性,
預測錯誤的代價
有兩種錯誤:納假(第一類錯誤),拒真(第二類錯誤),一個概率高另一個概率就低,要根據犯錯的成本來選擇,
④F值 = 2*PR/(P+R)
值越大越好
⑤ROC曲線
正確陽性率與錯誤陽性率在不同決定水平的關系的曲線,
曲線顯示了當你允許越來越多的錯誤陽性的時候能得到多少正確陽性分類,
曲線越靠左上角越好,
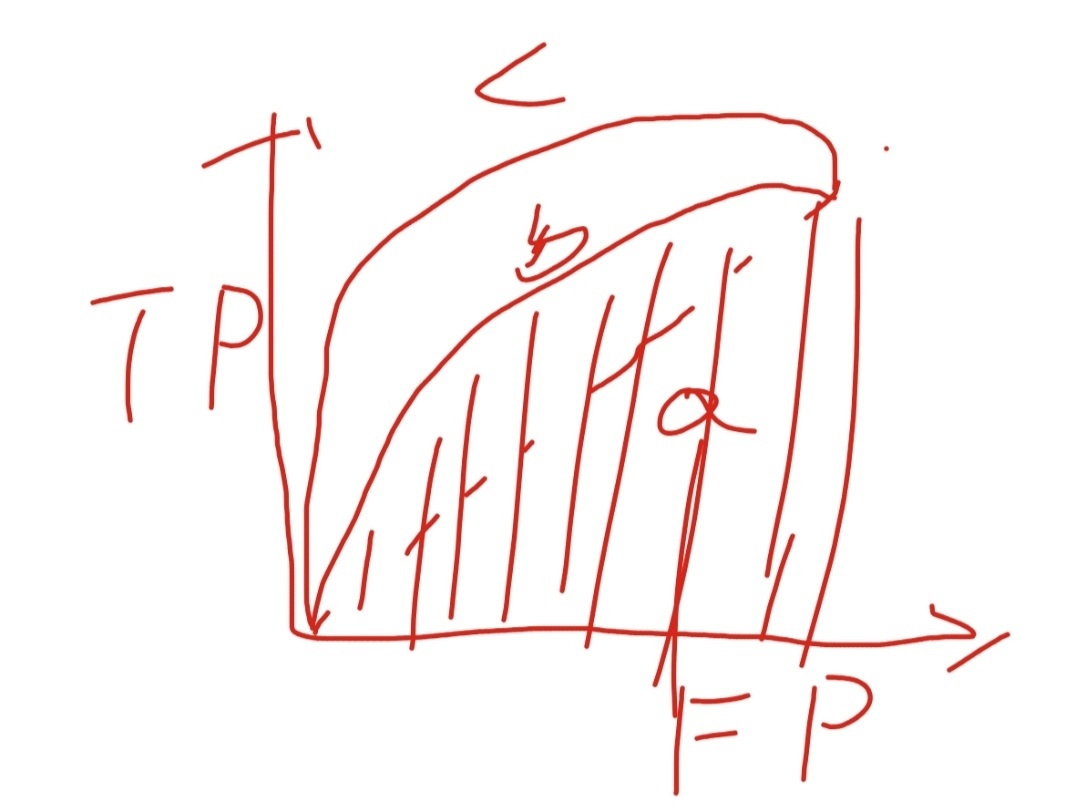
a是隨機猜測,c比b好,
⑥AUC,ROC曲線下的面積,是用單獨一個數衡量模型表現的最好方法,值越高越好,隨機猜的模型,AUC=0.5,
評估回歸演算法
①MAE:誤差絕對值的平均值,
測量預測值與真實值的接近程度,之所以取絕對值,是防止正負誤差相互抵消,最好的回歸有最小的MAE值,因此MAE值越小越好,
②MSE:誤差平方的平均值
用誤差平方值代替絕對值,會放大誤差較大者的影響,跟MAE一樣,越小越好,
③RMSE:誤差平方和的平均數的平方根,
即MSE開平方根,是在回歸分析中最常用的指標,它有一些缺點,比較容易受例外值影響,其對大的誤差值更加敏感,同樣越小越好,
④MAPE:平均絕對誤差比例
當資料沒有極端值(包括0)時最好,當資料為0或接近0時該指標會給出混亂的結果,越小越好,
⑤R2
r稱為皮爾森相關系數,衡量兩個變數的線性相關性,取值范圍為[-1,1],當值為0時二者沒有線性關系,
R2是測量模型是否擬合真實資料的標準方法,等于r*r,它描述了因變數的變化能由模型來解釋的比例,它取值范圍[0,1],越高越好,在使用時要小心,太高的值要懷疑,
具體計算略了,
R2的問題:①往模型中加入更多的特征,R2的值會增加,盡管特征可能與因變數無關,因此一個特征更多的模型可能位元征較少的模型的R2值高,其預測能力卻未必如此,②當模型有更多特征和更高階的多項式時,會擬合噪音,即過擬合,而R2值會較高,產生誤導,
⑥調整R2
是R2的修正版,如果加入更多的無關特征,模型的調整R2會降低,而加入更多相關特征,模型的調整R2會升高,調整R2總是小于或等于R2,
誤差的來源有兩個:偏倚和變異,
變異是預測值偏離其平均值的程度,
偏倚是預測值與真實值的差異,
預測誤差可以分解為上述兩個部分,
低偏倚及低變異是最好的,高偏倚和高誤差是最差的,但通常無法兩者兼顧,在選擇模型時需要權衡兩者,選擇能平衡二者并使總誤差最小的模型,
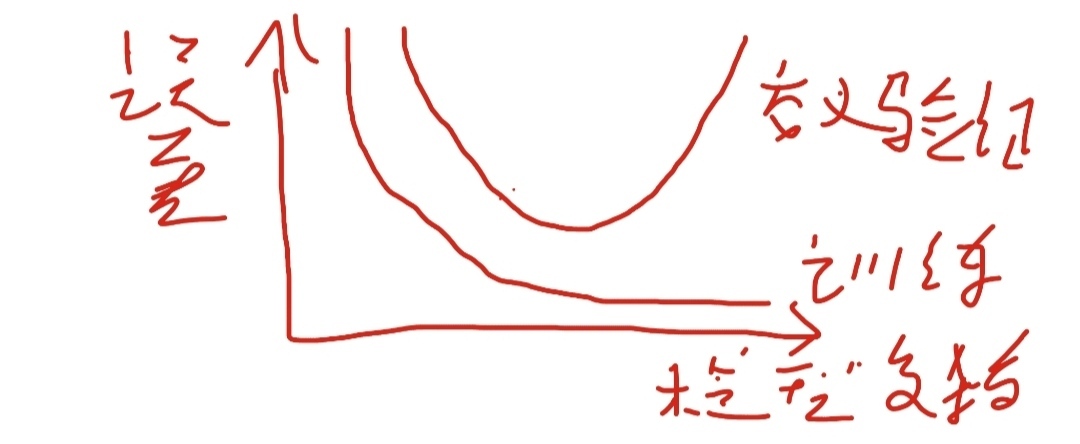
左側是欠擬合(偏倚),中間剛好,右邊是過擬合(變異),
模型在訓練集上很好,在測驗集上很差,是變異問題,如果模型在訓練和測驗集上都很差,是偏倚問題,
可以使用交叉驗證來診斷偏倚和變異問題,
高偏倚問題的特征:高訓練誤差,驗證誤差與訓練誤差類似,
高變異問題的特征:低的訓練誤差,非常高的驗證誤差,
處理:
①高偏倚(欠擬合):使模型更復雜(嘗試其它模型;如更大的神經網路,);使用更復雜的特征;調整超引數;使用一系列復雜度更低的演算法(bosting)
②低偏倚而高變異(過擬合):獲取更多資料;減少特征數量;使用正則化;換成復雜度較低的演算法;使用一系列高復雜度的演算法(Bagging/隨機樹森林)
學習曲線是描述訓練誤差和測驗誤差隨訓練集的大小增加的變化的曲線,用來診斷偏倚和變異,
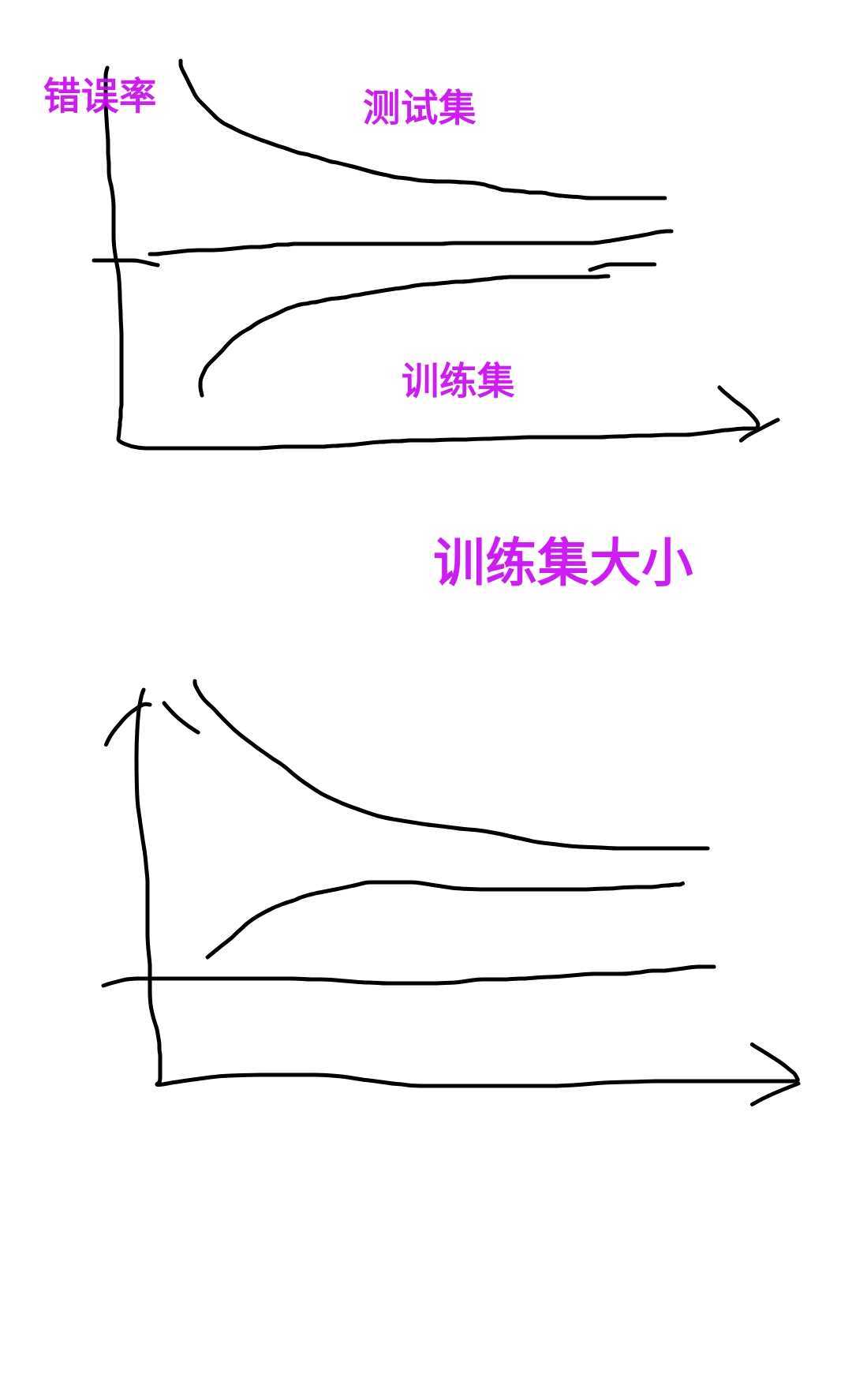
上面是典型的高變異的學習曲線,下面是典型的高偏倚的學習曲線,
具體調參的內容略了,
07.模型應用
應用訓練好的模型和真實資料進行預測,模型應用以后還要進行評估、監控、管理,
評估分為離線評估和在線評估,模型的表現會隨時間下降,對于表現不好的模型,撤回,
08.其它話題
幾個建議:
①快速建立初始系統,再迭代,別在一開始就過度思考,
②使用交叉驗證來評估模型的通用性,
③使用偏倚/變異分析和錯誤分析作為進一步改進的先導,
谷歌有資料集搜索引擎,
接下來第二部分是具體各種機器學習演算法的介紹,下次吧,
我發文章的四個地方,歡迎大家在朋友圈等地方分享,歡迎點“在看”,
我的個人博客地址:https://zwdnet.github.io
我的知乎文章地址: https://www.zhihu.com/people/zhao-you-min/posts
我的博客園博客地址: https://www.cnblogs.com/zwdnet/
我的微信個人訂閱號:趙瑜敏的口腔醫學學習園地
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/184124.html
標籤:Python
上一篇:2020Python練習一