若該文為原創文章,轉載請注明原文出處
本文章博客地址:https://blog.csdn.net/qq21497936/article/details/109096211
各位讀者,知識無窮而人力有窮,要么改需求,要么找專業人士,要么自己研究
紅胖子(紅模仿)的博文大全:開發技術集合(包含Qt實用技術、樹莓派、三維、OpenCV、OpenGL、ffmpeg、OSG、單片機、軟硬結合等等)持續更新中…(點擊傳送門)
OpenCV開發專欄(點擊傳送門)
上一篇:《OpenCV開發筆記(七十):紅胖子帶你傻瓜式編譯VS2017x64版本的openCV4》
下一篇:持續補充中…
前言
??紅胖子,來也!
??做影像處理,經常頭痛的是明明分離出來了(非顏色的),分為幾塊區域,那怎么知道這幾塊區域到底哪一塊是我們需要的,那么這部分就涉及到需要識別了,
??識別可以自己寫模板匹配、特征點識別、級聯分類器訓練識別,
??本文章就是講解級聯分類器的訓練與識別,
級聯分類器相關
??OpenCV的級聯分類器分有兩個,分別為Harr級聯分類器和LBP級聯分類器,具體級聯分類器請查看:
??《OpenCV開發筆記(五十四):紅胖子8分鐘帶你深入了解Haar級聯分類器進行人臉檢測(圖文并茂+淺顯易懂+程式原始碼)》
??《OpenCV開發筆記(五十五):紅胖子8分鐘帶你深入了解Haar、LBP特征以及級聯分類器識別程序(圖文并茂+淺顯易懂+程式原始碼)》
明確目標
??目標是識別視頻中的歌手,我們先手動采集資料集合,
??視頻為《綠色》,如下圖:

訓練分類器前的準備作業
采集正樣本圖片
??正樣本的尺寸不是必須一致的,但是要和生成的正樣本矢量檔案中的寬高有相同的比例(因為訓練程序中,會根據設定的寬高進行等比縮放,比如設定正版本圖片是128x128的,那么樣本為256x256會縮放,假設為256x128的那么比例就不同了,這個圖怎么處理?待定);
??正樣本圖片應該盡可能包含少的干擾背景資訊,在訓練程序中多余的背景資訊也會成為正樣本的一個區域特征,此處與深度學習不同,深度學習現在主流無腦深度學習,影像基本的一些去噪都可能不做,
??資料來源盡可能做到多樣化,比如樣本為車,車的姿態場景應稍豐富些,同一正樣本目標的影像太多會使區域特征過于明顯,造成這個目標的訓練過擬合,影響檢測精度,不利于訓練器泛化使用,
??我們采集視頻的人臉,先把視頻解碼后保存成jpg圖片,
??此處省略一萬字…
創建樣本:opencv_createsamples.exe
??使用opencv自帶的命令列工具opencv_createsamples.exe
- [-info <collection_file_name>]
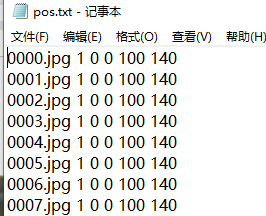
樣本說明檔案,每一行的內容為
xxx.jpg nums x y width height
??例如:圖片中有兩個目標
xxx.jpg 2 0 0 100 100 200 200 100 100
??生成樣本在windows上依托命令列
dir /b > pos.data
- [-img <image_file_name>]
??通過一張圖片的扭曲形變成多張圖片作為樣本,就填寫這個引數,引數的內容為要扭曲的圖片的路徑,填入后,-info引數不再有效, - [-vec <vec_file_name>]
??樣本描述檔案的名字及路徑 - [-bg <background_file_name>]
??負樣本描述檔案的名字及路徑,如果省略,則使用bgcolor的值填充作為背景,就是跟存放負樣本圖片(背景圖片)目錄位置相同的描述檔案的路徑,可用txt,dat等格式保存,每一行的內容為:xxx.jpg, - [-inv]
??如果指定該標志,前景影像的顏色將翻轉 - [-randinv]
??如果指定該標志,顏色將隨機地翻轉 - [-num <number_of_samples = 1000>]
??總共幾個樣本,可以省略,則按照輸入的實際樣本數量產生 - [-bgcolor <background_color = 0>]
??背景顏色(目前為灰度圖);背景顏色表示透明顏色,因為影像壓縮可造成顏色偏差,顏色的容差可以由-bgthresh指定,所有處于bgcolor-bgthresh和bgcolor+bgthresh之間的像素都被設定為透明像素, - [-bgthresh <background_color_threshold = 80>]
??(參考-bgcolor) - [-maxidev <max_intensity_deviation = 40>]
??前景樣本里像素的亮度梯度的最大值 - [-maxxangle <max_x_rotation_angle = 1.100000>]
??x軸最大旋轉角度,單位弧度 - [-maxyangle <max_y_rotation_angle = 1.100000>]
??y軸最大旋轉角度,單位弧度 - [-maxzangle <max_z_rotation_angle = 0.500000>]
??z軸最大旋轉角度,單位弧度 - [-show [<scale = 4.000000>]]
??顯示樣本,作為創建樣本時的除錯 - [-w <sample_width = 24>]
??樣本縮放到的尺寸 - [-h <sample_height = 24>]
??樣本縮放到的尺寸 - [-maxscale ]:
- [-rngseed ]:
創建正樣本

創建負樣本

創建樣本檔案vec
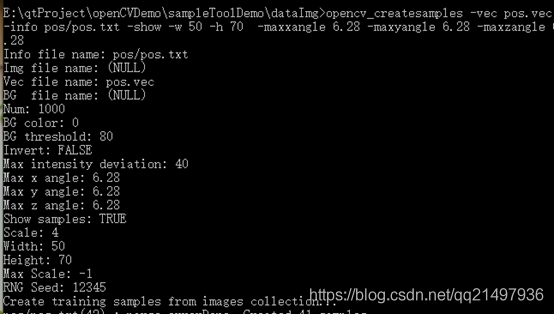
opencv_createsamples -vec pos.vec -info pos/pos.txt -bg neg/neg.txt -show -w 50 -h 70 、
-maxxangle 6.28 -maxyangle 6.28 -maxzangle 6.28
(注意:LBP特征50x70等都可以可以訓練,實測HAAR則必須是24x24 or 20x20)
訓練樣本opencv_traincascade.exe
??使用opencv自帶的命令列工具opencv_traincascade.exe,可以訓練三個特征目標:HAAR、HOG、LBP,
- -data <cascade_dir_name>
??訓練的分類器的存盤目錄, - -vec <vec_file_name>
??通過opencv_createsamples生成的vec檔案,正樣本的資料, - -bg <background_file_name>
??負樣本說明檔案,主要包含負樣本檔案所在的目錄及負樣本檔案名, - [-numPos <number_of_positive_samples = 2000>]
??每級分類器訓練時所用到的正樣本數目,但是應當注意,這個數值一定要比準備正樣本時的數目少, - [-numNeg <number_of_negative_samples = 1000>]
??每級分類器訓練時所用到的負樣本數目,可以大于-bg指 定的圖片數目, - [-numStages <number_of_stages = 20>]
??訓練分類器的級數,強分類器的個數 - [-precalcValBufSize <precalculated_vals_buffer_size_in_Mb = 1024>]
??快取大小,用于存盤預先計算的特征值,單位MB - [-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb = 1024>]
??快取大小,用于存盤預先計算的特征索引,單位MB - [-baseFormatSave]
??僅在使用Haar特征時有效,如果指定,級聯分類器將以老格式存盤, - [-numThreads <max_number_of_threads = 1>]
??支持多執行緒并行訓練 - [-acceptanceRatioBreakValue = -1>]
??此引數用于確定模型應保持學習的精確程度以及何時停止,一個好的指導方針是訓練不超過10e-5(等于10*10^(-5) ),以確保模型不會過度訓練您的訓練資料,默認情況下,此值設定為-1以禁用此功能,
–cascadeParams–
- [-stageType <BOOST(default)>]
??級聯型別,目前只能取BOOST - [-featureType <{HAAR(default), LBP, HOG}>]
??訓練使用的特征型別,目前支持的特征有Haar,LBP和HOG - [-w <sampleWidth = 24>]
??訓練的正樣本的寬度,Haar特征的w和h一般為20,LBP特征的w和h一般為24,HOG特征的w和h一般為64 - [-h <sampleHeight = 24>]
??訓練的正樣本的高
–boostParams–
- [-bt <{DAB, RAB, LB, GAB(default)}>]
??增強分類器型別:DAB-Discrete AdaBoost,RAB-Real AdaBoost,LB-LogitBoost,GAB-Gentle AdaBoost, - [-minHitRate <min_hit_rate> = 0.995>]
??類器每個階段的最小期望命中率,總體命中率估計為(最小命中率^階段數), - [-maxFalseAlarmRate <max_false_alarm_rate = 0.5>]
??分類器每個階段的最大期望誤報率, - [-weightTrimRate <weight_trim_rate = 0.95>]
??指定是否應使用修剪及其權重,一個不錯的選擇是0.95, - [-maxDepth <max_depth_of_weak_tree = 1>]
??弱樹的最大深度,一個不錯的選擇是1,這是樹樁的情況, - [-maxWeakCount <max_weak_tree_count = 100>]
??每個級聯階段的最大弱樹數,提升分類器(stage)將具有許多弱樹(<=maxWeakCount),以實作給定的-maxFalseAllRate,
–haarFeatureParams–
- [-mode <BASIC(default) | CORE | ALL>]
??選擇訓練中使用的Haar特征集的型別,基本只使用直立特征,而所有特征都使用全套直立和45度旋轉特征集,
訓練級聯分類器
opencv_traincascade.exe -data data -vec pos.vec -bg neg\neg.txt \
-numPos 41 -numNeg 215 -numStages 16 -featureType HAAR -w 64 -h 64
訓練出錯如下:

更換LBP特征,繼續訓練:
opencv_traincascade.exe -data data -vec pos.vec -bg neg\neg.txt \
-numPos 41 -numNeg 215 -numStages 16 -featureType LBP -w 64 -h 64
訓練出錯如下:
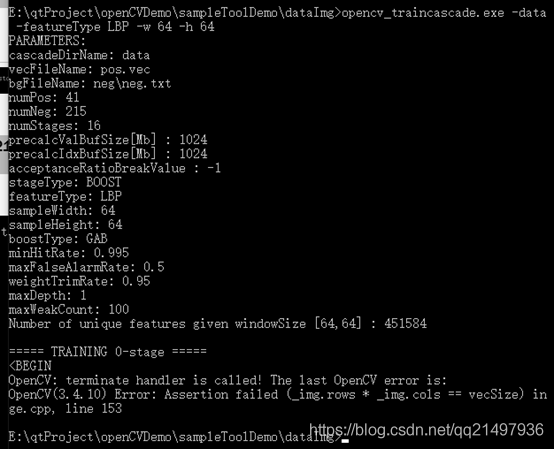
??根據錯誤寬高是要跟創建的樣本一樣,改為50x70,(創建的樣本為50x70),繼續訓練:
opencv_traincascade.exe -data data -vec pos.vec -bg neg\neg.txt \
-numPos 41 -numNeg 215 -numStages 16 -featureType LBP -w 50 -h 70
??負樣本再生成一次絕對路徑:
dir /b /s >negAb.txt
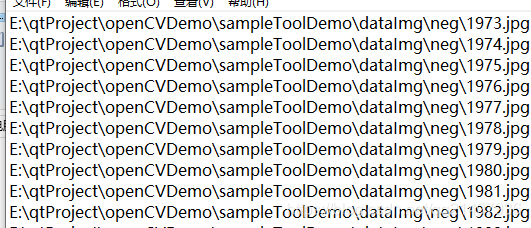
??刪掉非圖片的行
??然后繼續訓練:
opencv_traincascade.exe -data data -vec pos.vec -bg neg\negAb.txt \
-numPos 41 -numNeg 215 -numStages 16 -featureType LBP -w 50 -h 70
訓練出錯,如下:
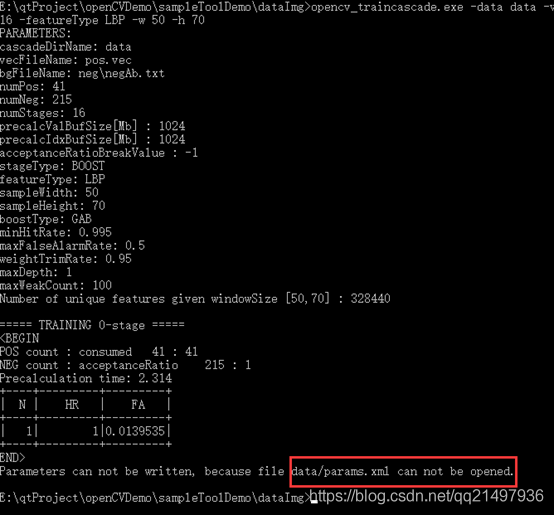
手動創建data目錄
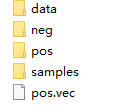
??繼續訓練:
opencv_traincascade.exe -data data -vec pos.vec -bg neg\negAb.txt -numPos 41 -numNeg 215 -numStages 16 -featureType LBP -w 50 -h 70
??然后,正常訓練,訓練完成:
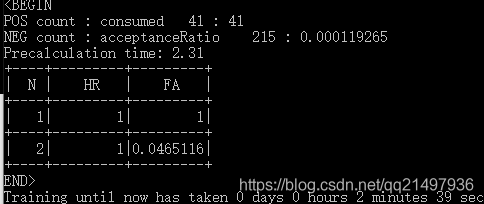
如何訓練Haar
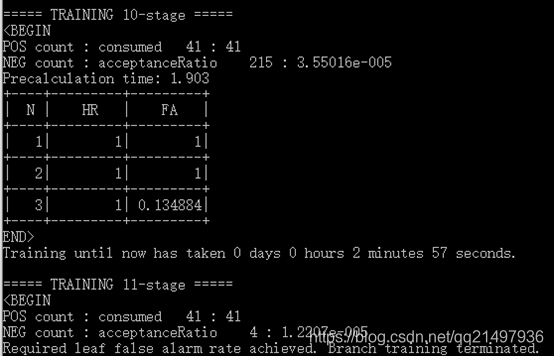
??要訓練haar特征級聯分類器,最開始創建樣本就必須為24x24 or 20x20的(經過多次嘗試論證),最終設定24x24訓練如下:
opencv_traincascade.exe -data data -vec pos.vec -bg neg\negAb.txt \
-numPos 41 -numNeg 215 -numStages 16 -featureType HAAR -w 24 -h 24
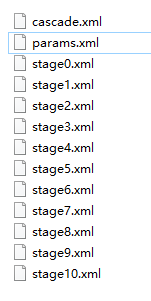
??使用該級聯分類器,使用cascade.xml加載即可,
Haar級聯分類器的測驗
??級聯分類器的測驗請參考《OpenCV開發筆記(五十四):紅胖子8分鐘帶你深入了解Haar級聯分類器進行人臉檢測(圖文并茂+淺顯易懂+程式原始碼)》
上一篇:《OpenCV開發筆記(七十):紅胖子帶你傻瓜式編譯VS2017x64版本的openCV4》
下一篇:持續補充中…
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/184469.html
標籤:java
上一篇:蘋果調整App Store政策;國內首個5G+8K超高清國產化白皮書發布;Windows計算器移植到到 Linux|極客頭條