
注意:
- Stream 自己不會存盤元素,
- Stream 不會改變源物件,相反,它會回傳一個持有結果得新Stream
- Stream 操作時延遲執行得,這意味著它們會等到需要結果時才執行,(延遲加載)
另外注意:在學習Java高級程序中難免會遇到各種問題解決不了,為此我建了個裙 783802103,里面很多架構師一起交流解答,沒基礎勿進哦!
Stream 操作步驟
- Stream 創建: 一個資料源(集合,陣列),獲取一個流,
- Stream 中間操作: 一個中間操作鏈,對資料源的資料進行處理,
- Stream 終止操作: 一個終止操作,執行中間操作鏈,并產生結果,
2 Stream 用法
2.1 創建Stream
//1. 通過 Collection.stream() / parallelStream() 創建Stream
List<String> list = new ArrayList<String>();
Stream<String> stream11 = list.stream(); // 串行流
Stream<String> stream12 = list.parallelStream(); // 并行流
//2. 通過 Arrays.stream() 獲取陣列流
IntStream stream2 = Arrays.stream(new int[]{1,2}); // 串行流
//3. 通過 Stream.of() 獲取流
Stream<String> stream3 = Stream.of("123", "456"); // 串行流
//4. 創建無限流,需要配合 limit() 截斷,不然無限制下去
Stream<Integer> stream41 = Stream.iterate(2, (x) -> x * 2); // 串行流
Stream<Double> stream42 = Stream.generate(Math::random); // 串行流
2.2 Stream 中間操作
多個中間操作可以連接起來形成一個流水線,除非流水線上觸發終止操作,否則中間操作不會執行任何得處理,而終止操作時一次性全部處理,稱為‘延遲加載’
| 中間操作(例舉部分) | 說明 |
|---|---|
| limit(long maxSize) | 截斷,使其元素不超過給定數量 |
| filter(Predicate<T> predicate) | 過濾,從流中過濾出想要的元素 |
| skip(long n) | 忽略,跳過前n個元素,若流中元素不足n個,則回傳空 |
| distinct() | 去重,通過元素 hashCode() 和 equals() 去除重復元素 |
| map(Funcation<T,R> mapper) | 映射,函式會被應用到每個元素上,并將其映射成一個新的元素 |
| flatMap(Function<T, Stream> mapper) | 映射,將流中的每個值都換成一個流,然后把所有流連接成一個流 |
| sorted() | 排序,自然排序 |
| sorted(Comparator<T> comparator) | 排序,定制排序 |
// 中間操作:不會執行任何操作
Stream<Double> stream = Stream.generate(Math::random) // double 無限流
.limit(20) // 截斷,取前 20 個
.filter(x -> x > 0.3) // 過濾,取大于 0.3 的元素
.skip(1) // 忽略,丟棄第一個元素
.distinct() // 去重
.map(x -> x * 10) // 映射,將每個元素擴大 10 倍
.sorted(); // 對 double 流進行排序
// 終止操作,只有執行終止操作才會執行全部,即:延遲加載
stream.forEach(System.out::println);
// 中間操作:flatMap 接收一個函式作為引數,將流中的每個值都換成一個流,然后把所有流連接成一個流
List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd");
list.stream().flatMap((e) -> filterCharacter(e)).forEach(System.out::println);
//如果使用map則需要這樣寫
list.stream().map((e) -> filterCharacter(e)).forEach((e) -> {
e.forEach(System.out::println);
});
public Stream<Character> filterCharacter(String str){
List<Character> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
2.3 Stream 終止操作
2.3.1 查找與匹配
| 操作(例舉部分) | 說明 |
|---|---|
| allMatch(Predicate<T> predicate) | 檢查是否匹配所有元素 |
| anyMatch(Predicate<T> predicate) | 檢查是否至少匹配所有元素 |
| noneMatch(Predicate<T> predicate) | 檢查是否沒有匹配所有元素 |
| findFirst() | 回傳第一個元素 |
| findAny() | 回傳當前流中任意元素 |
| count() | 回傳流中元素總個數 |
| max(Comparator<T> comparator) | 回傳流中最大值 |
| min(Comparator<T> comparator) | 回傳流中最小值 |
2.3.2 規約 - 將流中元素結合在一起,回傳一個值
| 操作(例舉部分) | 說明 |
|---|---|
| reduce(T identitty,BinaryOperator<T>) | 需要傳一個起始值,然后,傳入的是一個二元運算 |
| reduce(BinaryOperator<T>) | 沒有起始值,有可能結果為空,所以回傳的值會被封裝到Optional中 |
// 求和
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Integer sum = list.stream().reduce(0, (x, y) -> x + y);
// 求和,沒有起始值,則有可能結果為空,所以回傳的值會被封裝到Optional中
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Optional<Integer> sum = list.stream().reduce(Integer :: sum);
2.3.3 收集
將流轉換為其他形式,接收一個Collector介面的實作,用于給Stream中元素做匯總的方法,Collector介面方法的實作決定了如何對流執行收集操作(如收集到List,Set,Map),但是Collectors實用類提供了很多靜態方法,可以方便地創建常見得收集器實體,
| 操作(例舉部分) | 說明 |
|---|---|
| Collectors.toList() | 將流轉換成List |
| Collectors.toSet() | 將流轉換為Set |
| Collectors.toCollection(Supplier<T> supplier) | 將流轉換為其他型別的集合 |
| Collectors.counting() | 元素個數 |
| Collectors.averagingInt/Long/Double(Function<T,R> function) | 平均數,不同之處在于傳入得引數型別不同,回傳值都為Double |
| Collectors.summingInt/Long/Double(Function<T,R> function) | 求和,不同之處在于傳入得引數型別不同,回傳值為Integer, Double, Long |
| Collectors.maxBy(Comparator<T> comparator) | 最大值 |
| Collectors.minBy(Comparator<T> comparator) | 最小值 |
| Collectors.groupingBy(Function<T,R> function) | 分組,回傳Map |
| Collectors.partitioningBy(Predicate<T> predicate) | 磁區,傳入函式回傳true和false 分成兩個區,回傳Map |
3 并行流
并行流就是把一個內容分成多個資料塊,并用不同的執行緒分別處理每個資料塊的流,Java8中將并行流進行了優化,我們可以很容易的對資料進行并行操作,Stream API可以宣告性地通過parallel()與scqucntial()在并行流與順序流之間進行切換,
3.1 Fork-Join 框架
Fork—Join框架:是java7提供得一個用于執行任務得框架,就是在必要得情況下,將一個大任務,進行拆分(Fork)成若干個小任務(拆分到不能再拆分),再將一個個的小任務運算得結果進行join匯總,
Fork—Join框架時ExecutorService介面得一種具體實作,目的是為了幫助更好地利用多處理器帶來得好處,它是為那些能夠被遞回地拆分成子任務的作業型別量身設計的,起目的在于能夠使用所有有可用的運算能力來提升你的應用的性能, 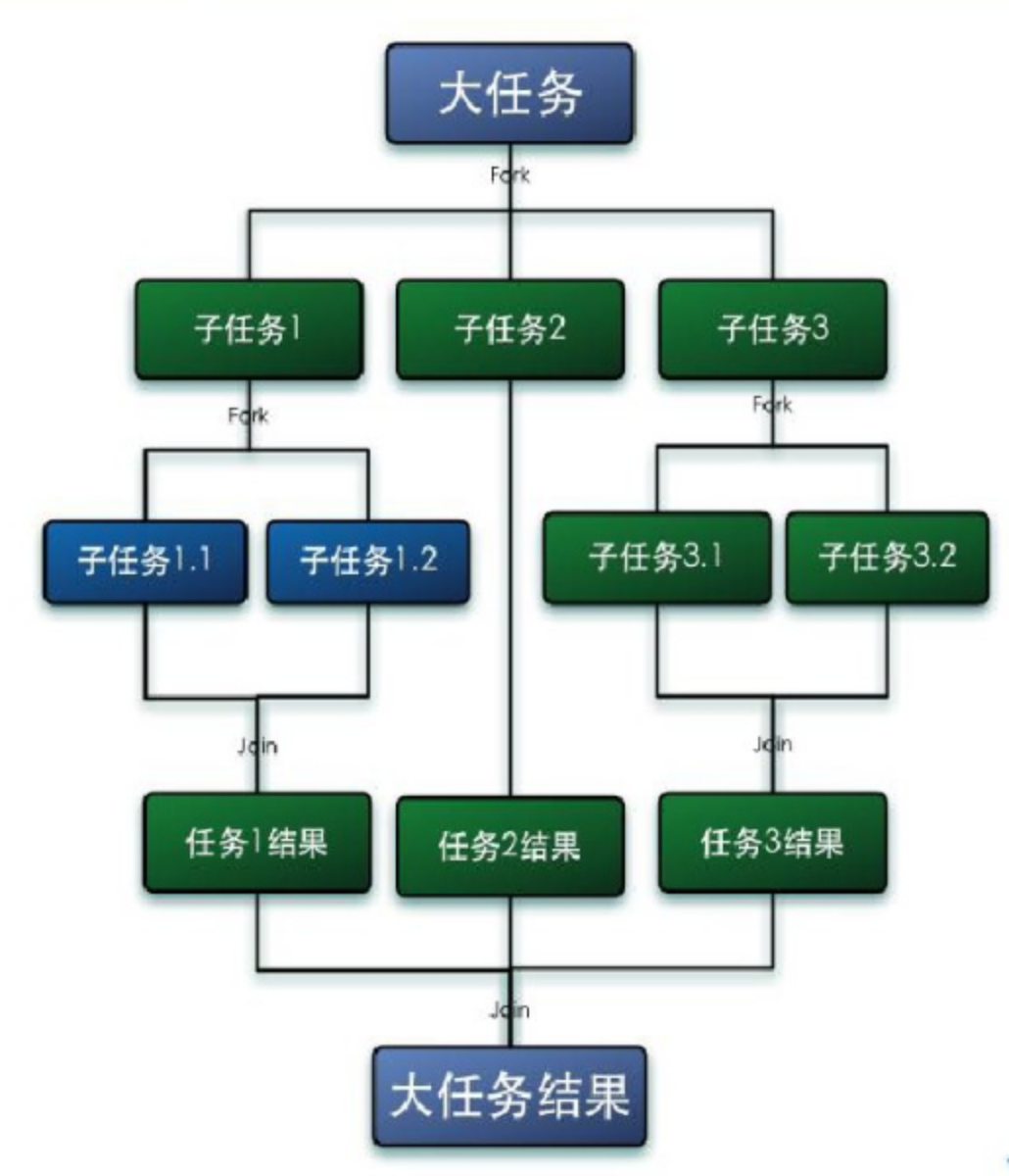
關于 Fork-Join 實作原理請看這篇:圖解Fork/Join https://mp.weixin.qq.com/s/OzZFGW_8GBYHUa0Ef10WVg
/**
* 要想使用Fark—Join,類必須繼承RecursiveAction(無回傳值)或者 RecursiveTask(有回傳值)
*
* 計算從 start 到 end 的數字累加
*/
public class ForkJoin extends RecursiveTask<Long> {
private long start; // 起始數字
private long end; // 結束數字
public ForkJoin(long start, long end) {
this.start = start;
this.end = end;
}
// 拆分的最小區間
private static final long THRESHOLD = 10000L;
@Override
protected Long compute() {
// 當區間小于最小區間時,直接計算累加
if (end - start <= THRESHOLD) {
long sum = 0;
for (long i = start; i < end; i++) {
sum += i;
}
return sum;
} else { // 否則,將區間一分為二,分給兩個不同的執行緒去計算
// 注意這里,如果有問題,會拋出java.lang.NoClassDefFoundError: Could not initialize class java.util.concurrent.locks.AbstractQueuedSynchronizer$Node 例外
long middle = start + (end - start) / 2;
ForkJoin left = new ForkJoin(start, middle); // 遞回,直到分解到最小區間后,開始計算
left.fork(); // 拆分子任務,壓入執行緒佇列
ForkJoin right = new ForkJoin(middle, end); // 遞回,直到分解到最小區間后,開始計算
right.fork(); // 拆分子任務,壓入執行緒佇列
// 合并兩部分計算的值
return left.join() + right.join();
}
}
public static void main(String[] args) {
// 開始時間
Instant start = Instant.now();
// 這里需要一個執行緒池的支持
ForkJoinPool pool = new ForkJoinPool();
// 累加到 1 億
ForkJoinTask<Long> task = new ForkJoin(0, 100000000L);
long sum = pool.invoke(task);
// 結束時間
Instant end = Instant.now();
System.out.println(String.format("累加到1億的計算時間為:%s 毫秒,值:%s", Duration.between(start, end).toMillis(), sum));
}
}
3.2 并行流對 Fork-Join 的簡化
//開始時間
Instant start = Instant.now();
long sum = LongStream.rangeClosed(0, 1000000000L) // 創建0-1億的數字串行流
.parallel() // 轉換為并行流,使用Fort-Join框架,預設使用ForkJoinPool.commonPool()執行緒池
.reduce(0, Long :: sum); // 規約計算所有元素累加
//結束時間
Instant end = Instant.now();
System.out.println(String.format("累加到1億的計算時間為:%s 毫秒,值:%s", Duration.between(start, end).toMillis(), sum));
3.3 并行流的性能
性能測驗請看:Stream Performance https://github.com/CarpenterLee/JavaLambdaInternals/blob/master/8-Stream%20Performance.md 此處參考結論:
* 對于簡單操作,比如最簡單的遍歷,Stream串行API性能明顯差于顯示迭代,但并行的Stream API能夠發揮多核特性,
* 對于復雜操作,Stream串行API性能可以和手動實作的效果匹敵,在并行執行時Stream API效果遠超手動實作,
所以,如果出于性能考慮,
1. 對于簡單操作推薦使用外部迭代手動實作,
2. 對于復雜操作,推薦使用Stream API,
3. 在多核情況下,推薦使用并行Stream API來發揮多核優勢,
4. 單核情況下不建議使用并行Stream API,
如果出于代碼簡潔性考慮,使用Stream API能夠寫出更短的代碼,
即使是從性能方面說,盡可能的使用Stream API也另外一個優勢,
那就是只要Java Stream類別庫做了升級優化,代碼不用做任何修改就能享受到升級帶來的好處,最后注意:在學習Java高級程序中難免會遇到各種問題解決不了,為此我建了個裙 783802103,里面很多架構師一起交流解答,沒基礎勿進哦!
本文的文字及圖片來源于網路加上自己的想法,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/184521.html
標籤:Java