1. itertools迭代器函式
itertools包括一組用于處理序列資料集的函式,這個模塊提供的函式是受函式式編程語言(如Clojure、Haskell、APL和SML)中類似特性的啟發,其目的是要能快速處理,以及要高效地使用記憶體,而且可以聯結在一起表述更復雜的基于迭代的演算法,
與使用串列的代碼相比,基于迭代器的代碼可以提供更好的記憶體消費特性,在真正需要資料之前,并不從迭代器生成資料,由于這個原因,不需要把所有資料都同時存盤在記憶體中,這種“懶”處理模式可以減少交換以及大資料集的其他副作用,從而改善性能,
除了itertools中定義的函式,這一節中的例子還會利用一些內置函式完成迭代,
1.1 合并和分解迭代器
chain()函式取多個迭代器作為引數,最后回傳一個迭代器,它會生成所有輸入迭代器的內容,就好像這些內容來自一個迭代器一樣,
from itertools import * for i in chain([1, 2, 3], ['a', 'b', 'c']): print(i, end=' ') print()
利用chain(),可以輕松地處理多個序列而不必構造一個很大的串列,
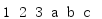
如果不能提前知道所有要結合的迭代器(可迭代物件),或者如果需要采用懶方法計算,那么可以使用chain.from_iterable()來構造這個鏈,
from itertools import * def make_iterables_to_chain(): yield [1, 2, 3] yield ['a', 'b', 'c'] for i in chain.from_iterable(make_iterables_to_chain()): print(i, end=' ') print()
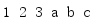
內置函式zip()回傳一個迭代器,它會把多個迭代器的元素結合到一個元組中,
for i in zip([1, 2, 3], ['a', 'b', 'c']): print(i)
與這個模塊中的其他函式一樣,回傳值是一個可迭代物件,會一次生成一個值,
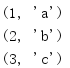
第一次輸入迭代器處理完時zip()就會停止,要處理所有輸入(即使迭代器生成的值個數不同),則要使用zip_longest(),
from itertools import * r1 = range(3) r2 = range(2) print('zip stops early:') print(list(zip(r1, r2))) r1 = range(3) r2 = range(2) print('\nzip_longest processes all of the values:') print(list(zip_longest(r1, r2)))
默認地,zip_longest()會把所有缺少的值替換為None,可以借助fillvalue引數來使用一個不同的替換值,

islice()函式回傳一個迭代器,它按索引從輸入迭代器回傳所選擇的元素,
from itertools import * print('Stop at 5:') for i in islice(range(100), 5): print(i, end=' ') print('\n') print('Start at 5, Stop at 10:') for i in islice(range(100), 5, 10): print(i, end=' ') print('\n') print('By tens to 100:') for i in islice(range(100), 0, 100, 10): print(i, end=' ') print('\n')
islice()與串列的slice運算子引數相同,同樣包括開始位置(start)、結束位置(stop)和步長(step),start和step引數是可選的,

tee()函式根據一個原輸入迭代器回傳多個獨立的迭代器(默認為2個),
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('i1:', list(i1)) print('i2:', list(i2))
tee()的語意類似與UNIX tee工具,它會重復從輸入讀到的值,并把它們寫至一個命名檔案和標準輸出,tee()回傳的迭代器可以用來為并行處理的多個演算法提供相同的資料集,
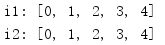
tee()創建的新迭代器會共享其輸入迭代器,所以創建了新迭代器后,不應再使用原迭代器,
from itertools import * r = islice(count(), 5) i1, i2 = tee(r) print('r:', end=' ') for i in r: print(i, end=' ') if i > 1: break print() print('i1:', list(i1)) print('i2:', list(i2))
如果原輸入迭代器的一些值已經消費,新迭代器不會再生成這些值,

1.2 轉換輸入
內置的map()函式回傳一個迭代器,它對輸入迭代器中的值呼叫一個函式并回傳結果,任何輸入迭代器中的元素全部消費時,map()函式都會停止,
def times_two(x): return 2 * x def multiply(x, y): return (x, y, x * y) print('Doubles:') for i in map(times_two, range(5)): print(i) print('\nMultiples:') r1 = range(5) r2 = range(5, 10) for i in map(multiply, r1, r2): print('{:d} * {:d} = {:d}'.format(*i)) print('\nStopping:') r1 = range(5) r2 = range(2) for i in map(multiply, r1, r2): print(i)
在第一個例子中,lambda函式將輸入值乘以2,在第二個例子中,lambda函式將兩個引數相乘(這兩個引數分別來自不同的迭代器),回傳一個元組,其中包含原引數和計算得到的值,第三個例子會在生成兩個元組后停止,因為第二個區間已經處理完,

starmap()函式類似于map(),不過并不是由多個迭代器構成一個元組,它使用 * 語法分解一個迭代器中的元素作為映射函式的引數,
from itertools import * values = [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9)] for i in starmap(lambda x, y: (x, y, x * y), values): print('{} * {} = {}'.format(*i))
map()的映射函式名為f(i1,i2),而傳入starmap()的映射函式名為f(*i),
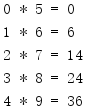
1.3 生成新值
count()函式回傳一個迭代器,該迭代器能夠無限地生成連續的整數,第一個數可以作為引數傳入(默認為0),這里沒有上界引數(參見內置的range(),這個函式對結果集可以有更多控制),
from itertools import * for i in zip(count(1), ['a', 'b', 'c']): print(i)
這個例子會停止,因為串列引數會被完全消費,
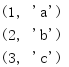
count()的“開始位置”和“步長”引數可以是可相加的任意的數字值,
import fractions from itertools import * start = fractions.Fraction(1, 3) step = fractions.Fraction(1, 3) for i in zip(count(start, step), ['a', 'b', 'c']): print('{}: {}'.format(*i))
在這個例子中,開始點和步長是來自fraction模塊的Fraction物件,

cycle()函式回傳一個迭代器,它會無限地重復給定引數的內容,由于必須記住輸入迭代器的全部內容,所以如果這個迭代器很長,則可能會耗費大量記憶體,
from itertools import * for i in zip(range(7), cycle(['a', 'b', 'c'])): print(i)
這個例子中使用了一個計數器變數,在數個周期后會中止回圈,
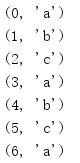
repeat()函式回傳一個迭代器,每次訪問時會生成相同的值,
from itertools import * for i in repeat('over-and-over', 5): print(i)
repeat()回傳的迭代器會一直回傳資料,除非提供了可選的times引數來限制次數,

如果即要包含來自其他迭代器的值,也要包含一些不變的值,那么可以結合使用repeat()以及zip()或map(),
from itertools import * for i, s in zip(count(), repeat('over-and-over', 5)): print(i, s)
這個例子中就結合了一個計數器值和repeat()回傳的常量,

下面這個例子使用map()將0到4區間中的數乘以2,
from itertools import * for i in map(lambda x, y: (x, y, x * y), repeat(2), range(5)): print('{:d} * {:d} = {:d}'.format(*i))
repeat()迭代器不需要被顯式限制,因為任何一個輸入迭代器結束時map()就會停止處理,而且range()只回傳5個元素.
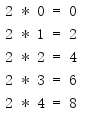
1.4 過濾
dropwhile()函式回傳一個迭代器,它會在條件第一次變為false之后生成輸入迭代器的元素,
from itertools import * def should_drop(x): print('Testing:', x) return x < 1 for i in dropwhile(should_drop, [-1, 0, 1, 2, -2]): print('Yielding:', i)
dropwhile()并不會過濾輸入的每一個元素,第一次條件為false之后,輸入迭代器的所有其余元素都會回傳,

taskwhile()與dropwhile()正相反,它也回傳一個迭代器,這個迭代器將回傳輸入迭代器中保證測驗條件為true的元素,
from itertools import * def should_take(x): print('Testing:', x) return x < 2 for i in takewhile(should_take, [-1, 0, 1, 2, -2]): print('Yielding:', i)
一旦should_take()回傳false,takewhile()就停止處理輸入,

內置函式filter()回傳一個迭代器,它只包含測驗條件回傳true時所對應的元素,
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filter(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
filter()與dropwhile()和takewhile()不同,它在回傳之前會測驗每一個元素,

filterfalse()回傳一個迭代器,其中只包含測驗條件回傳false時對應的元素,
from itertools import * def check_item(x): print('Testing:', x) return x < 1 for i in filterfalse(check_item, [-1, 0, 1, 2, -2]): print('Yielding:', i)
check_item()中的測驗運算式與前面相同,所以在這個使用filterfalse()的例子中,結果與上一個例子的結果正好相反,

compress()提供了另一種過濾可迭代物件內容的方法,不是呼叫一個函式,而是使用另一個可迭代物件中的值指示什么時候接受一個值以及什么時候互虐一個值,
from itertools import * every_third = cycle([False, False, True]) data = range(1, 10) for i in compress(data, every_third): print(i, end=' ') print()
第一個引數是要處理的資料迭代器,第二個引數是一個選擇器迭代器,這個迭代器會生成布林值指示從資料輸入中取哪些元素(true值說明將生成這個值;false值表示這個值將被忽略),
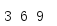
1.5 資料分組
groupby()函式回傳一個迭代器,它會生成按一個公共鍵組織的值集,下面這個例子展示了如何根據一個屬性對相關的值分組,
import functools from itertools import * import operator import pprint @functools.total_ordering class Point: def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return '({}, {})'.format(self.x, self.y) def __eq__(self, other): return (self.x, self.y) == (other.x, other.y) def __gt__(self, other): return (self.x, self.y) > (other.x, other.y) # Create a dataset of Point instances data =https://www.cnblogs.com/liuhui0308/p/ list(map(Point, cycle(islice(count(), 3)), islice(count(), 7))) print('Data:') pprint.pprint(data, width=35) print() # Try to group the unsorted data based on X values print('Grouped, unsorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print() # Sort the data data.sort() print('Sorted:') pprint.pprint(data, width=35) print() # Group the sorted data based on X values print('Grouped, sorted:') for k, g in groupby(data, operator.attrgetter('x')): print(k, list(g)) print()
輸入序列要根據鍵值排序,以保證得到預期的分組,

1.6 合并輸入
accumulate()函式處理輸入迭代器,向一個函式傳遞第n和n+1個元素,并且生成回傳值而不是某個輸入,合并兩個值的默認函式會將兩個值相加,所以accumulate()可以用來生成一個數值輸入序列的累加和,
from itertools import * print(list(accumulate(range(5)))) print(list(accumulate('abcde')))
用于非整數值序列時,結果取決于將兩個元素“相加”是什么含義,這個腳本中的第二個例子顯示了當accumulate()接收到一個字串輸入時,每個相應都將是該字串的一個前綴,而且長度不斷增加,
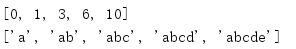
accumulate()可以與任何取兩個輸入值的函式結合來得到不同的結果,
from itertools import * def f(a, b): print(a, b) return b + a + b print(list(accumulate('abcde', f)))
這個例子以一種特殊的方式合并字串值,會生成一系列(無意義的)回文,每一步呼叫f()時,它都會列印accumulate()傳入的輸入值,

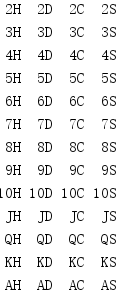
迭代處理多個序列的嵌套for回圈通常可以被替換為product(),它會生成一個迭代器,值為輸入值集合的笛卡爾積,
from itertools import * import pprint FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( chain(range(2, 11), FACE_CARDS), SUITS, ) ) for card in DECK: print('{:>2}{}'.format(*card), end=' ') if card[1] == SUITS[-1]: print()
product()生成的值是元組,成員取自作為引數傳入的各個迭代器(按其傳入的順序),回傳的第一個元組包含各個迭代器的第一個值,傳入product()的最后一個迭代器最先處理,接下來處理倒數第二個迭代器,依此類推,結果是按第一個迭代器、下一個迭代器等的順序得到的回傳值,
在這個例子中,撲克牌首先按牌面大小排序,然后按花色排序,
要改變這些撲克牌的順序,需要改變傳入product()的引數的順序,
from itertools import * FACE_CARDS = ('J', 'Q', 'K', 'A') SUITS = ('H', 'D', 'C', 'S') DECK = list( product( SUITS, chain(range(2, 11), FACE_CARDS), ) ) for card in DECK: print('{:>2}{}'.format(card[1], card[0]), end=' ') if card[1] == FACE_CARDS[-1]: print()
這個例子中的列印回圈會查找一個A而不是黑桃,然后增加一個換行使輸出分行顯示,

要計算一個序列與自身的積,開源指定輸入重復多少次,
from itertools import * def show(iterable): for i, item in enumerate(iterable, 1): print(item, end=' ') if (i % 3) == 0: print() print() print('Repeat 2:\n') show(list(product(range(3), repeat=2))) print('Repeat 3:\n') show(list(product(range(3), repeat=3)))
由于重復一個迭代器就像把同一個迭代器傳入多次,product()生成的每個元組所包含的元素個數就等于重復計數器,

permutations()函式從輸入迭代器生成元素,這些元素以給定長度的排列形式組合,默認地它會生成所有排列的全集,
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('All permutations:\n') show(permutations('abcd')) print('\nPairs:\n') show(permutations('abcd', r=2))
可以使用r引數限制回傳的各個排列的長度和個數,

為了將值限制為唯一的組合而不是排列,可以使用combinations(),只要輸入的成員是唯一的,輸出就不會包含任何重復的值,
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs:\n') show(combinations('abcd', r=2))
與排列不同,combinations()的r引數是必要引數,

盡管combinations()不會重復單個的輸入元素,但有時可能也需要考慮包含重復的元素組合,對于這種情況,可以使用combinations_with_replacement(),
from itertools import * def show(iterable): first = None for i, item in enumerate(iterable, 1): if first != item[0]: if first is not None: print() first = item[0] print(''.join(item), end=' ') print() print('Unique pairs:\n') show(combinations_with_replacement('abcd', r=2))
在這個輸出中,每個輸入元素會與自身以及輸入序列的所有其他成員配對,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/188615.html
標籤:Python
下一篇:Python_網路編程