前言
好久沒有寫實戰博客了,因為前幾個月在公司實習,博客更新就耽擱了下來,現在又受疫情影響無法返校,但是技能還是不能丟的,今天就寫一篇使用scrapy爬取當當網的實戰練習吧,
創建scrapy專案
目標站點: http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1 這是在當當網搜索關鍵字python得到的頁面
第一步仍然是使用命令列切換到作業目錄創建scrapy專案
- D:\pythonwork\cnblog>scrapy startproject cnblog_dangdang

然后使用cd命令進入專案中的spiders檔案夾使用命令創建爬蟲檔案(注意:該命令后的網址跟的是目標網址域名,而不是整個網址)
- D:\pythonwork\cnblog\cnblog_dangdang\cnblog_dangdang\spiders>scrapy genspider dangdang_spider dangdang.com

此時我們的專案與基礎爬蟲檔案已經創建完畢,接下來撰寫代碼使用pycharm打開專案
內容分析
打開目標站點分析我們需要爬取什么內容
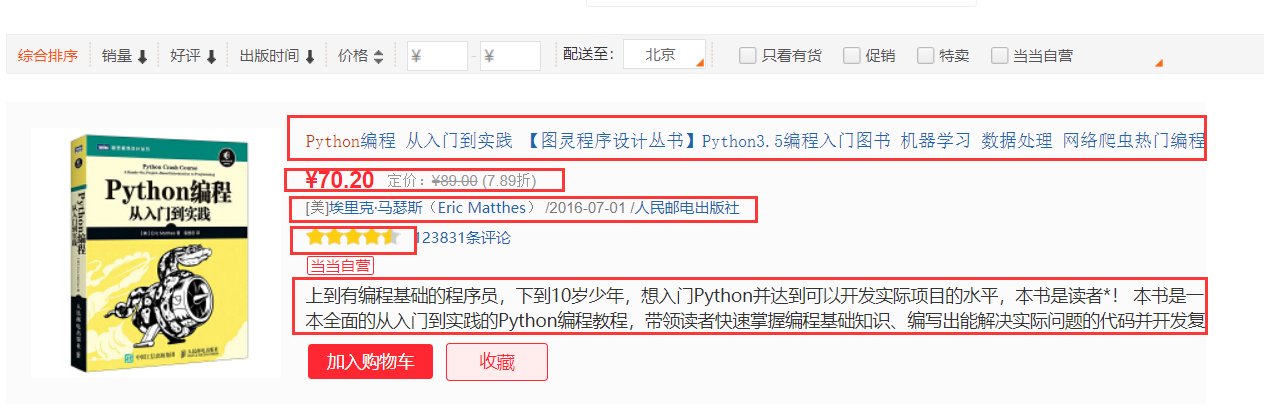
對于目標站點的商品圖書而言,我們需要爬取它的標題、價格、作者、評分和概括五個部分
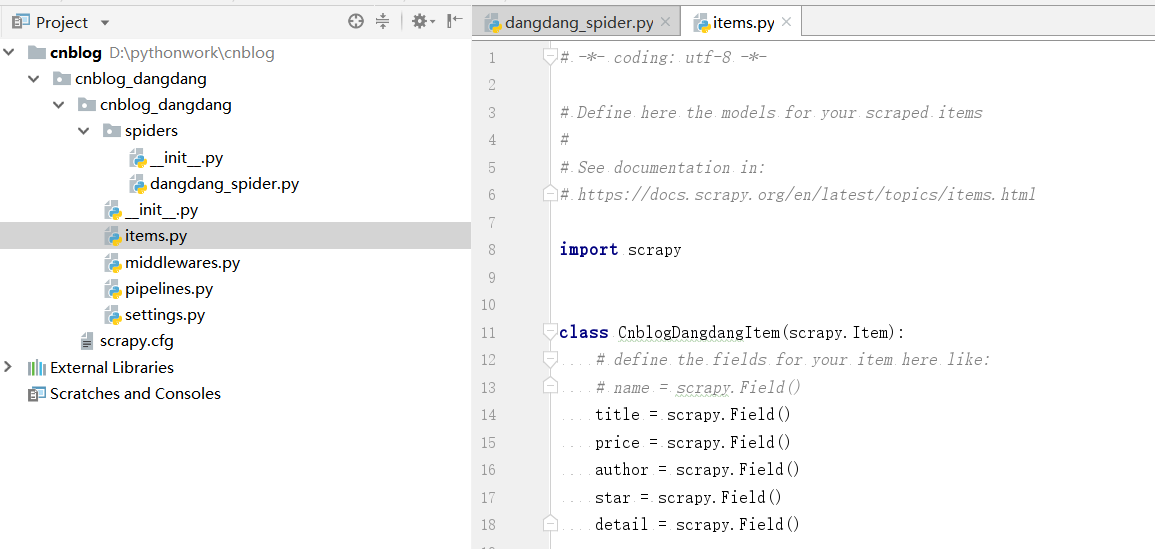
因此首先我們在專案的items.py檔案中宣告我們需要爬取的內容,
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class CnblogDangdangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() price = scrapy.Field() author = scrapy.Field() star = scrapy.Field() detail = scrapy.Field()
因此我們的資料表的sql陳述句創建如下:
CREATE TABLE IF NOT EXISTS dangdang_item ( id INT UNSIGNED AUTO_INCREMENT, title CHAR(100) NOT NULL, price CHAR(100) NOT NULL, author CHAR(100) NOT NULL, star CHAR(10) NOT NULL, detail VARCHAR(1000), PRIMARY KEY (id) )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
爬蟲檔案撰寫
內容分析完成之后我們到了最關鍵的爬蟲檔案撰寫部分,首先我們要測驗下該網站有沒有反爬措施,
這一步我們只需要簡單的將spiders檔案夾中的dangdang_spider.py檔案進行簡單的修改讓其輸出目標站點的回應內容即可
dangdang_spider.py
# -*- coding: utf-8 -*- import scrapy class DangdangSpiderSpider(scrapy.Spider): name = 'dangdang_spider' allowed_domains = ['dangdang.com'] start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response): print(response.text) pass
為了方便我們進行除錯,我們在專案下創建一個main.py檔案用于啟動爬蟲,不然我們每次啟動都需要在命令列中使用scrapy命令,
main.py
from scrapy import cmdline cmdline.execute('scrapy crawl dangdang_spider'.split())
然后直接運行main.py檔案,發現輸出了目標網站的html源代碼,所以目標網站并沒有反爬措施,我們可以直接拿取內容,接下來就開始拿取內容了,
五部分內容使用xpath拿取,網頁結構很簡單,直接從原始碼分析xpath即可,
開始實際撰寫爬蟲檔案dangdang_spider.py
# -*- coding: utf-8 -*- import scrapy import re from cnblog_dangdang.items import CnblogDangdangItem str_re = re.compile('\d+') class DangdangSpiderSpider(scrapy.Spider): name = 'dangdang_spider' allowed_domains = ['dangdang.com'] start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response): book_item = CnblogDangdangItem() items = response.xpath("//ul[@class='bigimg']/li")#不用加get 因為此步驟為了拿到一個xpath物件 for item in items: book_item['title'] = item.xpath("./a/@title").get() book_item['price'] = item.xpath("./p[@class='price']").xpath("string(.)").get()#使用string(.)方法為了拿取目標節點下的所有子節點文本 book_item['author'] = item.xpath("./p[@class='search_book_author']").xpath("string(.)").get() book_item['star'] = int(str_re.findall(item.xpath("./p[@class='search_star_line']/span/span/@style").get())[0])/20 book_item['detail'] = item.xpath("./p[@class='detail']//text()").get() print(book_item) yield book_item next_url_end = response.xpath("//li[@class='next']/a/@href").get() #如果拿到了下一頁鏈接,則訪問 if next_url_end: next_url ='http://search.dangdang.com/'+ next_url_end yield scrapy.Request(next_url,callback=self.parse)
再次運行爬蟲,發現現在已經可以輸出拿取到的資訊

說明我們的爬蟲檔案撰寫成功,接下來就是對我們拿取到的資料進行處理,
資料的存盤
此次我們選擇使用mysql進行資料的存盤,那么我們首先要干什么呢?是直接撰寫pipeline.py檔案嗎?并不是,我們還有一個很重要的地方沒有弄,就是settings.py檔案,
我們想要通過pipeline.py檔案來處理爬取到的資料,首先就需要去settings.py中開啟我們的pipeline選項,很簡單只需要在settings.py中將ITEM_PIPELINES的注釋消掉即可如下圖
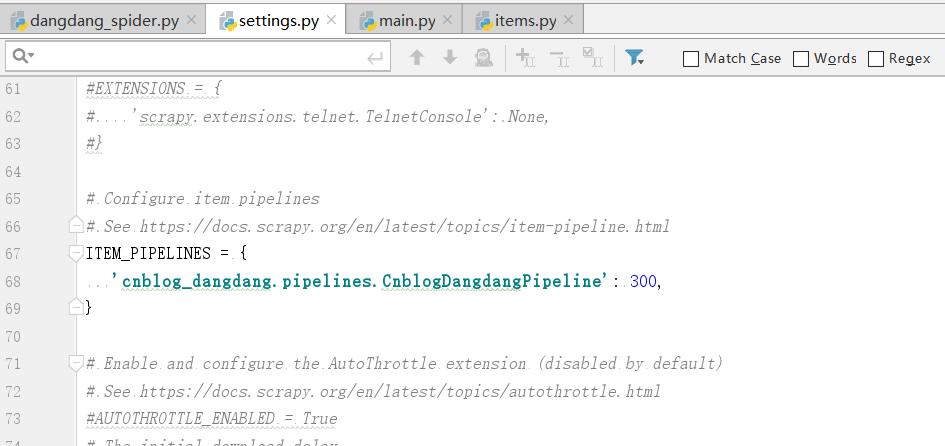
接下來就可以撰寫pipeline.py檔案來對我們的資料進行操作了
pipeline.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymysql number = 0 class DangdangPipeline(object): # open_spider()爬蟲開啟時執行一次 def open_spider(self,spider): # 連接資料庫 print("連接資料庫,準備寫入資料") self.db = pymysql.connect('localhost', '你的mysql賬戶', '你的mysql密碼', '你的資料庫名稱') self.cursor = self.db.cursor() def process_item(self, item, spider): global number number = number+1 print('當前寫入第'+str(number)+'個商品資料') #使用replace是為了避免資料中存在引號與sql陳述句沖突 title=str(item['title']).replace("'","\\'").replace('"','\\"') price=str(item['price']).replace("'","\\'").replace('"','\\"') author=str(item['author']).replace("'","\\'").replace('"','\\"') star=str(item['star']).replace("'","\\'").replace('"','\\"') detail=str(item['detail']).replace("'","\\'").replace('"','\\"') sql = f'INSERT INTO dangdang_item (title,price,author,star,detail) VALUES (\'{title}\',\'{price}\',\'{author}\',\'{star}\',\'{detail}\');' #執行sql陳述句 self.cursor.execute(sql) #資料庫提交修改 self.db.commit() return item # close_spider()爬蟲關閉后執行 def close_spider(self,spider): print('寫入完成,一共'+str(number)+'個資料') # 關閉連接 self.cursor.close() self.db.close()
接下來再次運行main.py檔案,看看爬蟲效果,

我們去資料庫中看一下我們剛剛爬取的資料
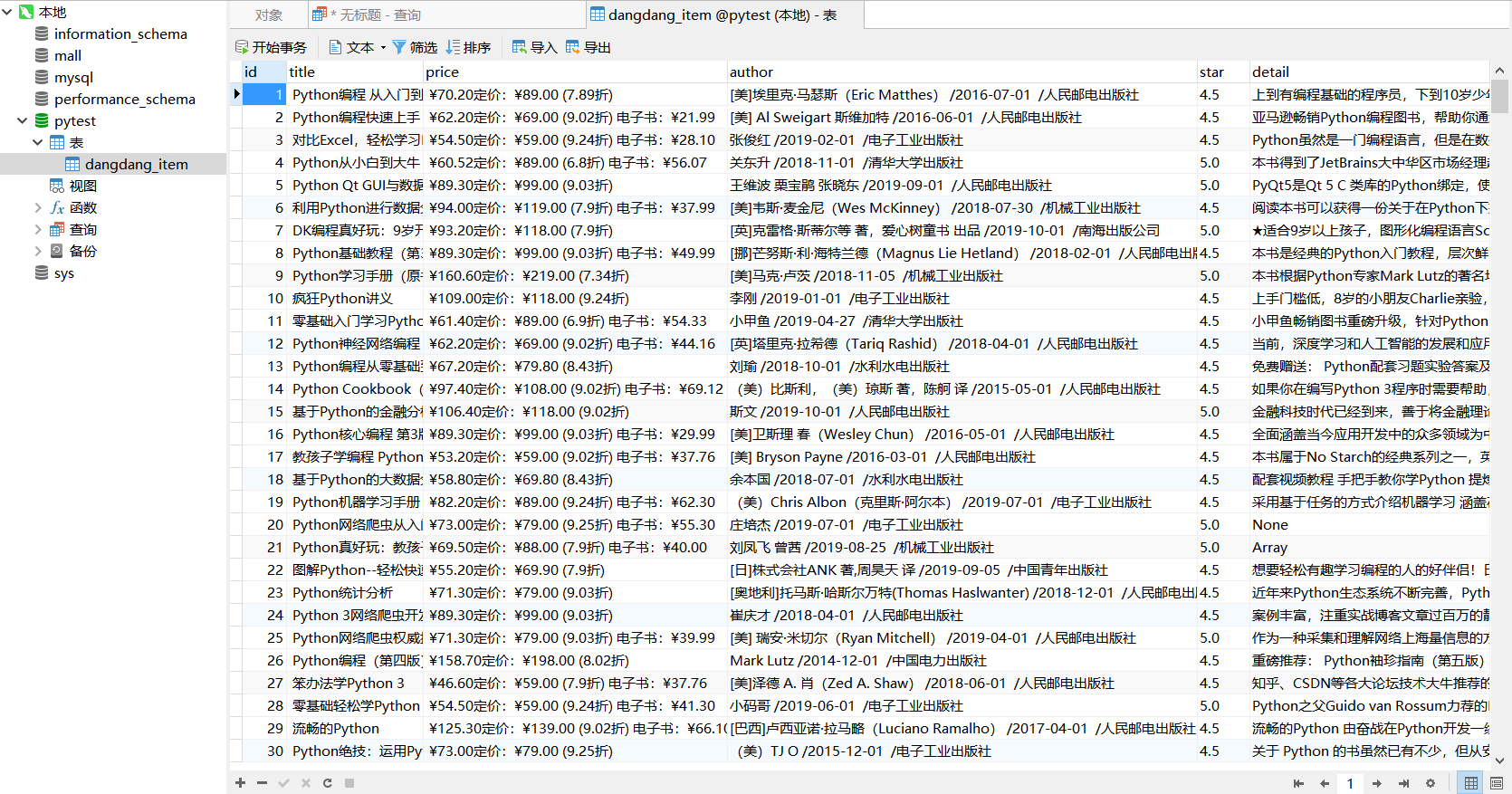
ok,大功完成了,我們的當當網scrapy爬蟲就撰寫好了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/188620.html
標籤:Python
上一篇:[Python] 前程無憂招聘網爬取軟體工程職位 網路爬蟲 https://www.51job.com
下一篇:Web框架