在大部分分布式應用中,為了提高系統的效率,都會引入快取,例如使用Redis,與此同時,也會帶來快取與資料庫資料不一致的問題,
如果對資料一致性要求不是很高的場景,我們正常的操作是,客戶端先去快取查詢,如果查詢不到再去資料中查找,資料庫查詢到以后,
再在快取中放一份,最后回傳給客戶端,這樣把大多數的請求落在快取上,減少資料庫的查詢操作,
如果是做資料增刪改的操作,一般也是有兩種情況,
1.先洗掉快取,再操作資料庫;
2.先操作資料庫,再更新快取,
這兩種情況也各有優劣,大部分使用第二種場景,
當然這里存在快取穿透,快取雪崩,快取擊穿等情況,在這里不做詳細解釋,
這里舉了例子,蘋果官網預售Apple 12 Pro Max,庫存是200W,然后果粉們準備去搶購,那么這里會存在以下情況:
- 資料庫扣減庫存成功了,但是更新快取失敗,例如,資料庫里已經剩余100W,但快取里還有150W,快取庫存大于資料庫剩余庫存,
這種請求如何解決?其實可以在扣減庫存前,先去查詢剩余數量,如果數量不足,則回傳失敗, - 如果資料庫扣減失敗了,但快取里的快取卻更新了,也就是說快取中庫存數量小于資料庫里的數量,那么就存在部分剩余庫存無法賣出的問題,
當然這種情況很難發生,因為資料庫的讀操作是遠遠快于寫操作的,
但是,如果要保證資料庫與快取強一致性該如何設計?
這里可以考慮另一種思路,也就是使用MySQL的binlog,
流程圖是這樣的:
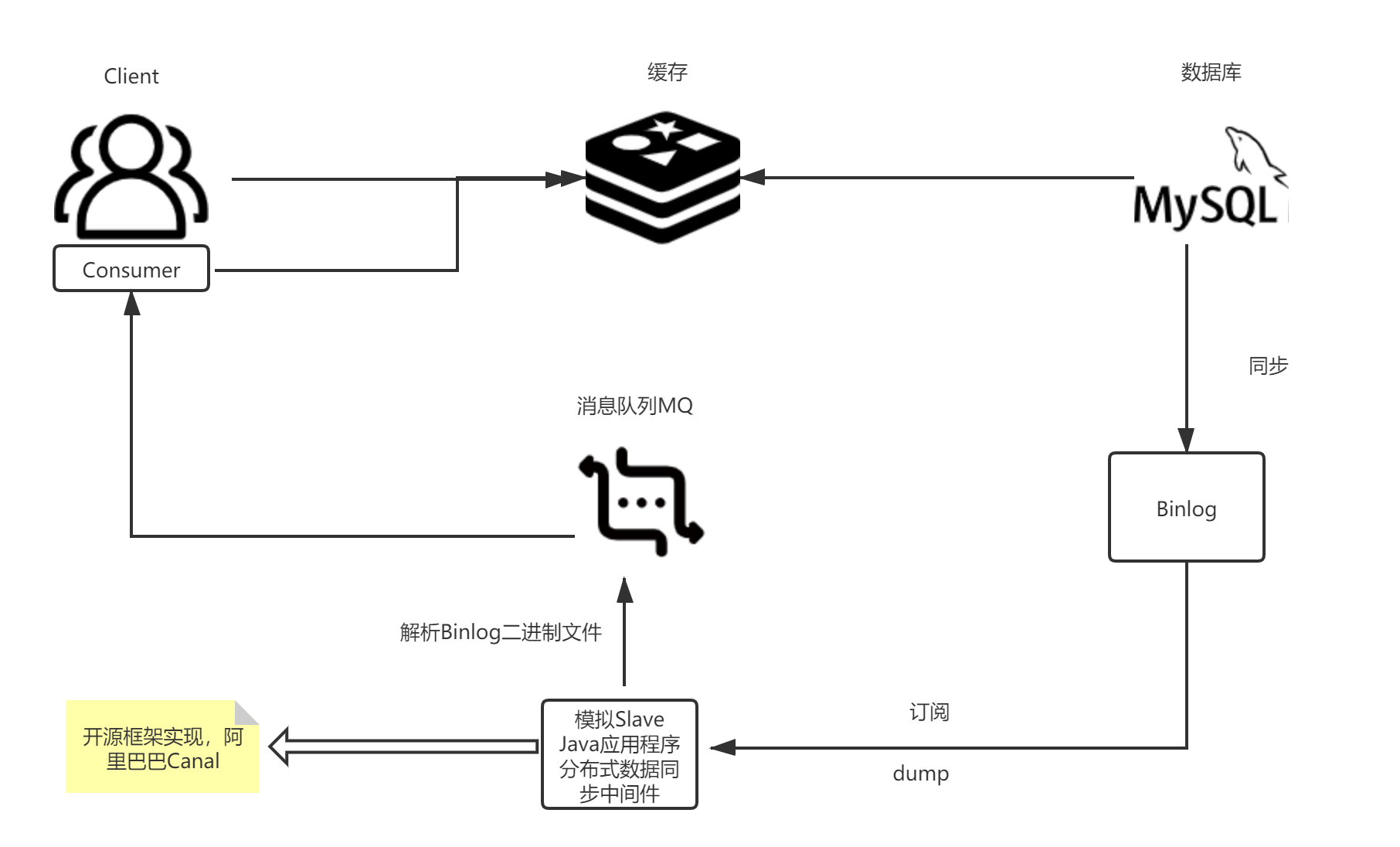
這里說一下流程:
1.客戶端從快取中讀取;
2.如果有變更操作,更新資料庫;
3.資料庫事務提交以后寫入binlog;
4.我們自己寫一個Java應用程式,把自己模擬成一個MySQL的slave,去訂閱MySQL的資料庫的binlog,MySQL會把binlog dump給我們應用程式;
5.因為binlog是二進制檔案,這里需要決議,處理insert、update、delete這些操作,
6.決議完以后,把這些資料丟到訊息佇列里,這里的訊息佇列有兩個用處,第一是做持久化訊息,第二是重試機制;
7.客戶端消費訊息佇列的訊息,然后推到快取中,如果沒有成功,進行重試,
8.更新快取完畢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/188875.html
標籤:Java
上一篇:Docker簡介