在互聯網上進行自動資料采集(抓取)這件事和互聯網存在的時間差不多一樣長,今天大眾好像更傾向于用“網路資料采集”,有時會把網路資料采集程式稱為網路機器人(bots),最常用的方法是寫一個自動化程式向網路服務器請求資料(通常是用 HTML 表單或其他網頁檔案),然后對資料進行決議,提取需要的資訊,
很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!??¤
QQ群:623406465
本文假定讀者已經了解如何用代碼來抓取一個遠程的 URL,并具備表單如何提交及 JavaScript 在瀏覽器如何運行的機制,想更多了解網路資料采集基礎知識,可以參考文后的資料,
在采集網站的時會遇到一些比資料顯示在瀏覽器上卻抓取不出來更令人沮喪的事情,也許是向服務器提交自認為已經處理得很好的表單卻被拒絕,也許是自己的 IP 地址不知道什么原因直接被網站封殺,無法繼續訪問,
原因可能是一些最復雜的 bug,也可能是這些 bug 讓人意想不到(程式在一個網站上可以正常使用,但在另一個看起來完全一樣的網站上卻用不了),最有可能出現的情況是:對方有意不讓爬蟲抓取資訊,網站已經把你定性為一個網路機器人直接拒絕了,你無法找出原因,
接下來就介紹一些網路采集的黑魔法(HTTP headers、CSS 和 HTML 表單等),以克服網站阻止自動采集,不過,先讓我們聊聊道德問題,
網路爬蟲的道德與禮儀
說實話,從道德角度講,寫作以下文字不易,我自己的網站被網路機器人、垃圾郵件生成器、網路爬蟲和其他各種不受歡迎的虛擬訪問者騷擾過很多次了,你的網站可能也一樣,既然如此,為什么還要介紹那些更強大的網路機器人呢?有幾個很重要的理由,
-
白帽子作業,在采集那些不想被采集的網站時,其實存在一些非常符合道德和法律規范的理由,比如我之前的作業就是做網路爬蟲,我曾做過一個自動資訊收集器,從未經許可的網站上自動收集客戶的名稱、地址、電話號碼和其他個人資訊,然后把采集的資訊提交到網站上,讓服務器洗掉這些客戶資訊,為了避免競爭,這些網站都會對網路爬蟲嚴防死守,但是,我的作業要確保公司的客戶們都匿名(這些人都是家庭暴力受害者,或者因其他正當理由想保持低調的人),這為網路資料采集作業創造了極其合理的條件,我很高興自己有能力從事這項作業,
-
雖然不太可能建立一個完全“防爬蟲”的網站(最起碼得讓合法的用戶可以方便地訪問網站),但我還是希望以下內容可以幫助人們保護自己的網站不被惡意攻擊,下文將指出每一種網路資料采集技術的缺點,你可以利用這些缺點保護自己的網站,其實,大多數網路機器人一開始都只能做一些寬泛的資訊和漏洞掃描,接下來介紹的幾個簡單技術就可以擋住 99% 的機器人,但是,它們進化的速度非常快,最好時刻準備迎接新的攻擊,
-
和大多數程式員一樣,我從來不相信禁止某一類資訊的傳播就可以讓世界變得更和諧,
閱讀之前,請牢記:這里演示的許多程式和介紹的技術都不應該在網站上使用,
爬蟲黑科技:
網路機器人看起來像人類用戶的一些方法
網站防采集的前提就是要正確地區分人類訪問用戶和網路機器人,雖然網站可以使用很多識別技術(比如驗證碼)來防止爬蟲,但還是有一些十分簡單的方法,可以讓你的網路機器人看起來更像人類訪問用戶,
1. 構造合理的 HTTP 請求頭
除了處理網站表單,requests 模塊還是一個設定請求頭的利器,HTTP 的請求頭是在你每次向網路服務器發送請求時,傳遞的一組屬性和配置資訊,HTTP 定義了十幾種古怪的請求頭型別,不過大多數都不常用,只有下面的七個欄位被大多數瀏覽器用來初始化所有網路請求(表中資訊是我自己瀏覽器的資料),

![]()
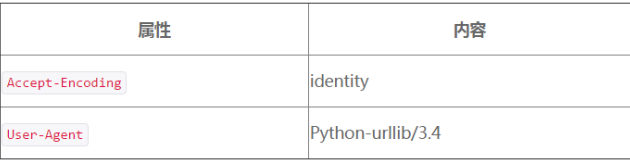
經典的 Python 爬蟲在使用 urllib 標準庫時,都會發送如下的請求頭:
![]()
如果你是一個防范爬蟲的網站管理員,你會讓哪個請求頭訪問你的網站呢?
安裝 Requests
可在模塊的網站上找到下載鏈接(http://docs.python-requests.org/en/latest/user/install/)和安裝方法,或者用任意第三方 Python 模塊安裝器進行安裝,
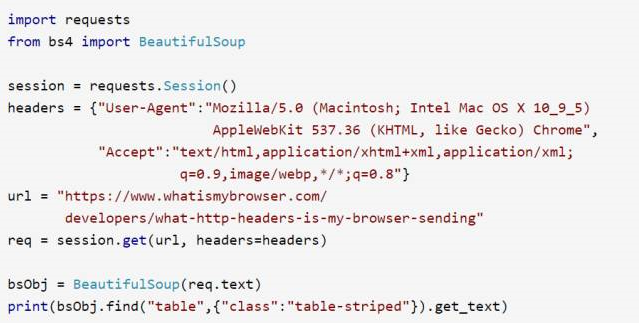
請求頭可以通過 requests 模塊進行自定義,https://www.whatismybrowser.com/ 網站就是一個非常棒的網站,可以讓服務器測驗瀏覽器的屬性,我們用下面的程式來采集這個網站的資訊,驗證我們瀏覽器的 cookie 設定:
![]()
程式輸出結果中的請求頭應該和程式中設定的 headers 是一樣的,
雖然網站可能會對 HTTP 請求頭的每個屬性進行“是否具有人性”的檢查,但是我發現通常真正重要的引數就是 User-Agent,無論做什么專案,一定要記得把 User-Agent 屬性設定成不容易引起懷疑的內容,不要用 Python-urllib/3.4,另外,如果你正在處理一個警覺性非常高的網站,就要注意那些經常用卻很少檢查的請求頭,比如 Accept-Language 屬性,也許它正是那個網站判斷你是個人類訪問者的關鍵,
請求頭會改變你觀看網路世界的方式
假設你想為一個機器學習的研究專案寫一個語言翻譯機,卻沒有大量的翻譯文本來測驗它的效果,很多大型網站都會為同樣的內容提供不同的語言翻譯,根據請求頭的引數回應網站不同的語言版本,因此,你只要簡單地把請求頭屬性從 Accept-Language:en-US 修改成 Accept-Language:fr,就可以從網站上獲得“Bonjour”(法語,你好)這些資料來改善翻譯機的翻譯效果了(大型跨國企業通常都是好的采集物件),
請求頭還可以讓網站改變內容的布局樣式,例如,用移動設備瀏覽網站時,通常會看到一個沒有廣告、Flash 以及其他干擾的簡化的網站版本,因此,把你的請求頭 User-Agent 改成下面這樣,就可以看到一個更容易采集的網站了!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53
2. 設定 cookie 的學問
雖然 cookie 是一把雙刃劍,但正確地處理 cookie 可以避免許多采集問題,網站會用 cookie 跟蹤你的訪問程序,如果發現了爬蟲例外行為就會中斷你的訪問,比如特別快速地填寫表單,或者瀏覽大量頁面,雖然這些行為可以通過關閉并重新連接或者改變 IP 地址來偽裝,但是如果 cookie 暴露了你的身份,再多努力也是白費,
在采集一些網站時 cookie 是不可或缺的,要在一個網站上持續保持登錄狀態,需要在多個頁面中保存一個 cookie,有些網站不要求在每次登錄時都獲得一個新 cookie,只要保存一個舊的“已登錄”的 cookie 就可以訪問,
如果你在采集一個或者幾個目標網站,建議你檢查這些網站生成的 cookie,然后想想哪一個 cookie 是爬蟲需要處理的,有一些瀏覽器插件可以為你顯示訪問網站和離開網站時 cookie 是如何設定的,EditThisCookie(http://www.editthiscookie.com/)是我最喜歡的 Chrome 瀏覽器插件之一,
因為 requests 模塊不能執行 JavaScript,所以它不能處理很多新式的跟蹤軟體生成的 cookie,比如 Google Analytics,只有當客戶端腳本執行后才設定 cookie(或者在用戶瀏覽頁面時基于網頁事件產生 cookie,比如點擊按鈕),要處理這些動作,需要用 Selenium 和 PhantomJS 包,
Selenium 與 PhantomJS
Selenium(http://www.seleniumhq.org/)是一個強大的網路資料采集工具,最初是為網站自動化測驗而開發的,近幾年,它還被廣泛用于獲取精確的網站快照,因為它們可以直接運行在瀏覽器上,Selenium 可以讓瀏覽器自動加載頁面,獲取需要的資料,甚至頁面截屏,或者判斷網站上某些動作是否發生,
Selenium 自己不帶瀏覽器,它需要與第三方瀏覽器結合在一起使用,例如,如果你在 Firefox 上運行 Selenium,可以直接看到 Firefox 視窗被打開,進入網站,然后執行你在代碼中設定的動作,雖然這樣可以看得更清楚,但是我更喜歡讓程式在后臺運行,所以我 PhantomJS(http://phantomjs.org/download.html)代替真實的瀏覽器,
PhantomJS 是一個“無頭”(headless)瀏覽器,它會把網站加載到記憶體并執行頁面上的 JavaScript,但不會向用戶展示網頁的圖形界面,將 Selenium 和 PhantomJS 結合在一起,就可以運行一個非常強大的網路爬蟲了,可以處理 cookie、JavaScrip、header,以及任何你需要做的事情,
可以從PyPI網站(https://pypi.python.org/simple/selenium/)下載Selenium庫,也可以用第三方管理器(像pip)用命令列安裝,
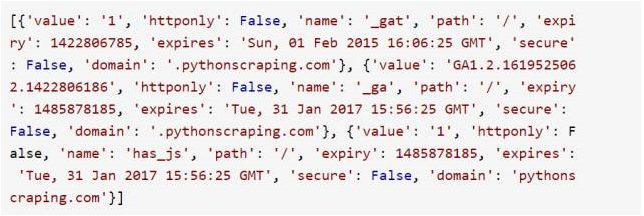
你可以對任意網站(本例用的是 http://pythonscraping.com)呼叫 webdriver 的 get_cookie()方法來查看 cookie:

![]()
點擊可查看大圖
這樣就可以獲得一個非常典型的 Google Analytics 的 cookie 串列:
![]()
點擊可查看大圖
還可以呼叫 delete_cookie()、add_cookie() 和 delete_all_cookies() 方法來處理 cookie,另外,還可以保存 cookie 以備其他網路爬蟲使用,下面的例子演示了如何把這些函陣列合在一起:

![]()
點擊可查看大圖
在這個例子中,第一個 webdriver 獲得了一個網站,列印 cookie 并把它們保存到變數savedCookies 里,第二個 webdriver 加載同一個網站(技術提示:必須首先加載網站,這樣 Selenium 才能知道 cookie 屬于哪個網站,即使加載網站的行為對我們沒任何用處),洗掉所有的 cookie,然后替換成第一個 webdriver 得到的 cookie,當再次加載這個頁面時,兩組 cookie 的時間戳、源代碼和其他資訊應該完全一致,從 Google Analytics 的角度看,第二個 webdriver 現在和第一個 webdriver 完全一樣,
3. 正常的時間訪問路徑
有一些防護措施完備的網站可能會阻止你快速地提交表單,或者快速地與網站進行互動,即使沒有這些安全措施,用一個比普通人快很多的速度從一個網站下載大量資訊也可能讓自己被網站封殺,
因此,雖然多執行緒程式可能是一個快速加載頁面的好辦法——在一個執行緒中處理資料,另一個執行緒中加載頁面——但是這對撰寫好的爬蟲來說是恐怖的策略,還是應該盡量保證一次加載頁面加載且資料請求最小化,如果條件允許,盡量為每個頁面訪問增加一點兒時間間隔,即使你要增加一行代碼:
time.sleep(3)(小編:3 + 亂數 是不是更好一些?)
合理控制速度是你不應該破壞的規則,過度消耗別人的服務器資源會讓你置身于非法境地,更嚴重的是這么做可能會把一個小型網站拖垮甚至下線,拖垮網站是不道德的,是徹頭徹尾的錯誤,所以請控制采集速度!
常見表單反爬蟲安全措施解密
許多像 Litmus 之類的測驗工具已經用了很多年了,現在仍用于區分網路爬蟲和使用瀏覽器的人類訪問者,這類手段都取得了不同程度的效果,雖然網路機器人下載一些公開的文章和博文并不是什么大事,但是如果網路機器人在你的網站上創造了幾千個賬號并開始向所有用戶發送垃圾郵件,就是一個大問題了,網路表單,尤其是那些用于賬號創建和登錄的網站,如果被機器人肆意地濫用,網站的安全和流量費用就會面臨嚴重威脅,因此努力限制網站的接入是最符合許多網站所有者的利益的(至少他們這么認為),
這些集中在表單和登錄環節上的反機器人安全措施,對網路爬蟲來說確實是嚴重的挑戰,
4. 注意隱含輸入欄位值
在 HTML 表單中,“隱含”欄位可以讓欄位的值對瀏覽器可見,但是對用戶不可見(除非看網頁源代碼),隨著越來越多的網站開始用 cookie 存盤狀態變數來管理用戶狀態,在找到另一個最佳用途之前,隱含欄位主要用于阻止爬蟲自動提交表單,
下圖顯示的例子就是 Facebook 登錄頁面上的隱含欄位,雖然表單里只有三個可見欄位(username、password 和一個確認按鈕),但是在源代碼里表單會向服務器傳送大量的資訊,
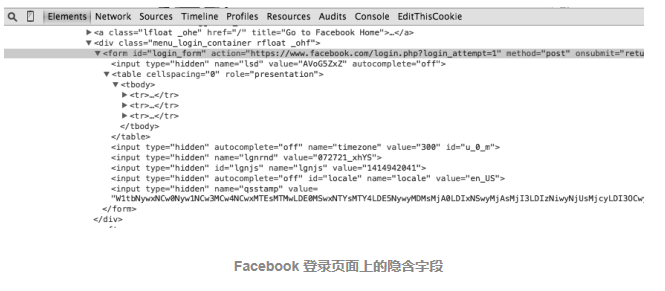
![]()
Facebook 登錄頁面上的隱含欄位
用隱含欄位阻止網路資料采集的方式主要有兩種,第一種是表單頁面上的一個欄位可以用服務器生成的隨機變數表示,如果提交時這個值不在表單處理頁面上,服務器就有理由認為這個提交不是從原始表單頁面上提交的,而是由一個網路機器人直接提交到表單處理頁面的,繞開這個問題的最佳方法就是,首先采集表單所在頁面上生成的隨機變數,然后再提交到表單處理頁面,
第二種方式是“蜜罐”(honey pot),如果表單里包含一個具有普通名稱的隱含欄位(設定蜜罐圈套),比如“用戶名”(username)或“郵箱地址”(email address),設計不太好的網路機器人往往不管這個欄位是不是對用戶可見,直接填寫這個欄位并向服務器提交,這樣就會中服務器的蜜罐圈套,服務器會把所有隱含欄位的真實值(或者與表單提交頁面的默認值不同的值)都忽略,而且填寫隱含欄位的訪問用戶也可能被網站封殺,
總之,有時檢查表單所在的頁面十分必要,看看有沒有遺漏或弄錯一些服務器預先設定好的隱含欄位(蜜罐圈套),如果你看到一些隱含欄位,通常帶有較大的隨機字串變數,那么很可能網路服務器會在表單提交的時候檢查它們,另外,還有其他一些檢查,用來保證這些當前生成的表單變數只被使用一次或是最近生成的(這樣可以避免變數被簡單地存盤到一個程式中反復使用),
5. 爬蟲通常如何避開蜜罐
雖然在進行網路資料采集時用 CSS 屬性區分有用資訊和無用資訊會很容易(比如,通過讀取 id和 class 標簽獲取資訊),但這么做有時也會出問題,如果網路表單的一個欄位通過 CSS 設定成對用戶不可見,那么可以認為普通用戶訪問網站的時候不能填寫這個欄位,因為它沒有顯示在瀏覽器上,如果這個欄位被填寫了,就可能是機器人干的,因此這個提交會失效,
這種手段不僅可以應用在網站的表單上,還可以應用在鏈接、圖片、檔案,以及一些可以被機器人讀取,但普通用戶在瀏覽器上卻看不到的任何內容上面,訪問者如果訪問了網站上的一個“隱含”內容,就會觸發服務器腳本封殺這個用戶的 IP 地址,把這個用戶踢出網站,或者采取其他措施禁止這個用戶接入網站,實際上,許多商業模式就是在干這些事情,
下面的例子所用的網頁在 http://pythonscraping.com/pages/itsatrap.html,這個頁面包含了兩個鏈接,一個通過 CSS 隱含了,另一個是可見的,另外,頁面上還包括兩個隱含欄位:

![]()
點擊可查看大圖
這三個元素通過三種不同的方式對用戶隱藏:
-
第一個鏈接是通過簡單的 CSS 屬性設定
display:none進行隱藏 -
電話號碼欄位
name="phone"是一個隱含的輸入欄位 -
郵箱地址欄位
name="email"是將元素向右移動 50 000 像素(應該會超出電腦顯示幕的邊界)并隱藏滾動條
因為 Selenium 可以獲取訪問頁面的內容,所以它可以區分頁面上的可見元素與隱含元素,通過 is_displayed() 可以判斷元素在頁面上是否可見,
例如,下面的代碼示例就是獲取前面那個頁面的內容,然后查找隱含鏈接和隱含輸入欄位:
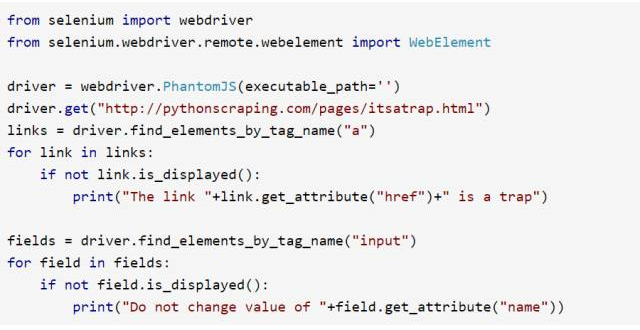
![]()
點擊可查看大圖
Selenium 抓取出了每個隱含的鏈接和欄位,結果如下所示:

![]()
點擊可查看大圖
雖然你不太可能會去訪問你找到的那些隱含鏈接,但是在提交前,記得確認一下那些已經在表單中、準備提交的隱含欄位的值(或者讓 Selenium 為你自動提交),
使用遠程服務器來避免 IP 封鎖
啟用遠程平臺的人通常有兩個目的:對更大計算能力和靈活性的需求,以及對可變 IP 地址的需求,
6. 使用可變的遠程 IP 地址
建立網路爬蟲的第一原則是:所有資訊都可以偽造,你可以用非本人的郵箱發送郵件,通過命令列自動化滑鼠的行為,或者通過 IE 5.0 瀏覽器耗費網站流量來嚇唬網管,
但是有一件事情是不能作假的,那就是你的 IP 地址,任何人都可以用這個地址給你寫信:“美國華盛頓特區賓夕法尼亞大道西北 1600 號,總統,郵編 20500,”但是,如果這封信是從新墨西哥州的阿爾伯克基市發來的,那么你肯定可以確信給你寫信的不是美國總統,
從技術上說,IP 地址是可以通過發送資料包進行偽裝的,就是分布式拒絕服務攻擊技術(Distributed Denial of Service,DDoS),攻擊者不需要關心接收的資料包(這樣發送請求的時候就可以使用假 IP 地址),但是網路資料采集是一種需要關心服務器回應的行為,所以我們認為 IP 地址是不能造假的,
阻止網站被采集的注意力主要集中在識別人類與機器人的行為差異上面,封殺 IP 地址這種矯枉過正的行為,就好像是農民不靠噴農藥給莊稼殺蟲,而是直接用火燒徹底解決問題,它是最后一步棋,不過是一種非常有效的方法,只要忽略危險 IP 地址發來的資料包就可以了,但是,使用這種方法會遇到以下幾個問題,
-
IP 地址訪問串列很難維護,雖然大多數大型網站都會用自己的程式自動管理 IP 地址訪問串列(機器人封殺機器人),但是至少需要人偶爾檢查一下串列,或者至少要監控問題的增長,
-
因為服務器需要根據 IP 地址訪問串列去檢查每個準備接收的資料包,所以檢查接收資料包時會額外增加一些處理時間,多個 IP 地址乘以海量的資料包更會使檢查時間指數級增長,為了降低處理時間和處理復雜度,管理員通常會對 IP 地址進行分組管理并制定相應的規則,比如如果這組 IP 中有一些危險分子就“把這個區間的所有 256 個地址全部封殺”,于是產生了下一個問題,
-
封殺 IP 地址可能會導致意外后果,例如,當我還在美國麻省歐林工程學院讀本科的時候,有個同學寫了一個可以在 http://digg.com/ 網站(在 Reddit 流行之前大家都用 Digg)上對熱門內容進行投票的軟體,這個軟體的服務器 IP 地址被 Digg 封殺,導致整個網站都不能訪問,于是這個同學就把軟體移到了另一個服務器上,而 Digg 自己卻失去了許多主要目標用戶的訪問量,
雖然有這些缺點,但封殺 IP 地址依然是一種十分常用的手段,服務器管理員用它來阻止可疑的網路爬蟲入侵服務器,
Tor 代理服務器
洋蔥路由(The Onion Router)網路,常用縮寫為 Tor,是一種 IP 地址匿名手段,由網路志愿者服務器構建的洋蔥路由器網路,通過不同服務器構成多個層(就像洋蔥)把客戶端包在最里面,資料進入網路之前會被加密,因此任何服務器都不能偷取通信資料,另外,雖然每一個服務器的入站和出站通信都可以被查到,但是要想查出通信的真正起點和終點,必須知道整個通信鏈路上所有服務器的入站和出站通信細節,而這基本是不可能實作的,
Tor 匿名的局限性
雖然我們在本文中用 Tor 的目的是改變 IP 地址,而不是實作完全匿名,但有必要關注一下 Tor 匿名方法的能力和不足,
雖然 Tor 網路可以讓你訪問網站時顯示的 IP 地址是一個不能跟蹤到你的 IP 地址,但是你在網站上留給服務器的任何資訊都會暴露你的身份,例如,你登錄 Gmail 賬號后再用 Google 搜索,那些搜索歷史就會和你的身份系結在一起,
另外,登錄 Tor 的行為也可能讓你的匿名狀態處于危險之中,2013 年 12 月,一個哈佛大學本科生想逃避期末考試,就用一個匿名郵箱賬號通過 Tor 網路給學校發了一封炸彈威脅信,結果哈佛大學的 IT 部門通過日志查到,在炸彈威脅信發來的時候,Tor 網路的流量只來自一臺機器,而且是一個在校學生注冊的,雖然他們不能確定流量的最初源頭(只知道是通過 Tor 發送的),但是作案時間和注冊資訊證據充分,而且那個時間段內只有一臺機器是登錄狀態,這就有充分理由起訴那個學生了,
登錄 Tor 網路不是一個自動的匿名措施,也不能讓你進入互聯網上任何區域,雖然它是一個實用的工具,但是用它的時候一定要謹慎、清醒,并且遵守道德規范,
在 Python 里使用 Tor,需要先安裝運行 Tor,下一節將介紹,Tor 服務很容易安裝和開啟,只要去 Tor 下載頁面下載并安裝,打開后連接就可以,不過要注意,當你用 Tor 的時候網速會變慢,這是因為代理有可能要先在全世界網路上轉幾次才到目的地!
PySocks
PySocks 是一個非常簡單的 Python 代理服務器通信模塊,它可以和 Tor 配合使用,你可以從它的網站(https://pypi.python.org/pypi/PySocks)上下載,或者使用任何第三方模塊管理器安裝,
這個模塊的用法很簡單,示例代碼如下所示,運行的時候,Tor 服務必須運行在 9150 埠(默認值)上:
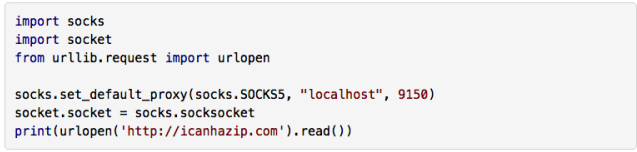
![]()
網站 http://icanhazip.com/ 會顯示客戶端連接的網站服務器的 IP 地址,可以用來測驗 Tor 是否正常運行,當程式執行之后,顯示的 IP 地址就不是你原來的 IP 了,
如果你想在 Tor 里面用 Selenium 和 PhantomJS,不需要 PySocks,只要保證 Tor 在運行,然后增加 service_args 引數設定代理埠,讓 Selenium 通過埠 9150 連接網站就可以了:
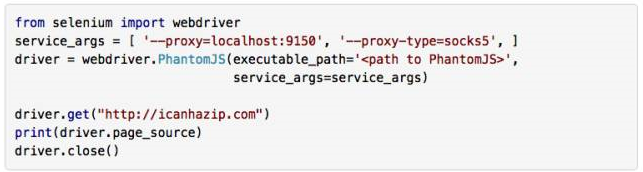
![]()
和之前一樣,這個程式列印的 IP 地址也不是你原來的,而是你通過 Tor 客戶端獲得的 IP 地址,
從網站主機運行
如果你擁有個人網站或公司網站,那么你可能已經知道如何使用外部服務器運行你的網路爬蟲了,即使是一些相對封閉的網路服務器,沒有可用的命令列接入方式,你也可以通過網頁界面對程式進行控制,
如果你的網站部署在 Linux 服務器上,應該已經運行了 Python,如果你用的是 Windows 服務器,可能就沒那么幸運了;你需要仔細檢查一下 Python 有沒有安裝,或者問問網管可不可以安裝,
大多數小型網路主機都會提供一個軟體叫 cPanel,提供網站管理和后臺服務的基本管理功能和資訊,如果你接入了 cPanel,就可以設定 Python 在服務器上運行——進入“Apache Handlers”然后增加一個 handler(如還沒有的話):

![]()
這會告訴服務器所有的 Python 腳本都將作為一個 CGI 腳本運行,CGI 就是通用網關介面(Common Gateway Interface),是可以在服務器上運行的任何程式,會動態地生成內容并顯示在網站上,把 Python 腳本顯式地定義成 CGI 腳本,就是給服務器權限去執行 Python 腳本,而不只是在瀏覽器上顯示它們或者讓用戶下載它們,
寫完 Python 腳本后上傳到服務器,然后把檔案權限設定成 755,讓它可執行,通過瀏覽器找到程式上傳的位置(也可以寫一個爬蟲來自動做這件事情)就可以執行程式,如果你擔心在公共領域執行腳本不安全,可以采取以下兩種方法,
-
把腳本存盤在一個隱晦或深層的 URL 里,確保其他 URL 鏈接都不能接入這個腳本,這樣可以避免搜索引擎發現它,
-
用密碼保護腳本,或者在執行腳本之前用密碼或加密令牌進行確認,
確實,通過這些原本主要是用來顯示網站的服務運行 Python 腳本有點兒復雜,比如,你可能會發現網路爬蟲運行時網站的加載速度變慢了,其實,在整個采集任務完成之前頁面都是不會加載的(得等到所有“print”陳述句的輸出內容都顯示完),這可能會消耗幾分鐘,幾小時,甚至永遠也完成不了,要看程式的具體情況了,雖然它最終一定能完成任務,但是可能你還想看到實時的結果,這樣就需要一臺真正的服務器了,
從云主機運行
雖然云計算的花費可能是無底洞,但是寫這篇文章時,啟動一個計算實體最便宜只要每小時 1.3 美分(亞馬遜 EC2 的 micro 實體,其他實體會更貴),Google 最便宜的計算實體是每小時 4.5 美分,最少需要用 10 分鐘,考慮計算能力的規模效應,從大公司買一個小型的云計算實體的費用,和自己買一臺專業物體機的費用應該差不多——不過用云計算不需要雇人去維護設備,
設定好計算實體之后,你就有了新 IP 地址、用戶名,以及可以通過 SSH 進行實體連接的公私密鑰了,后面要做的每件事情,都應該和你在物體服務器上干的事情一樣了——當然,你不需要再擔心硬體維護,也不用運行復雜多余的監控工具了,
總結
爬蟲被封禁常見原因串列
如果你一直被網站封殺卻找不到原因,那么這里有個檢查串列,可以幫你診斷一下問題出在哪里,
-
首先,檢查 JavaScript ,如果你從網路服務器收到的頁面是空白的,缺少資訊,或其遇到他不符合你預期的情況(或者不是你在瀏覽器上看到的內容),有可能是因為網站創建頁面的 JavaScript 執行有問題,
-
檢查正常瀏覽器提交的引數,如果你準備向網站提交表單或發出
POST請求,記得檢查一下頁面的內容,看看你想提交的每個欄位是不是都已經填好,而且格式也正確,用 Chrome 瀏覽器的網路面板(快捷鍵 F12 打開開發者控制臺,然后點擊“Network”即可看到)查看發送到網站的POST命令,確認你的每個引數都是正確的, -
是否有合法的 Cookie?如果你已經登錄網站卻不能保持登錄狀態,或者網站上出現了其他的“登錄狀態”例外,請檢查你的 cookie,確認在加載每個頁面時 cookie 都被正確呼叫,而且你的 cookie 在每次發起請求時都發送到了網站上,
-
IP 被封禁?如果你在客戶端遇到了 HTTP 錯誤,尤其是 403 禁止訪問錯誤,這可能說明網站已經把你的 IP 當作機器人了,不再接受你的任何請求,你要么等待你的 IP 地址從網站黑名單里移除,要么就換個 IP 地址(可以去星巴克上網),如果你確定自己并沒有被封殺,那么再檢查下面的內容,
-
確認你的爬蟲在網站上的速度不是特別快,快速采集是一種惡習,會對網管的服務器造成沉重的負擔,還會讓你陷入違法境地,也是 IP 被網站列入黑名單的首要原因,給你的爬蟲增加延遲,讓它們在夜深人靜的時候運行,切記:匆匆忙忙寫程式或收集資料都是拙劣專案管理的表現;應該提前做好計劃,避免臨陣慌亂,
-
還有一件必須做的事情:修改你的請求頭!有些網站會封殺任何聲稱自己是爬蟲的訪問者,如果你不確定請求頭的值怎樣才算合適,就用你自己瀏覽器的請求頭吧,
-
確認你沒有點擊或訪問任何人類用戶通常不能點擊或接入的資訊,
-
如果你用了一大堆復雜的手段才接入網站,考慮聯系一下網管吧,告訴他們你的目的,試試發郵件到 webmaster@< 域名 > 或 admin@< 域名 >,請求網管允許你使用爬蟲采集資料,管理員也是人嘛!
-
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/188892.html
標籤:其他