目標網站:https://www.mn52.com/
本文代碼已上傳至git和百度網盤,鏈接分享在文末
網站概覽

目標,使用scrapy框架抓取全部圖片并分類保存到本地,
1.創建scrapy專案
scrapy startproject images
2.創建spider
cd images
scrapy genspider mn52 www.mn52.com
創建后結構目錄如下
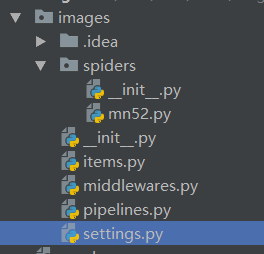
3.定義item定義爬取欄位
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy class ImagesItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() image_url = scrapy.Field() field_name = scrapy.Field() detail_name = scrapy.Field()
這里定義三個欄位,分別為圖片地址,圖片類別名稱和圖片詳細類別名稱
4.撰寫spider
# -*- coding: utf-8 -*- import scrapy import requests from lxml import etree from images.items import ImagesItem class Mn52Spider(scrapy.Spider): name = 'mn52' # allowed_domains = ['www.mn52.com'] # start_urls = ['http://www.mn52.com/'] def start_requests(self): response = requests.get('https://www.mn52.com/') result = etree.HTML(response.text) li_lists = result.xpath('//*[@id="bs-example-navbar-collapse-2"]/div/ul/li') for li in li_lists: url = li.xpath('./a/@href')[0] field_name = li.xpath('./a/text()')[0] print('https://www.mn52.com' + url,field_name) yield scrapy.Request('https://www.mn52.com' + url,meta={'field_name':field_name},callback=self.parse) def parse(self, response): field_name = response.meta['field_name'] div_lists = response.xpath('/html/body/section/div/div[1]/div[2]/div') for div_list in div_lists: detail_urls = div_list.xpath('./div/a/@href').extract_first() detail_name = div_list.xpath('./div/a/@title').extract_first() yield scrapy.Request(url='https:' + detail_urls,callback=self.get_image,meta={'detail_name':detail_name,'field_name':field_name}) url_lists = response.xpath('/html/body/section/div/div[3]/div/div/nav/ul/li') for url_list in url_lists: next_url = url_list.xpath('./a/@href').extract_first() if next_url: yield scrapy.Request(url='https:' + next_url,callback=self.parse,meta=response.meta) def get_image(self,response): field_name = response.meta['field_name'] image_urls = response.xpath('//*[@id="originalpic"]/img/@src').extract() for image_url in image_urls: item = ImagesItem() item['image_url'] = 'https:' + image_url item['field_name'] = field_name item['detail_name'] = response.meta['detail_name'] # print(item['image_url'],item['field_name'],item['detail_name']) yield item
邏輯思路:spider中重寫start_requests獲取起始路由,這里起始路由設為圖片的一級分類如性感美女,清純美女,萌寵圖片等的地址,使用requests庫請求mn52.com來決議獲取,然后把url和一級分類名稱傳遞給parse,在parse中決議獲取圖片的二級分類地址和二級分類名稱,并判斷是否含有下一頁資訊,這里使用scrapy框架自動去重原理,所以不用再寫去重邏輯,獲取到的資料傳遞給get_image,在get_image中決議出圖片路由并賦值到item欄位中然后yield item.
5.pipelines管道檔案下載圖片
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import scrapy import os # 匯入scrapy 框架里的 管道檔案的里的影像 影像處理的專用管道檔案 from scrapy.pipelines.images import ImagesPipeline # 匯入圖片路徑名稱 from images.settings import IMAGES_STORE as images_store class Image_down(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(url=item['image_url']) def item_completed(self, results, item, info): print(results) image_url = item['image_url'] image_name = image_url.split('/')[-1] old_name_list = [x['path'] for t, x in results if t] # 真正的原圖片的存盤路徑 old_name = images_store + old_name_list[0] image_path = images_store + item['field_name'] + '/' + item['detail_name'] + '/' # 判斷圖片存放的目錄是否存在 if not os.path.exists(image_path): # 根據當前頁碼創建對應的目錄 os.makedirs(image_path) # 新名稱 new_name = image_path + image_name # 重命名 os.rename(old_name, new_name) return item
分析:scrapy內置的ImagesPipeline自己生成經過md5加密的圖片名稱,這里匯入os模塊來使圖片下載到自定義的檔案夾和名稱,需要繼承ImagesPipeline類,
6.settings中設定所需引數(部分)
#USER_AGENT = 'images (+http://www.yourdomain.com)' USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36' #指定輸出某一種日志資訊 LOG_LEVEL = 'ERROR' #將日志資訊存盤到指定檔案中,不在終端輸出 LOG_FILE = 'log.txt' # Obey robots.txt rules ROBOTSTXT_OBEY = False IMAGES_STORE = './mn52/' ITEM_PIPELINES = { # 'images.pipelines.ImagesPipeline': 300, 'images.pipelines.Image_down': 301, }
說明:settings中主要定義了圖片的存盤路徑,user_agent資訊,打開下載管道,
7.創建crawl.py檔案,運行爬蟲
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52是爬蟲名 process.crawl('mn52') process.start()
這里沒有使用cmdline方法運行程式,因為涉及到后面的打包問題,使用cmdline方法無法打包,
8.至此,scrapy爬蟲已撰寫完畢,右鍵運行crawl檔案啟動爬蟲,圖片就會下載,
控制臺輸出: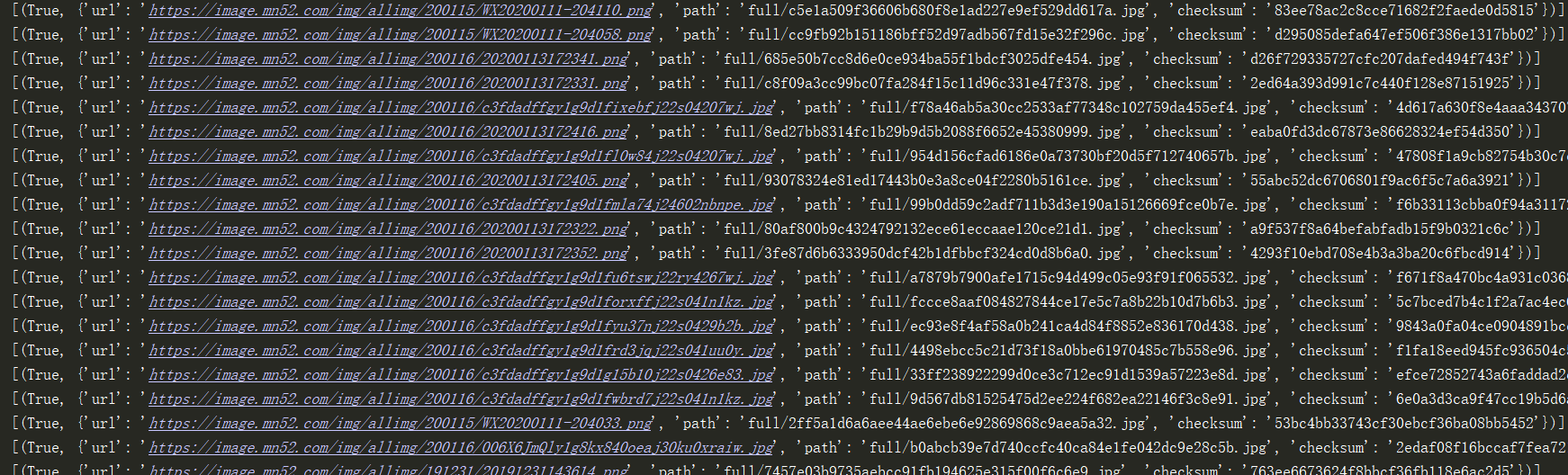
打開檔案夾查看圖片
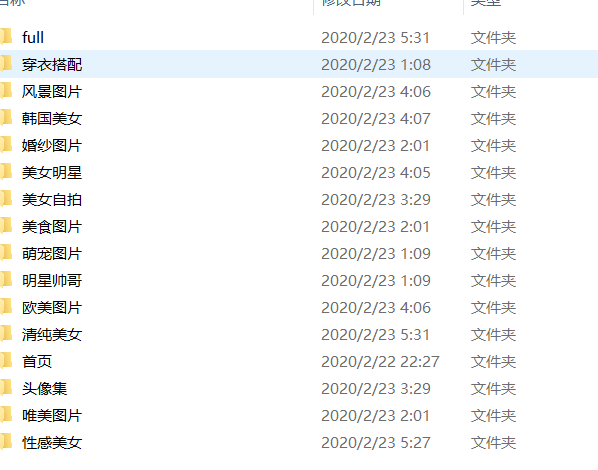
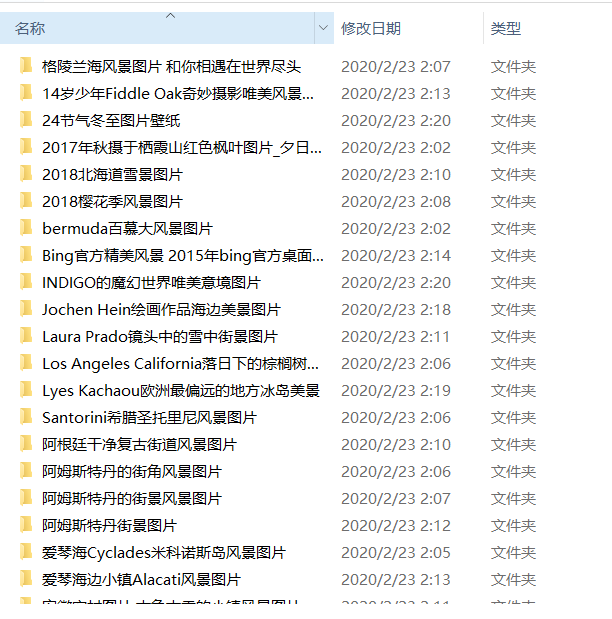
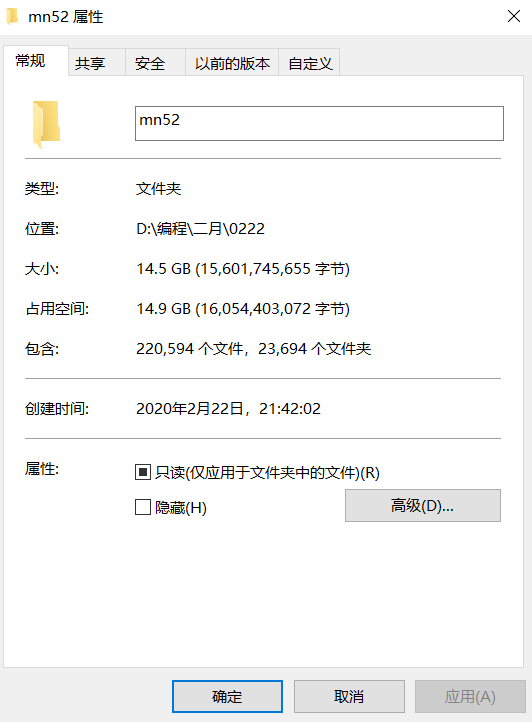
全站下載完成的話大概有22萬張圖片
9.打包scrapy爬蟲,
scrapy爬蟲作為一個框架爬蟲也是可以被打包成exe檔案的,是不是很神奇/??
打包步驟:
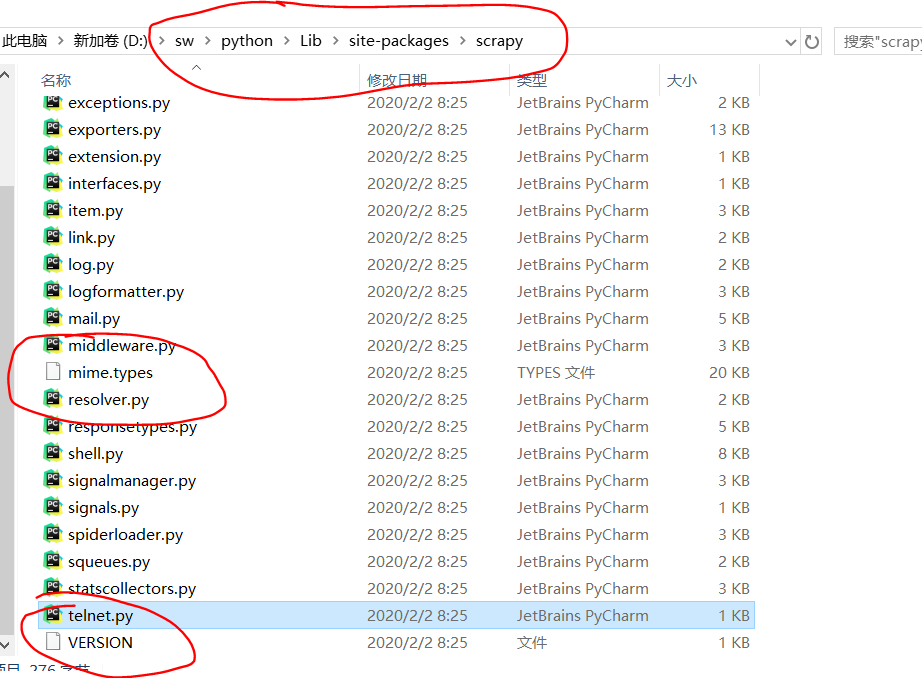
1>在你的python安裝目錄下找到scrapy復制其中的mime.types和VERSION檔案到專案目錄下,一般路徑如下
2>在專案下創建generate_cfg.py檔案,用來生成scrapy.cfg
data = https://www.cnblogs.com/nmsghgnv/p/''' [settings] default = images.settings [deploy] # url = http://localhost:6800/ project = images ''' with open('scrapy.cfg', 'w') as f: f.write(data)
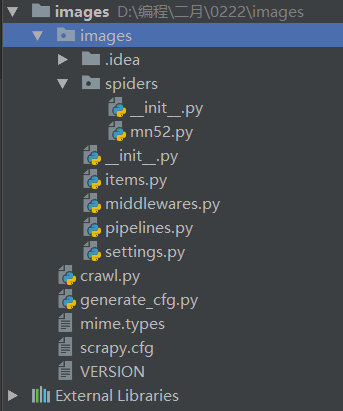
完成后專案結構如下
3>crawl.py檔案內引入專案所需的庫
import scrapy.spiderloader import scrapy.statscollectors import scrapy.logformatter import scrapy.dupefilters import scrapy.squeues import scrapy.extensions.spiderstate import scrapy.extensions.corestats import scrapy.extensions.telnet import scrapy.extensions.logstats import scrapy.extensions.memusage import scrapy.extensions.memdebug import scrapy.extensions.feedexport import scrapy.extensions.closespider import scrapy.extensions.debug import scrapy.extensions.httpcache import scrapy.extensions.statsmailer import scrapy.extensions.throttle import scrapy.core.scheduler import scrapy.core.engine import scrapy.core.scraper import scrapy.core.spidermw import scrapy.core.downloader import scrapy.downloadermiddlewares.stats import scrapy.downloadermiddlewares.httpcache import scrapy.downloadermiddlewares.cookies import scrapy.downloadermiddlewares.useragent import scrapy.downloadermiddlewares.httpproxy import scrapy.downloadermiddlewares.ajaxcrawl import scrapy.downloadermiddlewares.chunked import scrapy.downloadermiddlewares.decompression import scrapy.downloadermiddlewares.defaultheaders import scrapy.downloadermiddlewares.downloadtimeout import scrapy.downloadermiddlewares.httpauth import scrapy.downloadermiddlewares.httpcompression import scrapy.downloadermiddlewares.redirect import scrapy.downloadermiddlewares.retry import scrapy.downloadermiddlewares.robotstxt import os import scrapy.spidermiddlewares.depth import scrapy.spidermiddlewares.httperror import scrapy.spidermiddlewares.offsite import scrapy.spidermiddlewares.referer import scrapy.spidermiddlewares.urllength from scrapy.pipelines.images import ImagesPipeline import scrapy.pipelines from images.settings import IMAGES_STORE as images_store import scrapy.core.downloader.handlers.http import scrapy.core.downloader.contextfactory import requests from lxml import etree from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # mn52是爬蟲名 process.crawl('mn52') process.start()
10.使用pyinstaller第三方打包庫打包
如果沒有安裝的話使用pip安裝
pip install pyinstaller
在專案下使用打包命令
pyinstaller -F --add-data=https://www.cnblogs.com/nmsghgnv/p/mime.types;scrapy --add-data=VERSION;scrapy --add-data=images/*py;images --add-data=images/spiders/*.py;images/spiders --runtime-hook=generate_cfg.py crawl.py
一共用了4個--add-data命令以及1個--runtime-hook命令
第一個--add-data用來mime.types檔案,添加后放在臨時檔案夾中的scrapy檔案夾內,
第二個用來添加VERSION檔案,添加后的檔案同mime.types相同
第三個用來添加scrapy的代碼——images檔案夾下的所有py檔案,*代表通配符
第四個用來添加scrapy的代碼——mn52檔案夾下的所有py檔案
--runtime-hook用于添加運行鉤子,也就是這里的generate_cfg.py檔案
命令執行完畢后在dist檔案夾內生成可執行檔案,雙擊可執行檔案,同路徑下生成scrapy_cfg部署檔案和mn52圖片檔案夾,運行么有問題

代碼地址git:https://github.com/terroristhouse/crawler
exe可執行檔案地址(無需python環境):
鏈接:https://pan.baidu.com/s/19TkeDY9EHMsFPULudOJRzw
提取碼:8ell
python系列教程:
鏈接:https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
提取碼:h0td
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/189855.html
標籤:Python