傳送門
創建一個百度語音的應用
首先需要登錄百度云,接著進入我的控制臺,打開百度語音,進入語音應用管理界面,創建一個新的應用
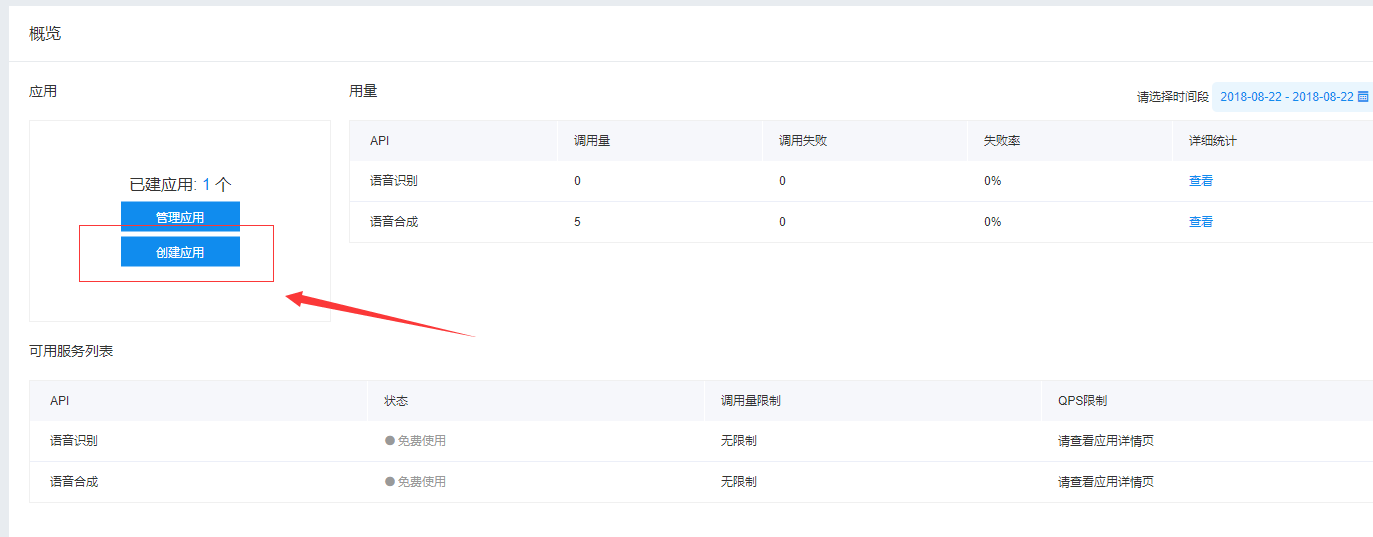
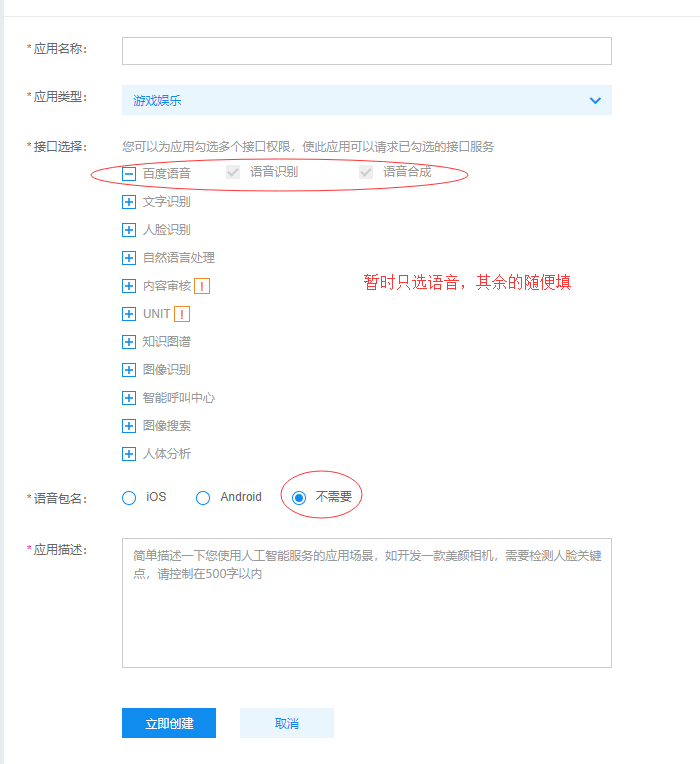
接著就能看到自己創建的應用啦

這里面有三個值 AppID , API Key , Secret Key 記住可以從這里面看到 , 在之后的學習中我們會用到
好了 百度語音的應用已經創建完成了 接下來 我會用Python 代碼作為實體進行應用及講解
安裝百度的人工智能SDK
- 首先咱們要 pip install baidu-aip 安裝一個百度人工智能開放平臺的Python SDK實在是太方便了,這也是為什么我們選擇百度人工智能的最大原因
語音合成
-
安裝好后我們先來測驗下,語音合成功能,
-
具體引數,不詳盡之處請看官方檔案:傳送門
- 這一步會生成一個名字為audio.m4a的檔案

from aip import AipSpeech
import os
APP_ID = '11711274'
API_KEY = 'iL6rNZgPjplCGYQfw86zO2ro'
SECRET_KEY = '0YNfOLiAPUgqCL4XxYVoO2oLV37pmByY'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你好啊', 'zh', 1, {
"spd": 4,
'vol': 8,
"pit": 6,
"per": 0,
})
# 識別正確回傳語音二進制 錯誤則回傳dict 參照下面錯誤碼
if not isinstance(result, dict):
with open('audio.m4a', 'wb') as f:
f.write(result)
else:
print(result)
回到頂部
二、語音識別
安裝音頻轉換工具FFmpeg
-
聲音這個東西格式太多樣化了,如果要想讓百度的SDK識別咱們的音頻檔案,就要想辦法轉變成百度SDK可以識別的格式PCM,
-
這里我們選擇的是FFmpeg ,下載好后配置好環境變數,
- 即可在CMD中使用
ffmpeg -y -i audio.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
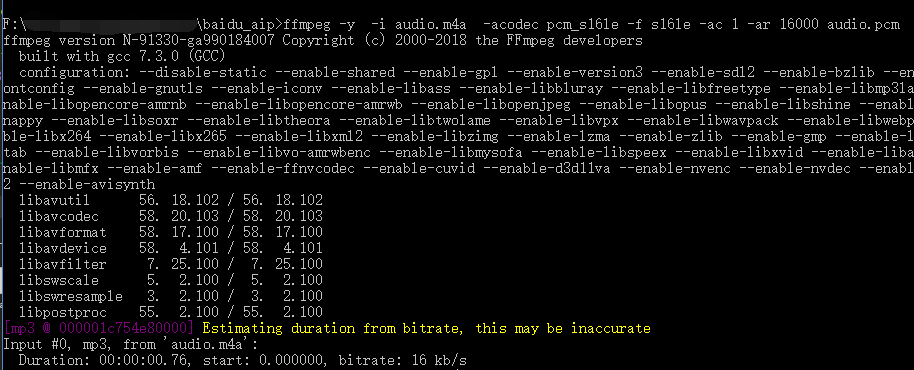
- 接著在檔案夾中就可以看到pcm格式的檔案了

百度語音識別SDK應用
-
好了準備作業都做好了就開始到正式接觸人工智障了
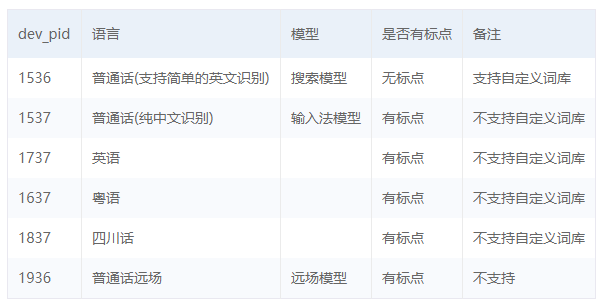
- asr函式需要四個引數,第四個引數可以忽略,自有默認值,參照一下這些引數是做什么的
-
第一個引數: speech 音頻檔案流 建立包含語音內容的Buffer物件, 語音檔案的格式,pcm 或者 wav 或者 amr,(雖說支持這么多格式,但是只有pcm的支持是最好的) 第二個引數: format 檔案的格式,包括pcm(不壓縮)、wav、amr (雖說支持這么多格式,但是只有pcm的支持是最好的) 第三個引數: rate 音頻檔案采樣率 如果使用剛剛的FFmpeg的命令轉換的,你的pcm檔案就是16000 第四個引數: dev_pid 音頻檔案語言id 默認1537(普通話 輸入法模型)
from aip import AipSpeech
import os
APP_ID = '11711274'
API_KEY = 'iL6rNZgPjplCGYQfw86zO2ro'
SECRET_KEY = '0YNfOLiAPUgqCL4XxYVoO2oLV37pmByY'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 識別本地檔案
res = client.asr(get_file_content('audio.pcm'), 'pcm', 16000,{
'dev_pid': 1536,
})
print(
res.get("result")[0]
)
- 接著來看看回傳值
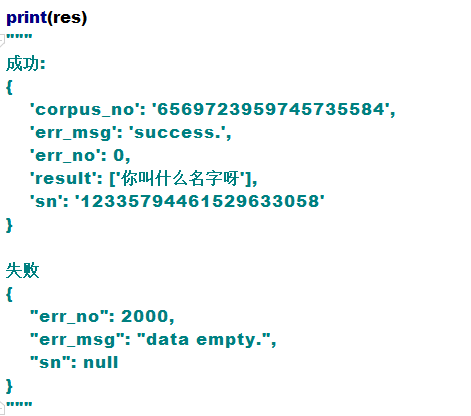
成功的dict中 result 就是我們要的識別文本
失敗的dict中 err_no 就是我們要的錯誤編碼,錯誤編碼代表什么呢?

如果err_no不是0的話,就參照一下錯誤碼表
到此百度AI語音部分的呼叫就結束了,是不是感覺很簡單,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/189861.html
標籤:Python
上一篇:python成語接龍小游戲
下一篇:python做個谷歌內核瀏覽器