前言
在了解深度學習框架之前,我們需要自己去理解甚至去實作一個網路學習和調參的程序,進而理解深度學習的機理;
為此,博主這里提供了一個自己撰寫的一個例子,帶領大家理解一下網路學習的正向傳播和反向傳播的程序;
除此之外,為了實作batch讀取,我還設計并提供了一個簡單的DataLoader類去模擬深度學習中資料迭代器的取樣;并且提供了存取模型的函式;
值得注意的是僅僅使用python實作,因此對于環境的需求不是很大,希望各位可以多多star我的博客和github,學習到更有用的知識!!
目錄
一、實作效果
二、整體代碼框架
三、詳細代碼說明
1.資料處理
2.網路設計
3.激活函式
4.訓練
四、訓練演示
五、總結
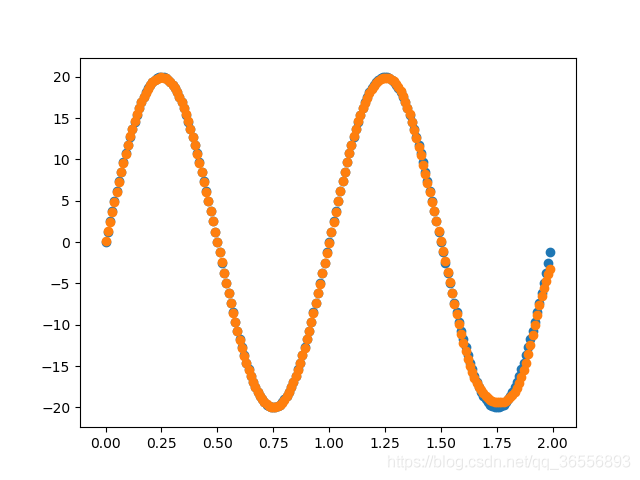
一、實作效果
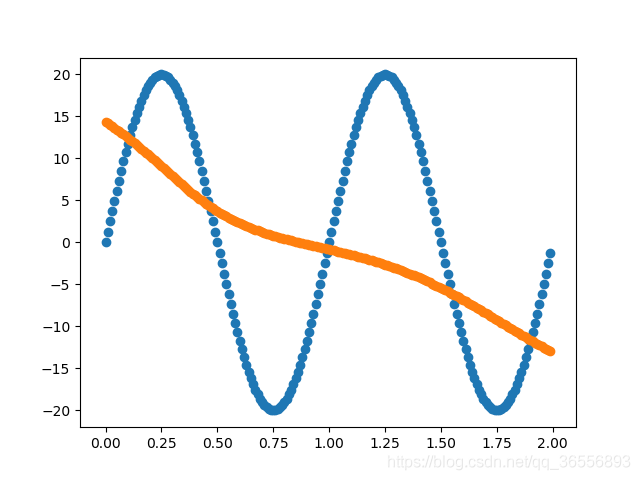
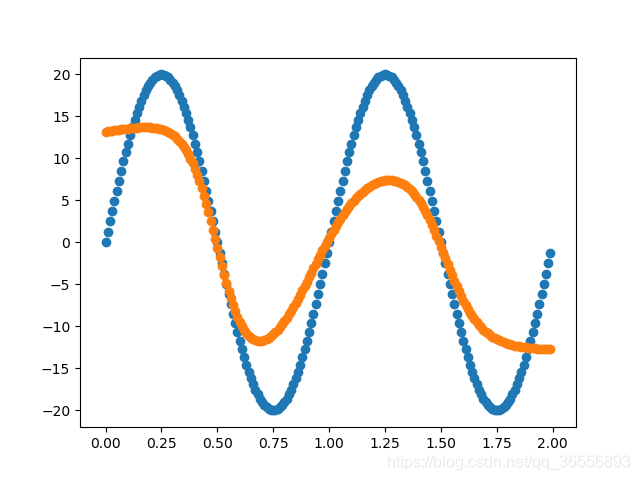
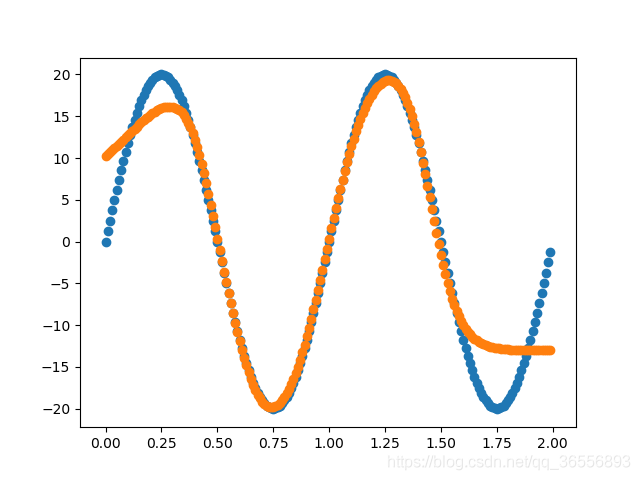
實作一個由多個Linear層構成的網路來擬合函式,專案地址:https://github.com/nickhuang1996/HJLNet,運行:
python demo.py
擬合函式為:
以下結果從左到右依次為(學習率為0.03,batchsize為90):
Epoch:400,1000, 2000, 10000以上
二、整體代碼框架
三、詳細代碼說明
1.資料處理
Dataset.py
x是0到2之間的資料,步長為0.01,因此是200個資料;
y是目標函式,振幅為20;
length是資料長度;
_build_items()是建立一個dict存盤x和y;
_transform()是對x和y進行資料的變換;
import numpy as np
class Dataset:
def __init__(self):
self.x = np.arange(0.0, 2.0, 0.01)
self.y = 20 * np.sin(2 * np.pi * self.x)
self.length = len(list(self.x))
self._build_items()
self._transform()
def _build_items(self):
self.items = [{
'x': list(self.x)[i],
'y': list(self.y)[i]
}for i in range(self.length)]
def _transform(self):
self.x = self.x.reshape(1, self.__len__())
self.y = self.y.reshape(1, self.__len__())
def __len__(self):
return self.length
def __getitem__(self, index):
return self.items[index]DataLoader.py
類似于Pytorch里的DataLoader,博主這里初始化也傳入兩個引數:dataset和batch_size
__next__()就是每次迭代執行的函式,利用__len__()得到dataset的長度,利用__getitem__()得到資料集里的資料;
_concate()就是把一個batch的資料拼接起來;
_transform()就是轉換一個batch的資料形式;
import numpy as np
class DataLoader:
def __init__(self, dataset, batch_size):
self.dataset = dataset
self.batch_size = batch_size
self.current = 0
def __next__(self):
if self.current < self.dataset.__len__():
if self.current + self.batch_size <= self.dataset.__len__():
item = self._concate([self.dataset.__getitem__(index) for index in range(self.current, self.current + self.batch_size)])
self.current += self.batch_size
else:
item = self._concate([self.dataset.__getitem__(index) for index in range(self.current, self.dataset.__len__())])
self.current = self.dataset.__len__()
return item
else:
self.current = 0
raise StopIteration
def _concate(self, dataset_items):
concated_item = {}
for item in dataset_items:
for k, v in item.items():
if k not in concated_item:
concated_item[k] = [v]
else:
concated_item[k].append(v)
concated_item = self._transform(concated_item)
return concated_item
def _transform(self, concated_item):
for k, v in concated_item.items():
concated_item[k] = np.array(v).reshape(1, len(v))
return concated_item
def __iter__(self):
return self
2.網路設計
Linear.py
類似于Pytorch里的Linear,博主這里初始化也傳入三個引數:in_features, out_features, bias
_init_parameters()是初始化權重weight和偏置bias,weight大小是[out_features, in_features],bias大小是[out_features, 1]
forward就是前向傳播:
import numpy as np
class Linear:
def __init__(self, in_features, out_features, bias=False):
self.in_features = in_features
self.out_features = out_features
self.bias = bias
self._init_parameters()
def _init_parameters(self):
self.weight = np.random.random([self.out_features, self.in_features])
if self.bias:
self.bias = np.zeros([self.out_features, 1])
else:
self.bias = None
def forward(self, input):
return self.weight.dot(input) + self.bias
*network.py
一個簡單的多層Linear網路
_init_parameters()是把Linear層里的權重和偏執都放在一個dict里存盤;
forward()就是前向傳播,最后一層不經過Sigmoid;
backward()就是反向傳播,利用梯度下降實作誤差傳遞和調參:例如一個兩層的Linear層的反向傳播如下
update_grads()是更新權重和偏置;
# -*- coding: UTF-8 -*-
import numpy as np
from ..lib.Activation.Sigmoid import sigmoid_derivative, sigmoid
from ..lib.Module.Linear import Linear
class network:
def __init__(self, layers_dim):
self.layers_dim = layers_dim
self.linear_list = [Linear(layers_dim[i - 1], layers_dim[i], bias=True) for i in range(1, len(layers_dim))]
self.parameters = {}
self._init_parameters()
def _init_parameters(self):
for i in range(len(self.layers_dim) - 1):
self.parameters["w" + str(i)] = self.linear_list[i].weight
self.parameters["b" + str(i)] = self.linear_list[i].bias
def forward(self, x):
a = []
z = []
caches = {}
a.append(x)
z.append(x)
layers = len(self.parameters) // 2
for i in range(layers):
z_temp = self.linear_list[i].forward(a[i])
self.parameters["w" + str(i)] = self.linear_list[i].weight
self.parameters["b" + str(i)] = self.linear_list[i].bias
z.append(z_temp)
if i == layers - 1:
a.append(z_temp)
else:
a.append(sigmoid(z_temp))
caches["z"] = z
caches["a"] = a
return caches, a[layers]
def backward(self, caches, output, y):
layers = len(self.parameters) // 2
grads = {}
m = y.shape[1]
for i in reversed(range(layers)):
# 假設最后一層不經歷激活函式
# 就是按照上面的圖片中的公式寫的
if i == layers - 1:
grads["dz" + str(i)] = output - y
else: # 前面全部都是sigmoid激活
grads["dz" + str(i)] = self.parameters["w" + str(i + 1)].T.dot(
grads["dz" + str(i + 1)]) * sigmoid_derivative(
caches["z"][i + 1])
grads["dw" + str(i)] = grads["dz" + str(i)].dot(caches["a"][i].T) / m
grads["db" + str(i)] = np.sum(grads["dz" + str(i)], axis=1, keepdims=True) / m
return grads
# 就是把其所有的權重以及偏執都更新一下
def update_grads(self, grads, learning_rate):
layers = len(self.parameters) // 2
for i in range(layers):
self.parameters["w" + str(i)] -= learning_rate * grads["dw" + str(i)]
self.parameters["b" + str(i)] -= learning_rate * grads["db" + str(i)]3.激活函式
Sigmoid.py
公式定義:
導數可由自身表示:
import numpy as np
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
4.訓練
demo.py
訓練模型的入口檔案,包含訓練、測驗和存盤模型
from code.scripts.trainer import Trainer
from code.config.default_config import _C
if __name__ == '__main__':
trainer = Trainer(cfg=_C)
trainer.train()
trainer.test()
trainer.save_models()
default_config.py
組態檔:
layers_dim代表Linear層的輸入輸出維度;
batch_size是batch的大小;
total_epochs是總體的訓練時間,訓練一次x為一個epoch;
resume是判斷繼續訓練;
result_img_path是結果存盤的路徑;
ckpt_path是模型存盤的路徑;
from easydict import EasyDict
_C = EasyDict()
_C.layers_dim = [1, 25, 1] # [1, 30, 10, 1]
_C.batch_size = 90
_C.total_epochs = 40000
_C.resume = True # False means retraining
_C.result_img_path = "D:/project/Pycharm/HJLNet/result.png"
_C.ckpt_path = 'D:/project/Pycharm/HJLNet/ckpt.npy'trainer.py
這里不多贅述,主要利用train()這個函式進行訓練,test()進行測驗
from ..lib.Data.DataLoader import DataLoader
from ..scripts.Dataset import Dataset
from ..scripts.network import network
import matplotlib.pyplot as plt
import numpy as np
class Trainer:
def __init__(self, cfg):
self.ckpt_path = cfg.ckpt_path
self.result_img_path = cfg.result_img_path
self.layers_dim = cfg.layers_dim
self.net = network(self.layers_dim)
if cfg.resume:
self.load_models()
self.dataset = Dataset()
self.dataloader = DataLoader(dataset=self.dataset, batch_size=cfg.batch_size)
self.total_epochs = cfg.total_epochs
self.iterations = 0
self.x = self.dataset.x
self.y = self.dataset.y
self.draw_data(self.x, self.y)
def train(self):
for i in range(self.total_epochs):
for item in self.dataloader:
caches, output = self.net.forward(item['x'])
grads = self.net.backward(caches, output, item['y'])
self.net.update_grads(grads, learning_rate=0.03)
if i % 100 == 0:
print("Epoch: {}/{} Iteration: {} Loss: {}".format(i + 1,
self.total_epochs,
self.iterations,
self.compute_loss(output, item['y'])))
self.iterations += 1
def test(self):
caches, output = self.net.forward(self.x)
self.draw_data(self.x, output)
self.save_results()
self.show()
def save_models(self):
ckpt = {
"layers_dim": self.net.layers_dim,
"parameters": self.net.linear_list
}
np.save(self.ckpt_path, ckpt)
print('Save models finish!!')
def load_models(self):
ckpt = np.load(self.ckpt_path).item()
self.net.layers_dim = ckpt["layers_dim"]
self.net.linear_list = ckpt["parameters"]
print('load models finish!!')
def draw_data(self, x, y):
plt.scatter(x, y)
def show(self):
plt.show()
def save_results(self):
plt.savefig(fname=self.result_img_path, figsize=[10, 10])
# 計算誤差值
def compute_loss(self, output, y):
return np.mean(np.square(output - y))
四、訓練演示
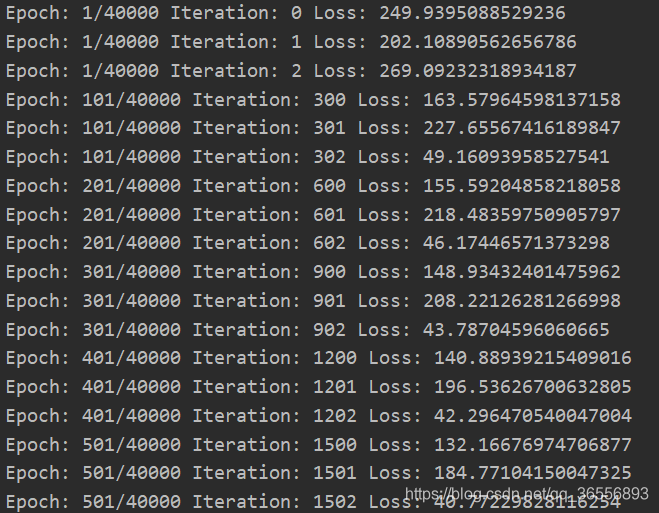
訓練期間會輸出訓練的時間,迭代次數和損失變化,訓練結束存盤模型和結果,
1.開始訓練
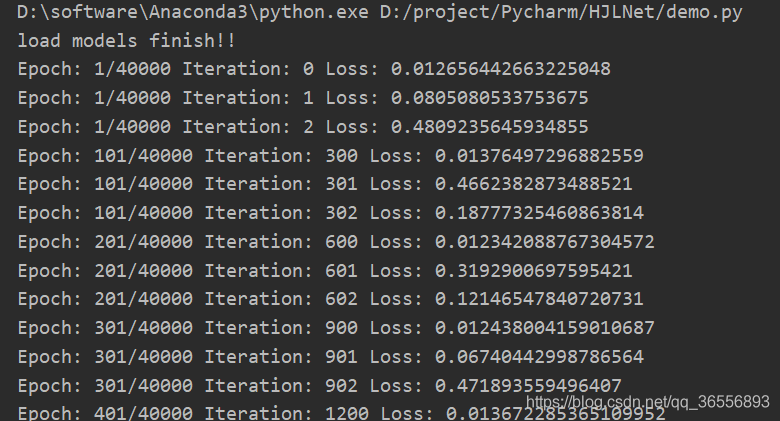
2.訓練完畢,讀取上次的模型繼續訓練
3.結果展示
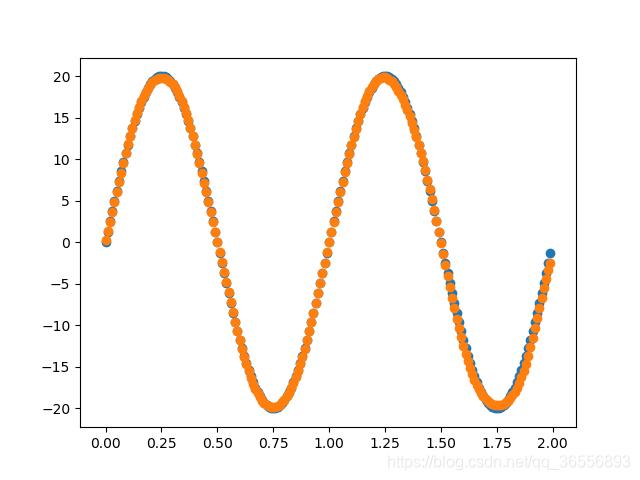
五、總結
如此一來便知曉了一個基本網路訓練程序中正向反向傳播程序,之后會更新更加詳細的代碼和原理,幫助各位學習深度學習的知識和概念~
 CSDN認證博客專家
深度學習
神經網路
Pytorch
CSDN認證博客專家
深度學習
神經網路
Pytorch
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/190216.html
標籤:python
上一篇:八數碼寬度優先極簡版
下一篇:Python實作LR1文法