時間復雜度
漸進時間復雜度(asymptotic time complexity)的概念,官方的定義如下:
若存在函式 f(n),使得當n趨近于無窮大時,T(n)/ f(n)的極限值為不等于零的常數,則稱 f(n)是T(n)的同數量級函式,
記作 T(n)= O(f(n)),稱O(f(n)) 為演算法的漸進時間復雜度,簡稱時間復雜度,
漸進時間復雜度用大寫O來表示,所以也被稱為大O表示法,
O(n)是nums中的元素個數演算法和n呈線性關系,忽略了常數,實際是 T = c1*n + c2; 但是 T = 2*n + 2 O(n) T = 2000*n + 10000 O(n) T = 1*n*n + 0 O(n^2) 上面的運算式中第三個n下于3000的時候都是比前面的要小的,但是在n接近無窮的時候, 就是不一樣了,所以O是漸進時間復雜度描述n趨近于無窮的情況
O一般是計算最壞的結果
均攤復雜度,有時早規律出現的時候可以使用均攤復雜度
復雜度震蕩,在邊界情況下,來回操作,過于著急(Eager)解決方案就是Lazy
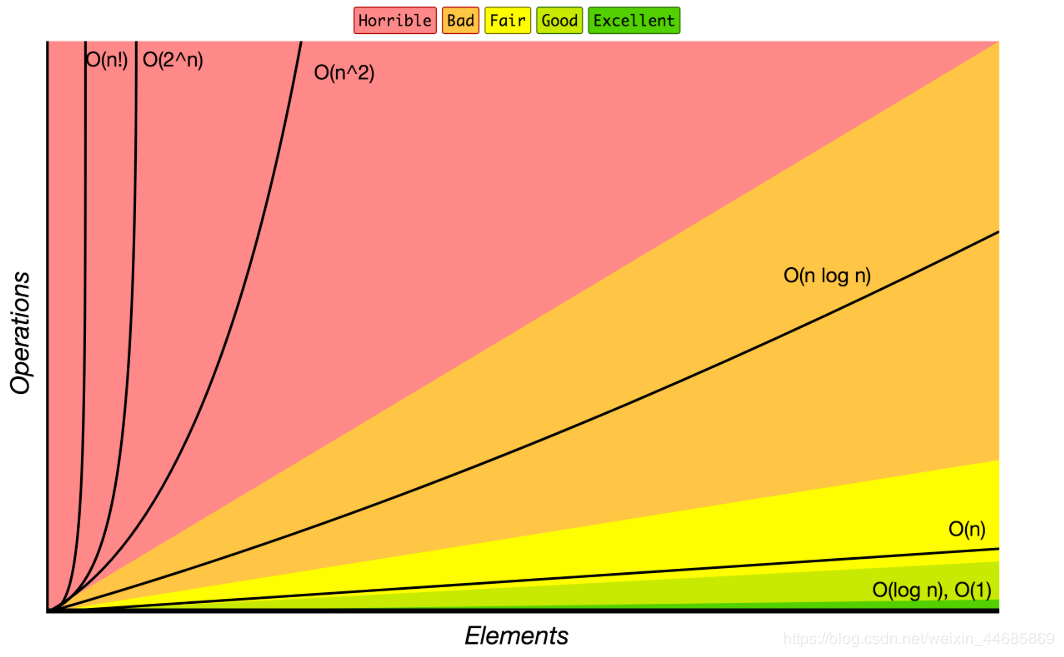
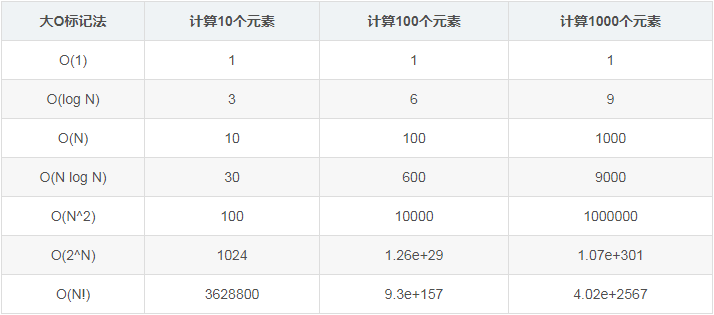
資料結構操作的復雜性
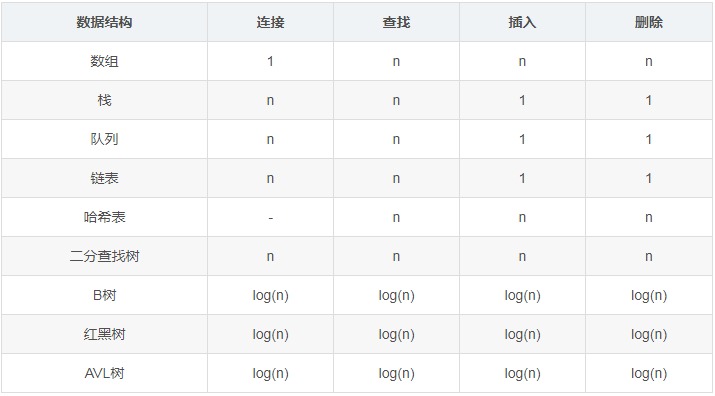
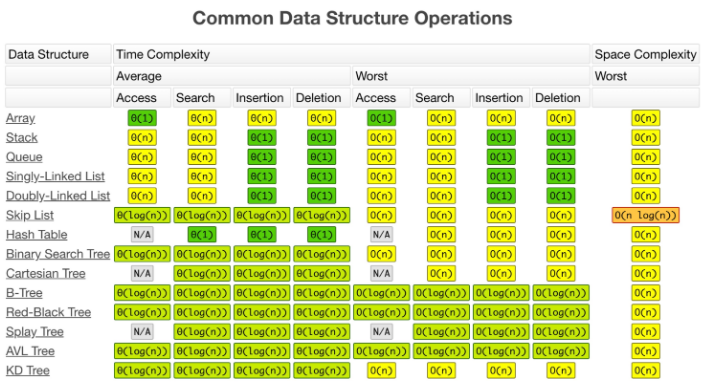
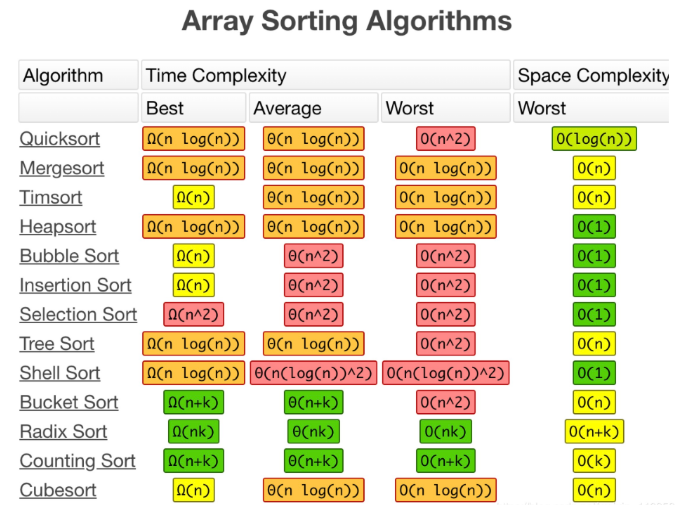
空間復雜度
空間復雜度(Space Complexity)是對一個演算法在運行程序中臨時占用存盤空間大小的量度,記做 S(n)=O(f(n)),比如直接插入排序的時間復雜度是 O(n^2) ,空間復雜度是O(1) ,而一般的遞回演算法就要有 O(n) 的空間復雜度了,因為每次遞回都要存盤回傳資訊,一個演算法的優劣主要從演算法的執行時間和所需要占用的存盤空間兩個方面衡量,
前面提到了,時間復雜度的全稱是漸進時間復雜度,表示演算法的執行時間與資料規模之間的增長關系,類比一下,空間復雜度全稱就是漸進空間復雜度(asymptotic space complexity),表示演算法的存盤空間與資料規模之間的增長關系,
我還是拿具體的例子來給你說明,(asymptotic space complexity),表示演算法的存盤空間與資料規模之間的增長關系,
我們常見的空間復雜度就是 O(1)、O(n)、O(n2 ),像 O(logn)、O(nlogn) 這樣的對數階復雜度平時都用不到,而且,空間復雜度分析比時間復雜度分析要簡單很多,所以,對于空間復雜度,掌握剛我說的這些內容已經足夠了,
時間-空間 復雜度詳解:https://www.cnblogs.com/chenjinxinlove/p/10038919.html
穩定性
排序演算法的穩定性,通俗地講就是能保證排序前兩個相等的資料其在序列中的先后位置順序與排序后它們兩個先后位置順序相同,即:如,如果A1 == A2,A1 原來在 A2 位置前,排序后 A1 仍然是在 A2 位置前,
1、如果排序演算法是穩定的,那么從一個鍵上排序,然后再從另一個鍵上排序,第一個鍵排序的結果可以為第二個鍵排序所利用, 基數排序就是這樣,先按低位排序,逐次按高位排序,那么,低位相同的資料元素其先后位置順序即使在高位也相同時是不會 改變的,
2、學習排序原理時,可能編的程式里面要排序的元素都是簡單型別,實際上真正應用時,可能是對一個復雜型別(自定義型別) 的陣列排序,而排序的鍵值僅僅只是這個元素中的一個屬性,對于一個簡單型別,數字值就是其全部意義,即使交換了也看不 出什么不同,但是,對于復雜型別,交換的話可能就會使原本不應該交換的元素交換了,比如:一個“學生”陣列,欲按照年齡排 序,“學生”這個物件不僅含有“年齡”,還有其它很多屬性,假使原陣列是把學號作為主鍵由小到大進行的資料整理,而穩定的排 序會保證比較時,如果兩個學生年齡相同,一定不會交換,也就意味著盡管是對“年齡”進行了排序,但是學號順序仍然是由小到 大的要求,
3、如果排序演算法穩定,對基于比較的排序演算法而言,元素交換的次數可能相對會少一些,
常用排序演算法
演算法比較
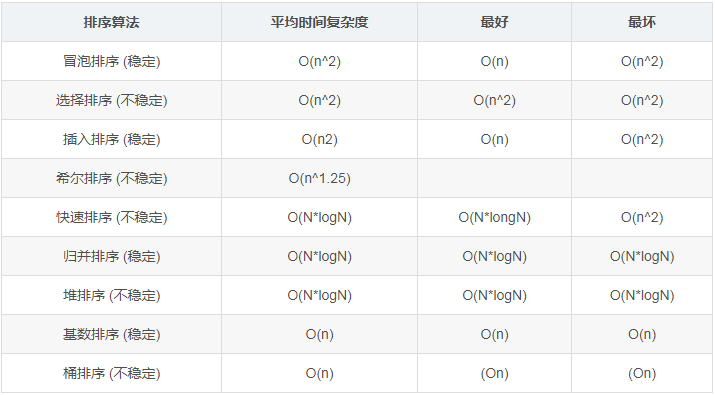
O(n)這樣的標志叫做漸近時間復雜度,是個近似值.各種漸近時間復雜度由小到大的順序如下
O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(n^3) < O(2^n) < O(n!) < O(n^n)
一般時間復雜度到了2^n(指數階) 及更大的時間復雜度,這樣的演算法我們基本上不會用了,不實用了,比如遞回實作的漢諾塔問題演算法就是O(2^n,
平方階(n^2)的演算法是勉強能用,而nlogn及更小的時間復雜度演算法那就是非常高效的演算法了啊.
冒泡排序 Bubble Sort
性質:穩定性排序演算法
它重復地走訪過要排序的元素列,依次比較兩個相鄰的元素,如果順序(如從大到小、首字母從從Z到A)錯誤就把他們交換過來,走訪元素的作業是重復地進行直到沒有相鄰元素需要交換,也就是說該元素列已經排序完成,
這個演算法的名字由來是因為越小的元素會經由交換慢慢“浮”到數列的頂端(升序或降序排列),就如同碳酸飲料中二訊訓碳的氣泡最侄訓上浮到頂端一樣,故名“冒泡排序”,
原理:比較兩個相鄰的元素,將值大的元素交換到右邊
思路:依次比較相鄰的兩個數,將比較小的數放在前面,比較大的數放在后面,
由上圖可知:
1、第一次比較:首先比較第一和第二個數,將小數放在前面,將大數放在后面,
2、比較第2和第3個數,將小數 放在前面,大數放在后面,
3、如此繼續,知道比較到最后的兩個數,將小數放在前面,大數放在后面,重復步驟,直至全部排序完成
4、在上面一趟比較完成后,最后一個數一定是陣列中最大的一個數,所以在比較第二趟的時候,最后一個數是不參加比較的,
5、在第二趟比較完成后,倒數第二個數也一定是陣列中倒數第二大數,所以在第三趟的比較中,最后兩個數是不參與比較的,
6、依次類推,每一趟比較次數減少依次
# Bubble Sort def bubble_sort(nums): for i in range(len(nums) - 1): # 這個回圈負責設定冒泡排序進行的次數 for j in range(len(nums) - i - 1): # j為串列下標 if nums[j] > nums[j + 1]: nums[j], nums[j + 1] = nums[j + 1], nums[j] return nums print(bubble_sort([45, 32, 8, 33, 12, 22, 19, 97])) # 輸出:[8, 12, 19, 22, 32, 33, 45, 97] # Second def bubble(bubbleList): listLength = len(bubbleList) while listLength > 0: for i in range(listLength - 1): if bubbleList[i] > bubbleList[i+1]: bubbleList[i], bubbleList[i+1] = bubbleList[i+1], bubbleList[i] listLength -= 1 print bubbleList if __name__ == '__main__': bubbleList = [3, 4, 1, 2, 5, 8, 0] bubble(bubbleList)
演算法分析:
由此可見:N個數字要排序完成,總共進行N-1趟排序,每i趟的排序次數為(N-i)次,所以可以用雙重回圈陳述句,外層控制回圈多 少趟,內層控制每一趟的回圈次數
冒泡排序的優點:每進行一趟排序,就會少比較一次,因為每進行一趟排序都會找出一個較大值,如上例:第一趟比較之后,排 在最后的一個數一定是最大的一個數,第二趟排序的時候,只需要比較除了最后一個數以外的其他的數,同樣也能找 出一個最大的數排在參與第二趟比較的數后面,第三趟比較的時候,只需要比較除了最后兩個數以外的其他的數,以 此類推……也就是說,沒進行一趟比較,每一趟少比較一次,一定程度上減少了演算法的量,
時間復雜度:如果我們的資料正序,只需要走一趟即可完成排序,所需的比較次數C和記錄移動次數M均達到最小值,即: Cmin=n-1;Mmin=0;所以,冒泡排序最好的時間復雜度為O(n),如果很不幸我們的資料是反序的,則需要進行n-1趟排 序,每趟排序要進行n-i次比較(1≤i≤n-1),且每次比較都必須移動記錄三次來達到交換記錄位置,在這種情況下,比較 和移動次數均達到最大值:
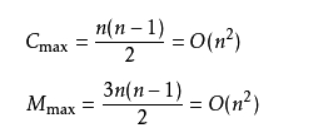
綜上所述:冒泡排序總的平均時間復雜度為:O(n2) ,時間復雜度和資料狀況無關,
選擇排序 Selection Sort
性質:不穩定的排序方法
第一次從待排序的資料元素中選出最小(或最大)的一個元素,存放在序列的起始位置,然后再從剩余的未排序元素中尋找到最小(大)元素,然后放到已排序的序列的末尾,以此類推,直到全部待排序的資料元素的個數為零,選擇排序是不穩定的排序方法,
原理: 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,
再從剩余未排序元素中繼續尋找最小(大)元素,然后放到已排序序列的末尾,
重復第二步,直到所有元素均排序完畢,
思路: 從頭至尾掃描序列,找出最小的一個元素,和第一個元素交換,接著從剩下的元素中繼續這種選擇和交換方式,最終 得到一個有序序列,
1、初始狀態:序列為無序狀態,
2、第1次排序:從n個元素中找出最小(大)元素與第1個記錄交換
3、第2次排序:從n-1個元素中找出最小(大)元素與第2個記錄交換
4、第i次排序:從n-i+1個元素中找出最小(大)元素與第i個記錄交換
5、以此類推直到排序完成
# Selection sort def selectionSort(arr): for i in range(len(arr) - 1): # 記錄最小數的索引 minIndex = i for j in range(i + 1, len(arr)): if arr[j] < arr[minIndex]: minIndex = j # i 不是最小數時,將 i 和最小數進行交換 if i != minIndex: arr[i], arr[minIndex] = arr[minIndex], arr[i] return arr
演算法分析:
由此可見: 每經過一輪排序,有序區域內的元素數量增加1個,
如果待排序的元素個數為N,需要經歷N-1輪排序,
選擇排序的優點:n 個記錄的檔案的直接選擇排序可經過n-1 趟直接選擇排序得到有序結果,移動資料的次數已知(n-1 次);
時間復雜度:
1、簡單選擇排序的比較次數與序列的初始排序無關,假設待排序的系列有N個元素,則比較次數總是 N(N-1)/2而移動次數 與系列的初始排序有關,當排序正序時,移動次數最少,為0
2、當序列反序時,移動次數最多,為 3N(N-1)/2
所以,綜上,簡單排序的時間復雜度為 O(N*N)
選擇排序的簡單和直觀名副其實,這也造就了它”出了名的慢性子”,無論是哪種情況,哪怕原陣列已排序完成,它也將花 費將近n2/2次遍歷來確認一遍,
即便是這樣,它的排序結果也還是不穩定的, 唯一值得高興的是,它并不耗費額外的記憶體空間,
綜上所述:選擇排序總的平均時間復雜度為:O(n2) ,時間復雜度和資料狀況無關,
插入排序 Lnsertion Sort
性質:穩定性排序演算法
插入排序的基本操作就是將一個資料插入到已經排好序的有序資料中,從而得到一個新的、個數加一的有序資料,演算法適用于少量資料的排序,時間復雜度為O(n^2),
原理:
插入排序始終在串列的較低位置維護一個排序的子串列,遇到新的項將它插入到原來的子串列,使得排序的子串列稱為一個 較大的項,插入演算法把要排序的陣列分成兩部分:第一部分包含了這個陣列的所有元素,但將最后一個元素除外(讓陣列多一 個空間才有插入的位置),而第二部分就只包含這一個元素(即待插入元素),在第一部分排序完成后,再將這個最后元素插 入到已排好序的第一部分中,
思路:
每步將一個待排序的記錄,按其關鍵碼值的大小插入前面已經排序的檔案中適當位置上,直到全部插入完為止,
1、從第一個元素開始,該元素可認為已排序,
2、取出下一個元素,在排序好的元素序列中從后往前掃描
3、如果元素(已排序)大于新元素,將該元素移到下一位置
4、重復3.直到找到已排序的元素小于或等于新元素的位置
5、將新元素插入該位置后
6、重復2-5直到排序完成
# Insertion sort def insert_sort(lst): for i in range(1,len(lst)): tmp = lst[i] j = i - 1 while j >= 0 and tmp < lst[j]: lst[j + 1] = lst[j] j = j - 1 lst[j + 1] = tmp return lst
演算法分析:
插入排序是一種簡單直觀的排序演算法,作業原理為構建有序序列,對于未排序元素,在已排序序列中從后向前掃描,找到相應位置并插入,插入排序在實作上,通常采用in-place排序(即只需用到O(1)的額外空間的排序),因而在從后向前掃描程序中,需要反復把已排序元素逐步向后挪位,為最新元素提供插入空間,直到排序完成,如果碰見一個和插入元素相等的,那么插入元素把想插入的元素放在相等元素的后面,所以,相等元素的前后順序沒有改變,從原無序序列出去的順序就是排好序后的順序,所以插入排序是穩定的,理解了插入排序的思想后,我們便能夠得到它的時間復雜度,對于n個元素,一共需要進行n-1輪比較,而第k輪比較需要進行k次陣列元素的兩兩比較,因此共需要進行的比較次數為:1 + 2 + … + (n-1),所以插入排序的時間復雜度同冒泡排序一樣,也為O(n^2),
對比冒泡和插入的代碼,冒泡排序的資料交換比插入排序的資料移動要復雜,冒泡排序需要三次賦值操作,而插入排序只需要一次,
因此,我們對逆序度為K的陣列進行排序,用冒泡排序需要進行3*K次單元時間,而插入排序只需要K次單元時間,因此插入排序性能更優,
時間復雜度:
1、最好:如果序列已經是排好序的,那么就是最好的情況,
此時外層回圈執行n-1次,每次中內回圈體執行1次,賦值陳述句執行一次,則T(n) = n-1,所以時間復雜度為O(n),
2、最壞:如果序列正好是逆序的,那么就是最壞的情況,
此時外層回圈執行n-1次,對應的內回圈體分別執行n-(n-1),n-(n-2),n-(n-3)…,n-3,n-2,n-1,T(n)= n(n-1)/2,所以時間 復雜度為O(n),
3、平均:平均執行的次數 = n-1 + n(n-1)/2 = 1/2n^2 + 1/2n -1,則平均時間復雜度為O(n^2),
序列中兩個相等的元素在排序之后,它們的相對位置不會發生改變,因此插入排序演算法是穩定的演算法,
綜上所述:選擇排序總的平均時間復雜度為:O(n2) ,時間復雜度和資料狀況無關,
快速排序 Quick Sort
性質:不穩定的排序方法
快速排序(Quicksort)是對冒泡排序的一種改進,
快速排序的基本思想:通過一趟排序將待排記錄分隔成獨立的兩部分,其中一部分記錄的關鍵字均比另一部分的關鍵字小,則可分別對這兩部分記錄繼續進行排序,以達到整個序列有序,
原理:
先從資料序列中選一個元素,并將序列中所有比該元素小的元素都放到它的右邊或左邊,再對左右兩邊分別用同樣的方法處 之直到每一個待處理的序列的長度為1,處理結束
思路:
先從數列中取出一個數作為基準數,磁區程序,將比這個數大的數全放到它的右邊,小于或等于它的數全放到它的左邊, 再對左右區間重復第二步,直到各區間只有一個數
1、求第一趟劃分后的結果,
2、關鍵碼 序列遞增,
3、以第一個元素為劃分基準,(自己設定的排序初始值,這里我選擇第一個)
4、將兩個指標i,j分別指向表的起始和最后的位置,
反復操作以下兩步:
5、 逐漸減小,并逐次比較 j 指向的元素和目標元素的大小,若 p( j ) < T(準基) 則交換位置,
6、逐漸增大,并逐次比較 i 指向的元素和目標元素的大小,若 p( i ) > T(準基) 則交換位置,
7、直到6,5指向同一個值,回圈結束,
回傳規則是:左邊磁區+基準值+右邊磁區
# Quick Sort def quick_sort(data): """quick_sort""" if len(data) >= 2: mid = data[len(data)//2] left,right = [], [] data.remove(mid) for num in data: if num >= mid: right.append(num) else: left.append(num) return quick_sort(left) + [mid] + quick_sort(right) else: return data a = [2,3,4,1,45,6,6,7,8,7,9,10,18,20,30,12] print(quick_sort(a)) [1, 2, 3, 4, 6, 6, 7, 7, 8, 9, 10, 12, 18, 20, 30, 45]
演算法分析:
快速排序演算法的時間復雜度和各次標準資料元素的值關系很大,如果每次選取的標準元素都能均分兩個子陣列的長度,這樣的快速排序程序是一個完全二叉樹結構,(即每個結點都把當前陣列分成兩個大小相等的陣列結點,n個元素陣列的根結點的分解次數就構成一棵完全二叉樹),這時分解次數等于完全二叉樹的深度log2n;每次快速排序程序無論把陣列怎樣劃分、全部的比較次數都接近于n-1次,所以最好情況下快速排序演算法的時間復雜度為O(nlog2n):快速排序演算法的最壞情況是資料元素已全部有序,此時資料元素陣列的根結點的分需次數構成一棵二叉退化樹(即單分支二叉樹),一棵二叉退化樹的深度是n,所以最壞情況下快速排序演算法的時間復雜度為O(n2),般情況下 ,標準元素值的分布是隨機的,陣列的分郵大數構成模二又樹,這樣的二叉樹的深度接近于log2n, 所以快速排序演算法的平均(或稱期望)時間復雜度為O(nlog2n)
時間復雜度:
1、快速排序最優的情況就是每一次取到的元素都剛好平分整個陣列,
此時的時間復雜度公式則為:T[n] = 2T[n/2] + f(n);T[n/2]為平分后的子陣列的時間復雜度,f[n] 為平分這個陣列時所花的時間
2、最差的情況就是每一次取到的元素就是陣列中最小/最大的,這種情況其實就是冒泡排序了(每一次都排好一個元素的順序)
這種情況時間復雜度就好計算了,就是冒泡排序的時間復雜度:T[n] = n * (n-1) = n^2 + n;
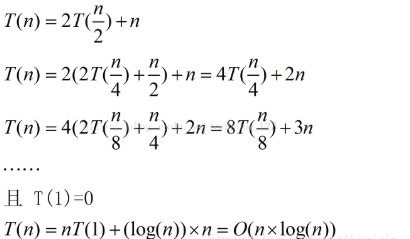
平均時間復雜度為O(nlog2n)
堆排序 HeapSort
性質:不穩定的排序方法
堆排序是指利用堆這種資料結構所設計的一種排序演算法,堆積是一個近似完全二叉樹的結構,并同時滿足堆積的性質:即子結點的鍵值或索引總是小于(或者大于)它的父節點,
什么是 堆?
堆是一種特殊的完全二叉樹
樹: 樹是不包含回路的連通無向圖(任意的兩個節點僅有唯一的一條路徑連通,在一棵樹中加一條邊會構成圖)
二叉樹: 是一種特殊的樹,只要不為空,就由根節點、左子樹和右子樹組成,左子樹和右子樹分別是一棵二叉樹
完全二叉樹: 完全二叉樹和滿二叉樹都是一種特殊的二叉樹,兩者可以一起記,如下圖,左邊為滿二叉樹:每個分支節點都有左子樹和右子樹,所有葉子都在同一層上,右邊為完全二叉樹,是從右向左減少葉子節點的滿二叉樹
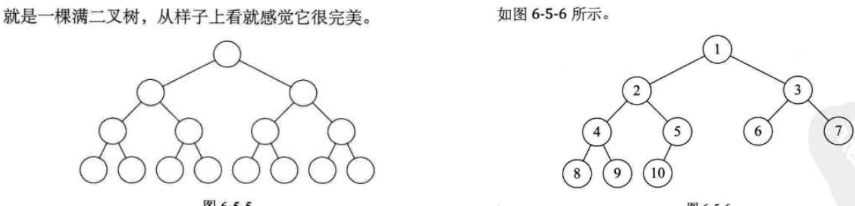
堆分為:
大頂堆:所有父節點都比子節點大
小頂堆:所有父節點都比子節點小
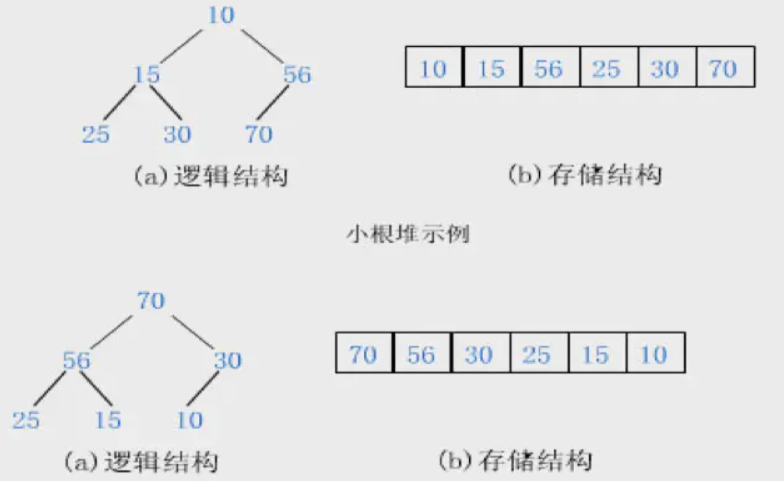
堆排序就是利用堆(假設利用大頂堆)進行排序的方法,
原理:
將待排序的序列構造成一個大頂堆,此時,整個序列的最大值就是堆頂的根節點,將它移走(其實就是將其與堆陣列的末尾元素交換,此時末尾元素就是最大值),然后將剩余的 n-1 個序列重新構造成一個堆,這樣就會得到 n 個元素中次大的值,如此反復執行,便能得到一個有序序列了,
一般升序采用大頂堆,降序采用小頂堆
還有個簡易版的:
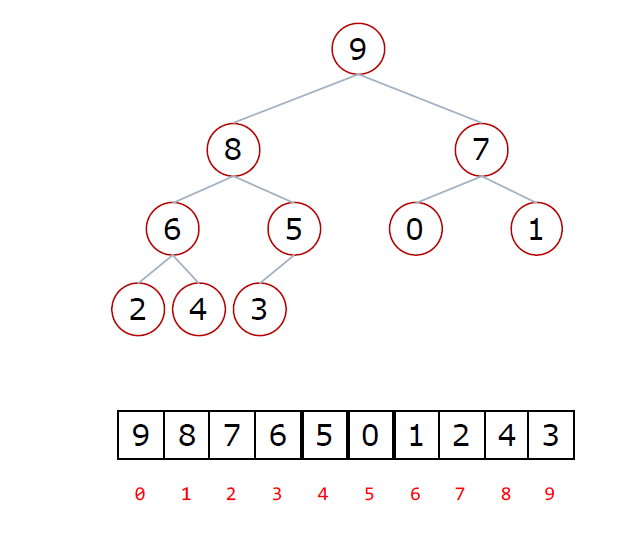
假設
根節點的左右子樹都是堆,但根節點不滿足堆的性質(大根堆,小根堆)
可以通過一次向下的調整來將其變成一個堆 (下圖)
堆排序程序:
步驟:
1、建立堆
2、得到堆頂元素,為最大元素
3、去掉堆頂,將堆最后一個元素放到堆頂,此時可通過一次調整重新使堆有序,
4、堆頂元素為第二大元素
5、重復步驟3,直到堆變空
這回理解了吧,
堆排序的實作程序中,其實大部分程序都在調整程序(建立堆,排序的時候去掉堆頂,重新調整)
所以我們先來實作調整堆的代碼
def heap_sort(li): """ 實作堆排序程序: 1、先根據傳入的串列構建堆(大根堆) 2、再埃個出數 :param li: :return: """ n = len(li) # 1、構建堆--包圍框 for i in range((n-2)//2, -1, -1): # i 就是每個父節點的位置 # (n-2)//2 是根據堆的最后一個葉子節點位置推算其父節點位置的公式:(i-1)//2 # 而 i 又等于 n - 1, 所以 (i-1)//2 == ((n - 1)-1)//2 == (n-2)//2 # 第一個 -1 ,因為要從最后一個根節點回圈到第一個根節點也就是串列中下標為0的元素,range 為開頭閉尾 # 第二個 -1, 倒序 sift(li, i, n-1) # 2、埃個出數,完成串列排序, # 原地排序,每次都根節點都和最后一個葉子節點互換,然后調整位置, 再進行如上回圈操作,直到堆為空 for i in range(n-1, -1, -1): # i是每次回圈堆里面最后一個數 li[0], li[i] = li[i], li[0] sift(li, 0, i-1) # 邊界值下標, 因為出數完之后,最后原i位置上的元素是出數的結果,所以i位置上的元素不參加調整,故邊界值為i-1. # 書寫完畢進行測驗 li = [i for i in range(100)] import random random.shuffle(li) print(li) heap_sort(li) print(li) [26, 16, 81, 29, 11, 75, 73, 0, 35, 21, 95, 37, 72, 79, 80, 46, 76, 1, 93, 45, 25, 48, 92, 77, 42, 40, 82, 10, 6, 67, 30, 96, 47, 51, 38, 60, 4, 61, 64, 97, 33, 71, 8, 59, 87, 49, 19, 22, 83, 44, 9, 28, 27, 99, 69, 12, 2, 34, 24, 85, 32, 53, 14, 88, 90, 41, 55, 39, 20, 94, 63, 23, 7, 66, 84, 74, 62, 58, 56, 70, 86, 17, 89, 13, 18, 65, 50, 98, 5, 54, 15, 78, 3, 57, 31, 52, 68, 43, 36, 91] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
第二種
def bucket_sort(s): """桶排序""" min_num = min(s) max_num = max(s) # 桶的大小 bucket_range = (max_num-min_num) / len(s) # 桶陣列 count_list = [ [] for i in range(len(s) + 1)] # 向桶陣列填數 for i in s: count_list[int((i-min_num)//bucket_range)].append(i) s.clear() # 回填,這里桶內部排序直接呼叫了sorted for i in count_list: for j in sorted(i): s.append(j) if __name__ == '__main__': a = [3.2,6,8,4,2,6,7,3] bucket_sort(a) print(a) # [2, 3, 3.2, 4, 6, 6, 7, 8]
演算法分析:
優點:
堆排序的效率與快排、歸并相同,都達到了基于比較的排序演算法效率的峰值(時間復雜度為O(nlogn))
除了高效之外,最大的亮點就是只需要O(1)的輔助空間了,既最高效率又最節省空間,只此一家了
堆排序效率相對穩定,不像快排在最壞情況下時間復雜度會變成O(n^2)),所以無論待排序序列是否有序,堆排序的效率都 是O(nlogn)不變(注意這里的穩定特指平均時間復雜度=最壞時間復雜度,不是那個“穩定”,因為堆排序本身是不穩定的)
缺點:
(從上面看,堆排序幾乎是完美的,那么為什么最常用的內部排序演算法是快排而不是堆排序呢?)
最大的也是唯一的缺點就是——堆的維護問題,實際場景中的資料是頻繁發生變動的,而對于待排序序列的每次更新 (增,刪,改),我們都要重新做一遍堆的維護,以保證其特性,這在大多數情況下都是沒有必要的,(所以快排成為了實際 應用中的老大,而堆排序只能在演算法書里面頂著光環,當然這么說有些過分了,當資料更新不很頻繁的時候,當然堆排序更好 些…)
時間復雜度:
若有n個元素的序列,將元素接腰序組成一棵完全二叉樹,當且僅當滿足下列條件時稱為堆,大根堆是指所有結點的值大于或等于左右子結點的值;小掇堆是指所有結點的值小于或等于左右子結點的值,在調整建堆的程序中,總是將根結點值與左、右子樹的根結點進行比較,若不滿足堆的條件,則將左、右子樹根結點值中的大者與根結點值進行交換,堆排序最壞情況需要0(nlogn)次比較,所以時間復雜度是0(nlogn)
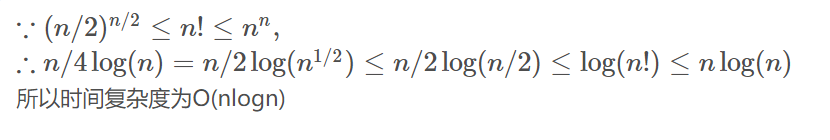
初始化建堆的時間復雜度為O(n),排序重建堆的時間復雜度為nlog(n),所以總的時間復雜度為O(n+nlogn)=O(nlogn),另外堆排序的比較次數和序列的初始狀態有關,但只是在序列初始狀態為堆的情況下比較次數顯著減少,在序列有序或逆序的情況下比較次數不會發生明顯變化,
歸并排序 Merge Sort
性質:穩定性排序演算法
歸并排序(MERGE-SORT)是建立在歸并操作上的一種有效的排序演算法,該演算法是采用分治法(Divide and Conquer)的一個非常典型的應用,將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序,若將兩個有序表合并成一個有序表,稱為二路歸并,
原理:
歸并排序是一種遞回演算法,不斷將串列拆分為一半,如果串列為慷訓有一個項,則按定義進行排序,如果串列有多個項,我 們分割串列,并遞回呼叫兩個半部分的合并排序,一旦對兩半排序完成,獲取兩個較小的排序串列并將它們組合成單個排序 的新串列的程序
思路:
歸并排序中,我們會先找到一個陣列的中間下標mid,然后以這個mid為中心,對兩邊分別進行排序,之后我們再根據兩邊已 排好序的子陣列,重新進行值大小分配,
1、把長度為n的輸入序列分成兩個長度為n/2的子序列;
2、對這兩個子序列分別采用歸并排序;
3、將兩個排序好的子序列合并成一個最終的排序序列,
data = https://www.cnblogs.com/yangmaosen/p/[45,3,2,6,3,78,5,44,22,65,46] # 合并函式,將相鄰的兩個區間合并為一個 def merge(a, b): result = [] i = j = 0 while i<len(a) and j<len(b): if a[i] < b[j]: result.append(a[i]) i += 1 else: result.append(b[j]) j += 1 result += a[i:] result += b[j:] return result def sorts(data): length = len(data) if length <=1: return data # 按照平分當前串列的方式將data遞回分為很多個平均的串列 mid = length/2 a = sorts(data[:mid]) b = sorts(data[mid:]) # 遞回分到每個串列只有一個數字后合并 return merge(a, b) print sorts(data)
演算法分析:
優點:
歸并排序的效率達到了巔峰:時間復雜度為O(nlogn),這是基于比較的排序演算法所能達到的最高境界
歸并排序是一種穩定的演算法(即在排序程序中大小相同的元素能夠保持排序前的順序,3212升序排序結果是1223,排序前后兩個2的順序不變),這一點在某些場景下至關重要
歸并排序是最常用的外部排序方法(當待排序的記錄放在外存上,記憶體裝不下全部資料時,歸并排序仍然適用,當然歸并排序同樣適用于內部排序…)
缺點:
歸并排序需要O(n)的輔助空間,而與之效率相同的快排和堆排分別需要O(logn)和O(1)的輔助空間,在同類演算法中歸并排序的空間復雜度略高
時間復雜度:
1、對于陣列:[5,3,6,2,0,1]
序列可以分為:[5,3,6]和[2,0,1]
2、對上面的序列分別進行排序,結果為:
[3,5,6]和[0,1,2]
然后將上面的兩個序列合并為一個排好序的序列
合并的方法是:設定兩個指標,分別指著兩個序列的開始位置,如下所示
[3,5,6] [0,1,2]
/|\ /|\
3、開始的時候兩個指標分別指向3和0,這時我們找到一個空陣列,將3和0中較小的值復制進這個 陣列中,并作為第一個元素, 新陣列:[0,]
4、后面陣列的指標后移一位,如下所示
[3,5,6] [0,1,2]
/|\ /|
將1和3進行比較,1小于3,于是將1插入新陣列:[0,1,…]
5、后面陣列的指標后移一位,如下所示
[3,5,6] [0,1,2]
/|\ /|
將2和3進行比較,2小于3,于是將2插入新陣列:[0,1,2,…]
6、將剩余的左邊已經有序的陣列直接復制進入新陣列中去,可以得到新陣列:[0,1,2,3,5,6]
7、有master公式(遞回公式):T(n)=2T(n/2)+O(N) 可以得出時間復雜度為:O(N*logN)
無論最好還是最壞均為: O(nlgn); 空間復雜度為 O(n); 是一種穩定的排序演算法;
二分查找法
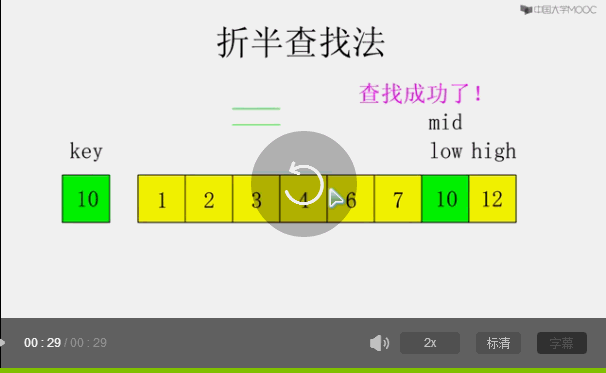
二分查找也稱折半查找(Binary Search),它是一種效率較高的查找方法,但是,折半查找要求線性表必須采用順序存盤結構,而且表中元素按關鍵字有序排列,
原理:
首先,假設表中元素是按升序排列,將表中間位置記錄的關鍵字與查找關鍵字比較,如果兩者相等,則查找成功;否則利用中間位置記錄將表分成前、后兩個子表,如果中間位置記錄的關鍵字大于查找關鍵字,則進一步查找前一子表,否則進一步查找后一子表,重復以上程序,直到找到滿足條件的記錄,使查找成功,或直到子表不存在為止,此時查找不成功,
def binary_chop(alist, data): """ 非遞回解決二分查找 """ n = len(alist) first = 0 last = n - 1 while first <= last: mid = (last+first)//2 if alist[mid] > data: last = mid - 1 elif alist[mid] < data: first = mid + 1 else: return True return False def binary_chop2(alist, data): """ 遞回解決二分查找 """ n = len(alist) if n < 1: return False mid = n // 2 if alist[mid] > data: return binary_chop2(alist[0:mid], data) elif alist[mid] < data: return binary_chop2(alist[mid+1:], data) else: return True if __name__ == "__main__": lis = [2,4, 5, 12, 14, 23] if binary_chop(lis, 12): print('ok') else: print('false')
二分檢索樹 (只闡述、待后期補充)
定義:
1、二分檢索樹是一顆二叉樹
2、二分檢索樹每個節點的左子樹的值都小于該節點的值,每個節點右子樹的值都大于該節點的值
3、任意一個節點的每棵子樹都滿足二分檢索樹的定義
特點:
1、高效 不接可以查找資料 插入洗掉資料的復雜度都是O(logn)
2、可以方便的回答很多資料之間的關系
3、min max floor ceil select
遞回
在函式內部,可以呼叫其他函式,如果一個函式在內部呼叫自身,這個函式就是遞回函式
1、必須有一個明確的結束條件;
2、每次進入更深一層遞回時,問題規模相比上次遞回都應有所減少;
3、遞回效率不高,遞回層次過多會導致堆疊溢位(在計算機中,函式呼叫是通過堆疊這種資料結構實作的,每次進入一個函式呼叫,堆疊 就會加一層堆疊幀,每當函式回傳,堆疊就會減一層堆疊幀,由于堆疊的大小是有限的,所以遞回次數過多會導致堆疊溢位)
所以我們此時可以理解,遞回是依靠 堆疊 來實作的
目前 Python 能承受遞回的最大次數是 998(因機器而異),大于998會導致堆疊溢位,
怎么解決呢?
Python設計者在sys模塊中提供了一個 setrecursionlimit() 的方法,用來修改遞回次數限制,
import sys sys.setrecursionlimit(1500) def recursion_test(numb): print(numb) if numb <= 0: return numb -= 1 recursion_test(numb) recursion_test(998)
只需這樣 就可以解決
希爾排序 Shell s Sort
性質:非穩定性排序演算法
希爾排序的名稱來源于它的發明者,該演算法是第一批沖破二次時間屏障的演算法之一,它是基于插入排序改進而成的的一種快速的演算法,
希爾排序(Shell’s Sort)是插入排序的一種又稱“縮小增量排序”(Diminishing Increment Sort),是直接插入排序演算法的一種更高效的改進版本,希爾排序是非穩定排序演算法,
原理:
?比較相隔一定距離的元素,并且每趟比較所用的距離隨演算法進行而減小,因此,希爾排序也叫做縮減增量排序,
思路:
希爾排序是把記錄按下標的一定增量分組,對每組使用直接插入排序演算法排序;隨著增量逐漸減少,每組包含的關鍵詞越來越多,當增量減至1時,整個檔案恰被分成一組,演算法便終止
def shell_sort(alist): n = len(alist) # 讓步長從大變小,最后一步必須是1,獲取gap的偏移值 gap = n // 2 # 只要gap在我們的合理范圍內,就一直分組下去 while gap >= 1: # 按照步長把資料分兩半,從步長的位置遍歷后面所有的資料,指定j下標的取值范圍 for j in range(gap, n): # 拿當前位置的資料,跟當前位置-gap 位置的資料進行比較 while j-gap >= 0: # 組內大小元素進行替換操作 if alist[j]<alist[j-gap]: alist[j], alist[j - gap] = alist[j - gap], alist[j] # 更新遷移元素的下標值為最新值 j -= gap else: # 否則的話,不進行替換 break # 每執行完畢一次分組內的插入排序,對gap進行/2細分 gap //= 2 if __name__ == '__main__': alist = [9, 8, 7, 6, 5, 4, 3, 2, 1] print(alist) shell_sort(alist) print(alist)
1、先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,具體演算法描述:
2、選擇一個增量序列t1,t2,…,tk,其中ti>tj,tk=1;
3、按增量序列個數k,對序列進行k 趟排序;
4、每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序,僅增量因子為1 時, 整 個序列作為一個表來處理,表長度即為整個序列的長度,
演算法分析
希爾排序的核心在于間隔序列的設定,既可以提前設定好間隔序列,也可以動態的定義間隔序列,動態定義間隔序列的演算法是《演算法(第4版)》的合著者Robert Sedgewick提出的,
計數排序
性質:穩定的排序方法
計數排序不是基于比較的排序演算法,其核心在于將輸入的資料值轉化為鍵存盤在額外開辟的陣列空間中, 作為一種線性時間復雜度的排序,計數排序要求輸入的資料必須是有確定范圍的整數,
原理:
計數排序的演算法的原理,其實是非常簡單的,它不需要去跟其他元素比來比去,而是一開始就知道自己的位置,所以直接歸位,在計數的該元素出現的詞頻陣列里面,出現一次,就直接+1一次即可,如果沒有出現改位置就是0,最后該位置的詞頻,就是代表其在原始陣列里面出現的次數,由于詞頻陣列的index是從0開始,所以最后直接遍歷輸出這個陣列里面的每一個大于0的元素值即可,
思路:
1、找出待排序的陣列中最大和最小的元素;
2、統計陣列中每個值為i的元素出現的次數,存入陣列C的第i項;
3、對所有的計數累加(從C中的第一個元素開始,每一項和前一項相加);
4、反向填充目標陣列:將每個元素i放在新陣列的第C(i)項,每放一個元素就將C(i)減去1,
def count_sort(s): """計數排序""" # 找到最大最小值 min_num = min(s) max_num = max(s) # 計數串列 count_list = [0]*(max_num-min_num+1) # 計數 for i in s: count_list[i-min_num] += 1 s.clear() # 填回 for ind,i in enumerate(count_list): while i != 0: s.append(ind+min_num) i -= 1 if __name__ == '__main__': a = [3,6,8,4,2,6,7,3] count_sort(a) print(a)
步驟:
演算法分析:
計數排序是一個穩定的排序演算法,當輸入的元素是 n 個 0到 k 之間的整數時,時間復雜度是O(n+k),空間復雜度也是O(n+k),其排序速度快于任何比較排序演算法,當k不是很大并且序列比較集中時,計數排序是一個很有效的排序演算法,
計數排序的缺點
當數值中有非整數時,計數陣列的索引無法分配
桶排序 Bucket Sort
性質:穩定的排序方法
桶排序 (Bucket sort)或所謂的箱排序,是一個排序演算法,作業的原理是將陣列分到有限數量的桶子里,每個桶子再個別排序(有可能再使用別的排序演算法或是以遞回方式繼續使用桶排序進行排序),桶排序是鴿巢排序的一種歸納結果,當要被排序的陣列內的數值是均勻分配的時候,桶排序使用線性時間(Θ(n)),但桶排序并不是 比較排序,他不受到 O(n log n) 下限的影響,
桶排序是計數排序的升級版,它利用了函式的映射關系,高效與否的關鍵就在于這個映射函式的確定,桶排序 (Bucket sort)的作業的原理:假設輸入資料服從均勻分布,將資料分到有限數量的桶里,每個桶再分別排序(有可能再使用別的排序演算法或是以遞回方式繼續使用桶排序進行排),
原理:
桶排序與計數排序類似,但可以解決非整數的排序
桶排序相當于把計數陣列劃分為按順序的幾個部分
每一部分叫做一個桶,它來存放處于該范圍內的數
然后再對每個桶內部進行排序,可以使用其他排序方法如快速排序
最后整個桶陣列就是排列好的資料,再將其回傳給原序列
思路:
設定一個定量的陣列當作空桶;
遍歷輸入資料,并且把資料一個一個放到對應的桶里去;
對每個不是空的桶進行排序;
從不是空的桶里把排好序的資料拼接起來,
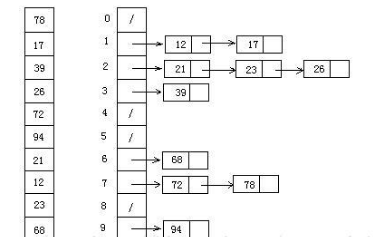
這里選擇桶的數量為序列元素個數+1,范圍分別是5等分與最大值,和上面那個圖一樣,
具體問題應該按照具體情況進行桶劃分
這里桶內部排序直接呼叫了sorted
def bucket_sort(s): """桶排序""" min_num = min(s) max_num = max(s) # 桶的大小 bucket_range = (max_num-min_num) / len(s) # 桶陣列 count_list = [ [] for i in range(len(s) + 1)] # 向桶陣列填數 for i in s: count_list[int((i-min_num)//bucket_range)].append(i) s.clear() # 回填,這里桶內部排序直接呼叫了sorted for i in count_list: for j in sorted(i): s.append(j) if __name__ == '__main__': a = [3.2,6,8,4,2,6,7,3] bucket_sort(a) print(a) # [2, 3, 3.2, 4, 6, 6, 7, 8]
計數排序與桶排序都是以犧牲空間換時間,雖然很快,但由于可能產生大量的空位置導致記憶體增大,尤其是計數排序,
桶排序中盡量使每個桶中的元素個數均勻分布最好
基數排序 Radix Sort
性質:穩定的排序方法
基數排序(radix sort)屬于“分配式排序”(distribution sort),又稱“桶子法”(bucket sort)或bin sort,顧名思義,它是透過鍵值的部份資訊,將要排序的元素分配至某些“桶”中,藉以達到排序的作用,基數排序法是屬于穩定性的排序,其時間復雜度為O (nlog?m),其中r為所采取的基數,而m為堆數,在某些時候,基數排序法的效率高于其它的穩定性排序法,
原理:
基數排序的原理就是,先排元素的最后一位,再排倒數第二位,直到所有位數都排完,這里并不能先排第一位,那樣最后依然是無序,
將整數按位數切割成不同的數字,然后按每個位數分別比較,由于整數也可以表達字串(比如名字或日期)和特定格式的浮點數,所以基數排序也不是只能使用于整數,
思路:
基數排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位,有時候有些屬性是有優先級順序的,先按低優先級排序,再按高優先級排序,最后的次序就是高優先級高的在前,高優先級相同的低優先級高的在前,
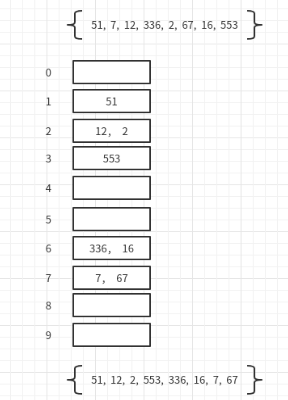
從這個圖中也能看出,排序是基于桶排序實作的,
然后就像排最低位一樣,然后再排倒數第二位,再排倒數第三位,注意向桶中放元素的時候一定要按順序放,
具體代碼:
# 這里將串列進行基數排序,默認串列中的元素都是正整數 def radix_sort(s): """基數排序""" i = 0 # 記錄當前正在排拿一位,最低位為1 max_num = max(s) # 最大值 j = len(str(max_num)) # 記錄最大值的位數 while i < j: bucket_list =[[] for _ in range(10)] #初始化桶陣列 for x in s: bucket_list[int(x / (10**i)) % 10].append(x) # 找到位置放入桶陣列 print(bucket_list) s.clear() for x in bucket_list: # 放回原序列 for y in x: s.append(y) i += 1 if __name__ == '__main__': a = [334,5,67,345,7,345345,99,4,23,78,45,1,3453,23424] radix_sort(a) print(a)
# 結果 [[], [1], [], [23, 3453], [334, 4, 23424], [5, 345, 345345, 45], [], [67, 7], [78], [99]] [[1, 4, 5, 7], [], [23, 23424], [334], [345, 345345, 45], [3453], [67], [78], [], [99]] [[1, 4, 5, 7, 23, 45, 67, 78, 99], [], [], [334, 345, 345345], [23424, 3453], [], [], [], [], []] [[1, 4, 5, 7, 23, 45, 67, 78, 99, 334, 345], [], [], [23424, 3453], [], [345345], [], [], [], []] [[1, 4, 5, 7, 23, 45, 67, 78, 99, 334, 345, 3453], [], [23424], [], [345345], [], [], [], [], []] [[1, 4, 5, 7, 23, 45, 67, 78, 99, 334, 345, 3453, 23424], [], [], [345345], [], [], [], [], [], []] [1, 4, 5, 7, 23, 45, 67, 78, 99, 334, 345, 3453, 23424, 345345]
基數排序不僅僅只能排正整數,只要通過調整元素放入桶陣列的方式就可以排序字串,浮點數等
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/190361.html
標籤:Python
下一篇:Python 類 初學者筆記