1 sklearn簡介
Scikit-learn(sklearn)是機器學習中的第三方模塊,封裝了常用的機器學習演算法,涉及回歸、降維、分類以及聚類等,提供python介面,
雖然sklearn容納的演算法眾多,但使用其中大多數演算法的模式(套路)都是一樣的,一般流程如下:
1 引入相關資料(包括訓練集與測驗集),其實Sklearn也自帶一些小型資料集,可以用來測驗檢驗各種演算法,方便快捷;
2 選擇演算法進行訓練,若模型帶有超引數,可以運用交叉驗證方法調參;
3 訓練完成后進行新資料預測,并可以通過引入MatPlotLib等庫展示資料;
4 將已訓練好的模型保存,避免往后用到時再重復訓練,
2 sklearn的自帶資料集
sklearn附帶了一些小型常用資料集,調取方法如下:
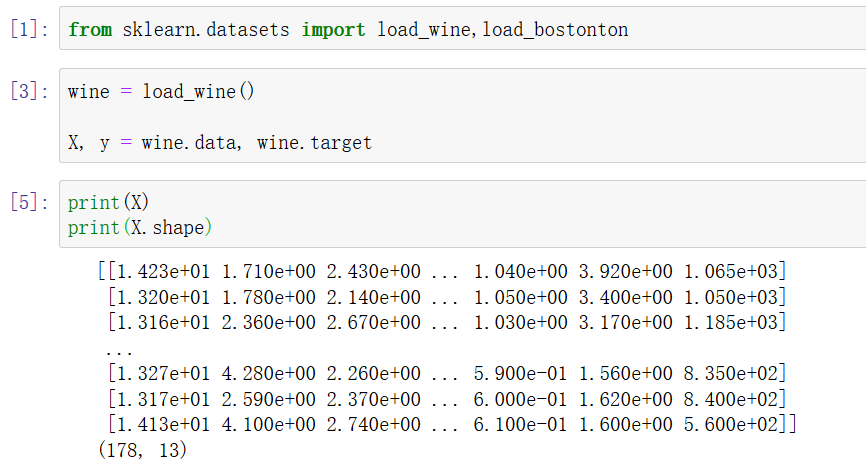
調取其它資料集的方法和上圖中的例子類似,
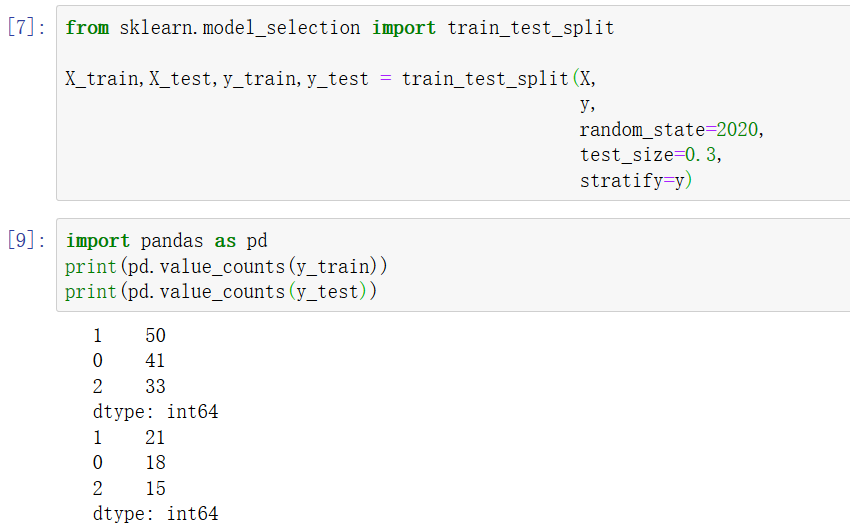
3 分層劃分訓練集與測驗集
注意:為了使實驗具有可重復性,在劃分資料集時要設定亂數種子,以確保重復多次運行代碼時得到的訓練集與測驗集是一樣的;此外,為了平衡訓練集與測驗集中各類別的比例(特別是在分類任務中),常常需要分層劃分資料集,這與統計學中分層抽樣的原理一樣,
4 資料標準化
常見的標準化方式有:離差標準化,高斯標準化,
離差標準化將所有資料變換到區間[0,1]中,高斯標準化將資料轉成高斯分布(正態分布)形態:

5 模型的保存與調取
為了避免重復訓練模型,同時方便后續直接調取已有模型,可以將訓練好的模型保存:
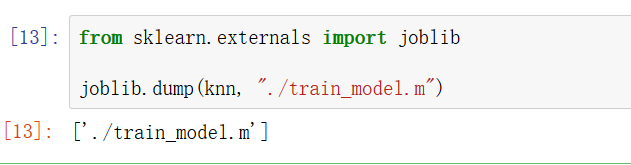
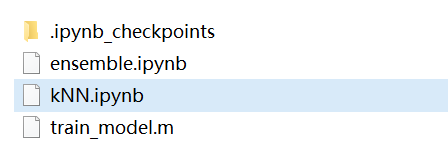
上圖中,將knn訓練完成的模型保存到代碼檔案的同目錄下,如下圖(代碼檔案名為:kNN.ipynb,模型名為:train_model.m):
若要加載已有模型,操作如下:

sklearn作為一個常用機器學習包,熟練使用它對于減少作業時間提高效率十分重要;只要學到一個演算法的使用流程,則可以觸類旁通,快速掌握其它演算法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/192498.html
標籤:Python
上一篇:python3-cookbook筆記:第一章 資料結構和演算法
下一篇:初入python