田海立@CSDN 2020-10-24
隨著華為Mate40 pro及其搭載的海思麒麟9000處理器的發布,其手機和移動soc的AI性能也雙雙登上了AI-Benchmark的榜首位置,其具體指標如何呢,為什么能登上榜首?本文從CPU性能、NNAP-INT8量化性能、NNAPI-FP16浮點性能、NNAPI-INT8精度和NNAPI-FP16精度等諸多指標因素來分析,借此分析當前Android生態各家移動soc AI性能態勢也就明朗了,
零、背景
《AI Benchmark測驗原理、v4測驗項變化以及榜單資料解讀》介紹了AI-Benchmark測驗AI的原理:在Android系統上測驗AI性能;基于Android NNAPI來測驗,用各種TensorFlow Lite模型(不同資料型別和算子)從不同角度來測驗AI性能,AI Benchmark v4版本更新了測驗模型、測驗方法與目標,相應的評分標準都有所變化,
《AI Benchmark v4榜首風云:麒麟9000登上榜首》介紹了隨著華為Mate40 pro及其搭載的海思麒麟9000處理器的發布,其AI性能也雙雙登上了AI-Benchmark的手機和移動soc的榜首,
其具體指標如何呢,為什么是它在榜首?本文將從CPU性能、NNAPI-INT8性能、NNAPI-FP16性能、精度等諸多方面來進一步分析,借此您也可了解當前Android生態各家移動soc AI性能態勢,
這里選取AI-Benchmark榜單上各家資料,每家選取一款得分最高的soc:海思麒麟9000、MTK 天璣1000+、高通驍龍865 Plus以及三星Exynos 990,沒有選取紫光展銳的虎賁T312以及SC9832A、Rockchip的RK3399等資料,是因為榜單上顯示并它們并沒有AI加速器的支持,
所選取對比的各家soc處理器的CPU與AI加速器以及各具體單項性能資料如下:
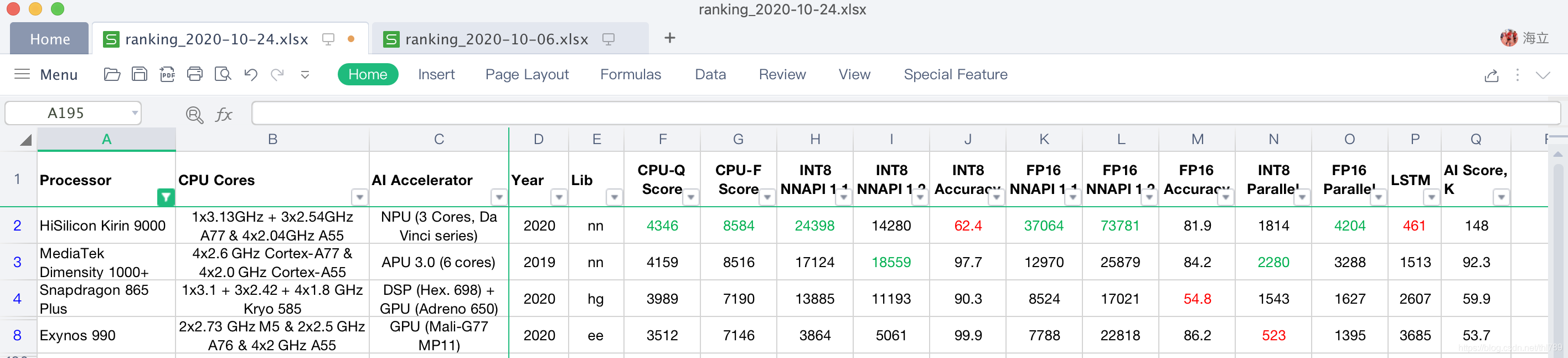
由此看出:
- CPU:因為Kirin 9000也是A77,不是Kirin 990 5G的A76,并且比Dimensity 1000+的工藝更先進,所以,其CPU的量化性能資料(CPU-Q)與浮點性能資料(CPU-F)的得分都比1000+還要高,不過是稍微超出,情理之中;
- INT8 NPU資料:麒麟9000的NNAPI 1.1分數超出天璣1000+很多(24398 vs 17124),看來NPU達芬奇架構在INT8的支持上也有了質的飛躍, 不過麒麟9000的NNAPI1.2分數不高(14280 vs 18559),可能是對NNAPI1.2新加的算子支持度不高導致,
- FP16 NPU資料:不管是NNAPI1.1還是NNAPI1.2資料,麒麟9000完全領先與其他各大soc處理器(NNAPI1.1得分:37064 vs 12970;NNAPI1.2得分:73781 vs 25879),
- 精度資料:麒麟9000的INT8以及驍龍865 Plus的FP16的精度資料較差,對于麒麟9000只是降低了分數,對驍龍865 Plus來說就是跑分上不去的一大因素了,
下面會逐項展開詳細分析這些資料及其背后展現的AI處理能力的邏輯,
一、CPU
看CPU的配置:
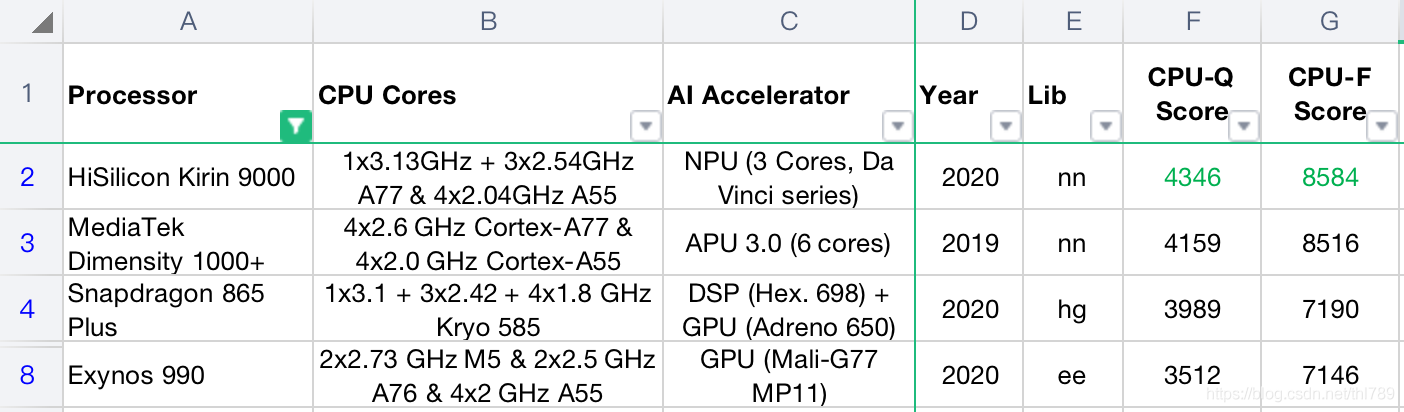
各家CPU的代系:
- 海思麒麟9000是A77,且5nm最新工藝超核能做到3.13GHZ;
- MTK天璣1000+是A77,4大核做到2.6 GHZ
- 驍龍865 Plus的Kryo 585也相當于A77
所以,這里的CPU跑分不管是量化還是浮點基本都反應了ARM的CPU架構代次以及芯片制造工藝水平,
各個模型的詳細跑分展開也進一步說明了這種情況:
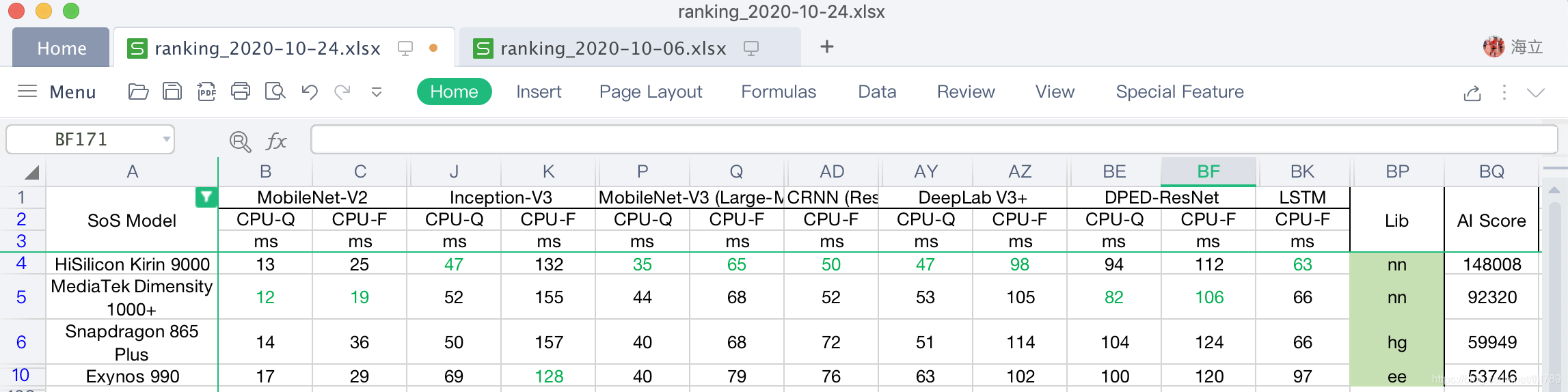
各個模型運行Latency最低的就是麒麟9000和天璣1000+了,
二、NNAPI-INT8
NNAPI-INT8資料反應了AI加速器對INT8量化模型的支持情況和性能:
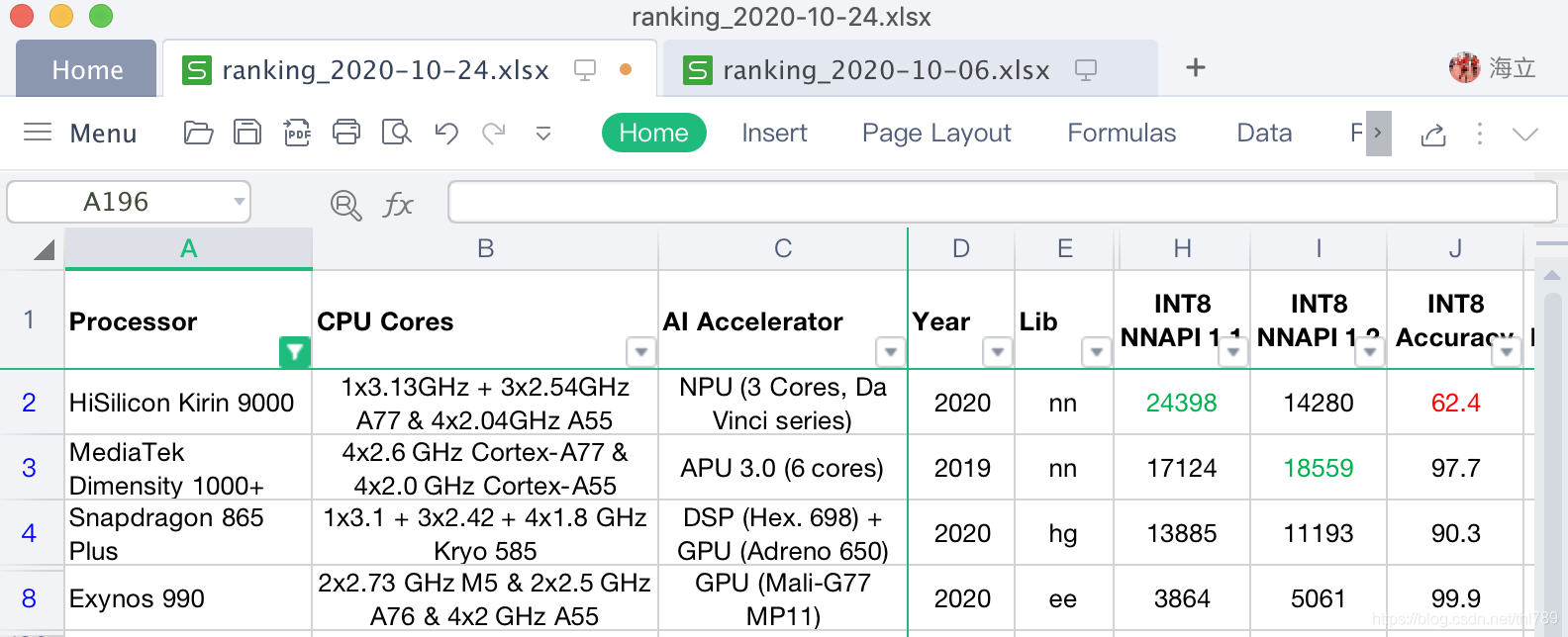
可以看到:海思麒麟9000的NNAPI 1.1超出第二名MTK天璣1000+很多(24398 vs 17124),看來NPU達芬奇架構在INT8的支持上也有了質的飛躍, 不過麒麟9000的NNAPI1.2不高(14280 vs 18559),可能是對NNAPI1.2新加的算子支持度不高導致,
各個模型的詳細跑分展開說明了這種情況:
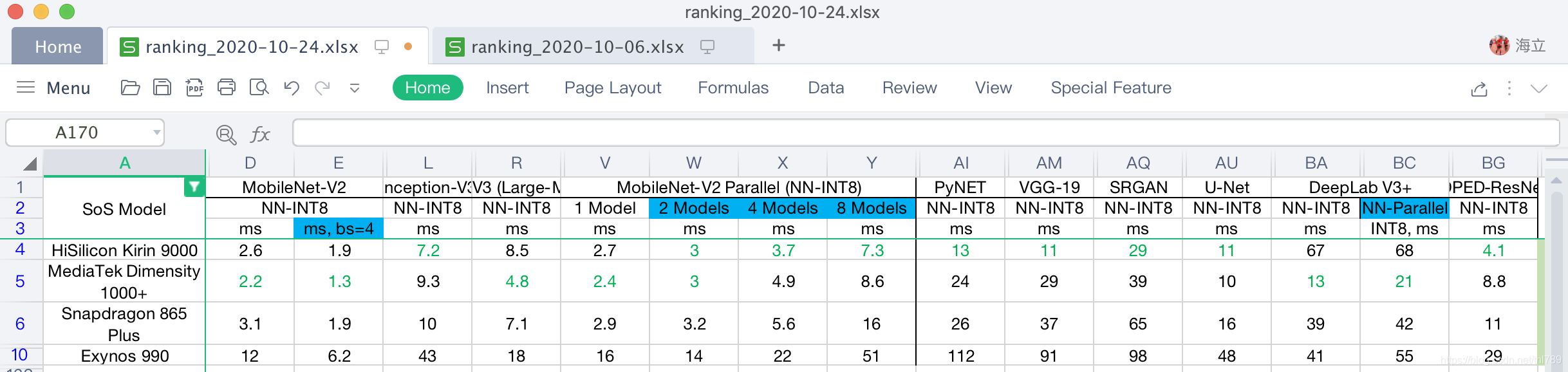
各個量化INT8模型測驗中:
- 麒麟9000在Inception-V3、MobileNet-V2 Parallel(2/4/8 Models)、PyNet、VGG-19、SRGAN、U-Net以及DPED-ResNet等9個量化指標中都占據第一;
- 天璣1000+在MobileNet-V2(bs=1, 2)、MobileNet-V3、MobileNet-V2 Parallel(1 Models)、DeepLab V3(單以及Parallel)等6個量化指標中占據第一;
而且帶背景的高亮部分應該是反應的Paralle能力,去除之后應該是麒麟9000 vs 天璣1000+:6 vs 4
因為不同的模型中的算子定義在不同的NNAPI版本中,而具體哪個模型反應了NNAPI 1.?的指標,AI-Benchmark官方并沒直接給出,這里也就暫時不能定量的詳細的給出,但這里基本反應了INT8的總分情況,麒麟9000對MTK天璣1000+:NNAPI 1.1 24398 vs 17124;NNAPI1.2 14280 vs 18559,
三、NNAPI-FP16
NNAPI-FP16資料反應了AI加速器對FP16浮點模型的支持情況和性能:
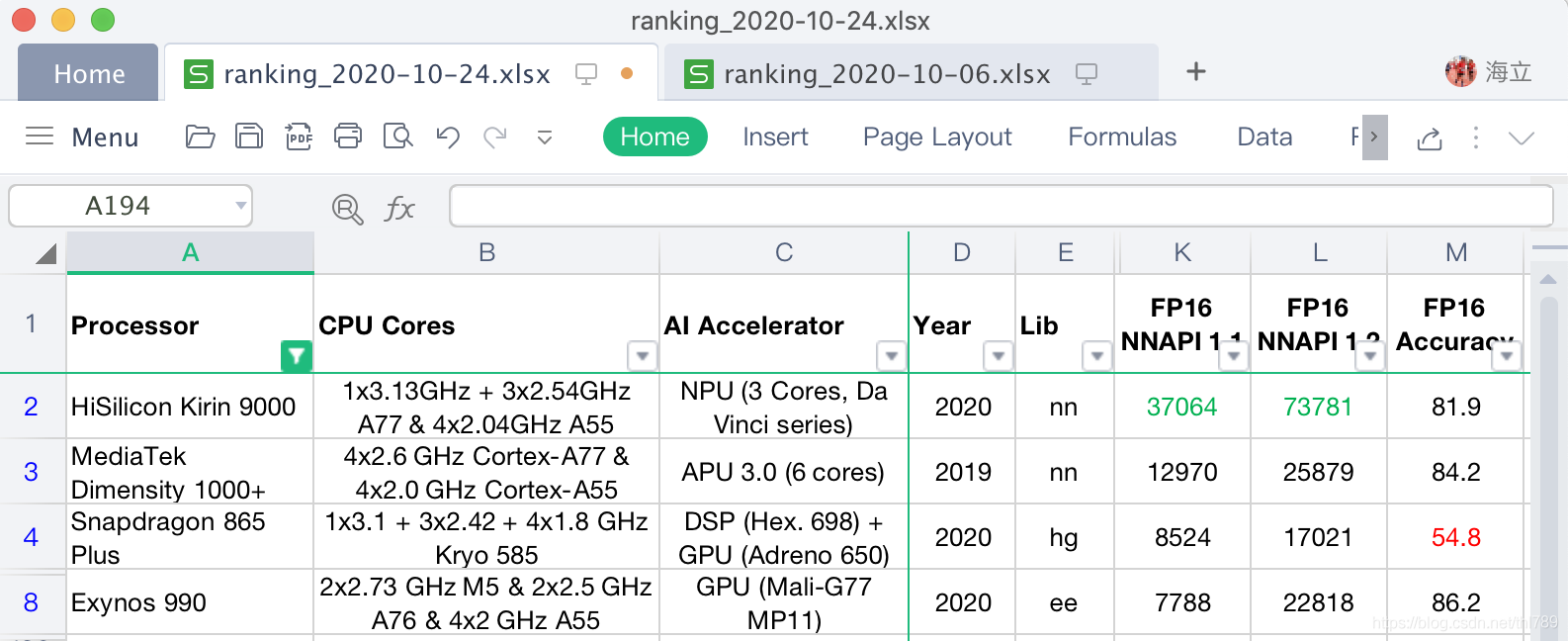
可以看到:不管是NNAPI1.1還是NNAPI1.2資料,海思麒麟9000完全領先其他各家,對比第二的MTK天璣1000+(NNAPI1.1得分:37064 vs 12970;NNAPI1.2得分:73781 vs 25879),
各個模型的詳細跑分展開說明了這種情況:
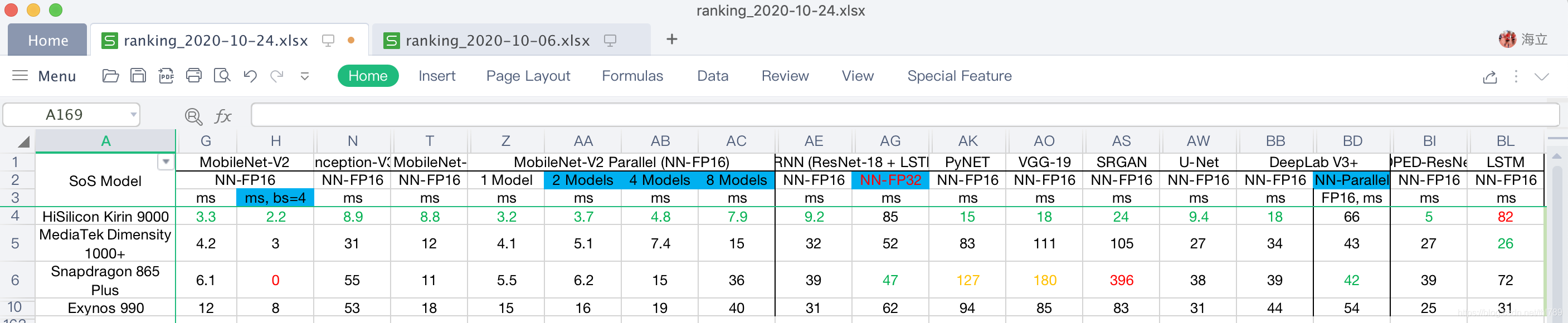
各個FP16浮點模型測驗中:
- 麒麟9000在MobileNet-V2(bs=1, 2)、Inception-V3、MobileNet-V3、MobileNet-V2 Parallel(1/2/4/8 Models)、CRNN (ResNet-18 + LSTM)、PyNet、VGG-19、SRGAN、U-Net、DeepLab V3+以及DPED-ResNet等15個FP16模型指標中都占據第一,且比第二的Latency低很多;
- 麒麟9000僅僅LSTM的支持比較差,另外FP32的支持【通過CRNN (ResNet-18 + LSTM)】也不強,
帶背景的高亮部分應該是反應的Paralle能力,去除之后麒麟9000 也有11個單個模型測驗高居第一,
這基本反應了FP16的總分情況,
四、精度
精度資料反應了AI加速器計算時的精度,所以也僅僅NNAPI-INT8和NNAPI-FP16才會考察該指標:
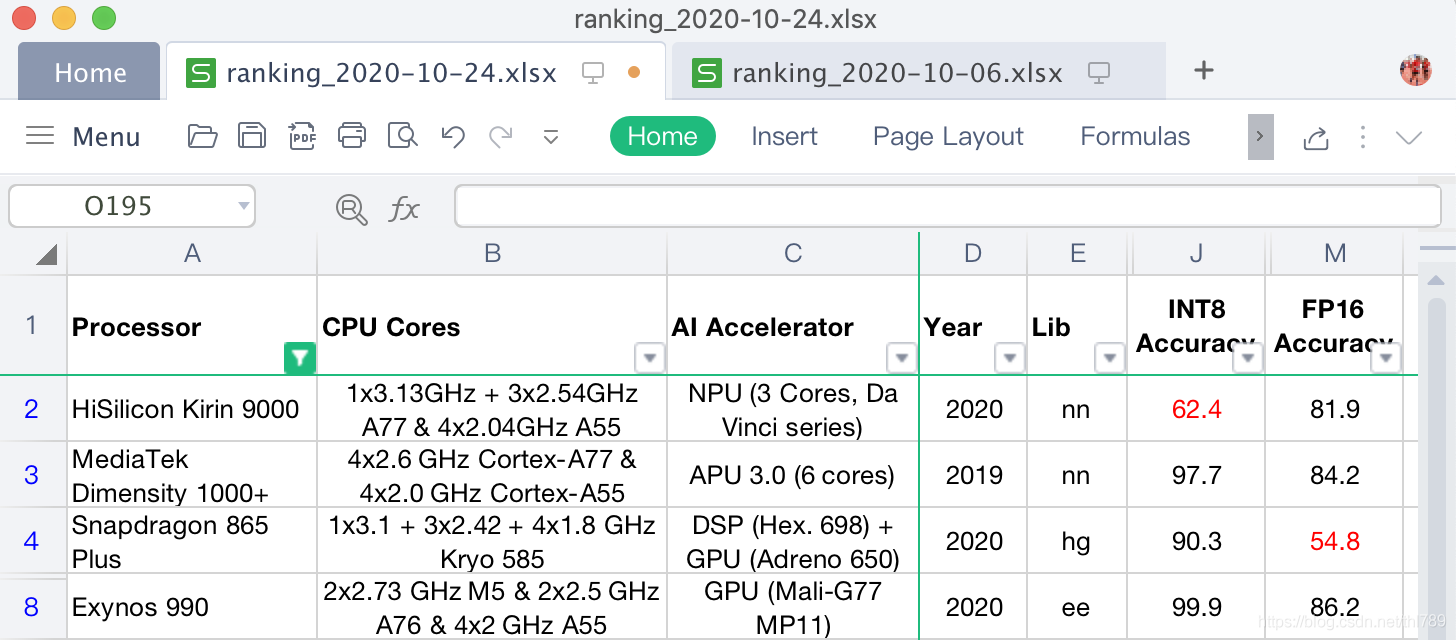
可以看到:麒麟9000的INT8以及驍龍865 Plus的FP16的精度資料較差,
各個模型的詳細跑分展開說明了這種情況:
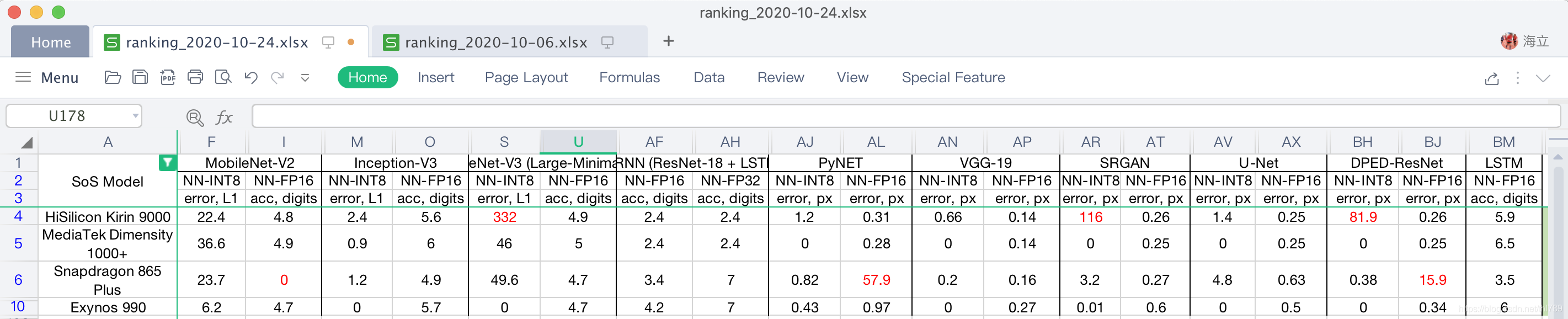
模型測驗的精度結果中:
- 麒麟9000的MobileNet-V3、SRGAN以及DPED-ResNet的NNAPI-INT8精度都很差;
- 驍龍865 Plus的PyNet以及DPED-ResNet的NNAPI-FP16精度也很差;
- MTK的天璣1000+在INT8和FP16的精度方面表現都很好,
精度方面,對于麒麟9000是降低了些分數,對驍龍865 Plus來說就是跑分上不去的一大因素了,
五、并發性能
并發資料反應了對多個AI推理任務的支持情況,從NNAPI-INT8和NNAPI-FP16考察該指標:
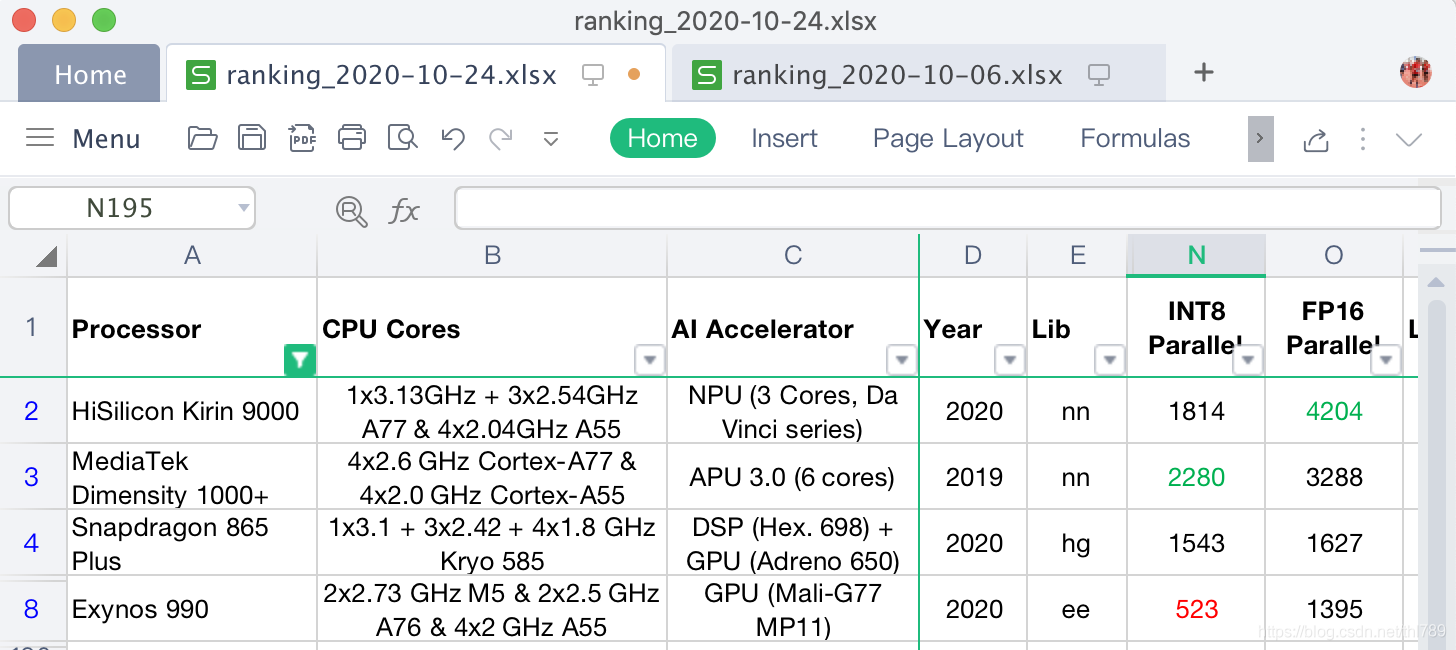
可以看到:麒麟9000對FP16支持比較好;天璣1000+對INT8支持比較好,
各個模型的詳細跑分展開說明了這種情況:
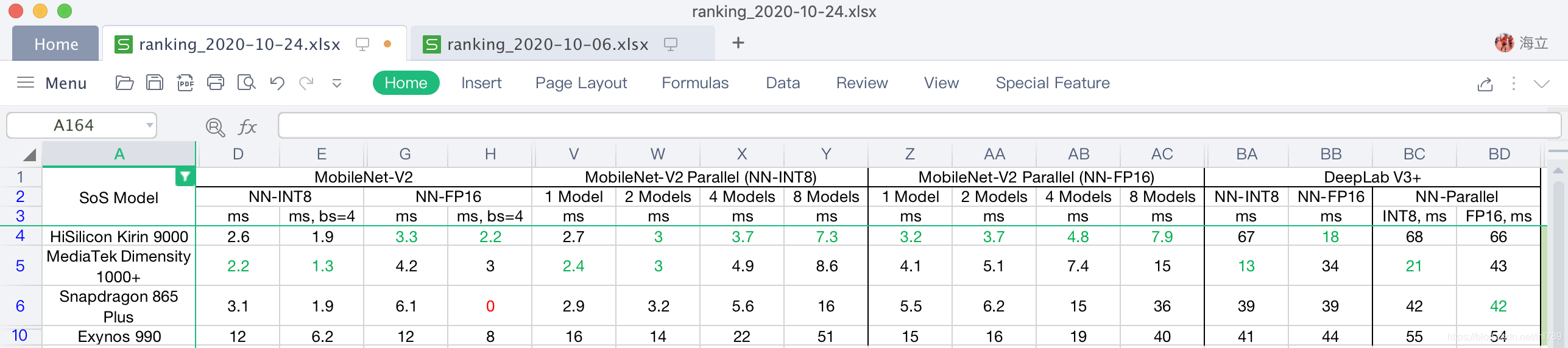
各個模型并發測驗結果中:
- 海思麒麟9000的各項FP16指標都很好,MobileNet V2 batch=4,以及MobileNet-V2(2/4/8個模型運行)都據第一,5占其4,且另一個DeepLab V3+并沒有被拉大距離;
- MTK天璣1000+各項INT8指標都很好,MobileNet V2 batch=4,MobileNet-V2(2個模型運行)以及DeepLab V3+都據第一,5占其3,雖然麒麟9000在MobileNet-V2(4/8個模型運行)占第一,但其實沒拉開與天璣1000+的差距,所以,最終天璣1000+的INT8并發指標好于麒麟9000;
- 驍龍865 Plus的DPED-ResNet的FP16的并發性能最強,不過并沒有拉開對別家的距離而形成優勢,
所以,總體并發性能看,麒麟9000對FP16支持比較好;天璣1000+對INT8支持比較好,
總結——當前態勢
通過上面對各家最頂級soc的分析,可以看到目前整個Android生態移動soc市場(其實移動市場也就Apple的iPhone系列不在這個體系)中AI的支持情況:
1. 華為海思麒麟達芬奇系列
通過達芬奇架構的NPU的加持,FP16性能,不管是NNAPI1.1還是NNAPI1.2資料,海思麒麟9000完全領先其他各家,對比第二的MTK天璣1000+(NNAPI1.1得分:37064 vs 12970;NNAPI1.2得分:73781 vs 25879)
INT8性能海思麒麟9000的NNAPI 1.1超出MTK天璣1000+很多(24398 vs 17124),看來NPU達芬奇架構在INT8的支持上也有了質的飛躍, 不過NNAPI1.2不高(14280 vs 18559),可能是對NNAPI1.2新加的算子支持度不高,
麒麟9000的INT8的精度不高,特別是三個模型MobileNet-V3、SRGAN以及DPED-ResNet的精度可以說是很差,光推理速度快,結果都是錯的,這快的質量要大打折扣的,
2. MTK天璣系列
MTK天璣1000+各方面都很均衡,各項指標(INT8量化性能、FP16浮點性能、INT8量化精度、FP16浮點精度、NNAPI1.2的支持)都很好,所以在麒麟9000發布之前,領先其他各家很多占據榜首(92.3k vs 當時的第二名高通驍龍865Plus的59.9k),
當然天璣1000+是2019年的產品,麒麟9000是新發布的產品,這態勢也只能說是目前的態勢,
3. 高通驍龍系列
高通驍龍865 Plus各項指標(INT8量化性能、INT8量化精度、FP16浮點精度、NNAPI1.2的支持)都比較好,考慮到其FP支持是在GPU上做,FP16的整體性能資料不高也能理解,而其FP32能力是最強的,不過估計評分體系中所占比重不高,
但是其FP16的精度資料很低是比較意外的,特別是PyNet以及DPED-ResNet的精度很差,而FP16在整個評分體系中的比重又比較高,所以Qualcomm要提高它的評分,應該關注一下它GPU支持的精度問題,而且即便不是為了AI-Benchmark上的跑分,實際運行模型的時候,精度差也基本上是不被接受的,
4. CPU性能資料
CPU沒什么特別可說的,基本比拼的是CPU的代次和工藝了,最新ARM架構、最先進工藝就意味著分數較高,不過CPU分數的差距也拉不開,差別也不大,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/192939.html
標籤:java