頂級資料挖掘會議ICDM于2006年12月評選出了資料挖掘領域的十大經典演算法,kNN便是其中一個,
kNN演算法的思想是:在訓練集中選取與輸入資料最近的k個鄰居,統計k個鄰居中出現次數最多的類別,以此作為該輸入資料的類別,這是非常合理的一個想法,因為“物以類聚,人以群分”,隸屬于聚類演算法的k-means與kNN有異曲同工之妙,基本思想是一致的,
k-means演算法對k值的選取是有要求的,k過大或過小都會降低演算法的實際效果,
同樣,kNN中k的取值也要適當:若k值過小,預測結果會對噪音樣本點顯得例外敏感,比如k等于1時,kNN退化成最近鄰演算法,沒有了顯式學習程序,若k值過大,會有較大的鄰域訓練樣本進行預測,雖然減小噪音樣本點的干擾,但是距離較遠的訓練樣本點與距離較近的訓練樣本點對預測結果會有相同程度的影響,造成預測結果錯誤,
對于輸入樣本點的k個鄰居而言,由于每個鄰居與樣本點的距離不等,所以這k個鄰居對最終預測結果的影響也不應該一樣,距離較遠的鄰居對預測結果的影回應該比距離較近的鄰居的影響小,所以需要考慮對kNN進行優化,一種較常用的方法是,對距離不同的鄰居的影響力(或貢獻值)賦予不同的權重,距離越遠則權重越小,表示影響力較小,
前文已經提到,演算法需要計算距離大小,所以需要一個距離函式衡量兩個樣本之間的距離,常用的距離函式有:歐氏距離、余弦距離、漢明距離以及曼哈頓距離等,一般選歐氏距離作為距離度量,但這只適用于連續變數,在文本分類這種非連續變數情況下,通常選用漢明距離,
一個kNN的具體示例如下:
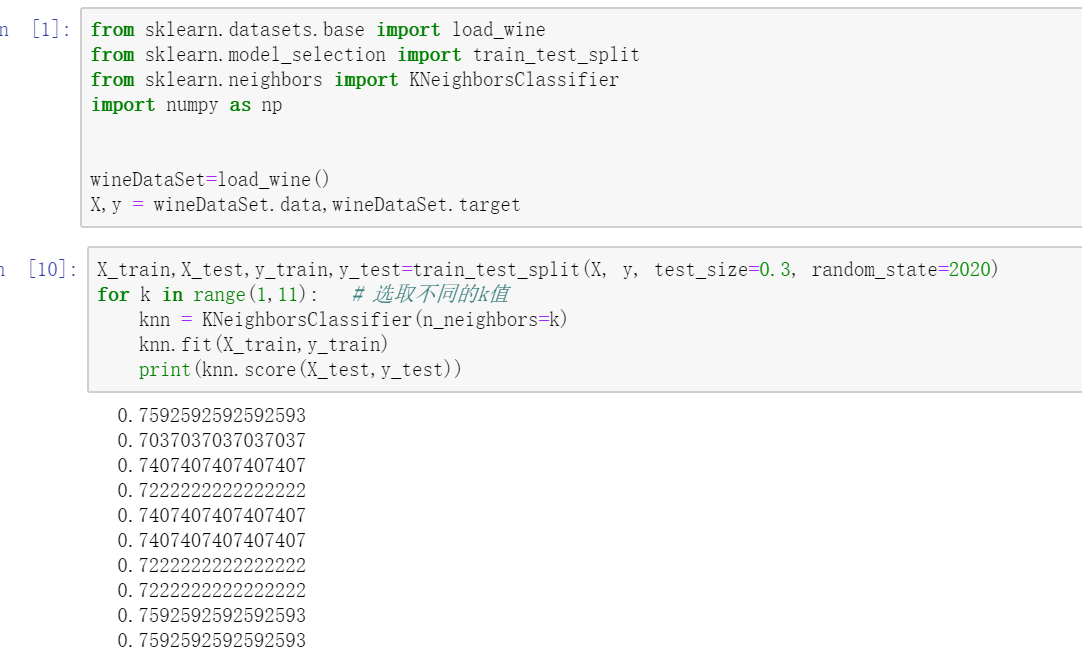
從上圖可以看到,k的不同導致了模型在測驗集準確率約六個百分點的波動(示例程式沒有作權重分配處理),
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/193608.html
標籤:Python