什么是模塊?
常見的場景:一個模塊就是一個包含了python定義和宣告的檔案,檔案名就是模塊名字加上.py的后綴,
但其實import加載的模塊分為四個通用類別:
1 使用python撰寫的代碼(.py檔案)
2 已被編譯為共享庫或DLL的C或C++擴展
3 包好一組模塊的包
4 使用C撰寫并鏈接到python解釋器的內置模塊
為何要使用模塊?
如果你退出python解釋器然后重新進入,那么你之前定義的函式或者變數都將丟失,因此我們通常將程式寫到檔案中以便永久保存下來,需要時就通過python test.py方式去執行,此時test.py被稱為腳本script,
隨著程式的發展,功能越來越多,為了方便管理,我們通常將程式分成一個個的檔案,這樣做程式的結構更清晰,方便管理,這時我們不僅僅可以把這些檔案當做腳本去執行,還可以把他們當做模塊來匯入到其他的模塊中,實作了功能的重復利用,
常用模塊
collections模塊
在內置資料型別(dict、list、set、tuple)的基礎上,collections模塊還提供了幾個額外的資料型別:Counter、deque、defaultdict、namedtuple和OrderedDict等,
1.namedtuple: 生成可以使用名字來訪問元素內容的tuple
2.deque: 雙端佇列,可以快速的從另外一側追加和推出物件
3.Counter: 計數器,主要用來計數
4.OrderedDict: 有序字典
5.defaultdict: 帶有默認值的字典
namedtuple
我們知道tuple可以表示不變集合,例如,一個點的二維坐標就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很難看出這個tuple是用來表示一個坐標的,
這時,namedtuple就派上了用場:
>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
類似的,如果要用坐標和半徑表示一個圓,也可以用namedtuple定義:
#namedtuple('名稱', [屬性list]): Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存盤資料時,按索引訪問元素很快,但是插入和洗掉元素就很慢了,因為list是線性存盤,資料量大的時候,插入和洗掉效率很低,
deque是為了高效實作插入和洗掉操作的雙向串列,適合用于佇列和堆疊:
>>> from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('x') >>> q.appendleft('y') >>> q deque(['y', 'a', 'b', 'c', 'x'])
deque除了實作list的append()和pop()外,還支持appendleft()和popleft(),這樣就可以非常高效地往頭部添加或洗掉元素,
OrderedDict
使用dict時,Key是無序的,在對dict做迭代時,我們無法確定Key的順序,
如果要保持Key的順序,可以用OrderedDict:
>>> from collections import OrderedDict >>> d = dict([('a', 1), ('b', 2), ('c', 3)]) >>> d # dict的Key是無序的 {'a': 1, 'c': 3, 'b': 2} >>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key會按照插入的順序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的順序回傳 ['z', 'y', 'x']
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大于 66 的值保存至字典的第一個key中,將小于 66 的值保存至第二個key的值中,
即: {'k1': 大于66 , 'k2': 小于66}


values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = {} for value in values: if value>66: if my_dict.has_key('k1'): my_dict['k1'].append(value) else: my_dict['k1'] = [value] else: if my_dict.has_key('k2'): my_dict['k2'].append(value) else: my_dict['k2'] = [value]原生字典解決方法
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value)defaultdict字典解決方法
使用dict時,如果參考的Key不存在,就會拋出KeyError,如果希望key不存在時,回傳一個默認值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,回傳默認值 'N/A'例1
Counter
Counter類的目的是用來跟蹤值出現的次數,它是一個無序的容器型別,以字典的鍵值對形式存盤,其中元素作為key,其計數作為value,計數值可以是任意的Interger(包括0和負數),Counter類和其他語言的bags或multisets很相似,
c = Counter('abcdeabcdabcaba') print c 輸出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他詳細內容 http://www.cnblogs.com/Eva-J/articles/7291842.html
time模塊
和時間有關系的我們就要用到時間模塊,在使用模塊之前,應該首先匯入這個模塊,
#常用方法 1.time.sleep(secs) (執行緒)推遲指定的時間運行,單位為秒, 2.time.time() 獲取當前時間戳
表示時間的三種方式
在Python中,通常有這三種方式來表示時間:時間戳、元組(struct_time)、格式化的時間字串:
(1)時間戳(timestamp) :通常來說,時間戳表示的是從1970年1月1日00:00:00開始按秒計算的偏移量,我們運行“type(time.time())”,回傳的是float型別,
(2)格式化的時間字串(Format String): ‘1999-12-06’
%y 兩位數的年份表示(00-99) %Y 四位數的年份表示(000-9999) %m 月份(01-12) %d 月內中的一天(0-31) %H 24小時制小時數(0-23) %I 12小時制小時數(01-12) %M 分鐘數(00=59) %S 秒(00-59) %a 本地簡化星期名稱 %A 本地完整星期名稱 %b 本地簡化的月份名稱 %B 本地完整的月份名稱 %c 本地相應的日期表示和時間表示 %j 年內的一天(001-366) %p 本地A.M.或P.M.的等價符 %U 一年中的星期數(00-53)星期天為星期的開始 %w 星期(0-6),星期天為星期的開始 %W 一年中的星期數(00-53)星期一為星期的開始 %x 本地相應的日期表示 %X 本地相應的時間表示 %Z 當前時區的名稱 %% %號本身
(3)元組(struct_time) :struct_time元組共有9個元素共九個元素:(年,月,日,時,分,秒,一年中第幾周,一年中第幾天等)
| 索引(Index) | 屬性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(時) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第幾天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令時) | 默認為0 |
首先,我們先匯入time模塊,來認識一下python中表示時間的幾種格式:
#匯入時間模塊 >>>import time #時間戳 >>>time.time() 1500875844.800804 #時間字串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04' #時間元組:localtime將一個時間戳轉換為當前時區的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
小結:時間戳是計算機能夠識別的時間;時間字串是人能夠看懂的時間;元組則是用來操作時間的
幾種格式之間的轉換
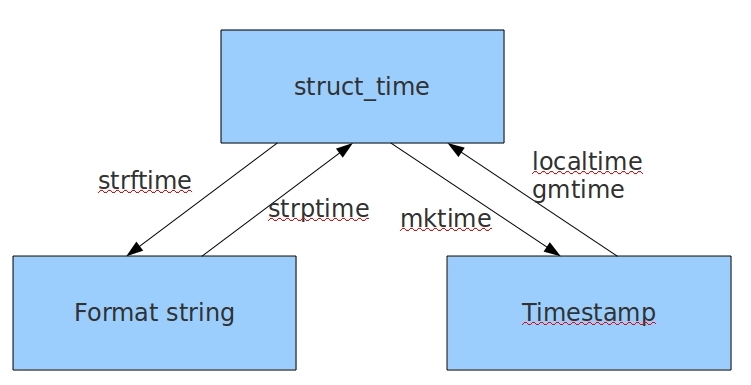
#時間戳-->結構化時間 #time.gmtime(時間戳) #UTC時間,與英國倫敦當地時間一致 #time.localtime(時間戳) #當地時間,例如我們現在在北京執行這個方法:與UTC時間相差8小時,UTC時間+8小時 = 北京時間 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #結構化時間-->時間戳 #time.mktime(結構化時間) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#結構化時間-->字串時間 #time.strftime("格式定義","結構化時間") 結構化時間引數若不傳,則顯示當前時間 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14' #字串時間-->結構化時間 #time.strptime(時間字串,字串對應格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
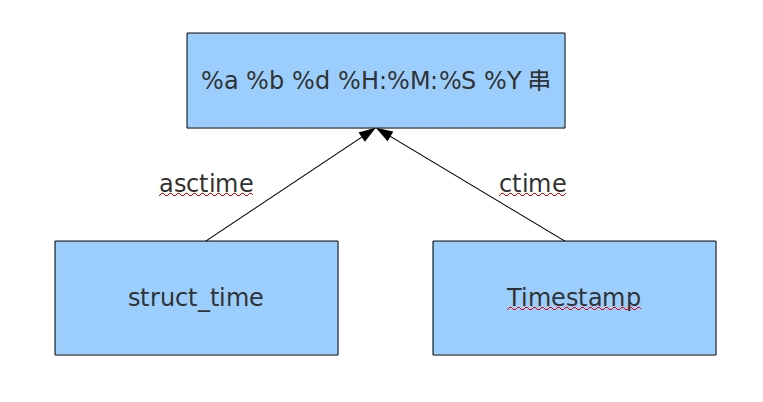
#結構化時間 --> %a %b %d %H:%M:%S %Y串 #time.asctime(結構化時間) 如果不傳引數,直接回傳當前時間的格式化串 >>>time.asctime(time.localtime(1500000000)) 'Fri Jul 14 10:40:00 2017' >>>time.asctime() 'Mon Jul 24 15:18:33 2017' #時間戳 --> %a %b %d %H:%M:%S %Y串 #time.ctime(時間戳) 如果不傳引數,直接回傳當前時間的格式化串 >>>time.ctime() 'Mon Jul 24 15:19:07 2017' >>>time.ctime(1500000000) 'Fri Jul 14 10:40:00 2017'
import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('過去了%d年%d月%d天%d小時%d分鐘%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))計算時間差
datetime模塊
1.datetime.now() # 獲取當前datetime
datetime.utcnow() # 獲取當前格林威治時間
from datetime import datetime #獲取當前本地時間 a=datetime.now() print('當前日期:',a) #獲取當前世界時間 b=datetime.utcnow() print('世界時間:',b)
2.datetime(2017, 5, 23, 12, 20) # 用指定日期時間創建datetime
from datetime import datetime #用指定日期創建 c=datetime(2017, 5, 23, 12, 20) print('指定日期:',c)
3.將以下字串轉換成datetime型別:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8時42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
# 時間字串格式化 from datetime import datetime d=datetime.strptime('2017/9/30','%Y/%m/%d') print(d) e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六') print(e) f=datetime.strptime('2017年9月30日星期六8時42分24秒','%Y年%m月%d日星期六%H時%M分%S秒') print(f) g=datetime.strptime('9/30/2017','%m/%d/%Y') print(g) h=datetime.strptime('9/30/2017 8:42:50 ','%m/%d/%Y %H:%M:%S ') print(h)
4.將以下datetime型別轉換成字串:
2017年9月28日星期4,10時3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
# 時間字串格式化 from datetime import datetime i=datetime(2017,9,28,10,3,43) print(i.strftime('%Y年%m月%d日%A,%H時%M分%S秒')) j=datetime(2017,9,30,10,3,43) print(j.strftime('%A,%B %d,%Y')) k=datetime(2017,9,30,9,22,17) print(k.strftime('%m/%d/%Y %I:%M:%S%p')) l=datetime(2017,9,30) print(l.strftime('%B %d,%Y'))
5.用系統時間輸出以下字串:
今天是2017年9月30日
今天是這周的第?天
今天是今年的第?天
今周是今年的第?周
今天是當月的第?天
from datetime import datetime #獲取當前系統時間 m=datetime.now() print(m.strftime('今天是%Y年%m月%d日')) print(m.strftime('今天是這周的第%w天')) print(m.strftime('今天是今年的第%j天')) print(m.strftime('今周是今年的第%W周')) print(m.strftime('今天是當月的第%d天'))
random模塊
>>> import random #隨機小數 >>> random.random() # 大于0且小于1之間的小數 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小數 1.6270147180533838
#恒富:發紅包 #隨機整數 >>> random.randint(1,5) # 大于等于1且小于等于5之間的整數 >>> random.randrange(1,10,2) # 大于等于1且小于10之間的奇數 #隨機選擇一個回傳 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #隨機選擇多個回傳,回傳的個數為函式的第二個引數 >>> random.sample([1,'23',[4,5]],2) # #串列元素任意2個組合 [[4, 5], '23'] #打亂串列順序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打亂次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
練習:生成隨機驗證碼
import random def v_code(): code = '' for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,90)) add=random.choice([num,alf]) code="".join([code,str(add)]) return code print(v_code())生成驗證碼
os模塊
os模塊是與作業系統互動的一個介面
os.makedirs('dirname1/dirname2') 可生成多層遞回目錄
os.removedirs('dirname1') 若目錄為空,則洗掉,并遞回到上一級目錄,如若也為空,則洗掉,依此類推
os.mkdir('dirname') 生成單級目錄;相當于shell中mkdir dirname
os.rmdir('dirname') 洗掉單級空目錄,若目錄不為空則無法洗掉,報錯;相當于shell中rmdir dirname
os.listdir('dirname') 列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,并以串列方式列印
os.remove() 洗掉一個檔案
os.rename("oldname","newname") 重命名檔案/目錄
os.stat('path/filename') 獲取檔案/目錄資訊
os.system("bash command") 運行shell命令,直接顯示
os.popen("bash command).read() 運行shell命令,獲取執行結果
os.getcwd() 獲取當前作業目錄,即當前python腳本作業的目錄路徑
os.chdir("dirname") 改變當前腳本作業目錄;相當于shell下cd
os.path
os.path.abspath(path) 回傳path規范化的絕對路徑
os.path.split(path) 將path分割成目錄和檔案名二元組回傳
os.path.dirname(path) 回傳path的目錄,其實就是os.path.split(path)的第一個元素
os.path.basename(path) 回傳path最后的檔案名,如何path以/或\結尾,那么就會回傳空值,即os.path.split(path)的第二個元素
os.path.exists(path) 如果path存在,回傳True;如果path不存在,回傳False
os.path.isabs(path) 如果path是絕對路徑,回傳True
os.path.isfile(path) 如果path是一個存在的檔案,回傳True,否則回傳False
os.path.isdir(path) 如果path是一個存在的目錄,則回傳True,否則回傳False
os.path.join(path1[, path2[, ...]]) 將多個路徑組合后回傳,第一個絕對路徑之前的引數將被忽略
os.path.getatime(path) 回傳path所指向的檔案或者目錄的最后訪問時間
os.path.getmtime(path) 回傳path所指向的檔案或者目錄的最后修改時間
os.path.getsize(path) 回傳path的大小
注意:os.stat('path/filename') 獲取檔案/目錄資訊 的結構說明
stat 結構: st_mode: inode 保護模式 st_ino: inode 節點號, st_dev: inode 駐留的設備, st_nlink: inode 的鏈接數, st_uid: 所有者的用戶ID, st_gid: 所有者的組ID, st_size: 普通檔案以位元組為單位的大小;包含等待某些特殊檔案的資料, st_atime: 上次訪問的時間, st_mtime: 最后一次修改的時間, st_ctime: 由作業系統報告的"ctime",在某些系統上(如Unix)是最新的元資料更改的時間,在其它系統上(如Windows)是創建時間(詳細資訊參見平臺的檔案),
os.sep 輸出作業系統特定的路徑分隔符,win下為"\\",Linux下為"/" os.linesep 輸出當前平臺使用的行終止符,win下為"\r\n",Linux下為"\n" os.pathsep 輸出用于分割檔案路徑的字串 win下為;,Linux下為: os.name 輸出字串指示當前使用平臺,win->'nt'; Linux->'posix'
os模塊應用
os模塊+shutil模塊,批量移動多個檔案夾下檔案
import os import shutil file_path = r"D:\Download\SkyDrive\go語言入門-視頻" new_path = r"F:\GoMP4" file_lst = os.listdir(file_path) for i in file_lst: ol = file_path + "\\" + i mp4_lst = os.listdir(ol) for x in mp4_lst: mp4_path = ol + "\\" + x shutil.move(mp4_path,new_path) print(f"{x} --移動成功") print("全部完成!")
os模塊批量修改檔案夾或者檔案的名字
import os path = r"F:\Go_noteBook" dir_list = os.listdir(path) for i in dir_list: path_name = path + "\\" + i new_name = path + "\\" + i[9:] os.rename(path_name, new_name) print("{path_name}重命名成功,新檔案名為{new_name}".format(path_name=path_name, new_name=new_name)) print("全部完成!")
sys模塊
sys模塊是與python解釋器互動的一個介面
sys.argv 命令列引數List,第一個元素是程式本身路徑
sys.exit(n) 退出程式,正常退出時exit(0),錯誤退出sys.exit(1)
sys.version 獲取Python解釋程式的版本資訊
sys.path 回傳模塊的搜索路徑,初始化時使用PYTHONPATH環境變數的值
sys.platform 回傳作業系統平臺名稱
import sys try: sys.exit(1) except SystemExit as e: print(e)
序列化模塊
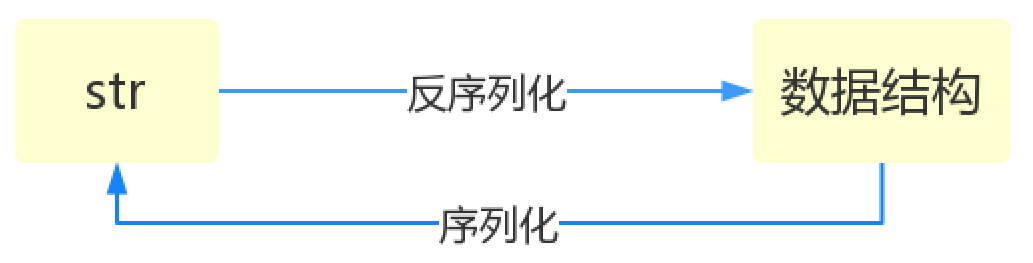
什么叫序列化——將原本的字典、串列等內容轉換成一個字串的程序就叫做序列化,
比如,我們在python代碼中計算的一個資料需要給另外一段程式使用,那我們怎么給? 現在我們能想到的方法就是存在檔案里,然后另一個python程式再從檔案里讀出來, 但是我們都知道,對于檔案來說是沒有字典這個概念的,所以我們只能將資料轉換成字典放到檔案中, 你一定會問,將字典轉換成一個字串很簡單,就是str(dic)就可以辦到了,為什么我們還要學習序列化模塊呢? 沒錯序列化的程序就是從dic 變成str(dic)的程序,現在你可以通過str(dic),將一個名為dic的字典轉換成一個字串, 但是你要怎么把一個字串轉換成字典呢? 聰明的你肯定想到了eval(),如果我們將一個字串型別的字典str_dic傳給eval,就會得到一個回傳的字典型別了, eval()函式十分強大,但是eval是做什么的?e官方demo解釋為:將字串str當成有效的運算式來求值并回傳計算結果, BUT!強大的函式有代價,安全性是其最大的缺點, 想象一下,如果我們從檔案中讀出的不是一個資料結構,而是一句"洗掉檔案"類似的破壞性陳述句,那么后果實在不堪設設想, 而使用eval就要擔這個風險, 所以,我們并不推薦用eval方法來進行反序列化操作(將str轉換成python中的資料結構)為什么要有序列化模塊
序列化的目的
1、以某種存盤形式使自定義物件持久化;
2、將物件從一個地方傳遞到另一個地方,
3、使程式更具維護性,
json
Json模塊提供了四個功能:dumps、dump、loads、load
import json dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #序列化:將一個字典轉換成一個字串 print(type(str_dic),str_dic) #<class 'str'> {"k3": "v3", "k1": "v1", "k2": "v2"} #注意,json轉換完的字串型別的字典中的字串是由""表示的 dic2 = json.loads(str_dic) #反序列化:將一個字串格式的字典轉換成一個字典 #注意,要用json的loads功能處理的字串型別的字典中的字串必須由""表示 print(type(dic2),dic2) #<class 'dict'> {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}] str_dic = json.dumps(list_dic) #也可以處理嵌套的資料型別 print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}] list_dic2 = json.loads(str_dic) print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}]loads和dumps
import json f = open('json_file','w') dic = {'k1':'v1','k2':'v2','k3':'v3'} json.dump(dic,f) #dump方法接收一個檔案句柄,直接將字典轉換成json字串寫入檔案 f.close() f = open('json_file') dic2 = json.load(f) #load方法接收一個檔案句柄,直接將檔案中的json字串轉換成資料結構回傳 f.close() print(type(dic2),dic2)load和dump
import json f = open('file','w') json.dump({'國籍':'中國'},f) ret = json.dumps({'國籍':'中國'}) f.write(ret+'\n') json.dump({'國籍':'美國'},f,ensure_ascii=False) ret = json.dumps({'國籍':'美國'},ensure_ascii=False) f.write(ret+'\n') f.close()ensure_ascii關鍵字引數
Serialize obj to a JSON formatted str.(字串表示的json物件) Skipkeys:默認值是False,如果dict的keys內的資料不是python的基本型別(str,unicode,int,long,float,bool,None),設定為False時,就會報TypeError的錯誤,此時設定成True,則會跳過這類key ensure_ascii:,當它為True的時候,所有非ASCII碼字符顯示為\uXXXX序列,只需在dump時將ensure_ascii設定為False即可,此時存入json的中文即可正常顯示,) If check_circular is false, then the circular reference check for container types will be skipped and a circular reference will result in an OverflowError (or worse). If allow_nan is false, then it will be a ValueError to serialize out of range float values (nan, inf, -inf) in strict compliance of the JSON specification, instead of using the JavaScript equivalents (NaN, Infinity, -Infinity). indent:應該是一個非負的整型,如果是0就是頂格分行顯示,如果為空就是一行最緊湊顯示,否則會換行且按照indent的數值顯示前面的空白分行顯示,這樣列印出來的json資料也叫pretty-printed json separators:分隔符,實際上是(item_separator, dict_separator)的一個元組,默認的就是(‘,’,’:’);這表示dictionary內keys之間用“,”隔開,而KEY和value之間用“:”隔開, default(obj) is a function that should return a serializable version of obj or raise TypeError. The default simply raises TypeError. sort_keys:將資料根據keys的值進行排序, To use a custom JSONEncoder subclass (e.g. one that overrides the .default() method to serialize additional types), specify it with the cls kwarg; otherwise JSONEncoder is used.其他引數說明
import json data = {'username':['李華','二愣子'],'sex':'male','age':16} json_dic2 = json.dumps(data,sort_keys=True,indent=2,separators=(',',':'),ensure_ascii=False) print(json_dic2)json格式化輸出
pickle
json & pickle 模塊
用于序列化的兩個模塊
- json,用于字串 和 python資料型別間進行轉換
- pickle,用于python特有的型別 和 python的資料型別間進行轉換
pickle模塊提供了四個功能:dumps、dump(序列化,存)、loads(反序列化,讀)、load (不僅可以序列化字典,串列...可以把python中任意的資料型別序列化)
import pickle dic = {'k1':'v1','k2':'v2','k3':'v3'} str_dic = pickle.dumps(dic) print(str_dic) #一串二進制內容 dic2 = pickle.loads(str_dic) print(dic2) #字典 import time struct_time = time.localtime(1000000000) print(struct_time) f = open('pickle_file','wb') pickle.dump(struct_time,f) f.close() f = open('pickle_file','rb') struct_time2 = pickle.load(f) print(struct_time2.tm_year)pickle
這時候機智的你又要說了,既然pickle如此強大,為什么還要學json呢?
這里我們要說明一下,json是一種所有的語言都可以識別的資料結構,
如果我們將一個字典或者序列化成了一個json存在檔案里,那么java代碼或者js代碼也可以拿來用,
但是如果我們用pickle進行序列化,其他語言就不能讀懂這是什么了~
所以,如果你序列化的內容是串列或者字典,我們非常推薦你使用json模塊
但如果出于某種原因你不得不序列化其他的資料型別,而未來你還會用python對這個資料進行反序列化的話,那么就可以使用pickle
re模塊
講正題之前我們先來看一個例子:https://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com/
這是京東的注冊頁面,打開頁面我們就看到這些要求輸入個人資訊的提示,
假如我們隨意的在手機號碼這一欄輸入一個11111111111,它會提示我們格式有誤,
這個功能是怎么實作的呢?
假如現在你用python寫一段代碼,類似:
phone_number = input('please input your phone number : ')
你怎么判斷這個phone_number是合法的呢?
根據手機號碼一共11位并且是只以13、14、15、18開頭的數字這些特點,我們用python寫了如下代碼:
while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手機號碼') else: print('不是合法的手機號碼')判斷手機號碼是否合法1
這是你的寫法,現在我要展示一下我的寫法:
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手機號碼') else: print('不是合法的手機號碼')判斷手機號是否合法2
對比上面的兩種寫法,此時此刻,我要問你你喜歡哪種方法呀?你肯定還是會說第一種,為什么呢?因為第一種不用學呀!
但是如果現在有一個檔案,我讓你從整個檔案里匹配出所有的手機號碼,你用python給我寫個試試?
但是學了今天的技能之后,分分鐘幫你搞定!
今天我們要學習python里的re模塊和正則運算式,學會了這個就可以幫我們解決剛剛的疑問,正則運算式不僅在python領域,在整個編程屆都占有舉足輕重的地位,
不管以后你是不是去做python開發,只要你是一個程式員就應該了解正則運算式的基本使用,如果未來你要在爬蟲領域發展,你就更應該好好學習這方面的知識, 但是你要知道,re模塊本質上和正則運算式沒有一毛錢的關系,re模塊和正則運算式的關系 類似于 time模塊和時間的關系 你沒有學習python之前,也不知道有一個time模塊,但是你已經認識時間了 12:30就表示中午十二點半(這個時間可好,一般這會兒就該下課了), 時間有自己的格式,年月日時分秒,12個月,365天......已經成為了一種規則,你也早就牢記于心了,time模塊只不過是python提供給我們的可以方便我們操作時間的一個工具而已正則運算式和re模塊
正則運算式本身也和python沒有什么關系,就是匹配字串內容的一種規則,
官方定義:正則運算式是對字串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規則字串”,這個“規則字串”用來表達對字串的一種過濾邏輯,
正則運算式
一說規則我已經知道你很暈了,現在就讓我們先來看一些實際的應用,在線測驗工具 http://tool.chinaz.com/regex/
首先你要知道的是,談到正則,就只和字串相關了,在我給你提供的工具中,你輸入的每一個字都是一個字串,
其次,如果在一個位置的一個值,不會出現什么變化,那么是不需要規則的,
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上,這連python的字串操作都可以輕松做到,
那么在之后我們更多要考慮的是在同一個位置上可以出現的字符的范圍,
字符組 : [字符組] 在同一個位置可能出現的各種字符組成了一個字符組,在正則運算式中用[]表示 字符分為很多類,比如數字、字母、標點等等, 假如你現在要求一個位置"只能出現一個數字",那么這個位置上的字符只能是0、1、2...9這10個數之一,
正則 |
待匹配字符 |
匹配 |
說明 |
[0123456789] |
8 |
True |
在一個字符組里列舉合法的所有字符,字符組里的任意一個字符 |
[0123456789] |
a |
False |
由于字符組中沒有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范圍,[0-9]就和[0123456789]是一個意思 |
[a-z] |
s |
True |
同樣的如果要匹配所有的小寫字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大寫字母 |
[0-9a-fA-F] |
e |
True |
可以匹配數字,大小寫形式的a~f,用來驗證十六進制字符 |
字符:
元字符 |
匹配內容 |
| . | 匹配除換行符以外的任意字符 |
| \w | 匹配字母或數字或下劃線 |
| \s | 匹配任意的空白符 |
| \d | 匹配數字 |
| \n | 匹配一個換行符 |
| \t | 匹配一個制表符 |
| \b | 匹配一個單詞的結尾 |
| ^ | 匹配字串的開始 |
| $ | 匹配字串的結尾 |
| \W |
匹配非字母或數字或下劃線 |
| \D |
匹配非數字
|
| \S |
匹配非空白符
|
| a|b |
匹配字符a或字符b |
| () |
匹配括號內的運算式,也表示一個組 |
| [...] |
匹配字符組中的字符 |
| [^...] |
匹配除了字符組中字符的所有字符 |
量詞:
量詞 |
用法說明 |
| * | 重復零次或更多次 |
| + | 重復一次或更多次 |
| ? | 重復零次或一次 |
| {n} | 重復n次 |
| {n,} | 重復n次或更多次 |
| {n,m} | 重復n到m次 |
. ^ $
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 海. | 海燕海嬌海東 | 海燕海嬌海東 | 匹配所有"海."的字符 |
| ^海. | 海燕海嬌海東 | 海燕 | 只從開頭匹配"海." |
| 海.$ | 海燕海嬌海東 | 海東 | 只匹配結尾的"海.$" |
* + ? { }
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李.? | 李杰和李蓮英和李二棍子 |
李杰 |
?表示重復零次或一次,即只匹配"李"后面一個任意字符 |
| 李.* | 李杰和李蓮英和李二棍子 | 李杰和李蓮英和李二棍子 |
*表示重復零次或多次,即匹配"李"后面0或多個任意字符 |
| 李.+ | 李杰和李蓮英和李二棍子 | 李杰和李蓮英和李二棍子 |
+表示重復一次或多次,即只匹配"李"后面1個或多個任意字符 |
| 李.{1,2} | 李杰和李蓮英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是貪婪匹配,也就是盡可能匹配,后面加?號使其變成惰性匹配
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李.*? | 李杰和李蓮英和李二棍子 | 李 李 李 |
惰性匹配 |
字符集[][^]
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李[杰蓮英二棍子]* | 李杰和李蓮英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰蓮英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李蓮英和李二棍子 |
李杰 |
表示匹配一個不是"和"的字符任意次 |
| [\d] | 456bdha3 |
4 |
表示匹配任意一個數字,匹配到4個結果 |
| [\d]+ | 456bdha3 |
456 |
表示匹配任意個數字,匹配到2個結果 |
分組 ()與 或 |[^]
身份證號碼是一個長度為15或18個字符的字串,如果是15位則全部???數字組成,首位不能為0;如果是18位,則前17位全部是數字,末位可能是數字或x,下面我們嘗試用正則來表示:
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一個正確的身份證號 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配這串數字,但這并不是一個正確的身份證號碼,它是一個16位的數字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
現在不會匹配錯誤的身份證號了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果沒有匹配上就匹配[1-9]\d{14}
|
轉義符 \
在正則運算式中,有很多有特殊意義的是元字符,比如\n和\s等,如果要在正則中匹配正常的"\n"而不是"換行符"就需要對"\"進行轉義,變成'\\',
在python中,無論是正則運算式,還是待匹配的內容,都是以字串的形式出現的,在字串中\也有特殊的含義,本身還需要轉義,所以如果匹配一次"\n",字串中要寫成'\\n',那么正則里就要寫成"\\\\n",這樣就太麻煩了,這個時候我們就用到了r'\n'這個概念,此時的正則是r'\\n'就可以了,
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| \n | \n | False |
因為在正則運算式中\是有特殊意義的字符,所以要匹配\n本身,用運算式\n無法匹配 |
| \\n | \n | True |
轉義\之后變成\\,即可匹配 |
| "\\\\n" | '\\n' | True |
如果在python中,字串中的'\'也需要轉義,所以每一個字串'\'又需要轉義一次 |
| r'\\n' | r'\n' | True |
在字串之前加r,讓整個字串不轉義 |
貪婪匹配
貪婪匹配:在滿足匹配時,匹配盡可能長的字串,默認情況下,采用貪婪匹配
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默認為貪婪匹配模式,會匹配盡量長的字串 |
| <.*?> | r'\d' |
<script> |
加上?為將貪婪匹配模式轉為非貪婪匹配模式,會匹配盡量短的字串 |
幾個常用的非貪婪匹配Pattern
*? 重復任意次,但盡可能少重復 +? 重復1次或更多次,但盡可能少重復 ?? 重復0次或1次,但盡可能少重復 {n,m}? 重復n到m次,但盡可能少重復 {n,}? 重復n次以上,但盡可能少重復
.*?的用法
. 是任意字符 * 是取 0 至 無限長度 ? 是非貪婪模式, 何在一起就是 取盡量少的任意字符,一般不會這么單獨寫,他大多用在: .*?x 就是取前面任意長度的字符,直到一個x出現
re模塊下的常用方法
import re ret = re.findall('a', 'eva egon yuan') # 回傳所有滿足匹配條件的結果,放在串列里 print(ret) #結果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #結果 : 'a' # 函式會在字串內查找模式匹配,只到找到第一個匹配然后回傳一個包含匹配資訊的物件,該物件可以 # 通過呼叫group()方法得到匹配的字串,如果字串沒有匹配,則回傳None, ret = re.match('a', 'abc').group() # 同search,不過盡在字串開始處進行匹配 print(ret) #結果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在對''和'bcd'分別按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#將數字替換成'H',引數1表示只替換1個 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#將數字替換成'H',回傳元組(替換的結果,替換了多少次) print(ret) obj = re.compile('\d{3}') #將正則運算式編譯成為一個 正則運算式物件,規則要匹配的是3個數字 ret = obj.search('abc123eeee') #正則運算式物件呼叫search,引數為待匹配的字串 print(ret.group()) #結果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer回傳一個存放匹配結果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一個結果 print(next(ret).group()) #查看第二個結果 print([i.group() for i in ret]) #查看剩余的左右結果
注意:
1 findall的優先級查詢:
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 這是因為findall會優先把匹配結果組里內容回傳,如果想要匹配結果,取消權限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
2 split的優先級查詢
ret=re.split("\d+","eva3egon4yuan") print(ret) #結果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #結果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的結果是不同的, #沒有()的沒有保留所匹配的項,但是有()的卻能夠保留了匹配的項, #這個在某些需要保留匹配部分的使用程序是非常重要的,
綜合練習與擴展
1、匹配標簽
import re ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") #還可以在分組中利用?<name>的形式給分組起名字 #獲取的匹配結果可以直接用group('名字')拿到對應的值 print(ret.group('tag_name')) #結果 :h1 print(ret.group()) #結果 :<h1>hello</h1> ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>") #如果不給組起名字,也可以用\序號來找到對應的組,表示要找的內容和前面的組內容一致 #獲取的匹配結果可以直接用group(序號)拿到對應的值 print(ret.group(1)) print(ret.group()) #結果 :<h1>hello</h1>
2、匹配整數
import re ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '2', '60', '40', '35', '5', '4', '3'] ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) #['1', '-2', '60', '', '5', '-4', '3'] ret.remove("") print(ret) #['1', '-2', '60', '5', '-4', '3']
3、數字匹配
1、 匹配一段文本中的每行的郵箱 http://blog.csdn.net/make164492212/article/details/51656638 2、 匹配一段文本中的每行的時間字串,比如:‘1990-07-12’; 分別取出1年的12個月(^(0?[1-9]|1[0-2])$)、 一個月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$ 3、 匹配qq號,(騰訊QQ號從10000開始) [1,9][0,9]{4,} 4、 匹配一個浮點數, ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d* 5、 匹配漢字, ^[\u4e00-\u9fa5]{0,}$ 6、 匹配出所有整數
4、爬蟲練習
import requests import re import json def getPage(url): response=requests.get(url) return response.text def parsePage(s): com=re.compile('<div >.*?<div >.*?<em .*?>(?P<id>\d+).*?<span >(?P<title>.*?)</span>' '.*?<span .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)評價</span>',re.S) ret=com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num response_html=getPage(url) ret=parsePage(response_html) print(ret) f=open("move_info7","a",encoding="utf8") for obj in ret: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") if __name__ == '__main__': count=0 for i in range(10): main(count) count+=25View Code
import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div >.*?<div >.*?<em .*?>(?P<id>\d+).*?<span >(?P<title>.*?)</span>' '.*?<span .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)評價</span>', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25簡化版
flags有很多可選值: re.I(IGNORECASE)忽略大小寫,括號內是完整的寫法 re.M(MULTILINE)多行模式,改變^和$的行為 re.S(DOTALL)點可以匹配任意字符,包括換行符 re.L(LOCALE)做本地化識別的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依賴于當前環境,不推薦使用 re.U(UNICODE) 使用\w \W \s \S \d \D使用取決于unicode定義的字符屬性,在python3中默認使用該flag re.X(VERBOSE)冗長模式,該模式下pattern字串可以是多行的,忽略空白字符,并可以添加注釋flags
hashlib模塊
演算法介紹
Python的hashlib提供了常見的摘要演算法,如MD5,SHA1等等,
什么是摘要演算法呢?摘要演算法又稱哈希演算法、散列演算法,它通過一個函式,把任意長度的資料轉換為一個長度固定的資料串(通常用16進制的字串表示),
摘要演算法就是通過摘要函式f()對任意長度的資料data計算出固定長度的摘要digest,目的是為了發現原始資料是否被人篡改過,
摘要演算法之所以能指出資料是否被篡改過,就是因為摘要函式是一個單向函式,計算f(data)很容易,但通過digest反推data卻非常困難,而且,對原始資料做一個bit的修改,都會導致計算出的摘要完全不同,
我們以常見的摘要演算法MD5為例,計算出一個字串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?') print md5.hexdigest() 計算結果如下: d26a53750bc40b38b65a520292f69306
如果資料量很大,可以分塊多次呼叫update(),最后計算的結果是一樣的:
md5 = hashlib.md5() md5.update('how to use md5 in ') md5.update('python hashlib?') print md5.hexdigest()
MD5是最常見的摘要演算法,速度很快,生成結果是固定的128 bit位元組,通常用一個32位的16進制字串表示,另一種常見的摘要演算法是SHA1,呼叫SHA1和呼叫MD5完全類似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in ') sha1.update('python hashlib?') print sha1.hexdigest()
SHA1的結果是160 bit位元組,通常用一個40位的16進制字串表示,比SHA1更安全的演算法是SHA256和SHA512,不過越安全的演算法越慢,而且摘要長度更長,
摘要演算法應用
任何允許用戶登錄的網站都會存盤用戶登錄的用戶名和口令,如何存盤用戶名和口令呢?方法是存到資料庫表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用戶口令,如果資料庫泄露,所有用戶的口令就落入黑客的手里,此外,網站運維人員是可以訪問資料庫的,也就是能獲取到所有用戶的口令,正確的保存口令的方式是不存盤用戶的明文口令,而是存盤用戶口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考慮這么個情況,很多用戶喜歡用123456,888888,password這些簡單的口令,于是,黑客可以事先計算出這些常用口令的MD5值,得到一個反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
這樣,無需破解,只需要對比資料庫的MD5,黑客就獲得了使用常用口令的用戶賬號,
對于用戶來講,當然不要使用過于簡單的口令,但是,我們能否在程式設計上對簡單口令加強保護呢?
由于常用口令的MD5值很容易被計算出來,所以,要確保存盤的用戶口令不是那些已經被計算出來的常用口令的MD5,這一方法通過對原始口令加一個復雜字串來實作,俗稱“加鹽”:
hashlib.md5("salt".encode("utf8"))
經過Salt處理的MD5口令,只要Salt不被黑客知道,即使用戶輸入簡單口令,也很難通過MD5反推明文口令,
但是如果有兩個用戶都使用了相同的簡單口令比如123456,在資料庫中,將存盤兩條相同的MD5值,這說明這兩個用戶的口令是一樣的,有沒有辦法讓使用相同口令的用戶存盤不同的MD5呢?
如果假定用戶無法修改登錄名,就可以通過把登錄名作為Salt的一部分來計算MD5,從而實作相同口令的用戶也存盤不同的MD5,
摘要演算法在很多地方都有廣泛的應用,要注意摘要演算法不是加密演算法,不能用于加密(因為無法通過摘要反推明文),只能用于防篡改,但是它的單向計算特性決定了可以在不存盤明文口令的情況下驗證用戶口令,
configparser模塊
該模塊適用于組態檔的格式與windows ini檔案類似,可以包含一個或多個節(section),每個節可以有多個引數(鍵=值),
創建檔案
來看一個好多軟體的常見檔案格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一個這樣的檔案怎么做呢?
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9', 'ForwardX11':'yes' } config['bitbucket.org'] = {'User':'hg'} config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} with open('example.ini', 'w') as configfile: config.write(configfile)
查找檔案
import configparser config = configparser.ConfigParser() #---------------------------查找檔案內容,基于字典的形式 print(config.sections()) # [] config.read('example.ini') print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] print('bytebong.com' in config) # False print('bitbucket.org' in config) # True print(config['bitbucket.org']["user"]) # hg print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no print(config['bitbucket.org']) #<Section: bitbucket.org> for key in config['bitbucket.org']: # 注意,有default會默認default的鍵 print(key) print(config.options('bitbucket.org')) # 同for回圈,找到'bitbucket.org'下所有鍵 print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有鍵值對 print(config.get('bitbucket.org','compression')) # yes get方法Section下的key對應的value
增刪改操作
import configparser config = configparser.ConfigParser() config.read('example.ini') config.add_section('yuan') config.remove_section('bitbucket.org') config.remove_option('topsecret.server.com',"forwardx11") config.set('topsecret.server.com','k1','11111') config.set('yuan','k2','22222') config.write(open('new2.ini', "w"))
logging模塊
函式式簡單配置
import logging logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
默認情況下Python的logging模塊將日志列印到了標準輸出中,且只顯示了大于等于WARNING級別的日志,這說明默認的日志級別設定為WARNING(日志級別等級CRITICAL > ERROR > WARNING > INFO > DEBUG),默認的日志格式為日志級別:Logger名稱:用戶輸出訊息,
靈活配置日志級別,日志格式,輸出位置:
import logging file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler,], level=logging.ERROR ) logging.error('你好')
日志切割
import time import logging from logging import handlers sh = logging.StreamHandler() rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5) fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8') logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[fh,sh,rh], level=logging.ERROR ) for i in range(1,100000): time.sleep(1) logging.error('KeyboardInterrupt error %s'%str(i))
配置引數:
logging.basicConfig()函式中可通過具體引數來更改logging模塊默認行為,可用引數有: filename:用指定的檔案名創建FiledHandler,這樣日志會被存盤在指定的檔案中, filemode:檔案打開方式,在指定了filename時使用這個引數,默認值為“a”還可指定為“w”, format:指定handler使用的日志顯示格式, datefmt:指定日期時間格式, level:設定rootlogger(后邊會講解具體概念)的日志級別 stream:用指定的stream創建StreamHandler,可以指定輸出到sys.stderr,sys.stdout或者檔案(f=open(‘test.log’,’w’)),默認為sys.stderr,若同時列出了filename和stream兩個引數,則stream引數會被忽略, format引數中可能用到的格式化串: %(name)s Logger的名字 %(levelno)s 數字形式的日志級別 %(levelname)s 文本形式的日志級別 %(pathname)s 呼叫日志輸出函式的模塊的完整路徑名,可能沒有 %(filename)s 呼叫日志輸出函式的模塊的檔案名 %(module)s 呼叫日志輸出函式的模塊名 %(funcName)s 呼叫日志輸出函式的函式名 %(lineno)d 呼叫日志輸出函式的陳述句所在的代碼行 %(created)f 當前時間,用UNIX標準的表示時間的浮 點數表示 %(relativeCreated)d 輸出日志資訊時的,自Logger創建以 來的毫秒數 %(asctime)s 字串形式的當前時間,默認格式是 “2003-07-08 16:49:45,896”,逗號后面的是毫秒 %(thread)d 執行緒ID,可能沒有 %(threadName)s 執行緒名,可能沒有 %(process)d 行程ID,可能沒有 %(message)s用戶輸出的訊息View Code
logger物件配置
import logging logger = logging.getLogger() # 創建一個handler,用于寫入日志檔案 fh = logging.FileHandler('test.log',encoding='utf-8')
# 再創建一個handler,用于輸出到控制臺
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger物件可以添加多個fh和ch物件
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
logging庫提供了多個組件:Logger、Handler、Filter、Formatter,Logger物件提供應用程式可直接使用的介面,Handler發送日志到適當的目的地,Filter提供了過濾日志資訊的方法,Formatter指定日志顯示格式,另外,可以通過:logger.setLevel(logging.Debug)設定級別,當然,也可以通過
fh.setLevel(logging.Debug)單對檔案流設定某個級別,
認識模塊
回傳頂部什么是模塊
什么是模塊?
常見的場景:一個模塊就是一個包含了python定義和宣告的檔案,檔案名就是模塊名字加上.py的后綴,
但其實import加載的模塊分為四個通用類別:
1 使用python撰寫的代碼(.py檔案)
2 已被編譯為共享庫或DLL的C或C++擴展
3 包好一組模塊的包
4 使用C撰寫并鏈接到python解釋器的內置模塊
為何要使用模塊?
如果你退出python解釋器然后重新進入,那么你之前定義的函式或者變數都將丟失,因此我們通常將程式寫到檔案中以便永久保存下來,需要時就通過python test.py方式去執行,此時test.py被稱為腳本script,
隨著程式的發展,功能越來越多,為了方便管理,我們通常將程式分成一個個的檔案,這樣做程式的結構更清晰,方便管理,這時我們不僅僅可以把這些檔案當做腳本去執行,還可以把他們當做模塊來匯入到其他的模塊中,實作了功能的重復利用,
回傳頂部
模塊的匯入和使用
模塊的匯入應該在程式開始的地方
更多相關內容 http://www.cnblogs.com/Eva-J/articles/7292109.html
常用模塊
回傳頂部
collections模塊
在內置資料型別(dict、list、set、tuple)的基礎上,collections模塊還提供了幾個額外的資料型別:Counter、deque、defaultdict、namedtuple和OrderedDict等,
1.namedtuple: 生成可以使用名字來訪問元素內容的tuple
2.deque: 雙端佇列,可以快速的從另外一側追加和推出物件
3.Counter: 計數器,主要用來計數
4.OrderedDict: 有序字典
5.defaultdict: 帶有默認值的字典
namedtuple
我們知道tuple可以表示不變集合,例如,一個點的二維坐標就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很難看出這個tuple是用來表示一個坐標的,
這時,namedtuple就派上了用場:

>>> from collections import namedtuple >>> Point = namedtuple('Point', ['x', 'y']) >>> p = Point(1, 2) >>> p.x 1 >>> p.y 2
類似的,如果要用坐標和半徑表示一個圓,也可以用namedtuple定義:
#namedtuple('名稱', [屬性list]): Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存盤資料時,按索引訪問元素很快,但是插入和洗掉元素就很慢了,因為list是線性存盤,資料量大的時候,插入和洗掉效率很低,
deque是為了高效實作插入和洗掉操作的雙向串列,適合用于佇列和堆疊:
>>> from collections import deque >>> q = deque(['a', 'b', 'c']) >>> q.append('x') >>> q.appendleft('y') >>> q deque(['y', 'a', 'b', 'c', 'x'])
deque除了實作list的append()和pop()外,還支持appendleft()和popleft(),這樣就可以非常高效地往頭部添加或洗掉元素,
OrderedDict
使用dict時,Key是無序的,在對dict做迭代時,我們無法確定Key的順序,
如果要保持Key的順序,可以用OrderedDict:
>>> from collections import OrderedDict >>> d = dict([('a', 1), ('b', 2), ('c', 3)]) >>> d # dict的Key是無序的 {'a': 1, 'c': 3, 'b': 2} >>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) >>> od # OrderedDict的Key是有序的 OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key會按照插入的順序排列,不是Key本身排序:
>>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的順序回傳 ['z', 'y', 'x']
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大于 66 的值保存至字典的第一個key中,將小于 66 的值保存至第二個key的值中,
即: {'k1': 大于66 , 'k2': 小于66}
原生字典解決方法
defaultdict字典解決方法
使用dict時,如果參考的Key不存在,就會拋出KeyError,如果希望key不存在時,回傳一個默認值,就可以用defaultdict:
例2
Counter
Counter類的目的是用來跟蹤值出現的次數,它是一個無序的容器型別,以字典的鍵值對形式存盤,其中元素作為key,其計數作為value,計數值可以是任意的Interger(包括0和負數),Counter類和其他語言的bags或multisets很相似,
c = Counter('abcdeabcdabcaba') print c 輸出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他詳細內容 http://www.cnblogs.com/Eva-J/articles/7291842.html
回傳頂部
時間模塊
和時間有關系的我們就要用到時間模塊,在使用模塊之前,應該首先匯入這個模塊,
#常用方法 1.time.sleep(secs) (執行緒)推遲指定的時間運行,單位為秒, 2.time.time() 獲取當前時間戳
表示時間的三種方式
在Python中,通常有這三種方式來表示時間:時間戳、元組(struct_time)、格式化的時間字串:
(1)時間戳(timestamp) :通常來說,時間戳表示的是從1970年1月1日00:00:00開始按秒計算的偏移量,我們運行“type(time.time())”,回傳的是float型別,
(2)格式化的時間字串(Format String): ‘1999-12-06’
python中時間日期格式化符號:
(3)元組(struct_time) :struct_time元組共有9個元素共九個元素:(年,月,日,時,分,秒,一年中第幾周,一年中第幾天等)
| 索引(Index) | 屬性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(時) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第幾天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令時) | 默認為0 |
首先,我們先匯入time模塊,來認識一下python中表示時間的幾種格式:
#匯入時間模塊 >>>import time #時間戳 >>>time.time() 1500875844.800804 #時間字串 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 13:54:37' >>>time.strftime("%Y-%m-%d %H-%M-%S") '2017-07-24 13-55-04' #時間元組:localtime將一個時間戳轉換為當前時區的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
小結:時間戳是計算機能夠識別的時間;時間字串是人能夠看懂的時間;元組則是用來操作時間的
幾種格式之間的轉換
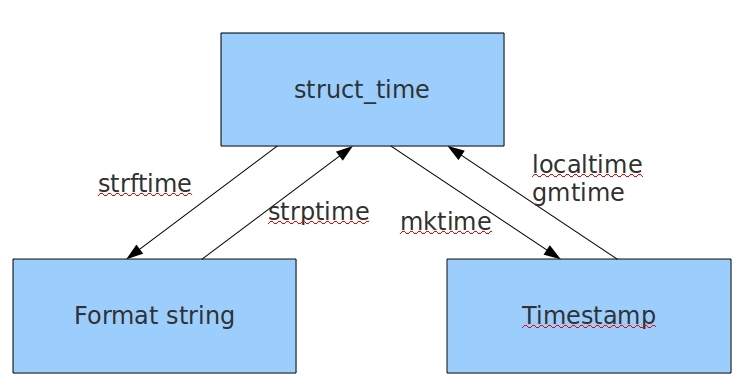
#時間戳-->結構化時間 #time.gmtime(時間戳) #UTC時間,與英國倫敦當地時間一致 #time.localtime(時間戳) #當地時間,例如我們現在在北京執行這個方法:與UTC時間相差8小時,UTC時間+8小時 = 北京時間 >>>time.gmtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) >>>time.localtime(1500000000) time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0) #結構化時間-->時間戳 #time.mktime(結構化時間) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#結構化時間-->字串時間 #time.strftime("格式定義","結構化時間") 結構化時間引數若不傳,則顯示當前時間 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14' #字串時間-->結構化時間 #time.strptime(時間字串,字串對應格式) >>>time.strptime("2017-03-16","%Y-%m-%d") time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1) >>>time.strptime("07/24/2017","%m/%d/%Y") time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=205, tm_isdst=-1)
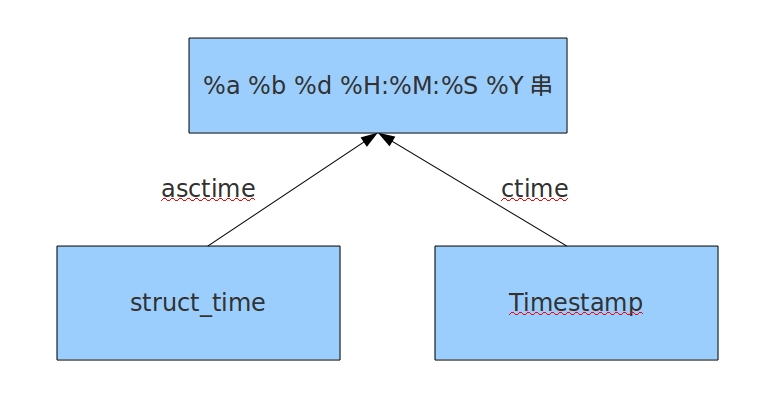
#結構化時間 --> %a %b %d %H:%M:%S %Y串 #time.asctime(結構化時間) 如果不傳引數,直接回傳當前時間的格式化串 >>>time.asctime(time.localtime(1500000000)) 'Fri Jul 14 10:40:00 2017' >>>time.asctime() 'Mon Jul 24 15:18:33 2017' #時間戳 --> %a %b %d %H:%M:%S %Y串 #time.ctime(時間戳) 如果不傳引數,直接回傳當前時間的格式化串 >>>time.ctime() 'Mon Jul 24 15:19:07 2017' >>>time.ctime(1500000000) 'Fri Jul 14 10:40:00 2017'
計算時間差
datetime模塊
1.datetime.now() # 獲取當前datetime
datetime.utcnow() # 獲取當前格林威治時間
View Code
2.datetime(2017, 5, 23, 12, 20) # 用指定日期時間創建datetime
from datetime import datetime #用指定日期創建 c=datetime(2017, 5, 23, 12, 20) print('指定日期:',c)
3.將以下字串轉換成datetime型別:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8時42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
時間字串格式化
4.將以下datetime型別轉換成字串:
2017年9月28日星期4,10時3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
時間字串格式化
5.用系統時間輸出以下字串:
今天是2017年9月30日
今天是這周的第?天
今天是今年的第?天
今周是今年的第?周
今天是當月的第?天
View Code
回傳頂部
random模塊
>>> import random #隨機小數 >>> random.random() # 大于0且小于1之間的小數 0.7664338663654585 >>> random.uniform(1,3) #大于1小于3的小數 1.6270147180533838
#恒富:發紅包 #隨機整數 >>> random.randint(1,5) # 大于等于1且小于等于5之間的整數 >>> random.randrange(1,10,2) # 大于等于1且小于10之間的奇數 #隨機選擇一個回傳 >>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5] #隨機選擇多個回傳,回傳的個數為函式的第二個引數 >>> random.sample([1,'23',[4,5]],2) # #串列元素任意2個組合 [[4, 5], '23'] #打亂串列順序 >>> item=[1,3,5,7,9] >>> random.shuffle(item) # 打亂次序 >>> item [5, 1, 3, 7, 9] >>> random.shuffle(item) >>> item [5, 9, 7, 1, 3]
練習:生成隨機驗證碼
生成驗證碼
回傳頂部
os模塊
os模塊是與作業系統互動的一個介面
os.makedirs('dirname1/dirname2') 可生成多層遞回目錄
os.removedirs('dirname1') 若目錄為空,則洗掉,并遞回到上一級目錄,如若也為空,則洗掉,依此類推
os.mkdir('dirname') 生成單級目錄;相當于shell中mkdir dirname
os.rmdir('dirname') 洗掉單級空目錄,若目錄不為空則無法洗掉,報錯;相當于shell中rmdir dirname
os.listdir('dirname') 列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,并以串列方式列印
os.remove() 洗掉一個檔案
os.rename("oldname","newname") 重命名檔案/目錄
os.stat('path/filename') 獲取檔案/目錄資訊
os.system("bash command") 運行shell命令,直接顯示
os.popen("bash command).read() 運行shell命令,獲取執行結果
os.getcwd() 獲取當前作業目錄,即當前python腳本作業的目錄路徑
os.chdir("dirname") 改變當前腳本作業目錄;相當于shell下cd
os.path
os.path.abspath(path) 回傳path規范化的絕對路徑
os.path.split(path) 將path分割成目錄和檔案名二元組回傳
os.path.dirname(path) 回傳path的目錄,其實就是os.path.split(path)的第一個元素
os.path.basename(path) 回傳path最后的檔案名,如何path以/或\結尾,那么就會回傳空值,即os.path.split(path)的第二個元素
os.path.exists(path) 如果path存在,回傳True;如果path不存在,回傳False
os.path.isabs(path) 如果path是絕對路徑,回傳True
os.path.isfile(path) 如果path是一個存在的檔案,回傳True,否則回傳False
os.path.isdir(path) 如果path是一個存在的目錄,則回傳True,否則回傳False
os.path.join(path1[, path2[, ...]]) 將多個路徑組合后回傳,第一個絕對路徑之前的引數將被忽略
os.path.getatime(path) 回傳path所指向的檔案或者目錄的最后訪問時間
os.path.getmtime(path) 回傳path所指向的檔案或者目錄的最后修改時間
os.path.getsize(path) 回傳path的大小
注意:os.stat('path/filename') 獲取檔案/目錄資訊 的結構說明
stat 結構
os模塊的屬性
回傳頂部
sys模塊
sys模塊是與python解釋器互動的一個介面
sys.argv 命令列引數List,第一個元素是程式本身路徑
sys.exit(n) 退出程式,正常退出時exit(0),錯誤退出sys.exit(1)
sys.version 獲取Python解釋程式的版本資訊
sys.path 回傳模塊的搜索路徑,初始化時使用PYTHONPATH環境變數的值
sys.platform 回傳作業系統平臺名稱
例外處理和status
回傳頂部
序列化模塊
什么叫序列化——將原本的字典、串列等內容轉換成一個字串的程序就叫做序列化,
為什么要有序列化模塊
序列化的目的
1、以某種存盤形式使自定義物件持久化; 2、將物件從一個地方傳遞到另一個地方, 3、使程式更具維護性,
json
Json模塊提供了四個功能:dumps、dump、loads、load
loads和dumps
load和dump
ensure_ascii關鍵字引數
其他引數說明
json的格式化輸出
pickle
json & pickle 模塊
用于序列化的兩個模塊
- json,用于字串 和 python資料型別間進行轉換
- pickle,用于python特有的型別 和 python的資料型別間進行轉換
pickle模塊提供了四個功能:dumps、dump(序列化,存)、loads(反序列化,讀)、load (不僅可以序列化字典,串列...可以把python中任意的資料型別序列化)
pickle
這時候機智的你又要說了,既然pickle如此強大,為什么還要學json呢?
這里我們要說明一下,json是一種所有的語言都可以識別的資料結構,
如果我們將一個字典或者序列化成了一個json存在檔案里,那么java代碼或者js代碼也可以拿來用,
但是如果我們用pickle進行序列化,其他語言就不能讀懂這是什么了~
所以,如果你序列化的內容是串列或者字典,我們非常推薦你使用json模塊
但如果出于某種原因你不得不序列化其他的資料型別,而未來你還會用python對這個資料進行反序列化的話,那么就可以使用pickle
re模塊
講正題之前我們先來看一個例子:https://reg.jd.com/reg/person?ReturnUrl=https%3A//www.jd.com/
這是京東的注冊頁面,打開頁面我們就看到這些要求輸入個人資訊的提示,
假如我們隨意的在手機號碼這一欄輸入一個11111111111,它會提示我們格式有誤,
這個功能是怎么實作的呢?
假如現在你用python寫一段代碼,類似:
phone_number = input('please input your phone number : ')
你怎么判斷這個phone_number是合法的呢?
根據手機號碼一共11位并且是只以13、14、15、18開頭的數字這些特點,我們用python寫了如下代碼:
判斷手機號碼是否合法1
這是你的寫法,現在我要展示一下我的寫法:
判斷手機號碼是否合法2
對比上面的兩種寫法,此時此刻,我要問你你喜歡哪種方法呀?你肯定還是會說第一種,為什么呢?因為第一種不用學呀!
但是如果現在有一個檔案,我讓你從整個檔案里匹配出所有的手機號碼,你用python給我寫個試試?
但是學了今天的技能之后,分分鐘幫你搞定!
今天我們要學習python里的re模塊和正則運算式,學會了這個就可以幫我們解決剛剛的疑問,正則運算式不僅在python領域,在整個編程屆都占有舉足輕重的地位,
正則運算式和re模塊
正則運算式本身也和python沒有什么關系,就是匹配字串內容的一種規則,
官方定義:正則運算式是對字串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規則字串”,這個“規則字串”用來表達對字串的一種過濾邏輯,
正則運算式
一說規則我已經知道你很暈了,現在就讓我們先來看一些實際的應用,在線測驗工具 http://tool.chinaz.com/regex/
首先你要知道的是,談到正則,就只和字串相關了,在我給你提供的工具中,你輸入的每一個字都是一個字串,
其次,如果在一個位置的一個值,不會出現什么變化,那么是不需要規則的,
比如你要用"1"去匹配"1",或者用"2"去匹配"2",直接就可以匹配上,這連python的字串操作都可以輕松做到,
那么在之后我們更多要考慮的是在同一個位置上可以出現的字符的范圍,
字符組
正則 |
待匹配字符 |
匹配 |
說明 |
[0123456789] |
8 |
True |
在一個字符組里列舉合法的所有字符,字符組里的任意一個字符 |
[0123456789] |
a |
False |
由于字符組中沒有"a"字符,所以不能匹配 |
[0-9] |
7 |
True |
也可以用-表示范圍,[0-9]就和[0123456789]是一個意思 |
[a-z] |
s |
True |
同樣的如果要匹配所有的小寫字母,直接用[a-z]就可以表示 |
[A-Z] |
B |
True |
[A-Z]就表示所有的大寫字母 |
[0-9a-fA-F] |
e |
True |
可以匹配數字,大小寫形式的a~f,用來驗證十六進制字符 |
字符:
元字符 |
匹配內容 |
| . | 匹配除換行符以外的任意字符 |
| \w | 匹配字母或數字或下劃線 |
| \s | 匹配任意的空白符 |
| \d | 匹配數字 |
| \n | 匹配一個換行符 |
| \t | 匹配一個制表符 |
| \b | 匹配一個單詞的結尾 |
| ^ | 匹配字串的開始 |
| $ | 匹配字串的結尾 |
| \W |
匹配非字母或數字或下劃線 |
| \D |
匹配非數字
|
| \S |
匹配非空白符
|
| a|b |
匹配字符a或字符b |
| () |
匹配括號內的運算式,也表示一個組 |
| [...] |
匹配字符組中的字符 |
| [^...] |
匹配除了字符組中字符的所有字符 |
量詞:
量詞 |
用法說明 |
| * | 重復零次或更多次 |
| + | 重復一次或更多次 |
| ? | 重復零次或一次 |
| {n} | 重復n次 |
| {n,} | 重復n次或更多次 |
| {n,m} | 重復n到m次 |
. ^ $
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 海. | 海燕海嬌海東 | 海燕海嬌海東 | 匹配所有"海."的字符 |
| ^海. | 海燕海嬌海東 | 海燕 | 只從開頭匹配"海." |
| 海.$ | 海燕海嬌海東 | 海東 | 只匹配結尾的"海.$" |
* + ? { }
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李.? | 李杰和李蓮英和李二棍子 |
李杰 |
?表示重復零次或一次,即只匹配"李"后面一個任意字符 |
| 李.* | 李杰和李蓮英和李二棍子 | 李杰和李蓮英和李二棍子 |
*表示重復零次或多次,即匹配"李"后面0或多個任意字符 |
| 李.+ | 李杰和李蓮英和李二棍子 | 李杰和李蓮英和李二棍子 |
+表示重復一次或多次,即只匹配"李"后面1個或多個任意字符 |
| 李.{1,2} | 李杰和李蓮英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
注意:前面的*,+,?等都是貪婪匹配,也就是盡可能匹配,后面加?號使其變成惰性匹配
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李.*? | 李杰和李蓮英和李二棍子 | 李 李 李 |
惰性匹配 |
字符集[][^]
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| 李[杰蓮英二棍子]* | 李杰和李蓮英和李二棍子 |
李杰 |
表示匹配"李"字后面[杰蓮英二棍子]的字符任意次 |
| 李[^和]* | 李杰和李蓮英和李二棍子 |
李杰 |
表示匹配一個不是"和"的字符任意次 |
| [\d] | 456bdha3 |
4 |
表示匹配任意一個數字,匹配到4個結果 |
| [\d]+ | 456bdha3 |
456 |
表示匹配任意個數字,匹配到2個結果 |
分組 ()與 或 |[^]
身份證號碼是一個長度為15或18個字符的字串,如果是15位則全部???數字組成,首位不能為0;如果是18位,則前17位全部是數字,末位可能是數字或x,下面我們嘗試用正則來表示:
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| ^[1-9]\d{13,16}[0-9x]$ | 110101198001017032 |
110101198001017032 |
表示可以匹配一個正確的身份證號 |
| ^[1-9]\d{13,16}[0-9x]$ | 1101011980010170 |
1101011980010170 |
表示也可以匹配這串數字,但這并不是一個正確的身份證號碼,它是一個16位的數字 |
| ^[1-9]\d{14}(\d{2}[0-9x])?$ | 1101011980010170 |
False |
現在不會匹配錯誤的身份證號了 |
| ^([1-9]\d{16}[0-9x]|[1-9]\d{14})$ | 110105199812067023 |
110105199812067023 |
表示先匹配[1-9]\d{16}[0-9x]如果沒有匹配上就匹配[1-9]\d{14}
|
轉義符 \
在正則運算式中,有很多有特殊意義的是元字符,比如\n和\s等,如果要在正則中匹配正常的"\n"而不是"換行符"就需要對"\"進行轉義,變成'\\',
在python中,無論是正則運算式,還是待匹配的內容,都是以字串的形式出現的,在字串中\也有特殊的含義,本身還需要轉義,所以如果匹配一次"\n",字串中要寫成'\\n',那么正則里就要寫成"\\\\n",這樣就太麻煩了,這個時候我們就用到了r'\n'這個概念,此時的正則是r'\\n'就可以了,
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| \n | \n | False |
因為在正則運算式中\是有特殊意義的字符,所以要匹配\n本身,用運算式\n無法匹配 |
| \\n | \n | True |
轉義\之后變成\\,即可匹配 |
| "\\\\n" | '\\n' | True |
如果在python中,字串中的'\'也需要轉義,所以每一個字串'\'又需要轉義一次 |
| r'\\n' | r'\n' | True |
在字串之前加r,讓整個字串不轉義 |
貪婪匹配
貪婪匹配:在滿足匹配時,匹配盡可能長的字串,默認情況下,采用貪婪匹配
| 正則 | 待匹配字符 | 匹配 結果 |
說明 |
| <.*> |
<script>...<script> |
<script>...<script> |
默認為貪婪匹配模式,會匹配盡量長的字串 |
| <.*?> | r'\d' |
<script> |
加上?為將貪婪匹配模式轉為非貪婪匹配模式,會匹配盡量短的字串 |
幾個常用的非貪婪匹配Pattern
*? 重復任意次,但盡可能少重復 +? 重復1次或更多次,但盡可能少重復 ?? 重復0次或1次,但盡可能少重復 {n,m}? 重復n到m次,但盡可能少重復 {n,}? 重復n次以上,但盡可能少重復
.*?的用法
. 是任意字符 * 是取 0 至 無限長度 ? 是非貪婪模式, 何在一起就是 取盡量少的任意字符,一般不會這么單獨寫,他大多用在: .*?x 就是取前面任意長度的字符,直到一個x出現
re模塊下的常用方法
import re ret = re.findall('a', 'eva egon yuan') # 回傳所有滿足匹配條件的結果,放在串列里 print(ret) #結果 : ['a', 'a'] ret = re.search('a', 'eva egon yuan').group() print(ret) #結果 : 'a' # 函式會在字串內查找模式匹配,只到找到第一個匹配然后回傳一個包含匹配資訊的物件,該物件可以 # 通過呼叫group()方法得到匹配的字串,如果字串沒有匹配,則回傳None, ret = re.match('a', 'abc').group() # 同search,不過盡在字串開始處進行匹配 print(ret) #結果 : 'a' ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在對''和'bcd'分別按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#將數字替換成'H',引數1表示只替換1個 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#將數字替換成'H',回傳元組(替換的結果,替換了多少次) print(ret) obj = re.compile('\d{3}') #將正則運算式編譯成為一個 正則運算式物件,規則要匹配的是3個數字 ret = obj.search('abc123eeee') #正則運算式物件呼叫search,引數為待匹配的字串 print(ret.group()) #結果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer回傳一個存放匹配結果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) #查看第一個結果 print(next(ret).group()) #查看第二個結果 print([i.group() for i in ret]) #查看剩余的左右結果
注意:
1 findall的優先級查詢:
import re ret = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['oldboy'] 這是因為findall會優先把匹配結果組里內容回傳,如果想要匹配結果,取消權限即可 ret = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') print(ret) # ['www.oldboy.com']
2 split的優先級查詢
ret=re.split("\d+","eva3egon4yuan") print(ret) #結果 : ['eva', 'egon', 'yuan'] ret=re.split("(\d+)","eva3egon4yuan") print(ret) #結果 : ['eva', '3', 'egon', '4', 'yuan'] #在匹配部分加上()之后所切出的結果是不同的, #沒有()的沒有保留所匹配的項,但是有()的卻能夠保留了匹配的項, #這個在某些需要保留匹配部分的使用程序是非常重要的,
綜合練習與擴展
1、匹配標簽
View Code
2、匹配整數
View Code
3、數字匹配
View Code
4、爬蟲練習
View Code
簡化版
flags
作業
實作能計算類似
1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等類似公式的計算器程式
在線測驗工具 http://tool.chinaz.com/regex/
常用模塊二
回傳頂部hashlib模塊
演算法介紹
Python的hashlib提供了常見的摘要演算法,如MD5,SHA1等等,
什么是摘要演算法呢?摘要演算法又稱哈希演算法、散列演算法,它通過一個函式,把任意長度的資料轉換為一個長度固定的資料串(通常用16進制的字串表示),
摘要演算法就是通過摘要函式f()對任意長度的資料data計算出固定長度的摘要digest,目的是為了發現原始資料是否被人篡改過,
摘要演算法之所以能指出資料是否被篡改過,就是因為摘要函式是一個單向函式,計算f(data)很容易,但通過digest反推data卻非常困難,而且,對原始資料做一個bit的修改,都會導致計算出的摘要完全不同,
我們以常見的摘要演算法MD5為例,計算出一個字串的MD5值:
import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?') print md5.hexdigest() 計算結果如下: d26a53750bc40b38b65a520292f69306
如果資料量很大,可以分塊多次呼叫update(),最后計算的結果是一樣的:
md5 = hashlib.md5() md5.update('how to use md5 in ') md5.update('python hashlib?') print md5.hexdigest()
MD5是最常見的摘要演算法,速度很快,生成結果是固定的128 bit位元組,通常用一個32位的16進制字串表示,另一種常見的摘要演算法是SHA1,呼叫SHA1和呼叫MD5完全類似:
import hashlib sha1 = hashlib.sha1() sha1.update('how to use sha1 in ') sha1.update('python hashlib?') print sha1.hexdigest()
SHA1的結果是160 bit位元組,通常用一個40位的16進制字串表示,比SHA1更安全的演算法是SHA256和SHA512,不過越安全的演算法越慢,而且摘要長度更長,
摘要演算法應用
任何允許用戶登錄的網站都會存盤用戶登錄的用戶名和口令,如何存盤用戶名和口令呢?方法是存到資料庫表中:
name | password --------+---------- michael | 123456 bob | abc999 alice | alice2008
如果以明文保存用戶口令,如果資料庫泄露,所有用戶的口令就落入黑客的手里,此外,網站運維人員是可以訪問資料庫的,也就是能獲取到所有用戶的口令,正確的保存口令的方式是不存盤用戶的明文口令,而是存盤用戶口令的摘要,比如MD5:
username | password ---------+--------------------------------- michael | e10adc3949ba59abbe56e057f20f883e bob | 878ef96e86145580c38c87f0410ad153 alice | 99b1c2188db85afee403b1536010c2c9
考慮這么個情況,很多用戶喜歡用123456,888888,password這些簡單的口令,于是,黑客可以事先計算出這些常用口令的MD5值,得到一個反推表:
'e10adc3949ba59abbe56e057f20f883e': '123456' '21218cca77804d2ba1922c33e0151105': '888888' '5f4dcc3b5aa765d61d8327deb882cf99': 'password'
這樣,無需破解,只需要對比資料庫的MD5,黑客就獲得了使用常用口令的用戶賬號,
對于用戶來講,當然不要使用過于簡單的口令,但是,我們能否在程式設計上對簡單口令加強保護呢?
由于常用口令的MD5值很容易被計算出來,所以,要確保存盤的用戶口令不是那些已經被計算出來的常用口令的MD5,這一方法通過對原始口令加一個復雜字串來實作,俗稱“加鹽”:
hashlib.md5("salt".encode("utf8"))
經過Salt處理的MD5口令,只要Salt不被黑客知道,即使用戶輸入簡單口令,也很難通過MD5反推明文口令,
但是如果有兩個用戶都使用了相同的簡單口令比如123456,在資料庫中,將存盤兩條相同的MD5值,這說明這兩個用戶的口令是一樣的,有沒有辦法讓使用相同口令的用戶存盤不同的MD5呢?
如果假定用戶無法修改登錄名,就可以通過把登錄名作為Salt的一部分來計算MD5,從而實作相同口令的用戶也存盤不同的MD5,
摘要演算法在很多地方都有廣泛的應用,要注意摘要演算法不是加密演算法,不能用于加密(因為無法通過摘要反推明文),只能用于防篡改,但是它的單向計算特性決定了可以在不存盤明文口令的情況下驗證用戶口令,
回傳頂部
configparser模塊
該模塊適用于組態檔的格式與windows ini檔案類似,可以包含一個或多個節(section),每個節可以有多個引數(鍵=值),
創建檔案
來看一個好多軟體的常見檔案格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
如果想用python生成一個這樣的檔案怎么做呢?
import configparser config = configparser.ConfigParser() config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9', 'ForwardX11':'yes' } config['bitbucket.org'] = {'User':'hg'} config['topsecret.server.com'] = {'Host Port':'50022','ForwardX11':'no'} with open('example.ini', 'w') as configfile: config.write(configfile)
查找檔案
import configparser config = configparser.ConfigParser() #---------------------------查找檔案內容,基于字典的形式 print(config.sections()) # [] config.read('example.ini') print(config.sections()) # ['bitbucket.org', 'topsecret.server.com'] print('bytebong.com' in config) # False print('bitbucket.org' in config) # True print(config['bitbucket.org']["user"]) # hg print(config['DEFAULT']['Compression']) #yes print(config['topsecret.server.com']['ForwardX11']) #no print(config['bitbucket.org']) #<Section: bitbucket.org> for key in config['bitbucket.org']: # 注意,有default會默認default的鍵 print(key) print(config.options('bitbucket.org')) # 同for回圈,找到'bitbucket.org'下所有鍵 print(config.items('bitbucket.org')) #找到'bitbucket.org'下所有鍵值對 print(config.get('bitbucket.org','compression')) # yes get方法Section下的key對應的value
增刪改操作
import configparser config = configparser.ConfigParser() config.read('example.ini') config.add_section('yuan') config.remove_section('bitbucket.org') config.remove_option('topsecret.server.com',"forwardx11") config.set('topsecret.server.com','k1','11111') config.set('yuan','k2','22222') config.write(open('new2.ini', "w"))
回傳頂部
logging模塊
函式式簡單配置
import logging logging.debug('debug message') logging.info('info message') logging.warning('warning message') logging.error('error message') logging.critical('critical message')
默認情況下Python的logging模塊將日志列印到了標準輸出中,且只顯示了大于等于WARNING級別的日志,這說明默認的日志級別設定為WARNING(日志級別等級CRITICAL > ERROR > WARNING > INFO > DEBUG),默認的日志格式為日志級別:Logger名稱:用戶輸出訊息,
靈活配置日志級別,日志格式,輸出位置:
import logging file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler,], level=logging.ERROR ) logging.error('你好')
日志切割
import time import logging from logging import handlers sh = logging.StreamHandler() rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5) fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8') logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[fh,sh,rh], level=logging.ERROR ) for i in range(1,100000): time.sleep(1) logging.error('KeyboardInterrupt error %s'%str(i))
配置引數:
View Code
logger物件配置
import logging logger = logging.getLogger() # 創建一個handler,用于寫入日志檔案 fh = logging.FileHandler('test.log',encoding='utf-8')
# 再創建一個handler,用于輸出到控制臺
ch = logging.StreamHandler()
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setLevel(logging.DEBUG)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
logger.addHandler(fh) #logger物件可以添加多個fh和ch物件
logger.addHandler(ch)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
logging庫提供了多個組件:Logger、Handler、Filter、Formatter,Logger物件提供應用程式可直接使用的介面,Handler發送日志到適當的目的地,Filter提供了過濾日志資訊的方法,Formatter指定日志顯示格式,另外,可以通過:logger.setLevel(logging.Debug)設定級別,當然,也可以通過
fh.setLevel(logging.Debug)單對檔案流設定某個級別,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/194772.html
標籤:Python
上一篇:Python_遞回函式
下一篇:Python_包