我們以微博樹洞為例,講解了怎么自動爬取單個微博的評論,今天我們就要用上這些資料做一個自殺傾向分類器,這樣的分類器如果應用得當,將可以幫助成千上萬誤入歧途的人們挽回生命,
為了簡化問題,我們將短文本分為兩種類別中的一種,即要么是正常微博、要么是自殺傾向微博,這樣,有了上次的微博樹洞,訓練集和測驗集就非常好獲得了,由于是短文本二分類問題,可以使用 scikit-learn 的 SVM 分類模型,
不過要注意的是,我們的分類器并不能保證分類出來的結果百分百正確,畢竟心理狀態是很難通過文本準確識別出來的,我們只能通過文字,大致判斷其抑郁情況并加以介入,實際上這是一個寧可錯殺一百,不可放過一個的問題,畢竟放過一個,可能就有一條生命悄然流逝,
本文源代碼: https://github.com/Ckend/suicide-detect-sv... 歡迎一同改進這個專案,在訓練集和模型方面,改進的空間還相當大,
PS:另外很多人在學習Python的程序中,往往因為遇問題解決不了或者沒好的教程從而導致自己放棄,為此我建了個Python全堆疊開發交流.裙 :一久武其而而流一思(數字的諧音)轉換下可以找到了,里面有最新Python教程專案可拿,不懂的問題有老司機解決哦,一起相互監督共同進步
1. 資料準備
資料集整體上分兩個部分,一部分是訓練集、一部分是測驗集,其中,訓練集和測驗集中還要分為正常微博短文本和自殺傾向短文本,
將上一篇爬取微博樹洞的文章中得到的資料進行人工篩選后,挑出 300 條作為訓練集(有點少,其實業界至少也要 3000 條以上),再根據上次的微博爬蟲隨意爬取 10000 條微博作為訓練集的正常微博類,另外再分別搜集自殺傾向微博和普通微博各 50 條作為測驗集,
每條微博按行存盤在 txt 檔案里,訓練集中,正常微博命名為 normal.txt, 自殺傾向微博命名為 die.txt,測驗集存放在后綴為_test.txt 的檔案中:

此外,接下來我們會使用到一個機器學習工具包叫 scikit-learn (sklearn),其打包好了許多機器學習模型和預處理的方法,方便我們構建分類器,在 CMD/Terminal 輸入以下命令安裝:
pip install -U scikit-learn
如果你還沒有安裝 Python,請看這篇文章安裝 Python,然后再執行上述命令安裝 sklearn.
2. 資料預處理
我們使用一個典型的中文自然語言預處理方法:對文本使用結巴分詞后將其數字化,
由于具有自殺傾向的微博中,其實類似于 "死"、"不想活"、"我走了" 等這樣的詞語比較常見,因此我們可以用 TF-IDF 將字串數字化,如果你不了解 TF-IDF,請看這篇文章: 文本處理之 tf-idf 演算法及其實踐
數字化的部分代碼如下,
print('(2) doc to var...')
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
# CountVectorizer考慮每種詞匯在該訓練文本中出現的頻率,得到計數矩陣
count_v0= CountVectorizer(analyzer='word',token_pattern='\w{1,}')
counts_all = count_v0.fit_transform(all_text)
count_v1= CountVectorizer(vocabulary=count_v0.vocabulary_)
counts_train = count_v1.fit_transform(train_texts)
print("the shape of train is "+repr(counts_train.shape) )
count_v2 = CountVectorizer(vocabulary=count_v0.vocabulary_)
counts_test = count_v2.fit_transform(test_texts)
print("the shape of test is "+repr(counts_test.shape) )
# 保存數字化后的詞典
joblib.dump(count_v0.vocabulary_, "model/die_svm_20191110_vocab.m")
counts_all = count_v2.fit_transform(all_text)
print("the shape of all is "+repr(counts_all.shape))
# 將計數矩陣轉換為規格化的tf-idf格式
tfidftransformer = TfidfTransformer()
train_data = tfidftransformer.fit(counts_train).transform(counts_train)
test_data = tfidftransformer.fit(counts_test).transform(counts_test)
all_data = tfidftransformer.fit(counts_all).transform(counts_all) 3. 訓練
使用 scikit-learn 的 SVM 分類模型,我們能很快滴訓練并構建出一個分類器:
print('(3) SVM...')
from sklearn.svm import SVC
# 使用線性核函式的SVM分類器,并啟用概率估計(分別顯示分到兩個類別的概率如:[0.12983359 0.87016641])
svclf = SVC(kernel = 'linear', probability=True)
# 開始訓練
svclf.fit(x_train,y_train)
# 保存模型
joblib.dump(svclf, "model/die_svm_20191110.m")這里我們忽略了 SVM 原理的講述,SVM 的原理可以參考這篇文章:支持向量機(SVM)—— 原理篇
4. 測驗
測驗的時候,我們要分別計算模型對兩個類別的分類精確率和召回率,scikit-learn 提供了一個非常好用的函式 classification_report 來計算它們:
# 測驗集進行測驗
preds = svclf.predict(x_test)
y_preds = svclf.predict_proba(x_test)
preds = preds.tolist()
for i,pred in enumerate(preds):
# 顯示被分錯的微博
if int(pred) != int(y_test[i]):
try:
print(origin_eval_text[i], ':', test_texts[i], pred, y_test[i], y_preds[i])
except Exception as e:
print(e)
# 分別查看兩個類別的準確率、召回率和F1值
print(classification_report(y_test, preds)) 結果:
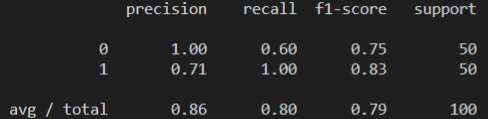
對自殺傾向微博的分類精確率為 100%,但是查全率不夠,它只找到了 50 條里的 60%,也就是 30 條自殺傾向微博,
對于正常微博的分類,其精確率為 71%,也就是說有部分正常微博被分類為自殺傾向微博,不過其查全率為 100%,也就是不存在不被分類的正常微博,
這是建立在訓練集還不夠多的情況下的結果,我們的自殺傾向微博的資料僅僅才 300 條,這是遠遠不夠的,如果能增加到 3000 條,相信結果會改進不少,尤其是對于自殺傾向微博的查全率有很大的幫助,預估最終該模型的精確率和召回率至少能達到 95%,
本次分享大家都明白了沒? 另外很多人在學習Python的程序中,往往因為遇問題解決不了從而導致自己放棄,為此我建了個Python全堆疊開發交流.裙 :一久武其而而流一思(數字的諧音)轉換下可以找到了,里面有最新Python教程專案可拿,不懂的問題有老司機解決哦,一起相互監督共同進步
本文的文字及圖片來源于網路加上自己的想法,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/195331.html
標籤:Python
下一篇:K折交叉驗證