“一切皆Socket!”
話雖些許夸張,但是事實也是,現在的網路編程幾乎都是用的socket,
——有感于實際編程和開源專案研究,
我們深諳資訊交流的價值,那網路中行程之間如何通信,如我們每天打開瀏覽器瀏覽網頁時,瀏覽器的行程怎么與web服務器通信的?當你用QQ聊天時,QQ行程怎么與服務器或你好友所在的QQ行程通信?這些都得靠socket?那什么是socket?socket的型別有哪些?還有socket的基本函式,這些都是本文想介紹的,本文的主要內容如下:
1、網路中行程之間如何通信?
2、Socket是什么?
3、socket的基本操作
3.1、socket()函式
3.2、bind()函式
3.3、listen()、connect()函式
3.4、accept()函式
3.5、read()、write()函式等
3.6、close()函式
4、socket中TCP的三次握手建立連接詳解
5、socket中TCP的四次握手釋放連接詳解
6、一個例子(實踐一下)
7、留下一個問題,歡迎大家回帖回答!!!
如果覺得文章對你有幫助,不妨給我點個關注
知乎:禿頂之路
b站:linux亦有歸途
每天都會更新我們的公開課錄播以及編程干貨和大廠面經
或者直接點擊鏈接
c/c++ linux服務器開發高級架構師
來課堂上跟我們講師面對面交流
需要大廠面經跟學習大綱的小伙伴可以加群973961276獲取
1、網路中行程之間如何通信?
本地的行程間通信(IPC)有很多種方式,但可以總結為下面4類:
訊息傳遞(管道、FIFO、訊息佇列)同步(互斥量、條件變數、讀寫鎖、檔案和寫記錄鎖、信號量)共享記憶體(匿名的和具名的)遠程程序呼叫(Solaris門和Sun RPC)
但這些都不是本文的主題!我們要討論的是網路中行程之間如何通信?首要解決的問題是如何唯一標識一個行程,否則通信無從談起!在本地可以通過行程PID來唯一標識一個行程,但是在網路中這是行不通的,其實TCP/IP協議族已經幫我們解決了這個問題,網路層的“ip地址”可以唯一標識網路中的主機,而傳輸層的“協議+埠”可以唯一標識主機中的應用程式(行程),這樣利用三元組(ip地址,協議,埠)就可以標識網路的行程了,網路中的行程通信就可以利用這個標志與其它行程進行互動,
使用TCP/IP協議的應用程式通常采用應用編程介面:UNIX BSD的套接字(socket)和UNIX System V的TLI(已經被淘汰),來實作網路行程之間的通信,就目前而言,幾乎所有的應用程式都是采用socket,而現在又是網路時代,網路中行程通信是無處不在,這就是我為什么說“一切皆socket”,
2、什么是Socket?
上面我們已經知道網路中的行程是通過socket來通信的,那什么是socket呢?socket起源于Unix,而Unix/Linux基本哲學之一就是“一切皆檔案”,都可以用“打開open –> 讀寫write/read –> 關閉close”模式來操作,我的理解就是Socket就是該模式的一個實作,socket即是一種特殊的檔案,一些socket函式就是對其進行的操作(讀/寫IO、打開、關閉),這些函式我們在后面進行介紹,
socket一詞的起源在組網領域的首次使用是在1970年2月12日發布的文獻IETF RFC33中發現的,撰寫者為Stephen Carr、Steve Crocker和Vint Cerf,根據美國計算機歷史博物館的記載,Croker寫道:“命名空間的元素都可稱為套接字介面,一個套接字介面構成一個連接的一端,而一個連接可完全由一對套接字介面規定,”計算機歷史博物館補充道:“這比BSD的套接字介面定義早了大約12年,”
3、socket的基本操作
既然socket是“open—write/read—close”模式的一種實作,那么socket就提供了這些操作對應的函式介面,下面以TCP為例,介紹幾個基本的socket介面函式,
3.1、socket()函式
int socket(int domain, int type, int protocol);
socket函式對應于普通檔案的打開操作,普通檔案的打開操作回傳一個檔案描述字,而socket()用于創建一個socket描述符(socket descriptor),它唯一標識一個socket,這個socket描述字跟檔案描述字一樣,后續的操作都有用到它,把它作為引數,通過它來進行一些讀寫操作,
正如可以給fopen的傳入不同引數值,以打開不同的檔案,創建socket的時候,也可以指定不同的引數創建不同的socket描述符,socket函式的三個引數分別為:
domain:即協議域,又稱為協議族(family),常用的協議族有,AF_INET、AF_INET6、AF_LOCAL(或稱AF_UNIX,Unix域socket)、AF_ROUTE等等,協議族決定了socket的地址型別,在通信中必須采用對應的地址,如AF_INET決定了要用ipv4地址(32位的)與埠號(16位的)的組合、AF_UNIX決定了要用一個絕對路徑名作為地址,type:指定socket型別,常用的socket型別有,SOCK_STREAM、SOCK_DGRAM、SOCK_RAW、SOCK_PACKET、SOCK_SEQPACKET等等(socket的型別有哪些?),protocol:故名思意,就是指定協議,常用的協議有,IPPROTO_TCP、IPPTOTO_UDP、IPPROTO_SCTP、IPPROTO_TIPC等,它們分別對應TCP傳輸協議、UDP傳輸協議、STCP傳輸協議、TIPC傳輸協議(這個協議我將會單獨開篇討論!),
注意:并不是上面的type和protocol可以隨意組合的,如SOCK_STREAM不可以跟IPPROTO_UDP組合,當protocol為0時,會自動選擇type型別對應的默認協議,
當我們呼叫socket創建一個socket時,回傳的socket描述字它存在于協議族(address family,AF_XXX)空間中,但沒有一個具體的地址,如果想要給它賦值一個地址,就必須呼叫bind()函式,否則就當呼叫connect()、listen()時系統會自動隨機分配一個埠,
3.2、bind()函式
正如上面所說bind()函式把一個地址族中的特定地址賦給socket,例如對應AF_INET、AF_INET6就是把一個ipv4或ipv6地址和埠號組合賦給socket,
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
函式的三個引數分別為:
sockfd:即socket描述字,它是通過socket()函式創建了,唯一標識一個socket,bind()函式就是將給這個描述字系結一個名字,addr:一個const struct sockaddr *指標,指向要系結給sockfd的協議地址,這個地址結構根據地址創建socket時的地址協議族的不同而不同,如ipv4對應的是:struct sockaddr_in { sa_family_t sin_family; /* address family: AF_INET */ in_port_t sin_port; /* port in network byte order */ struct in_addr sin_addr; /* internet address */ }; /* Internet address. */ struct in_addr { uint32_t s_addr; /* address in network byte order */ }; ipv6對應的是: struct sockaddr_in6 { sa_family_t sin6_family; /* AF_INET6 */ in_port_t sin6_port; /* port number */ uint32_t sin6_flowinfo; /* IPv6 flow information */ struct in6_addr sin6_addr; /* IPv6 address */ uint32_t sin6_scope_id; /* Scope ID (new in 2.4) */ }; struct in6_addr { unsigned char s6_addr[16]; /* IPv6 address */ }; Unix域對應的是: #define UNIX_PATH_MAX 108 struct sockaddr_un { sa_family_t sun_family; /* AF_UNIX */ char sun_path[UNIX_PATH_MAX]; /* pathname */ };
addrlen:對應的是地址的長度,
通常服務器在啟動的時候都會系結一個眾所周知的地址(如ip地址+埠號),用于提供服務,客戶就可以通過它來接連服務器;而客戶端就不用指定,有系統自動分配一個埠號和自身的ip地址組合,這就是為什么通常服務器端在listen之前會呼叫bind(),而客戶端就不會呼叫,而是在connect()時由系統隨機生成一個,
網路位元組序與主機位元組序主機位元組序就是我們平常說的大端和小端模式:不同的CPU有不同的位元組序型別,這些位元組序是指整數在記憶體中保存的順序,這個叫做主機序,參考標準的Big-Endian和Little-Endian的定義如下: a) Little-Endian就是低位位元組排放在記憶體的低地址端,高位位元組排放在記憶體的高地址端, b) Big-Endian就是高位位元組排放在記憶體的低地址端,低位位元組排放在記憶體的高地址端,網路位元組序:4個位元組的32 bit值以下面的次序傳輸:首先是0~7bit,其次8~15bit,然后16~23bit,最后是24~31bit,這種傳輸次序稱作大端位元組序,由于TCP/IP首部中所有的二進制整數在網路中傳輸時都要求以這種次序,因此它又稱作網路位元組序,位元組序,顧名思義位元組的順序,就是大于一個位元組型別的資料在記憶體中的存放順序,一個位元組的資料沒有順序的問題了,所以:在將一個地址系結到socket的時候,請先將主機位元組序轉換成為網路位元組序,而不要假定主機位元組序跟網路位元組序一樣使用的是Big-Endian,由于這個問題曾引發過血案!公司專案代碼中由于存在這個問題,導致了很多莫名其妙的問題,所以請謹記對主機位元組序不要做任何假定,務必將其轉化為網路位元組序再賦給socket,
3.3、listen()、connect()函式
如果作為一個服務器,在呼叫socket()、bind()之后就會呼叫listen()來監聽這個socket,如果客戶端這時呼叫connect()發出連接請求,服務器端就會接收到這個請求,
int listen(int sockfd, int backlog); int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
listen函式的第一個引數即為要監聽的socket描述字,第二個引數為相應socket可以排隊的最大連接個數,socket()函式創建的socket默認是一個主動型別的,listen函式將socket變為被動型別的,等待客戶的連接請求,
connect函式的第一個引數即為客戶端的socket描述字,第二引數為服務器的socket地址,第三個引數為socket地址的長度,客戶端通過呼叫connect函式來建立與TCP服務器的連接,
3.4、accept()函式
TCP服務器端依次呼叫socket()、bind()、listen()之后,就會監聽指定的socket地址了,TCP客戶端依次呼叫socket()、connect()之后就想TCP服務器發送了一個連接請求,TCP服務器監聽到這個請求之后,就會呼叫accept()函式取接收請求,這樣連接就建立好了,之后就可以開始網路I/O操作了,即類同于普通檔案的讀寫I/O操作,
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
accept函式的第一個引數為服務器的socket描述字,第二個引數為指向struct sockaddr *的指標,用于回傳客戶端的協議地址,第三個引數為協議地址的長度,如果accpet成功,那么其回傳值是由內核自動生成的一個全新的描述字,代表與回傳客戶的TCP連接,
注意:accept的第一個引數為服務器的socket描述字,是服務器開始呼叫socket()函式生成的,稱為監聽socket描述字;而accept函式回傳的是已連接的socket描述字,一個服務器通常通常僅僅只創建一個監聽socket描述字,它在該服務器的生命周期內一直存在,內核為每個由服務器行程接受的客戶連接創建了一個已連接socket描述字,當服務器完成了對某個客戶的服務,相應的已連接socket描述字就被關閉,
3.5、read()、write()等函式
萬事具備只欠東風,至此服務器與客戶已經建立好連接了,可以呼叫網路I/O進行讀寫操作了,即實作了網咯中不同行程之間的通信!網路I/O操作有下面幾組:
read()/write()recv()/send()readv()/writev()recvmsg()/sendmsg()recvfrom()/sendto()
我推薦使用recvmsg()/sendmsg()函式,這兩個函式是最通用的I/O函式,實際上可以把上面的其它函式都替換成這兩個函式,它們的宣告如下:

read函式是負責從fd中讀取內容.當讀成功時,read回傳實際所讀的位元組數,如果回傳的值是0表示已經讀到檔案的結束了,小于0表示出現了錯誤,如果錯誤為EINTR說明讀是由中斷引起的,如果是ECONNREST表示網路連接出了問題,
write函式將buf中的nbytes位元組內容寫入檔案描述符fd.成功時回傳寫的位元組數,失敗時回傳-1,并設定errno變數, 在網路程式中,當我們向套接字檔案描述符寫時有倆種可能,1)write的回傳值大于0,表示寫了部分或者是全部的資料,2)回傳的值小于0,此時出現了錯誤,我們要根據錯誤型別來處理,如果錯誤為EINTR表示在寫的時候出現了中斷錯誤,如果為EPIPE表示網路連接出現了問題(對方已經關閉了連接),
其它的我就不一一介紹這幾對I/O函式了,具體參見man檔案或者baidu、Google,下面的例子中將使用到send/recv,
3.6、close()函式
在服務器與客戶端建立連接之后,會進行一些讀寫操作,完成了讀寫操作就要關閉相應的socket描述字,好比操作完打開的檔案要呼叫fclose關閉打開的檔案,
#include <unistd.h> int close(int fd);
close一個TCP socket的預設行為時把該socket標記為以關閉,然后立即回傳到呼叫行程,該描述字不能再由呼叫行程使用,也就是說不能再作為read或write的第一個引數,
注意:close操作只是使相應socket描述字的參考計數-1,只有當參考計數為0的時候,才會觸發TCP客戶端向服務器發送終止連接請求,
4、socket中TCP的三次握手建立連接詳解
我們知道tcp建立連接要進行“三次握手”,即交換三個分組,大致流程如下:
客戶端向服務器發送一個SYN J服務器向客戶端回應一個SYN K,并對SYN J進行確認ACK J+1客戶端再想服務器發一個確認ACK K+1
只有就完了三次握手,但是這個三次握手發生在socket的那幾個函式中呢?請看下圖:
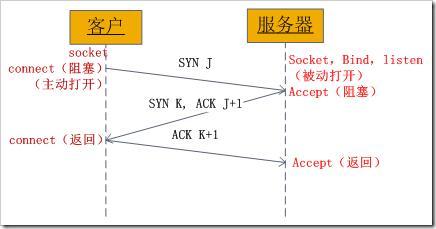
圖1、socket中發送的TCP三次握手
從圖中可以看出,當客戶端呼叫connect時,觸發了連接請求,向服務器發送了SYN J包,這時connect進入阻塞狀態;服務器監聽到連接請求,即收到SYN J包,呼叫accept函式接收請求向客戶端發送SYN K ,ACK J+1,這時accept進入阻塞狀態;客戶端收到服務器的SYN K ,ACK J+1之后,這時connect回傳,并對SYN K進行確認;服務器收到ACK K+1時,accept回傳,至此三次握手完畢,連接建立,
總結:客戶端的connect在三次握手的第二個次回傳,而服務器端的accept在三次握手的第三次回傳,
5、socket中TCP的四次握手釋放連接詳解
上面介紹了socket中TCP的三次握手建立程序,及其涉及的socket函式,現在我們介紹socket中的四次握手釋放連接的程序,請看下圖:
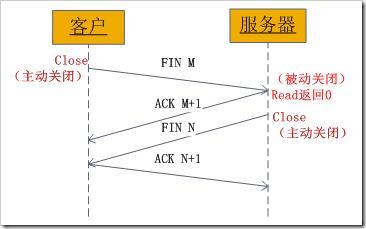
圖2、socket中發送的TCP四次握手
圖示程序如下:
某個應用行程首先呼叫close主動關閉連接,這時TCP發送一個FIN M;另一端接收到FIN M之后,執行被動關閉,對這個FIN進行確認,它的接收也作為檔案結束符傳遞給應用行程,因為FIN的接收意味著應用行程在相應的連接上再也接收不到額外資料;一段時間之后,接收到檔案結束符的應用行程呼叫close關閉它的socket,這導致它的TCP也發送一個FIN N;接收到這個FIN的源發送端TCP對它進行確認,
這樣每個方向上都有一個FIN和ACK,
6、一個例子(實踐一下)
說了這么多了,動手實踐一下,下面撰寫一個簡單的服務器、客戶端(使用TCP)——服務器端一直監聽本機的6666號埠,如果收到連接請求,將接收請求并接收客戶端發來的訊息;客戶端與服務器端建立連接并發送一條訊息,
服務器端代碼:
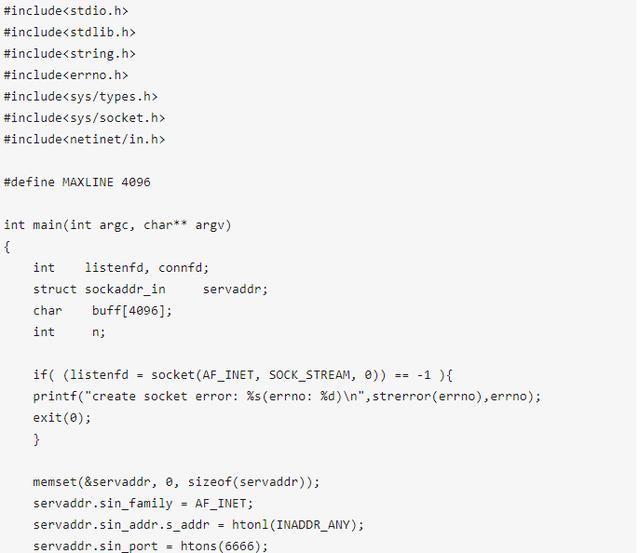

服務器端
客戶端代碼:


客戶端
當然上面的代碼很簡單,也有很多缺點,這就只是簡單的演示socket的基本函式使用,其實不管有多復雜的網路程式,都使用的這些基本函式,上面的服務器使用的是迭代模式的,即只有處理完一個客戶端請求才會去處理下一個客戶端的請求,這樣的服務器處理能力是很弱的,現實中的服務器都需要有并發處理能力!為了需要并發處理,服務器需要fork()一個新的行程或者執行緒去處理請求等,
7、動動手
留下一個問題,歡迎大家回帖回答!!!是否熟悉Linux下網路編程?如熟悉,撰寫如下程式完成如下功能:
服務器端:
接收地址192.168.100.2的客戶端資訊,如資訊為“Client Query”,則列印“Receive Query”
客戶端:
向地址192.168.100.168的服務器端順序發送資訊“Client Query test”,“Cleint Query”,“Client Query Quit”,然后退出,
題目中出現的ip地址可以根據實際情況定,
——本文只是介紹了簡單的socket編程,
更為復雜的需要自己繼續深入,
(unix domain socket)使用udp發送>=128K的訊息會報ENOBUFS的錯誤(一個實際socket編程中遇到的問題,希望對你有幫助)
都看到這里了,不妨關注我,后續會持續更新編程相關學習經驗,希望對大家能有所幫助
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/195753.html
標籤:python