本篇博客將闡述、討論的內容:
●int
int的范圍根據計算機的不同存在16位或32位的差異,以16位舉例,最大值為1111 1111 1111 1111,也就是65535,如果出現65536,就會溢位,
●unsigned int(無符號整型)
以16位系統為例,unsigned int能存盤的資料范圍是0~65535(需要注意整數是以補碼形式存放),其進行的是模數計算,也就是所謂的二進制相加減,計算方法和十進制加減并無區別,但是unsigned int有著正溢位和負溢位的問題,
對于正溢位與負溢位,諸多基礎概念便不再贅述,不懂的朋友可以去回顧計算機組成原理的相關知識,
這里僅舉出一個負溢位的例子:

進行自然丟棄后,可知結果為0,很明顯,產生了負溢位,
●接下來,我們說說unsigned int和int的相互轉化,代碼如下:
float sum_elements(float a[],unsigend length){
float result = 0;
for(int i = 0; i <= length - 1; i++){
result += a[i];
return result;
}
}
很顯然,計算一個陣列所有元素之和,但當陣列為空時,length輸入0,會回傳一個存盤器錯誤,為什么呢?請看unsigned int的計算,length是unsigned int 型別,進行的是模數運算,只代表正數,如果出先了0000000(這里有32個0)-00000..01(31個0,1個1)=111…11111(32個1)=UMAX,一個本該為-1的數變成了無符號數最大值,當i取任何不為0的數都發生了非法訪問,自然出現了存盤器錯誤,并且任何數都小于UMAX,出現判別式永遠為真,進入死回圈,解決辦法有兩種,做一個判斷,當傳入length<1,直接回傳0 or 在之前就將length轉化為int,
●浮點數
●定點數以及定點數的缺點
用10進制表示小數早已司空見慣,那么就會想要對二進制做同樣的操作,為它也加上小數點,
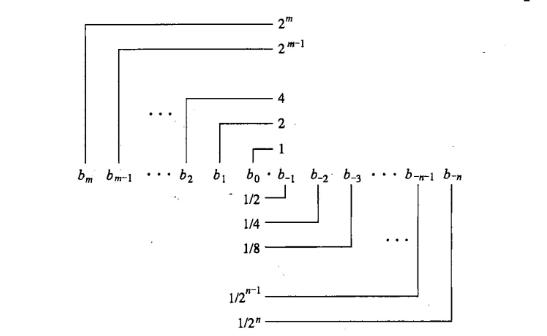
但是如此的二進制小數,會出現一些問題不可避免
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?| 整數部分 | 小數部分 | 二進制(Representation) |
|---|---|---|
| 5 | 3/4 | $101.11_2 $ |
| 2 | 7/8 | $10.111_2$ |
| 1 | 7/16 | $1.0111_2$ |
很明顯可以發現,只能準確的表示 \(x/2^k\) 的小數,而不為 \(x/2^k\) 只能近似,
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?| 十進制小數部分 | 二進制(Representation) |
|---|---|
| 1/3 | $0.01010101[01]… _2$ |
| 1/5 | $0.001100110011[0011]… _2$ |
| 1/10 | $0.0001100110011[0011]… _2$ |
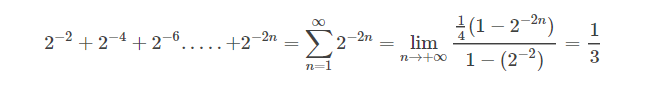
由此可見,當小數無法描述\(x/2^k\)時,二進制小數便只能取近似值(多采用close to even(靠近偶數)),
這就暴露定點數的一個重要缺點 ---- 定點數無法標準化,也就是說,關于小數點的位置無法給出一個標準的定點數計算方式,不同小數點的位置給計算定點數增加了難度,與此同時,定點數表示的范圍有限,32位的定點數,假設沒有整數位,那么所能表示的小數的最小值為:2-32,而32位浮點數僅指數位便可以表示到2-126,由此不難看出,定點數雖然精度高,但標準化和范圍大小都比較差,
所以此時便引出了浮點數來統一二進制小數的表示:
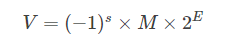
注:s:表示符號位,只用一個bit表示
M:表示尾數(significand)(frac)也表示小數位,即能準確表示小數位
E:表示指數位,
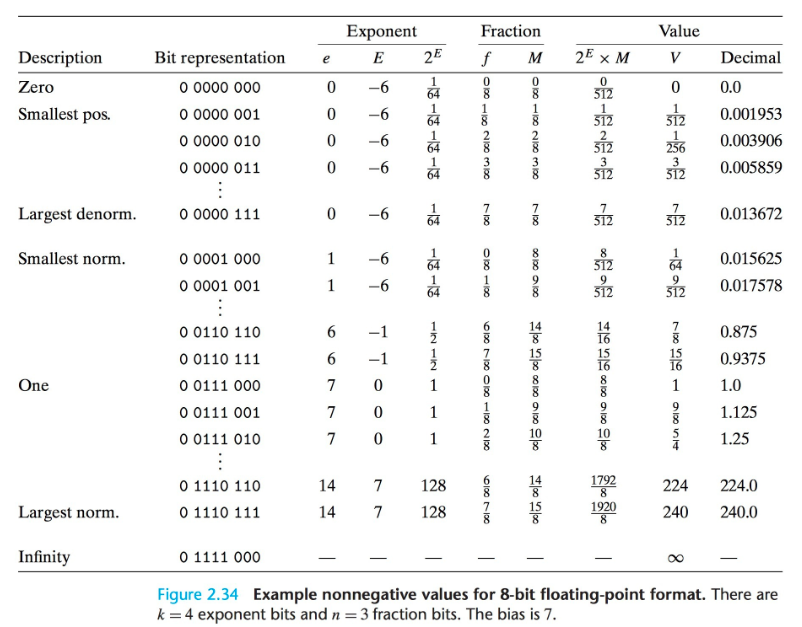
常用的float,double組成:

可以看出float有8位指數位,23位尾數位,指數最大可表示的范圍為-127~126
浮點數所表示的一個范圍:
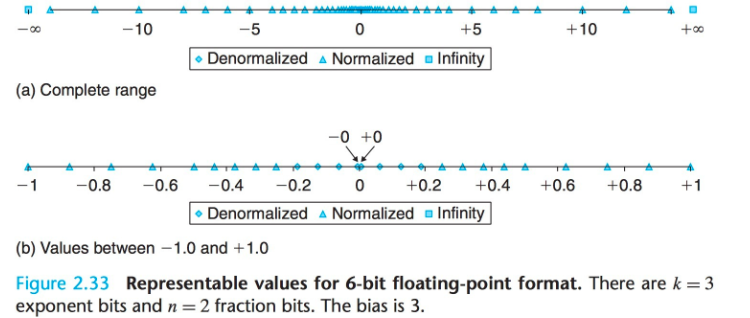
可以得到,浮點數隨著大小的不同被分為不同種類,接近0的稱為Denormalized,較大的數字被分為Infinity,(關于Denormalized、Infinity等名詞請自行了解,這里不再做過多的贅述),
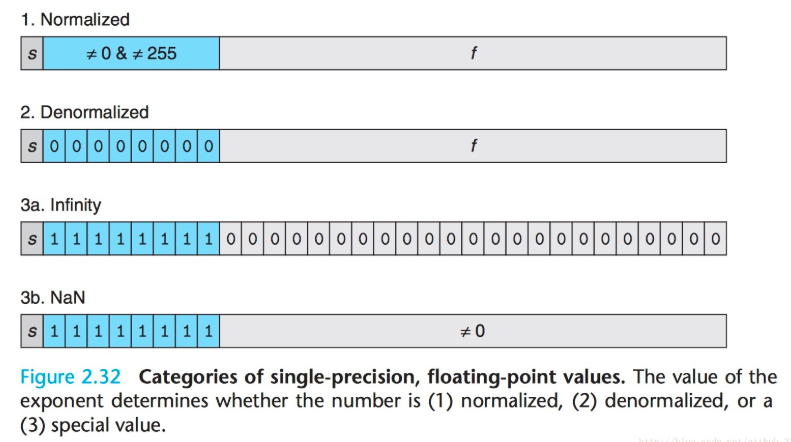
Denormalized到NaN的變化:
浮點數相加的公式:
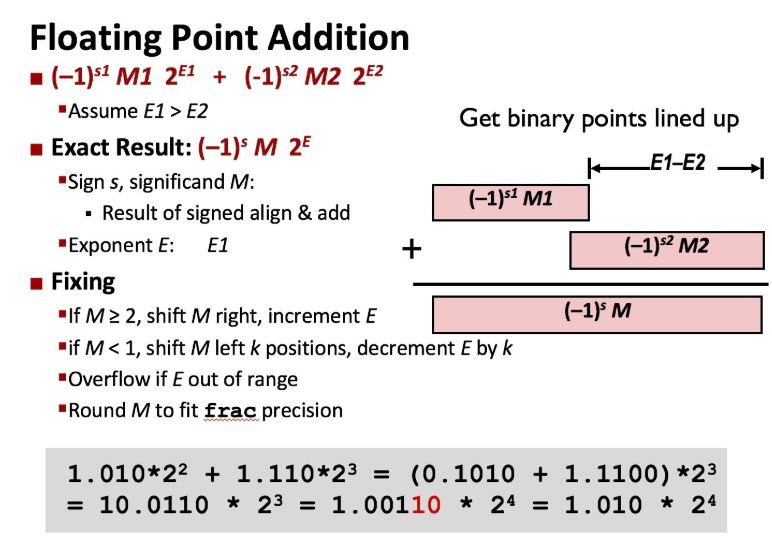
浮點數的加法和乘法由于近似的原因,經常無法實作加法的結合律和乘法分配律,如下所示:
(3.14+le10)-1e10=0.0,因為3.14+1e10會舍入,3.14會丟失(1e10表示1*101010)
然而3.14+(1e10-1e10)=3.14
le20*(le20-le20)=0.0
le20le20-le20le20=NaN,由于溢位的關系,可見在數字大的情況下不滿足加法結合律和乘法分配律,
最后,關于int,float,double之間相互轉換可能的問題:
當在int,float以及double格式之間進行強制轉換時,程式改變數值和位模式的原則如下(假設int為32位):
●從int轉換成float,數字不會溢位,但可能被舍入,
●從int或float轉換成double,因為double有更大的范圍(也就是可表示值得范圍),也有更高得精度(即有效位數),所以能保留精確得數值,
●從double轉換成float,因為范圍要小一些,所以值可嫩溢位為+∞或-∞,且由于精度較小,它還可能被舍入,
●從float或double轉換成int,值將會向0舍入,例如1.999將轉換為1,進一步說,值可能會溢位,C語言標準沒有對這種情況指定固定的結果,而與Inter兼容的微處理器指定位模式[10…00](字長為ω時的TMinω)為整數不確定值,一個從浮點數到整數的轉換,如果不能為該浮點數找到一個合理的整數近似值,就會產生一個這樣的值,因此,運算式(int)+le10會得到-21483648,即從一個正值變成了一個負值,
參考博主:寫代碼的柯長(CSDN)、Jamesjiang2050(博客園)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/195894.html
標籤:C++
上一篇:母嬰,愛情,生活,職場綜合笑話