hi各位大佬好,我是菜鳥小明哥(其實我也是大佬,哈哈,都是大佬),
SRGNN已經初步完成實際應用,效果還好,有用的參考來這里,據說原paper大佬已經更新換代了GNN,也就是TAGNN,望文生義就是“他的GNN”,我啥時候發個“WOGNN”,也就是“我的GNN”,hehe,本文依舊粉絲可見,年底回饋粉絲福利,(不喜歡我翻譯的就別看,看過了又瞎BB,你是閑的蛋疼嗎?),代碼在此,paper在此,
真正意義上的序列推薦,SRGNN算上一個,從序列到序列,無需考慮用戶的id,當然要記住是哪個用戶的點擊序列,不然怎么給他推(infer階段),
For Video Recommendation in Deep learning QQ Group 277356808
視頻推薦深度學習加這個群
For Visual in deep learning QQ Group 629530787
視覺深度學習加這個,別加錯
I'm here waiting for you
別加那么多,沒必要,另外,不接受這個網頁的私聊/私信!!!
1-拋出問題,提出解決方案
基于會話的推薦應用很廣,但他們的那些方法將會話壓縮為一個固定的向量表達,而沒有考慮預測的目標item,這種固定的向量將會限制推薦模型的能力,也就是目標item的多樣性和用戶的興趣,因此提出目標注意力圖模型用于會話推薦,在TAGNN中,目標意識的注意力自適應激活不同用戶的興趣,關于多樣的目標item,學習到的興趣向量表達隨不同的目標item變化,極大第提升了模型的表現能力,此外,TAGNN利用gnn的能力在會話中捕獲豐富的item轉換(transition),試驗證實方法有效,
2-問題定義和推導會話圖
在會話推薦中,匿名的會話可以表示為一個時間順序的串列,定義
作為所有用戶點擊的item集合,對于給定會話s,會話推薦的目的就是預測下個行為.模型產生一個所有item的概率有序串列,最后top-k用做推薦,
在模型中將每個會話直接表示為會話圖,其中的三個引數分別定義為節點集合,邊集合,鄰接矩陣,在圖中每個節點代表一個item,
,每個邊代表用戶訪問item的連續性,比如
表示用戶先訪問前者,后訪問后者,【i可視為時間上的概念,注意,作者用v表示item】,定義As為兩個鄰接矩陣
,
的拼接,表示會話中item之間的兩個方向的關系,兩個鄰接矩陣分別表示出邊和入邊連接的權重,
概圖如下:
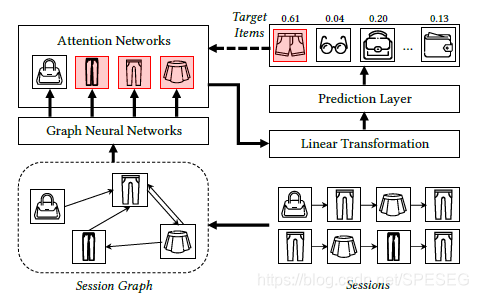
【再次注釋:會話就是用戶在一段時間內的點擊序列,如圖中就是兩個用戶的額點擊序列,會話中item之間的連接關系構成會話圖,經過gnn網路及注意力(何謂注意力?此處明顯可以望文生義得到,邊連接越多的item重點關注,大眾看的東西可能和你看的東西是相同的,這種情況會不會推出來的全是熱點部分(馬太/長尾啥的)?關于是否是熱點及小的debias方法,可以查看我之前的博文:1如何評價這種偏;2debias即gnn中的做法)處理后再經過線性轉換到預測層softmax,其中Target item虛線表示正反向傳播,即預測結果與實際結果對比,是一個學習程序】
3-學習item Embedding
將每個節點轉換到統一的embedding空間,最終得到每個item的d維度向量表示,這樣就可以用item的embedding表示每個會話s,gnn產生節點表示能夠將圖拓撲做得很好,這樣模型能夠擬合復雜item連接,paper采用ggnn(門圖網路)學習節點表示,網路更新規則:
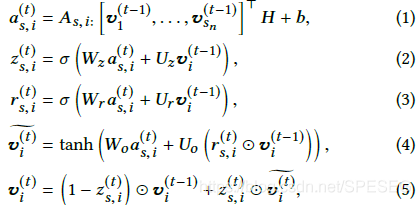
其中t是訓練步,是矩陣As第i行,H和b分別是權重和偏置,
是會話中節點向量的list,z和r分別是重置和更新門,
是sigmoid函式,
表示每個元素的點乘,
對于每個會話圖,ggnn模型在鄰節點之間傳遞資訊,更新門和重置門決定什么資訊保留,什么去掉,【說到這里,一個常見的面試題來了,LSTM是啥玩意,GRU是啥子,和經典的RNN有啥子區別,和CNN啥區別,哪里好了,哪里不好?既是送分題,又是送命題】
4-構建目標意識embedding【直譯的,target目標,aware意識】
之前的作業捕獲用戶的興趣僅僅使用會話間item表達,在我們模型中,一旦得到每個item的節點向量,經進行構建目標embedding,自適應的考慮歷史行為中關注的目標item的相關性,定義目標item為所有的候選item去預測,通常,用戶的行為,推薦的item只能匹配用戶一部分的興趣【也就是EE的問題了,參考我之前的知憾訓答】為了擬合這個程序,設計一個新的目標注意力機制計算軟注意力分數(在會話中所有的item上關于每個目標item),
首先引入區域目標注意力模塊計算會話s中所有item的注意力分數,一個非線性轉換通過一個權重W引數話,W用于每個節點-目標對,采用softmax對self-attention分數norm
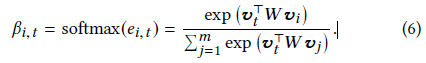
最終對每個會話s,用戶的興趣到目標item 可以表示為
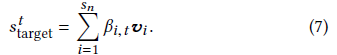
獲得的目標embedding表示用戶的興趣隨不同的目標item變化,
5- 生成會話embedding
在當前會話s中探索用戶的短長期喜好,使用s中的節點表示,兩個與用戶目標embedding一起的表達將會用于拼接產生更好的會話embedding,
區域embedding:用戶最終的行為可以視為短期喜好——作為一個區域embedding
全域embedding:表示用戶的長期喜好——全域的embedding,通過聚合所有涉及到的節點向量得到,采用另一個軟注意力機制描述最終點擊的item和s中每個涉及到的item之間的依賴關系:
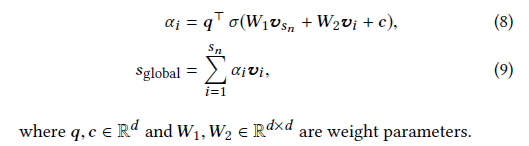
會話embedding:通過線性轉換將目標embedding,區域embedding,全域embedding得到會話的embedding,對于每個目標item都會有不同的會話embedding
![]()
6-做推薦
得到所有item的embedding和會話的embedding后,通過item embedding和會話embedding內積計算得到每個目標item的推薦分數,接下來,使用softmax得到最終的輸出概率:

【WOC,y定義為s中的下一個行為,應該是多少個點擊序列就有多少個吧,不然咋給每個用戶推薦啊,別告訴我,這個會話內的用戶推的都一樣,,,,,,,,,,】
交叉熵損失函式:
![]()
7-試驗設定
【今天看了優酷的新版本,WOC,竟然有了推薦功能,看起來也不錯,我就點了幾個,似乎很厲害啊,我就看了一個泰劇短片,然后我就搜了下這個名字,也有正片,這種推薦不錯,有沒有個性化我不知道,是在《精選》頁面的】
為了公平對比,去掉了頻次小于5的item,去掉了item少于2的session,為生成訓練集和測驗集,最后一天/一周的會話作為測驗,對于一個會話,可以生成一系列輸入和標簽,例如:一個會話,可以分為
串列后面的是label
對比方法有很多,包括item-knn,BPR,MF,NARM等等,當然肯定還有SRGNN
評價指標為P和MRR topk20
超引數設定,embedding維度為100,LR為0.001,衰減因子為0.1(每三次訓練),batch_size為100(是不是有點小啊),L2懲罰項為1e-5,優化器為Adam
8-消融研究(Ablation Studies)
【這個破玩意單詞不要以為多么復雜,它就是個初中物理中學的控制變數法,我至今還記得物理老師說,小車從斜坡上下滑,,,,,,,,一切高大上都不復雜,除非提出這個研究的人自己都解釋不清楚,能將自己研究的東西言簡意賅的講出來,這才是真正的懂了,做到這點,面試不會太差】
設計4個模型變體觀察模型效果,分別是只有區域embedding——TAGNN-L,采用avg的全域embedding——TAGNN-Avg,注意力全域embedding——TAGNN-att,區域embedding+注意力全域embedding——TAGNN-L+att,下圖是效果:
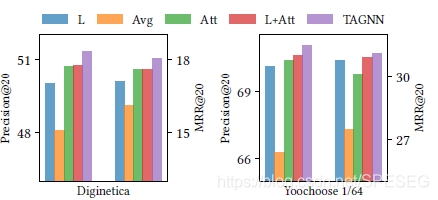
很顯然,混合embedding策略是最佳的,也就是論文提出的方法,TAGNN-L僅僅用了最后一個item作為會話的表達,說明最后的item對用戶最終的行為有很大影響,Avg是最差的,這就說明用戶的行為是多樣性的,不能平均,
敬請期待我的代碼解讀,拜拜,
回頭望,從未懂開口講愛你,
放下你,已是再會無期,
但常伴心扉,柔情全屬你,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/197886.html
標籤:python
上一篇:如何實作7*24小時慢直播應用?
下一篇:近期軟工視頻學習總結