- 參考 GC-Net pytorch版本
- 首先看代碼要對應著網路結構圖和網路層的表格,
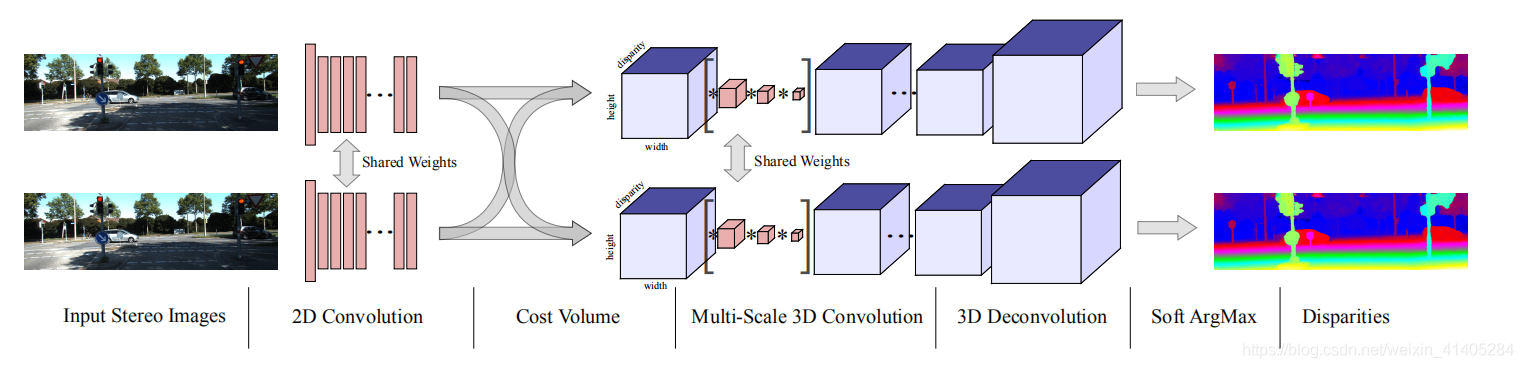

一.Unary Features 特征提取
1.使用2-D卷積提取深度特征,首先使用fiter size:5*5,stride:2的conv2d 將輸入降維(1/2H,1/2W).
imgl0=F.relu(self.bn0(self.conv0(imgLeft)))
imgr0=F.relu(self.bn0(self.conv0(imgRight)))
self.conv0=nn.Conv2d(3,32,5,2,2)
self.bn0=nn.BatchNorm2d(32)
2.后面緊接著是8層殘差網路,

- 注意到這里 num_block[0] ,這里的取值是8 代表八層殘差,變數定義在下面
self.res_block=self._make_layer(block,self.in_planes,32,num_block[0],stride=1)
def _make_layer(self,block,in_planes,planes,num_block,stride):
strides=[stride]+[1]*(num_block-1)
layers=[]
for step in strides:
layers.append(block(in_planes,planes,step))
return nn.Sequential(*layers)
- 注意到這個’num_block’引數,是一個陣列 [8,1],
- 這個for回圈需要注意一下,因為殘差結構穿進去的num_block=8,所以這里strides=[[1],[1],[1],[1],[1],[1],[1],[1]],step每次取值都是,所以傳到block中的步長stride=1
def GcNet(height,width,maxdisp):
return GC_NET(BasicBlock,ThreeDConv,[8,1],height,width,maxdisp)
- 下面詳細剖析8層殘差的代碼細節
- 殘差結構有兩層conv(input=32,output=32,kernel_size=3,stride=1,padding=1)組成,一共八層,這個殘差層的主要作用就是提取 左右影像的‘unary features’
class BasicBlock(nn.Module): #basic block for Conv2d
def __init__(self,in_planes,planes,stride=1):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_planes,planes,kernel_size=3,stride=stride,padding=1)
self.bn1=nn.BatchNorm2d(planes)
self.conv2=nn.Conv2d(planes,planes,kernel_size=3,stride=1,padding=1)
self.bn2=nn.BatchNorm2d(planes)
self.shortcut=nn.Sequential()
def forward(self, x):
out=F.relu(self.bn1(self.conv1(x)))
out=self.bn2(self.conv2(out))
out+=self.shortcut(x)
out=F.relu(out)
return out
- 最后通過一層(no RELU,no BN)的卷積,該層的作用我沒懂,大概就是擴大感受野?
self.conv1=nn.Conv2d(32,32,3,1,1)
二.形成cost volume
- 通過殘差層形成的 ‘unary features’,通過列拼接(w為什么是列拼接,請看我PSMNet的列印結果),形成(1,64,96,1/2H,1/2W)尺寸的 代價體,這個我是參考PSMNet的輸出估計的,代碼我沒跑,要配置環境,主要是理解思想,
def cost_volume(self,imgl,imgr):
B, C, H, W = imgl.size()
cost_vol = torch.zeros(B, C * 2, self.maxdisp , H, W).type_as(imgl)
for i in range(self.maxdisp):
if i > 0:
cost_vol[:, :C, i, :, i:] = imgl[:, :, :, i:]
cost_vol[:, C:, i, :, i:] = imgr[:, :, :, :-i]
else:
cost_vol[:, :C, i, :, :] = imgl
cost_vol[:, C:, i, :, :] = imgr
return cost_vol
cost_volum = self.cost_volume(imgl1, imgr1)
- 通過這種拼接的方式,保留了特征維度和 -
unary features,這樣網路可以學習到absolute representation,并可以結合 context .用這種拼接的方式優于距離度量函式(L1,L2,cosine) - 下面這個對cost volum形成的解釋很形象:
(對于某一個特征,匹配代價卷就是一個三維的方塊,第一層是視差為0時的特征圖,第二層是視差為1時的特征圖,以此類推共有最大視差+1層,長和寬分別是特征圖的尺寸,假設一共提取了10個特征,則有10個這樣的三維方塊)
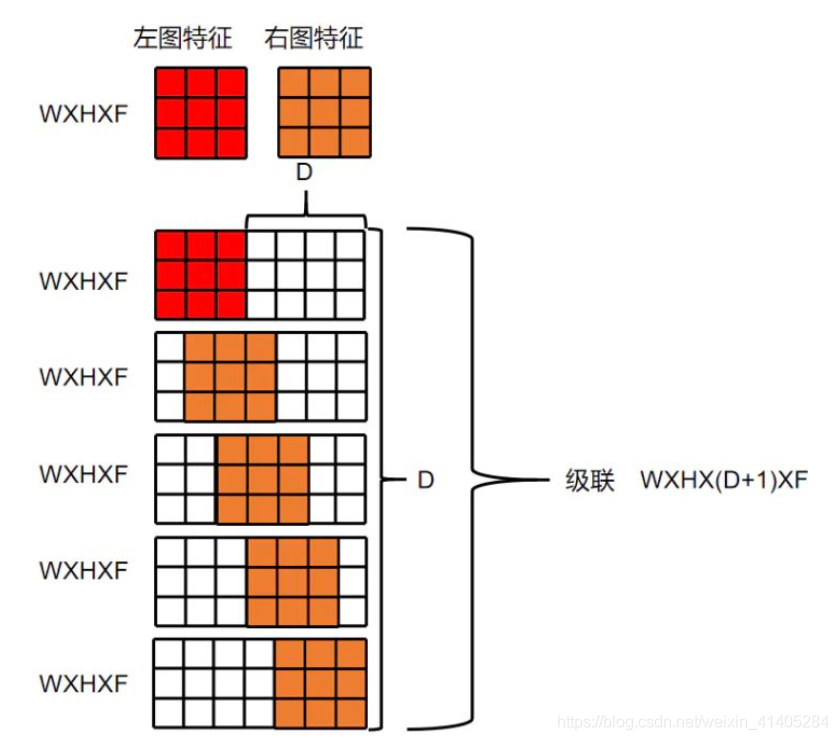
三. 3D卷積下采樣(encoder)
1.合并的’cost volume’ feature size=64,通過兩層conv3d把feature size降到32.
self.conv3d_1 = nn.Conv3d(64, 32, 3, 1, 1)
self.bn3d_1 = nn.BatchNorm3d(32)
self.conv3d_2 = nn.Conv3d(32, 32, 3, 1, 1)
self.bn3d_2 = nn.BatchNorm3d(32)
2.第一個 sub-sampled layer,使1/2變成1/4.
self.block_3d_1 = self._make_layer(block_3d, 64, 64, num_block[1], stride=2)
- 這時num_block[1]=1,運行 3D卷積模塊,其中stride=2用于下采樣,
class ThreeDConv(nn.Module):
def __init__(self,in_planes,planes,stride=1):
super(ThreeDConv, self).__init__()
self.conv1 = nn.Conv3d(in_planes, planes, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm3d(planes)
self.conv2 = nn.Conv3d(planes, planes, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm3d(planes)
self.conv3=nn.Conv3d(planes,planes,kernel_size=3,stride=1,padding=1)
self.bn3=nn.BatchNorm3d(planes)
def forward(self, x):
out=F.relu(self.bn1(self.conv1(x)))
out=F.relu(self.bn2(self.conv2(out)))
out=F.relu(self.bn3(self.conv3(out)))
return out
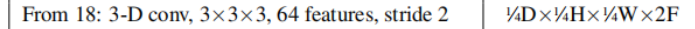
- 原文中的描述是,下采樣層后面跟兩層stirde=2的conv3d(),與代碼作者溝通,第二層的kernel_size=1,只起到了改變通道的作用,
self.conv3d_3 = nn.Conv3d(64, 64, 3, 2, 1)
self.bn3d_3 = nn.BatchNorm3d(64)
3.第二、第三個下采樣層類似,直接說第四個下采樣層,
- 注意到這個 該層的輸出通道變為128.
self.block_3d_4 = self._make_layer(block_3d, 64, 128, num_block[1], stride=2)
四.上采樣(decoder)
1.原文的描述是,下采樣提高速度和增大感受野的同時,也使細節丟失,作者使用殘差層,將高解析度的特征圖與下采樣層級聯,高解析度的影像使用轉置卷積nn.ConvTranspose3d()得到,下面看一下殘差結構如何形成,
- 轉置卷積:注意到將feature size變為2F=64
# deconv3d
self.deconv1 = nn.ConvTranspose3d(128, 64, 3, 2, 1, 1)
self.debn1 = nn.BatchNorm3d(64)

- 直接對下采樣的結果進行up-sample 會丟失很多特征,與高解析度的下采樣層輸出級聯,彌補丟失的細節,有四層上采樣和四個殘差結構不一一描述,
deconv3d = F.relu(self.debn1(self.deconv1(conv3d_block_4)) + conv3d_block_3)
- 最后一層上采樣輸出

2.最后在加一層 輸出通道為’1’的轉置卷積,將‘cost volum’壓縮到一層初始視差圖,還原尺寸(1DHW),注意到第一層55的conv2d的輸出是(1/2H,1/2W),這里恢復原圖的size
original_size = [1, self.maxdisp*2, imgLeft.size(2), imgLeft.size(3)]
- 這里補一下view()的語法
self.deconv5 = nn.ConvTranspose3d(32, 1, 3, 2, 1, 1)
out = deconv3d.view( original_size)
五.視差回歸
- 對于這種匹配代價卷,我們可以通過在視差維度上采用sof t argmin操作來估算視差值,函式有兩個特點:
- 可微分,可以使用optimizer進行梯度計算
- 可回歸,loss作用可以傳遞
prob = F.softmax(-out, 1)
- 視差回歸
disp1 = self.regression(prob)
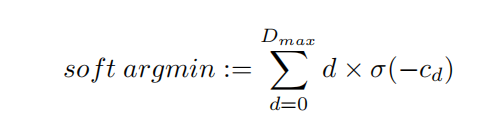
六.優化器和loss
criterion = SmoothL1Loss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/198069.html
標籤:java
下一篇:[提供軟體環境和資料集下載]Windows下基于YOLOv4和OpenCV4深度學習工業瑕疵缺陷檢測實戰:訓練自己的資料集和前端軟體,效果意外的好