平時大家都知道記憶體訪問很快,今天來讓我們來把刨根問底的精神發揮到極致,來思考兩個問題
問題1: 記憶體訪問延時到底是多少?你是否會進行大概的估算?
例如筆者的記憶體條的Speed顯示是1066MHz,那是否可以推算出記憶體IO延時是1s/1066MHz=0.93ns?
這種演算法大錯特錯,
問題2: 記憶體存在隨機IO比順序IO慢的問題嗎?
我們都知道磁盤的隨機IO要比順序IO慢的多(作業系統底層還專門實作了電梯調度演算法來緩解這個問題),那么記憶體的隨機IO會比順序IO慢嗎?
要想徹底弄明白以上兩個問題,我想我們得從記憶體IO的物理程序中來尋找答案,
先給你講個圖書管理員的故事
在開始介紹枯燥的記憶體作業原理之前,我想先給你講一個故事,并帶你去認識一個人,圖書館的管理員,
在我們的這個故事中,你是故事的主角,你有一所房子,房子里有一個仆人,他每天幫你處理各種各樣的圖書資料,但是北京房價太貴,所以你的這個房子很小,只能放的下64本書,你家的馬路對面,就是北京圖書館(你家房子雖然小但是地段還不錯),你所需要的所有的圖書在那里都可以找到,圖書館有個管理員,他負責幫你把你想要的書找出來,

好接下來,導演喊了action,場景開始!
-
場景1:
你發現你需要編號為0的書的計算結果,你的仆人穿過馬路告訴了圖書管理員,告訴他請幫我把第0-63本書取出來,圖書管理員幫你在電腦前查得該書在二樓, 于是他,花了點時間坐電梯到了二樓,等到了二樓,他又花了點時間幫你找了出來,然后你的仆人抱著64本書放到了客廳,拿起第0本書幫你處理了起來, -
場景2:
你發現你需要編號為1的書的計算結果,告訴你的仆人,你的仆人直接從客廳拿出來就可以處理了,這次你等的時間最短, -
場景3:
你發現需要編號為65的書,你又告訴你的仆人,你的仆人穿過馬路又去找了圖書管理員,圖書管理員還在二樓呢,聽說這次需要65-127,這次他不用再花時間找樓層了,只是花時間找書就可以了,你的仆人把65-127的書放到了客廳(以前的0-63就都扔了),并幫你開始處理起65號書來, -
場景4:
你發現你需要編號為10000的書,你告訴了你的仆人,你的仆人穿過馬路去圖書館,找到了管理員,這次管理員查得你需要的書是在10樓,他得花點時間坐電梯過去,去了之后,他又得花點時間幫你找出來,
這四個場景里,我覺得你一定發現了不同情形下耗時的差異,
- 場景1和場景4花費的時間最多,因為圖書管理員需要花時間坐電梯找樓層,需要花時間在樓內找書,
- 場景3次之,因為圖書管理員直接就在樓層內,只需要花時間在樓內找書既可
- 場景2最快,因為只需要仆人幫你從客廳拿過來就好,連馬路都不需要過,
之所以編造這么一個例子,是因為記憶體的作業方式和它太像了, 接下來我們進入記憶體的實際分析,
記憶體的物理結構
在《帶你理解記憶體對齊最底層原理!》中我們了解了記憶體顆粒的物理構造以及IO程序,今天我們再來復習一下,
記憶體是由chip構成,每個chip內部,是由8個bank組成的,其構造如下圖:
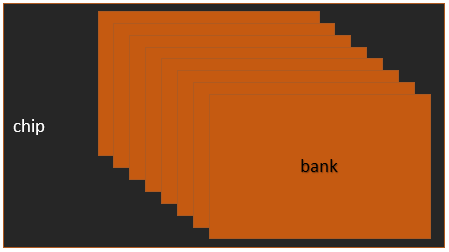
而每一個bank是一個二維平面上的矩陣,前面文章中我們說到過,矩陣中每一個元素中都是保存了1個位元組,也就是8個bit,
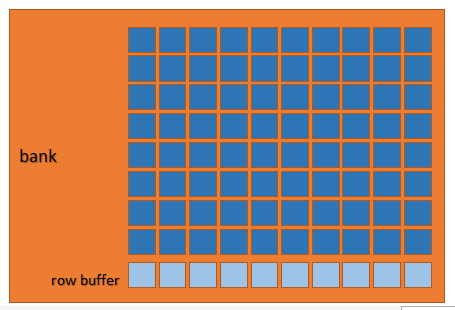
每當CPU向記憶體請求資料的時候,記憶體芯片總是8個bank并行一起作業,每個bank在定位到行地址后,把對應的行copy到row buffer, 再根據列地址把對應的元素中的資料取出來,8個bank把資料拼接一下,一個64位寬的資料就可以回傳給CPU了,
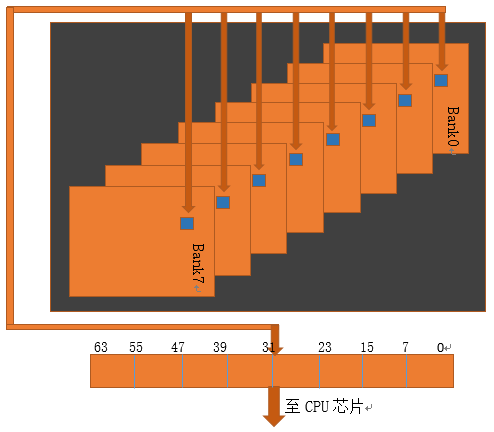
根據上面幾張圖我們可以大致了解記憶體的IO程序,在這個程序中每一步操作之間都有一些延遲,讓我們來繼續了解這些延遲,
記憶體IO延遲
在《從DDR發展到DDR4,記憶體核心頻率指標其實基本上就沒太大的進步,》里的結尾處,你應該記得我們提到了記憶體有CL-tRCD-tRP-tRAS四個引數, 我們今天來詳細理解一下這四個引數的含義:
- CL(Column Address Latency):發送一個列地址到記憶體與資料開始回應之間的周期數
- tRCD(Row Address to Column Address Delay):打開一行記憶體并訪問其中的列所需的最小時鐘周期數
- tRP(Row Precharge Time):發出預充電命令與打開下一行之間所需的最小時鐘周期數,
- tRAS(Row Active Time):行活動命令與發出預充電命令之間所需的最小時鐘周期數,也就是對下一次預充電時間進行限制,
要注意除了CL是固定周期數以外,其它的三個都是最小周期,另外上面的引數都是以時鐘周期為單位的,因為現代的記憶體都是一個時鐘周期上下沿分別各傳輸一次資料,所以用Speed/2就可以得出,例如筆者的機器的Speed是1066MHz,則時鐘周期為533MHz,你自己的機器可以通過dmidecode命令查看:
# dmidecode | grep -P -A16 "Memory Device"
Memory Device
......
Speed: 1067 MHz
......
和“圖書管理員”類似,記憶體芯片也有類似的作業場景:
-
場景1:
你的行程需要記憶體地址0x0000為的一個位元組的資料,CPU這時候向記憶體控制器發出請求,記憶體控制器進行行地址的預充電,需要等待tRP個時鐘周期,再發出打開一行記憶體的命令,又需要等待tRCD個時鐘周期,接著發送列地址,再等待CL個周期,最終將0x0000-0x0007的資料全部回傳給了CPU, CPU把這些資料放入到了自己的cache里,并幫你開始對0x0000的資料進行運算, -
場景2:
你的行程需要記憶體地址0x0003的一個位元組資料,CPU發現發現它在自己的cache里存在,直接使用就好了,這個場景里其實根本就沒有記憶體IO發生, -
場景3:
你的行程需要記憶體地址0x0008的一個位元組資料,CPU的cache并沒有命中,于是向記憶體控制器請求,記憶體控制器發現行地址和上一次作業的行地址一致,這次只需要發送列地址后等待CL個周期,就可以拿到0x0008-0x0015的資料并回傳給CPU了, -
場景4:
你的行程需要記憶體地址0xf000的一個位元組資料,同樣CPU的cache并不命中,向記憶體控制器請求,記憶體控制器一看(內心有些許的郁悶),這次行地址又變了,得,和場景1一樣,繼續等待tRP+tRCD+CL個周期后,才能夠取到資料并回傳,
實際的計算機的記憶體IO程序中還需要進行邏輯地址和物理地址的轉換,這里忽略不表,
結論
其中場景1和場景4是隨機IO的情況,場景2無記憶體IO發生,場景3是順序IO,,通過上面的程序描述我們可以得到結論,記憶體也存在和磁盤一樣,隨機IO比順序IO要慢的問題,如果行地址同上一次訪問的不一致,則需要重新拷貝row buffer,延遲周期需要tRP+tRCD+CL,而如果是順序IO的話(行地址不變),只需要CL個周期既可完成,
我們接著估算下記憶體的延時,筆者的機器上的記憶體引數Speed為1066MHz(通過dmidecode查得),該值除以2就是時鐘周期的頻率=1066/2=533Mhz,其延遲周期為7-7-7-24,
- 順序IO
這種狀況下需要tRP+tRCD+CL個時鐘周期,7+7+7=21個周期,但是還有個tRAS的限制,兩次行地址預充電不得小于24,所以我們得按24來計算,24*(1s/533Mhz) = 45ns - 隨機IO
這種狀況下只需要CL個時鐘周期 7*(1s/533Mhz)=13ns
擴展:回顧CPU的Cache Line
因為對于記憶體來說,隨機IO一次開銷比順序IO高好幾倍,所以作業系統在作業的時候,會盡量讓記憶體通過順序IO的方式來進行,做法關鍵就是Cache Line,當CPU發現快取不命中的時候,實際上從來不會向記憶體去請求1個位元組,8個位元組這種,而是一次性就要64位元組,然后放到自己的Cache中存起來,
用上面的例子來看,
- 如果隨機請求8位元組:耗時是45ns
- 如果隨機請求64位元組:耗時是45+7*13 = 136ns
開銷也沒貴多少,因為只有第一個位元組是隨機IO,后面的7個位元組都是順序IO,資料是8倍,但是IO耗時只有3倍,而且取出來的資料后面大概率要用,所以計算機內部就這么搞了,通過這種方式幫你避免一些隨機IO!
另外,記憶體也支持burst(突發傳輸)模式,在這種模式下可以只傳入一次行列地址,就命令記憶體回傳該記憶體開頭的連續位元組資料,比如64位元組,這種模式下,只有第一次的8位元組需要真正的行列訪問延遲,后面的7個位元組可以直接按記憶體的資料頻率給吐出來,耗時更短,

開發內功修煉之記憶體篇專輯:
- 1.帶你深入理解記憶體對齊最底層原理
- 2.記憶體隨機也比順序訪問慢,帶你深入理解記憶體IO程序
- 3.從DDR到DDR4,記憶體核心頻率其實基本上就沒太大的進步
- 4.實際測驗記憶體在順序IO和隨機IO時的訪問延時差異
- 5.揭穿記憶體廠家“謊言”,實測記憶體帶寬真實表現
- 6.NUMA架構下的記憶體訪問延遲區別!
- 7.PHP7記憶體性能優化的思想精髓
- 8.一次記憶體性能提升的專案實踐
- 9.挑戰Redis單實體記憶體最大極限,“遭遇”NUMA陷阱!
我的公眾號是「開發內功修煉」,在這里我不是單純介紹技術理論,也不只介紹實踐經驗,而是把理論與實踐結合起來,用實踐加深對理論的理解、用理論提高你的技術實踐能力,歡迎你來關注我的公眾號,也請分享給你的好友~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/199338.html
標籤:PHP