什么是map
是由一組<key,value>對組成的資料結構,并且同一個key只能出現一次
有map相關的操作主要是
- 增加一個k-v對------Add or insert
- 洗掉一個k-v對------Remover or delete
- 修改某個k對應的v------Reassign
- 查詢某個k對應的v------Lookup
- map的設計也稱為
The dictionary problem,它的任務是設計一種資料結構用來維護一個集合的資料,并且可以同時對集合進行增刪改查的操作,最主要的資料結構有兩種:哈希查找表(Hashtable)、 搜索樹(Searchtree)
哈希查找表用一個哈希函式將 key 分配到不同的桶(bucket,也就是陣列的不同 index),這樣,開銷主要在哈希函式的計算以及陣列的常數訪問時間,在很多場景下,哈希查找表的性能很高,
哈希查找表一般會存在"碰撞"的問題,就是說不同的key被哈希到同一個bucket(bucket :陣列的不同index),一般有兩種應對的方法:鏈表法和開放地址法,鏈表法將同一個bucket實作成一個鏈表,落在同一個bucket中的key都會插入這個鏈表,開放地址法則是碰撞發生后,通過一定的規律,在陣列的后面挑選"空位"用來放置新的key
搜索樹法一般采用自平衡搜索樹,包括:AVL 樹,紅黑樹,
自平衡搜索樹法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N),
遍歷自平衡搜索樹,回傳的 key 序列,一般會按照從小到大的順序;而哈希查找表則是亂序的,
為什么要用 map
Go語言內置的map實作了
hash table,特點是實作了快速查找,添加,洗掉的功能,
map的底層實作
在原始碼中,表示map的結構體是hmap,他是hashmap的"縮寫":
// A header for a Go map.
type hmap struct {
// 元素個數,呼叫 len(map) 時,直接回傳此值
count int
flags uint8
// buckets 的對數 log_2
B uint8
// overflow 的 bucket 近似數
noverflow uint16
// 計算 key 的哈希的時候會傳入哈希函式
hash0 uint32
// 指向 buckets 陣列,大小為 2^B
// 如果元素個數為0,就為 nil
buckets unsafe.Pointer
// 擴容的時候,buckets 長度會是 oldbuckets 的兩倍
oldbuckets unsafe.Pointer
// 指示擴容進度,小于此地址的 buckets 遷移完成
nevacuate uintptr
extra *mapextra // optional fields
}
說明一下, B 是 buckets 陣列的長度的對數,也就是說 buckets 陣列的長度就是 2^B,
bucket 里面存盤了 key 和 value,后面會再講,
buckets 是一個指標,最終它指向的是一個結構體:
type bmap struct {
tophash [bucketCnt]uint8
}
但這只是表面(src/runtime/hashmap.go)的結構,編譯期間會給它加料,動態地創建一個新的結構:
type bmap struct {
topbits [8]uint8
keys [8]
keytype values [8]valuetype
pad uintptr
overflow uintptr
}
bmap 就是我們常說的“桶”,桶里面會最多裝 8 個 key,這些 key 之所以會落入同一個桶,是因為它們經過哈希計算后,哈希結果是“一類”的,在桶內,又會根據 key 計算出來的 hash 值的高 8 位來決定 key 到底落入桶內的哪個位置(一個桶內最多有8個位置),
來一個整體的圖:
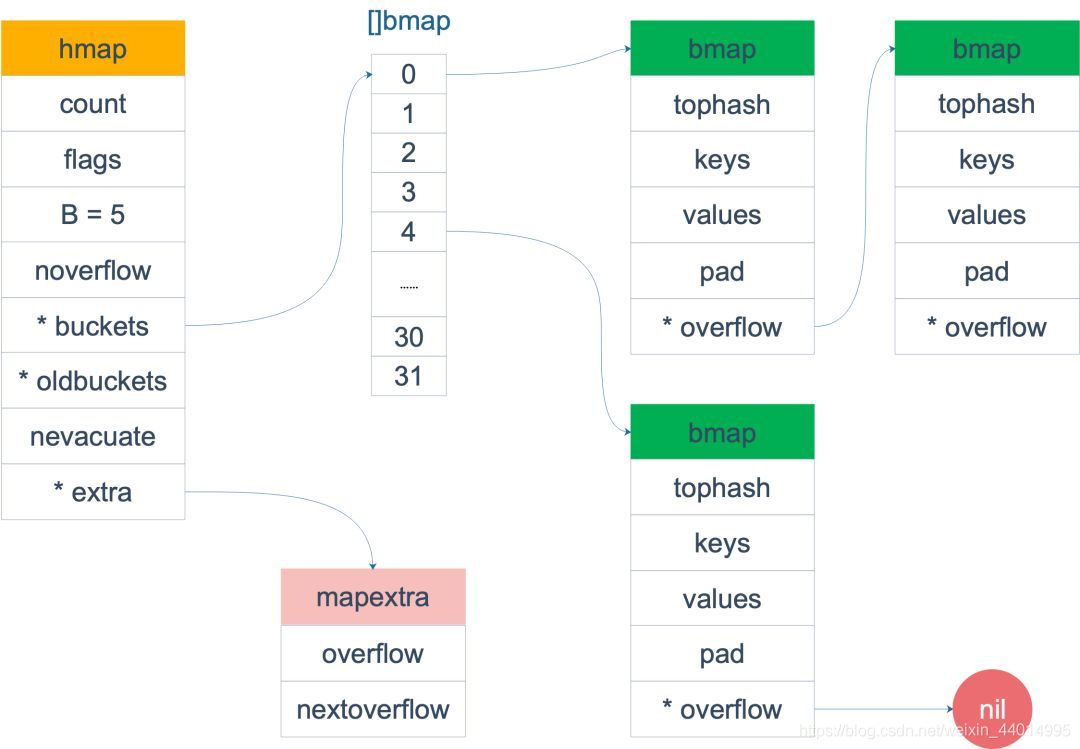
當 map 的 key 和 value 都不是指標,并且 size 都小于 128 位元組的情況下,會把 bmap 標記為不含指標,這樣可以避免 gc 時掃描整個 hmap,但是,我們看 bmap 其實有一個 overflow 的欄位,是指標型別的,破壞了 bmap 不含指標的設想,這時會把 overflow 移動到 extra 欄位來,
type mapextra struct {
// overflow[0] contains overflow buckets for hmap.buckets.
// overflow[1] contains overflow buckets for hmap.oldbuckets.
overflow [2]*[]*bmap
// nextOverflow 包含空閑的 overflow bucket,這是預分配的 bucket
nextOverflow *bmap
}
bmap 是存放 k-v 的地方,我們把視角拉近,仔細看 bmap 的內部組成,

上圖就是 bucket 的記憶體模型, HOBHash 指的就是 top hash,注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/… 這樣的形式,原始碼里說明這樣的好處是在某些情況下可以省略掉 padding 欄位,節省記憶體空間,
例如,有這樣一個型別的 map:
map[int64]int8
如果按照 key/value/key/value/… 這樣的模式存盤,那在每一個 key/value 對之后都要額外 padding 7 個位元組;而將所有的 key,value 分別系結到一起,這種形式 key/key/…/value/value/…,則只需要在最后添加 padding,
每個 bucket 設計成最多只能放 8 個 key-value 對,如果有第 9 個 key-value 落入當前的 bucket,那就需要再構建一個 bucket ,通過 overflow 指標連接起來,
創建 map
ageMp:=make(map[string]int)
//指定map長度
ageMp:=make(map[string]int,8)
//ageMp 為nil,不能向其添加元素,否則會直接panic
通過匯編語言可以看到,實際上底層呼叫的是 makemap 函式,主要做的作業就是初始化 hmap 結構體的各種欄位,例如計算 B 的大小,設定哈希種子 hash0 等等,
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap
注意,這個函式回傳的結果:*hmap,它是一個指標,而我們之前講過的 makeslice 函式回傳的是 Slice 結構體:
func makeslice(et *_type,len ,cap int)slice
回顧一下 slice 的結構體定義:
type slice struct{
array unsafe.Pointer//元素指標
len int// 長度
cap int// 容量
}
結構體內部包含底層的資料指標,
makemap 和 makeslice 的區別,帶來一個不同點:當 map 和 slice 作為函式引數時,在函式引數內部對 map 的操作會影響 map 自身;而對 slice 卻不會(之前講 slice 的文章里有講過),
主要原因:一個是指標( *hmap),一個是結構體( slice),Go 語言中的函式傳參都是值傳遞,在函式內部,引數會被 copy 到本地,*hmap指標 copy 完之后,仍然指向同一個 map,因此函式內部對 map 的操作會影響實參,而 slice 被 copy 后,會成為一個新的 slice,對它進行的操作不會影響到實參,
哈希函式
key 定位程序
以上省略了好大一部分的講解~~
因為看不懂,后續再來補充~
原文地址
map 的兩種 get 操作
Go 語言中讀取 map 有兩種語法:帶 comma 和 不帶 comma,當要查詢的 key 不在 map 里,帶 comma 的用法會回傳一個 bool 型變數提示 key 是否在 map 中;而不帶 comma 的陳述句則會回傳一個 value 型別的零值,如果 value 是 int 型就會回傳 0,如果 value 是 string 型別,就會回傳空字串,
package main
import (
"fmt"
)
func main() {
ageMap :=make(map[string]int)
ageMap["fu"] =26
//不帶comma用法
agel :=ageMap["shao"]
fmt.Println(agel)
//帶comma用法
age2,ok :=ageMap["shao"]
fmt.Println(age2,ok)
}
運行結果:
0
0 false
以前一直覺得好神奇,怎么實作的?這其實是編譯器在背后做的作業:分析代碼后,將兩種語法對應到底層兩個不同的函式,
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool)
原始碼里,函式命名不拘小節,直接帶上后綴 1,2,完全不理會《代碼大全》里的那一套命名的做法,從上面兩個函式的宣告也可以看出差別了, mapaccess2 函式回傳值多了一個 bool 型變數,兩者的代碼也是完全一樣的,只是在回傳值后面多加了一個 false 或者 true,
如何進行擴容
以上省略了好大一部分的講解~~
因為看不懂,后續再來補充~
原文地址
map 的遍歷
package main
import (
"fmt"
)
func main() {
ageMap :=make(map[string]int)
ageMap["fu"] =26
for name,age :=range ageMap{
fmt.Println(name,age)
}
}
執行匯編命令:
go tool compile -S main.go
關鍵的幾行匯編代碼如下:
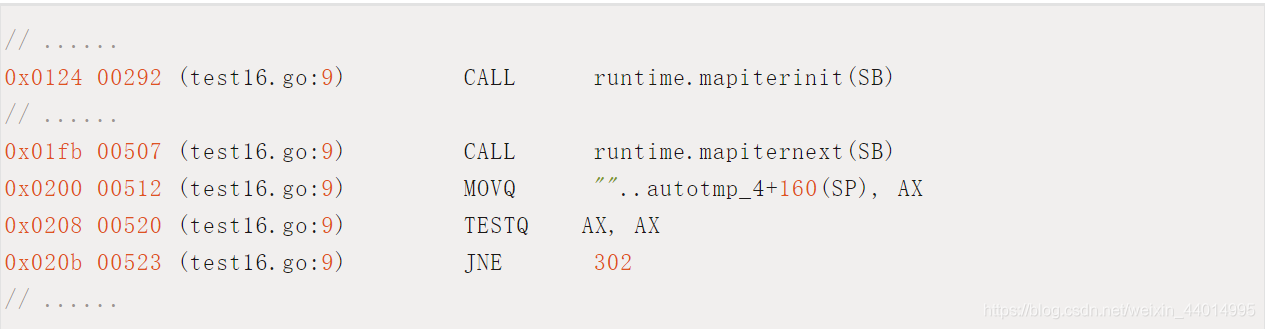
這樣,關于 map 迭代,底層的函式呼叫關系一目了然,先是呼叫 mapiterinit 函式初始化迭代器,然后回圈呼叫 mapiternext 函式進行 map 迭代,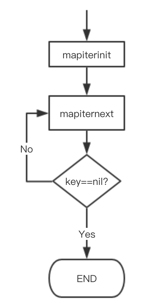
以上省略了好大一部分的講解~~
因為看不懂,后續再來補充~
原文地址
map 的賦值
package main
import (
"fmt"
)
func main() {
scene := make(map[string]int)
// 準備map資料
scene["route"] = 66
scene["brazil"] = 666
scene["china"] = 960
for k, v := range scene {
fmt.Println(k, v)
}
}
map 的洗掉
package main
import (
"fmt"
)
func main() {
scene := make(map[string]int)
// 準備map資料
scene["route"] = 66
scene["brazil"] = 4
scene["china"] = 960
delete(scene, "brazil")
for k, v := range scene {
fmt.Println(k, v)
}
}
可以邊遍歷邊洗掉嗎
go語言map遍歷時洗掉是安全的, 且可以完全洗掉
package main
import (
"fmt"
)
func main() {
x := map[int]int{}
for i := 0; i < 10000; i++ {
x[i] = i
}
fmt.Println("初始化后,長度:", len(x))
// 遍歷時洗掉所有的偶數
for k := range x {
if k%2 == 0 {
delete(x, k)
}
}
fmt.Println("洗掉所有的偶數后,長度:", len(x))
// 遍歷時洗掉所有的元素
for k := range x {
delete(x, k)
}
fmt.Println("洗掉所有的元素后,長度:", len(x))
}
map并發讀寫
map 并不是一個執行緒安全的資料結構,同時讀寫一個 map 是未定義的行為,如果被檢測到,會直接 panic,
package main
import (
"fmt"
"time"
)
func main(){
c := make(map[string]int)
go func() {//開一個goroutine寫map
for j := 0; j < 1000000; j++ {
c[fmt.Sprintf("%d", j)] = j
}
}()
go func() { //開一個goroutine讀map
for j := 0; j < 1000000; j++ {
fmt.Println(c[fmt.Sprintf("%d",j)])
}
}()
time.Sleep(time.Second*20)
}
一般而言,這可以通過讀寫鎖來解決:sync.RWMutex,
讀之前呼叫 RLock() 函式,讀完之后呼叫 RUnlock() 函式解鎖;寫之前呼叫 Lock() 函式,寫完之后,呼叫 Unlock() 解鎖,
package main
import (
"fmt"
"time"
"sync"
)
func main(){
c := make(map[string]int)
var rwLock *sync.RWMutex = new(sync.RWMutex)
go func() {//開一個goroutine寫map
for j := 0; j < 10; j++ {
rwLock.RLock()
c[fmt.Sprintf("%d", j)] = j
rwLock.RUnlock()
}
}()
go func() { //開一個goroutine讀map
for j := 0; j < 10; j++ {
rwLock.Lock()
fmt.Println(c[fmt.Sprintf("%d",j)])
rwLock.Unlock()
}
}()
time.Sleep(time.Second*1)
}
另外, sync.Map 是執行緒安全的 map,也可以使用,它的實作原理,這次先不說了,
sync.map的使用
key 可以是 float 型嗎?
從語法上看,是可以的,Go 語言中只要是可比較的型別都可以作為 key,除開 slice,map,functions 這幾種型別,其他型別都是 OK 的,具體包括:布林值、數字、字串、指標、通道、介面型別、結構體、只包含上述型別的陣列,這些型別的共同特征是支持 == 和 != 運算子, k1==k2 時,可認為 k1 和 k2 是同一個 key,如果是結構體,則需要它們的欄位值都相等,才被認為是相同的 key,
順便說一句,任何型別都可以作為 value,包括 map 型別
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/199486.html
標籤:java