論文地址:https://arxiv.org/pdf/2010.14851.pdf
github地址:https://github.com/jytime/DICL-Flow (目前還沒把訓練好的模型放出來,也還沒有訓練代碼,僅有模型搭建代碼)
Motivation:
- Learning Matching Costs在雙目匹配上取得了較大的成功,通過構造3D的Cost Volume(FxDxHxW)和3D Conv; 然而,若這一套直接使用在光流上,會構造4D的Cost Volume(FxUxVxHxW)和需要使用4D Conv,在目前的設備上這樣的操作基本上不允許的(算力要求高和需要的顯存大),該篇論文提出的DICL(displacement-invariant cost learning)層通過2D convolution-based matching net在每一個u(displacement)分別去學習該u的cost, 從而能夠對4D Cost Volume進行處理,
- 通過Learning Matching Costs獲得到在每一個u上的概率,通過soft-max去獲得能夠達到亞像素精度的光流值; 這樣的操作在單峰的概率分布上是很成功的,然而因為遮擋,低紋理,重復紋理以及影像的模糊會導致此概率分布是多峰的,這樣得到的光流值將會較差(平均的結果會差于Winner-Take-All(意思是誰的概率最高就選擇誰)的策略), 該篇論文提出的DAP(Displacement-Aware Projection)層能夠在這樣的case上取得成功,
DICL:
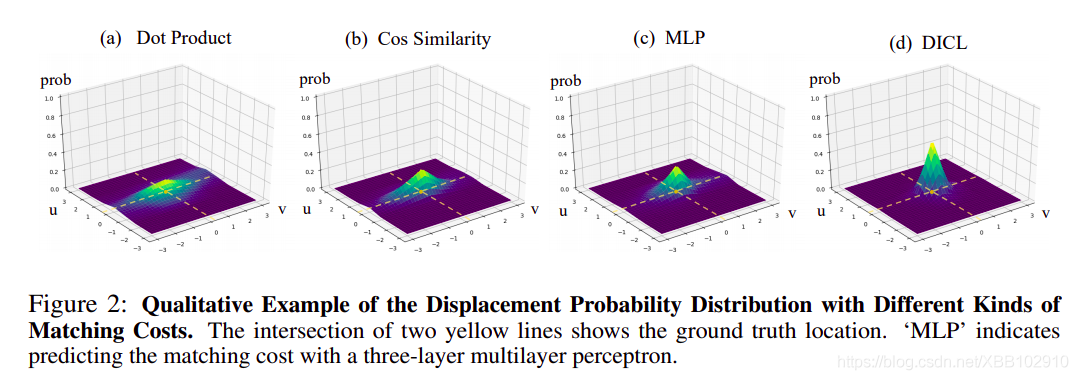
先看一下DICL與其他方式的對比,有較多文章使用傳統的點乘或者Cosine距離來代替Learning Matching Costs,這個效果在上圖表現比較明顯,不容易將峰值提煉出來,整體表現都還比較平; MLP指的是使用簡單的3層卷積去Learning Matching Costs,可以看到它的確能夠相對比與傳統方式的提升,然而還是不夠突出; 而在DICL中峰值的突出性較大,這使得能夠獲得的光流精度較高,具體DICL的操作如下:
對每一個u將src的feature(FxHxW)和ref偏移u的feature(FxHxW) concate起來構造一個Fu(2FxHxW):
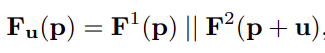
然后使用一個2D convolution-based net(G())來對Fu進行操作(不同的u的2D convolution-based net的權重共享),接著輸出一個(1xHxW)可以理解成是在u上的cost map,然后將所有的u構造在一起得到(UxVxHxW)的cost volume, 具體公式如下:
![]()
DAP:
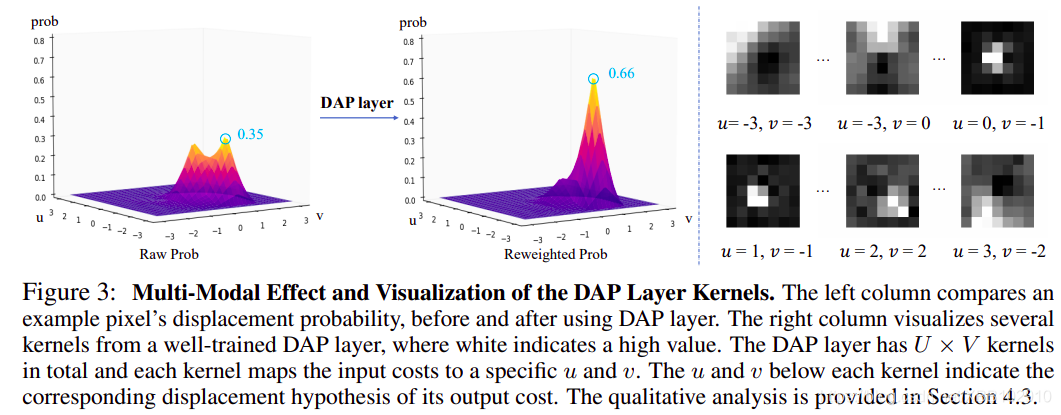
根據Motivation的介紹,DAP的一個很大的作用是在于將多峰的概率分布能夠轉換成單峰的概率分布; 如上圖所示,DAP的效果還是很明顯的,此層的操作也是比較簡單的,利用一個1x1的conv對displacement的維度進行加權平均,公式如下:
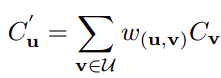
個人認為這種加權平均很難將所有的多峰情況處理,僅能處理一小部分
Experiments:
本篇博客近去討論DICL和DAP層的作用:
DICL:Reduced DICL表示DICL的網路使用1x1 conv代替,指標越低越好
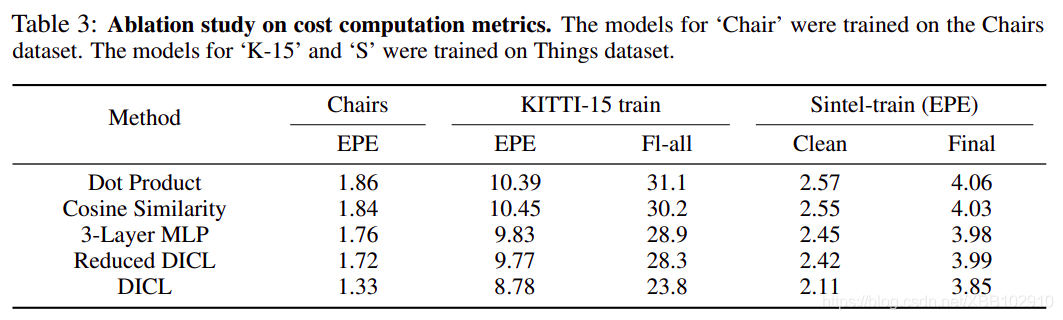
將DICL層使用在PWCNet和DICL上的效果如下:

DAP:Ours-w/o DAP就是表示去掉DAP層的結果
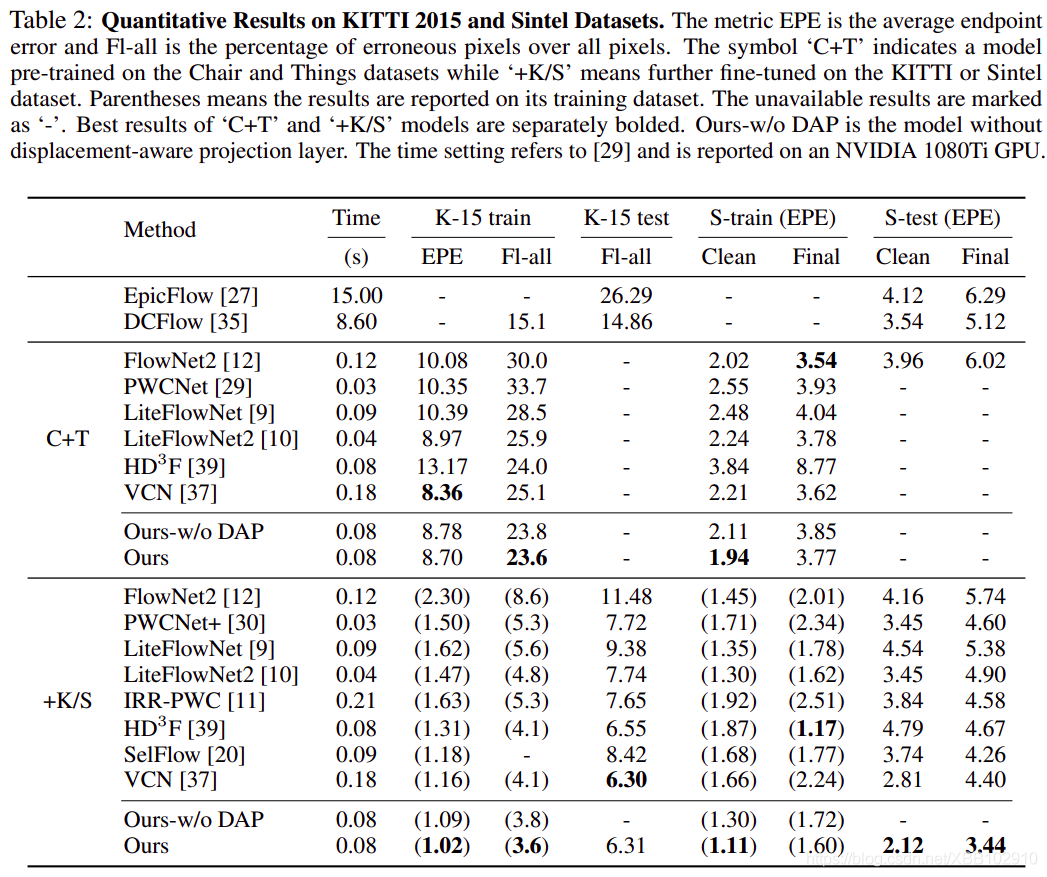
整體效果圖對比:

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/200717.html
標籤:python