卷積神經網路
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,Sequential,losses,optimizers,datasets
1.卷積層的實作
在 TensorFlow 中,既可以通過自定義權值的底層實作方式搭建神經網路,也可以直接呼叫現成的卷積層類的高層方式快速搭建復雜網路,我們主要以 2D 卷積為例,
1.1 自定義權值
在 TensorFlow 中,通過 tf.nn.conv2d 函式可以方便地實作 2D 卷積運算,tf.nn.conv2d基于輸入 X: [b,?,𝑤,𝑐𝑖𝑛] 和卷積核 W:[𝑘,𝑘,𝑐𝑖𝑛,𝑐𝑜𝑢𝑡] 進行卷積運算,得到輸出O:[b,?′,𝑤′, 𝑐𝑜𝑢𝑡],其中𝑐𝑖𝑛表示輸入通道數,𝑐𝑜𝑢𝑡表示卷積核的數量,也是輸出特征圖的通道數,
tf.nn.conv2d?
x = tf.random.normal([2,5,3,3]) # 2組資料,高寬為5,通道為3
w = tf.random.normal([3,3,3,4]) # 創建4個3*3,3個通道的卷積核
out = tf.nn.conv2d(x,w,strides = 1,padding = [[0,0],[0,0],[0,0],[0,0]])
out.shape
TensorShape([2, 3, 1, 4])
其中 padding 引數的設定格式為:
padding=[[0,0],[上,下],[左,右],[0,0]]
例如,上下左右各 padding 一個單位,則 padding=[[0,0],[1,1],[1,1],[0,0]],實作如下:
out = tf.nn.conv2d(x,w,strides = 1,padding = [[0,0],[1,1],[1,1],[0,0]])
out.shape
TensorShape([2, 5, 3, 4])
特別地,通過設定引數padding='SAME',strides=1 可以直接得到輸入、輸出同大小的卷積層,其中 padding 的具體數量由 TensorFlow 自動計算并完成填充操作:
out = tf.nn.conv2d(x,w,strides=1,padding='SAME')
out.shape
TensorShape([2, 5, 3, 4])
當𝑠 > 時,設定 padding='SAME' 將使得輸出高、寬將成 1/𝑠 倍地減少:
# 高寬先 padding 成可以整除 3 的最小整數 6,然后 6 按 3 倍減少,得到 2x2
out = tf.nn.conv2d(x,w,strides=3,padding='SAME')
out.shape
TensorShape([2, 2, 1, 4])
卷積神經網路層與全連接層一樣,可以設定網路帶偏置向量,tf.nn.conv2d 函式是沒有實作偏置向量計算的,添加偏置只需要手動累加偏置張量即可:
# 根據[cout]格式創建偏置向量
b = tf.zeros([4])
# 在卷積輸出上疊加偏置向量,它會自動 broadcasting 為[b,h',w',cout]
out = out + b
1.2 卷積層類
通過卷積層類 layers.Conv2D 可以不需要手動定義卷積核 W 和偏置 b 張量,直接呼叫類實體即可完成卷積層的前向計算,實作更加高層和快捷,
在新建卷積層類時,只需要指定卷積核數量引數 filters,卷積核大小 kernel_size,步長strides,填充 padding 等即可,如下創建了 4 個 3x3 大小的卷積核的卷積層,步長為 1, padding 方案為’SAME’:
layer = layers.Conv2D(4,kernel_size=3,strides=1,padding='SAME')
實際上,如果卷積核高寬不等,步長行列方向不等,此時需要將 kernel_size 引數設計為(𝑘?,𝑘𝑤),strides 引數設計為(𝑠?,𝑠𝑤),如下創建 4 個 3x4 大小的卷積核,豎直方向移動步長𝑠? = 2,水平方向移動步長𝑠𝑤 = 1:
layer = layers.Conv2D(4,kernel_size=(3,4),strides=(2,1),padding='SAME')
創建完成后,通過呼叫實體(的__call__方法)即可完成前向計算:
# 創建卷積層類
layer = layers.Conv2D(4,kernel_size=3,strides=1,padding='SAME')
out = layer(x) # 前向計算
out.shape
TensorShape([2, 5, 3, 4])
在類 Conv2D 中,保存了卷積核張量 W 和偏置 b,可以通過類成員 trainable_variables直接回傳 W,b 的串列:
layer.trainable_variables
2.LeNet-5 實戰
下圖是 LeNet-5 的網路結構圖,它接受 32x32 大小的數字、字符圖片,經過第一個卷積層得到 [b,28,28,6]形狀的張量,經過一個向下采樣層,張量尺寸縮小到 [b,14,14,6],經過第二個卷積層,得到[b,10,10,16]形狀的張量,同樣經過下采樣層,張量尺寸縮小到[b,5,5,16],在進入全連接層之前,先將張量打成[b,400]的張量,送入輸出節點數分別為 120,84 10 的 3 個全連接層,得到[b,10]的張量,
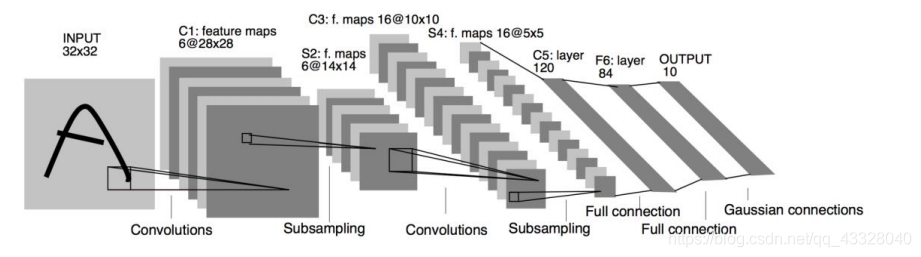
其中下采樣層我們用最大池化層來實作
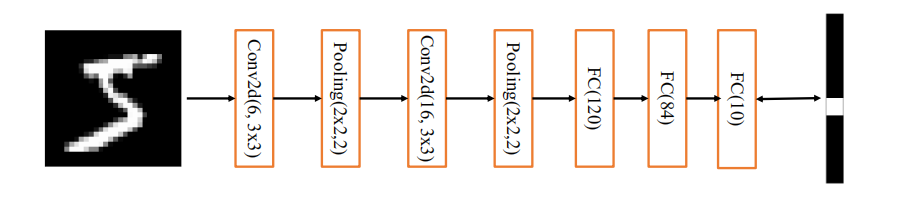
我們基于 MNIST 手寫數字圖片資料集訓練 LeNet-5 網路,并測驗其最終準確度,首先通過 Sequential 容器創建 LeNet-5:
def preprocess(x, y):
# [0~255] => [-1~1]
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1.
y = tf.cast(y, dtype=tf.int32)
return x,y
batchsz = 32
# [50k, 32, 32, 3], [10k, 1]
(x, y), (x_val, y_val) = datasets.mnist.load_data()
y = tf.squeeze(y)
y_val = tf.squeeze(y_val)
y = tf.one_hot(y, depth=10) # [50k, 10]
y_val = tf.one_hot(y_val, depth=10) # [10k, 10]
print('datasets:', x.shape, y.shape, x_val.shape, y_val.shape, x.min(), x.max())
train_db = tf.data.Dataset.from_tensor_slices((x,y))
train_db = train_db.map(preprocess).shuffle(10000).batch(batchsz)
db_test = tf.data.Dataset.from_tensor_slices((x_val, y_val))
db_test = db_test.map(preprocess).batch(batchsz)
datasets: (60000, 28, 28) (60000, 10) (10000, 28, 28) (10000, 10) 0 255
from tensorflow.keras import Sequential
network = Sequential([ # 網路容器
layers.Conv2D(6,kernel_size=3,strides=1), # 第一個卷積層, 6 個 3x3 卷積核
layers.MaxPooling2D(pool_size=2,strides=2), # 高寬各減半的池化層
layers.ReLU(), # 激活函式
layers.Conv2D(16,kernel_size=3,strides=1), # 第二個卷積層, 16 個 3x3 卷積核
layers.MaxPooling2D(pool_size=2,strides=2), # 高寬各減半的池化層
layers.ReLU(), # 激活函式
layers.Flatten(), # 打平層,方便全連接層處理
layers.Dense(120, activation='relu'), # 全連接層,120 個節點
layers.Dense(84, activation='relu'), # 全連接層,84 節點
layers.Dense(10) # 全連接層,10 個節點
])
# build 一次網路模型,給輸入 X 的形狀,其中 4 為隨意給的 batchsz
network.build(input_shape=(4, 28, 28, 1))
network.summary()

可以看到,卷積層的引數量非常少,主要的引數量集中在全連接層,
我們新建交叉熵損失函式類(沒錯,損失函式也能使用類方式)用于處理分類任務,通過設定 from_logits=True 標志位將 softmax 激活函式實作在損失函式中,不需要手動添加損失函式,提升數值計算穩定性:
# 匯入誤差計算,優化器模塊
from tensorflow.keras import losses, optimizers
# 創建損失函式的類,在實際計算時直接呼叫類實體即可
criteon = losses.CategoricalCrossentropy(from_logits=True)
訓練模型
optimizer = optimizers.Adam()
# 記錄預測正確的數量,總樣本數量
correct, total = 0,0
# 構建梯度記錄環境
for i in range(30):
for x, y in train_db:
with tf.GradientTape() as tape:
# 插入通道維度,=>[b,28,28,1]
x = tf.expand_dims(x,axis=3) # 前向計算,獲得 10 類別的概率分布,[b, 784] => [b, 10]
out = network(x)
# 計算交叉熵損失函式,標量
loss = criteon(y, out)
grads = tape.gradient(loss,network.trainable_variables)
optimizer.apply_gradients(zip(grads,network.trainable_variables))
對模型進行測驗
# 記錄預測正確的數量,總樣本數量
correct, total = 0,0
for x,y in db_test: # 遍歷所有訓練集樣本
# 插入通道維度,=>[b,28,28,1]
x = tf.expand_dims(x,axis=3) # 前向計算,獲得 10 類別的預測分布,[b, 784] => [b, 10]
out = network(x)
# 真實的流程時先經過 softmax,再 argmax
# 但是由于 softmax 不改變元素的大小相對關系,故省去
pred = tf.argmax(out, axis=-1)
y = tf.cast(y, tf.int64)
y = tf.argmax(y,axis = -1)
# 統計預測正確數量
correct += float(tf.reduce_sum(tf.cast(tf.equal(pred, y),tf.float32)))
# 統計預測樣本總數
total += x.shape[0] # 計算準確率
print('test acc:', correct/total)
test acc: 0.9855
2.BatchNorm 層
對資料進行標準化處理:
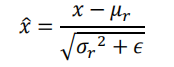
BN 層統計每個通道上面所有資料的𝜇r,𝜎r2,因此𝜇r,𝜎𝐵r是每個通道上所有其他維度的均值和方差,
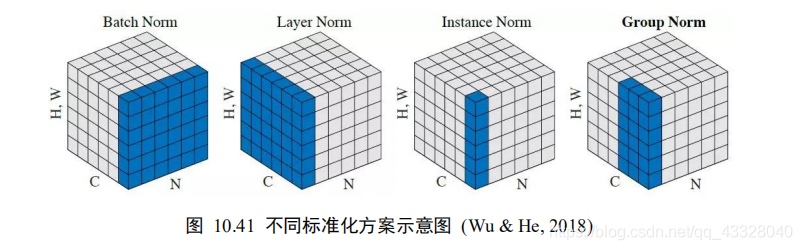
除了在通道上計算均值和方差,還有下面的幾種方式:
?Layer Norm:統計每個樣本的所有特征的均值和方差
? Instance Norm:統計每個樣本的每個通道上特征的均值和方差
? Group Norm:將 c 通道分成若干組,統計每個樣本的通道組內的特征均值和方差
2.1 BN 層實作
在 TensorFlow 中,通過 layers.BatchNormalization() 類可以非常方便地實作 BN 層:
通過設定training 標志位來區分訓練模式還是測驗模式,以 LeNet-5 的網路模型為例,在卷積層后添加 BN 層:
network = Sequential([ # 網路容器
layers.Conv2D(6,kernel_size=3,strides=1),
# 插入 BN 層
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=2,strides=2),
layers.ReLU(),
layers.Conv2D(16,kernel_size=3,strides=1),
# 插入 BN 層
layers.BatchNormalization(),
layers.MaxPooling2D(pool_size=2,strides=2),
layers.ReLU(),
layers.Flatten(),
layers.Dense(120, activation='relu'),
# 此處也可以插入 BN 層
layers.Dense(84, activation='relu'),
# 此處也可以插入 BN 層
layers.Dense(10)
])
在訓練階段,需要設定網路的引數 training=True 以區分 BN 層是訓練還是測驗模型:
with tf.GradientTape() as tape:
# 插入通道維度
x = tf.expand_dims(x,axis=3) # 前向計算,設定計算模式,[b, 784] => [b, 10]
out = network(x, training=True)
在測驗階段,需要設定 training=False,避免 BN 層采用錯誤的行為:
for x,y in db_test: # 遍歷測驗集
# 插入通道維度
x = tf.expand_dims(x,axis=3) # 前向計算,測驗模式
out = network(x, training=False)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers
# 2 images with 4x4 size, 3 channels
# we explicitly enforce the mean and stddev to N(1, 0.5)
x = tf.random.normal([2,4,4,3], mean=1.,stddev=0.5)
net = layers.BatchNormalization(axis=-1, center=True, scale=True,
trainable=True)
out = net(x)
print('forward in test mode:', net.variables)
out = net(x, training=True)
print('forward in train mode(1 step):', net.variables)
for i in range(100):
out = net(x, training=True)
print('forward in train mode(100 steps):', net.variables)
optimizer = optimizers.SGD(lr=1e-2)
for i in range(10):
with tf.GradientTape() as tape:
out = net(x, training=True)
loss = tf.reduce_mean(tf.pow(out,2)) - 1
grads = tape.gradient(loss, net.trainable_variables)
optimizer.apply_gradients(zip(grads, net.trainable_variables))
print('backward(10 steps):', net.variables)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/200724.html
標籤:python
上一篇:ArcGIS python計算長時間序列多個柵格資料的平均值
下一篇:CSS的文本樣式