
- 之前我們介紹了執行緒池的四種拒絕策略,了解了執行緒池引數的含義,那么今天我們來聊聊
Java中常見的幾種執行緒池,以及在jdk7加入的ForkJoin新型執行緒池 - 首先我們列出
Java中的六種執行緒池如下
| 執行緒池名稱 | 描述 |
|---|---|
| FixedThreadPool | 核心執行緒數與最大執行緒數相同 |
| SingleThreadExecutor | 一個執行緒的執行緒池 |
| CachedThreadPool | 核心執行緒為0,最大執行緒數為Integer. MAX_VALUE |
| ScheduledThreadPool | 指定核心執行緒數的定時執行緒池 |
| SingleThreadScheduledExecutor | 單例的定時執行緒池 |
| ForkJoinPool | JDK 7 新加入的一種執行緒池 |
- 在了解集中執行緒池時我們先來熟悉一下主要幾個類的關系,
ThreadPoolExecutor的類圖,以及Executors的主要方法:
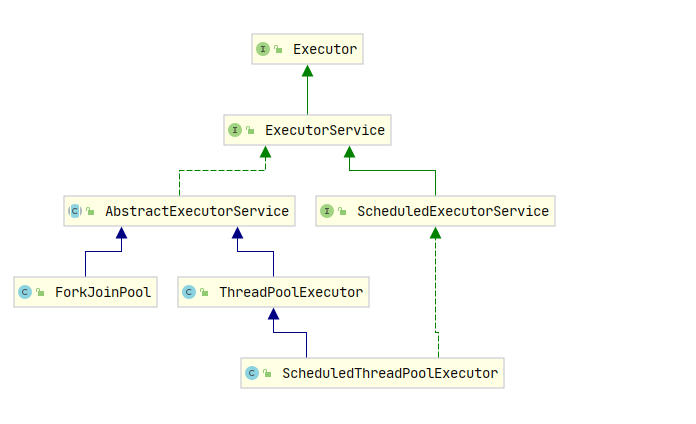
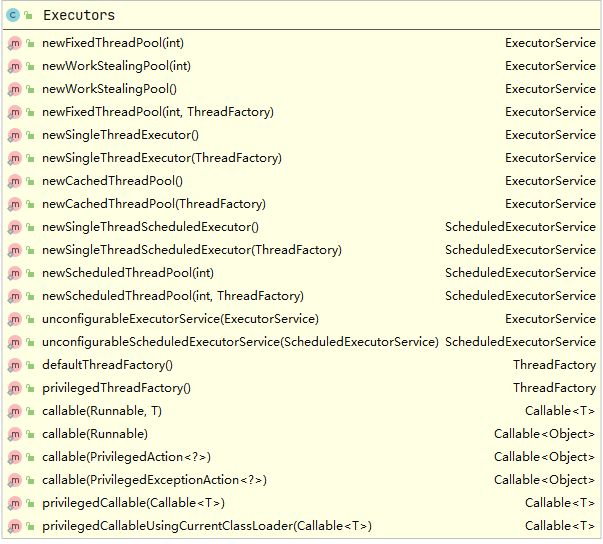
- 上面看到的類圖,方便幫助下面的理解和查看,我們可以看到一個核心類
ExecutorService, 這是我們執行緒池都實作的基類,我們接下來說的都是它的實作類,
FixedThreadPool
FixedThreadPool執行緒池的特點是它的核心執行緒數和最大執行緒數一樣,我們可以看它的實作代碼在Executors#newFixedThreadPool(int)中,如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
我們可以看到方法內創建執行緒呼叫的實際是
ThreadPoolExecutor類,這是執行緒池的核心執行器,傳入的nThread引數作為核心執行緒數和最大執行緒數傳入,佇列采用了一個鏈表結構的有界佇列,
- 這種執行緒池我們可以看作是固定執行緒數的執行緒池,它只有在開始初始化的時候執行緒數會從0開始創建,但是創建好后就不再銷毀,而是全部作為常駐執行緒池,這里如果對執行緒池引數不理解的可以看之前文章 《解釋執行緒池各個引數的含義》,
- 對于這種執行緒池他的第三個和第四個引數是沒意義,它們是空閑執行緒存活時間,這里都是常駐不存在銷毀,當執行緒處理不了時會加入到阻塞佇列,這是一個鏈表結構的有界阻塞佇列,最大長度是Integer. MAX_VALUE
SingleThreadExecutor
SingleThreadExecutor執行緒的特點是它的核心執行緒數和最大執行緒數均為1,我們也可以將其任務是一個單例執行緒池,它的實作代碼是Executors#newSingleThreadExcutor(), 如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
- 上述代碼中我們發現它有一個多載函式,傳入了一個
ThreadFactory的引數,一般在我們開發中會傳入我們自定義的執行緒創建工廠,如果不傳入則會呼叫默認的執行緒工廠 - 我們可以看到它與
FixedThreadPool執行緒池的區別僅僅是核心執行緒數和最大執行緒數改為了1,也就是說不管任務多少,它只會有唯一的一個執行緒去執行 - 如果在執行程序中發生例外等導致執行緒銷毀,執行緒池也會重新創建一個執行緒來執行后續的任務
- 這種執行緒池非常適合所有任務都需要按被提交的順序來執行的場景,是個單執行緒的串行,
CachedThreadPool
cachedThreadPool執行緒池的特點是它的常駐核心執行緒數為0,正如其名字一樣,它所有的縣城都是臨時的創建,關于它的實作在Executors#newCachedThreadPool()中,代碼如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
- 從上述代碼中我們可以看到
CachedThreadPool執行緒池中,最大執行緒數為Integer.MAX_VALUE, 意味著他的執行緒數幾乎可以無限增加, - 因為創建的執行緒都是臨時執行緒,所以他們都會被銷毀,這里空閑 執行緒銷毀時間是60秒,也就是說當執行緒在60秒內沒有任務執行則銷毀
- 這里我們需要注意點,它使用了
SynchronousQueue的一個阻塞佇列來存盤任務,這個佇列是無法存盤的,因為他的容量為0,它只負責對任務的傳遞和中轉,效率會更高,因為核心執行緒都為0,這個佇列如果存盤任務不存在意義,
ScheduledThreadPool
ScheduledThreadPool執行緒池是支持定時或者周期性執行任務,他的創建代碼Executors.newSchedsuledThreadPool(int)中,如下所示:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
- 我們發現這里呼叫了
ScheduledThreadPoolExecutor這個類的建構式,進一步查看發現ScheduledThreadPoolExecutor類是一個繼承了ThreadPoolExecutor的,同時實作了ScheduledExecutorService介面,我們看到它的幾個建構式都是呼叫父類ThreadPoolExecutor的建構式
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
- 從上面代碼我們可以看到和其他執行緒池創建并沒有差異,只是這里的任務佇列是
DelayedWorkQueue關于阻塞丟列我們下篇文章專門說,這里我們先創建一個周期性的執行緒池來看一下
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(5);
// 1. 延遲一定時間執行一次
service.schedule(() ->{
System.out.println("schedule ==> 云棲簡碼-i-code.online");
},2, TimeUnit.SECONDS);
// 2. 按照固定頻率周期執行
service.scheduleAtFixedRate(() ->{
System.out.println("scheduleAtFixedRate ==> 云棲簡碼-i-code.online");
},2,3,TimeUnit.SECONDS);
//3. 按照固定頻率周期執行
service.scheduleWithFixedDelay(() -> {
System.out.println("scheduleWithFixedDelay ==> 云棲簡碼-i-code.online");
},2,5,TimeUnit.SECONDS);
}
- 上面代碼是我們簡單創建了
newScheduledThreadPool,同時演示了里面的三個核心方法,首先看執行的結果:

- 首先我們看第一個方法
schedule, 它有三個引數,第一個引數是執行緒任務,第二個delay表示任務執行延遲時長,第三個unit表示延遲時間的單位,如上面代碼所示就是延遲兩秒后執行任務
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit);
- 第二個方法是
scheduleAtFixedRate如下, 它有四個引數,command引數表示執行的執行緒任務 ,initialDelay引數表示第一次執行的延遲時間,period引數表示第一次執行之后按照多久一次的頻率來執行,最后一個引數是時間單位,如上面案例代碼所示,表示兩秒后執行第一次,之后按每隔三秒執行一次
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
- 第三個方法是
scheduleWithFixedDelay如下,它與上面方法是非常類似的,也是周期性定時執行, 引數含義和上面方法一致,這個方法和scheduleAtFixedRate的區別主要在于時間的起點計時不同
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
scheduleAtFixedRate是以任務開始的時間為時間起點來計時,時間到就執行第二次任務,與任務執行所花費的時間無關;而scheduleWithFixedDelay是以任務執行結束的時間點作為計時的開始,如下所示
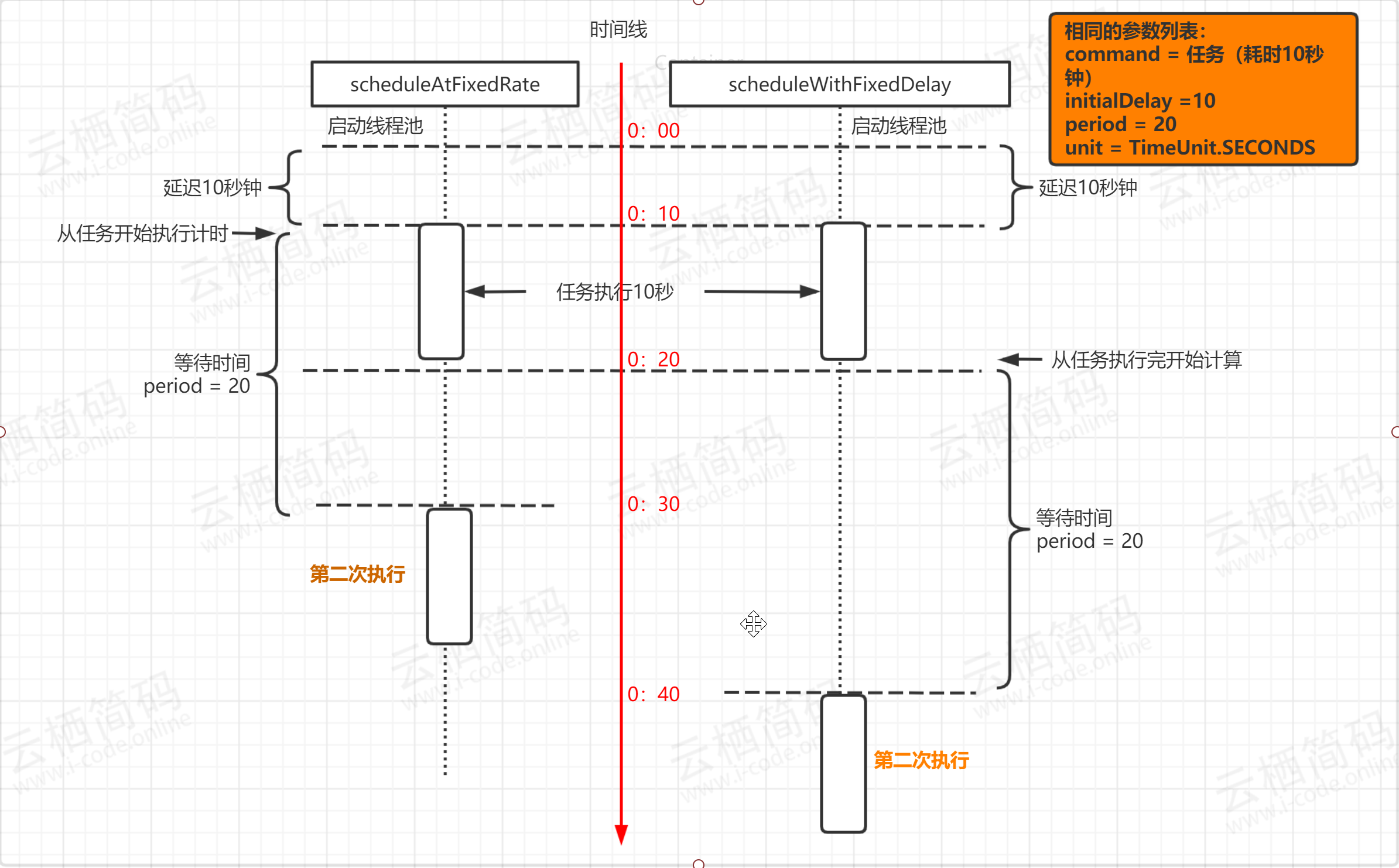
SingleThreadScheduledExecutor
- 它實際和
ScheduledThreadPool執行緒池非常相似,它只是ScheduledThreadPool的一個特例,內部只有一個執行緒,它只是將ScheduledThreadPool的核心執行緒數設定為了 1,如原始碼所示:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
- 上面我們介紹了五種常見的執行緒池,對于這些執行緒池我們可以從核心執行緒數、最大執行緒數、存活時間三個維度進行一個簡單的對比,有利于我們加深對這幾種執行緒池的記憶,
| FixedThreadPool | SingleThreadExecutor | CachedThreadPool | ScheduledThreadPool | SingleThreadScheduledExecutor | |
|---|---|---|---|---|---|
| corePoolSize | 建構式傳入 | 1 | 0 | 建構式傳入 | 1 |
| maxPoolSize | 同corePoolSize | 1 | Integer. MAX_VALUE | Integer. MAX_VALUE | Integer. MAX_VALUE |
| keepAliveTime | 0 | 0 | 60 | 0 | 0 |
ForkJoinPool
ForkJoinPool這是一個在JDK7引入的新新執行緒池,它的主要特點是可以充分利用多核CPU, 可以把一個任務拆分為多個子任務,這些子任務放在不同的處理器上并行執行,當這些子任務執行結束后再把這些結果合并起來,這是一種分治思想,ForkJoinPool也正如它的名字一樣,第一步進行Fork拆分,第二步進行Join合并,我們先來看一下它的類圖結構
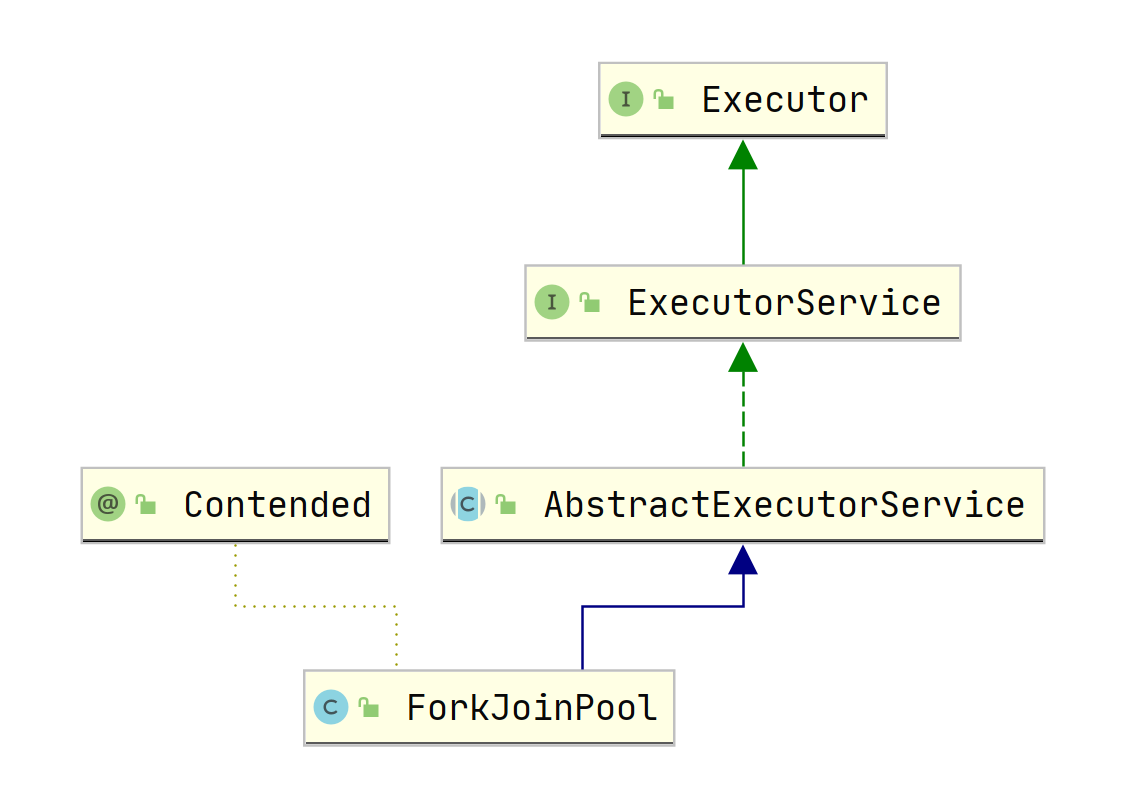
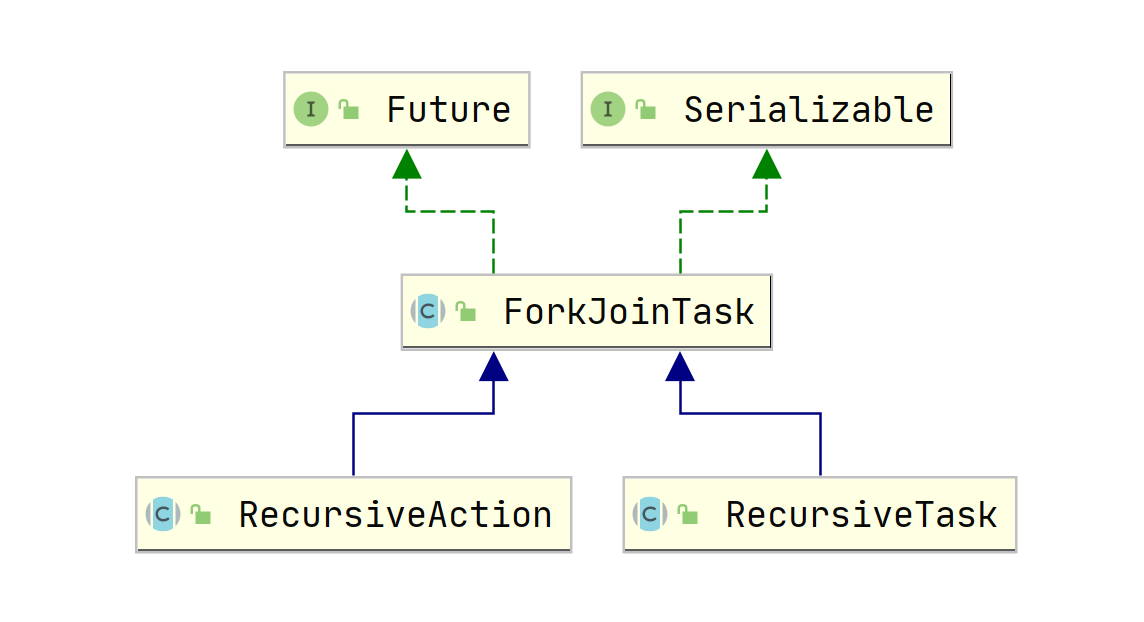
ForkJoinPool的使用也是通過呼叫submit(ForkJoinTask<T> task)或invoke(ForkJoinTask<T> task)方法來執行指定任務了,其中任務的型別是ForkJoinTask類,它代表的是一個可以合并的子任務,他本身是一個抽象類,同時還有兩個常用的抽象子類RecursiveAction和RecursiveTask,其中RecursiveTask表示的是有回傳值型別的任務,而RecursiveAction則表示無回傳值的任務,下面是它們的類圖:
- 下面我們通過一個簡單的代碼先來看一下如何使用
ForkJoinPool執行緒池
/**
* @url: i-code.online
* @author: AnonyStar
* @time: 2020/11/2 10:01
*/
public class ForkJoinApp1 {
/**
目標: 列印0-200以內的數字,進行分段每個間隔為10以上,測驗forkjoin
*/
public static void main(String[] args) {
// 創建執行緒池,
ForkJoinPool joinPool = new ForkJoinPool();
// 創建根任務
SubTask subTask = new SubTask(0,200);
// 提交任務
joinPool.submit(subTask);
//讓執行緒阻塞等待所有任務完成 在進行關閉
try {
joinPool.awaitTermination(2, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
joinPool.shutdown();
}
}
class SubTask extends RecursiveAction {
int startNum;
int endNum;
public SubTask(int startNum,int endNum){
super();
this.startNum = startNum;
this.endNum = endNum;
}
@Override
protected void compute() {
if (endNum - startNum < 10){
// 如果分裂的兩者差值小于10 則不再繼續,直接列印
System.out.println(Thread.currentThread().getName()+": [startNum:"+startNum+",endNum:"+endNum+"]");
}else {
// 取中間值
int middle = (startNum + endNum) / 2;
//創建兩個子任務,以遞回思想,
SubTask subTask = new SubTask(startNum,middle);
SubTask subTask1 = new SubTask(middle,endNum);
//執行任務, fork() 表示異步的開始執行
subTask.fork();
subTask1.fork();
}
}
}
結果:
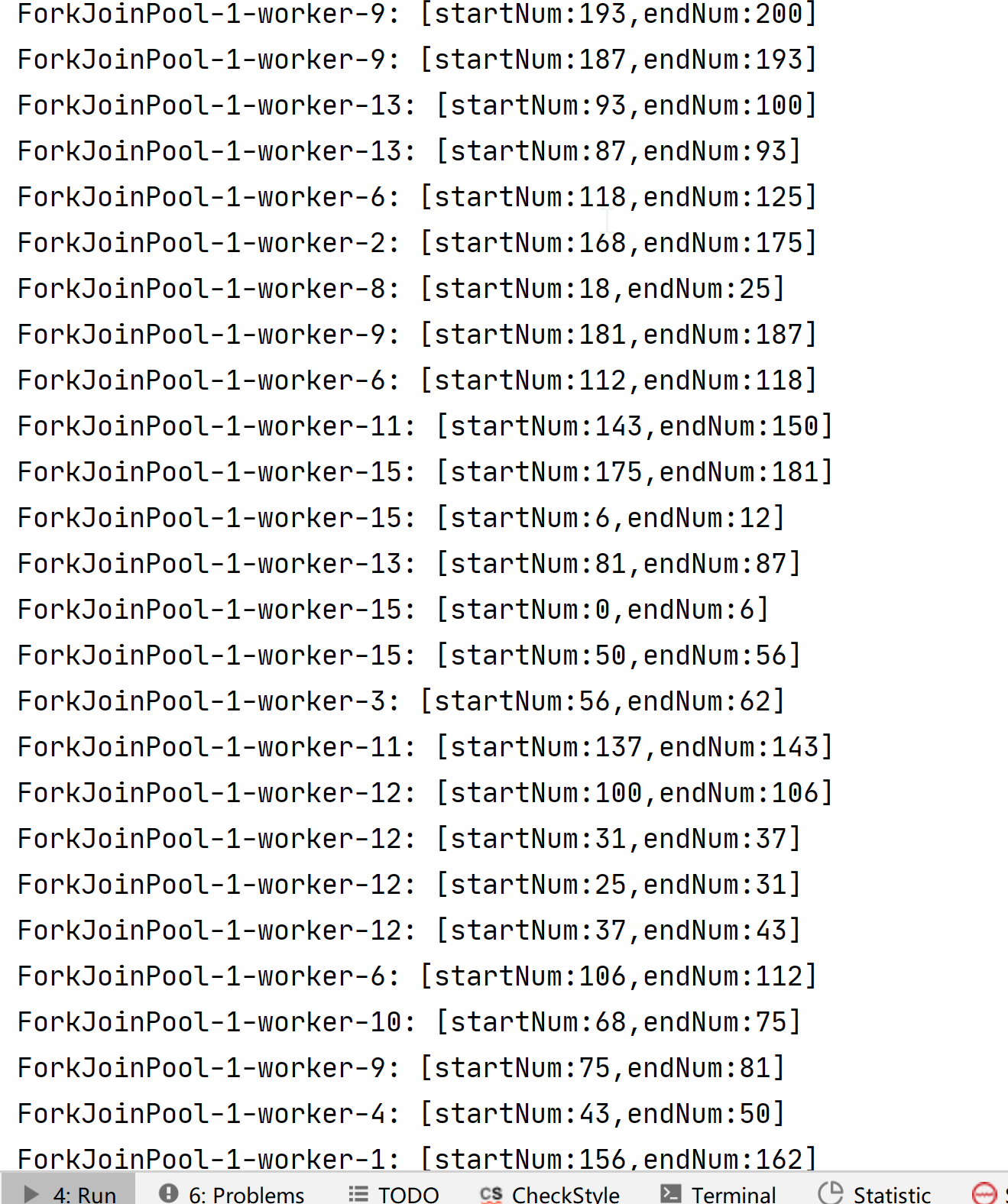
- 從上面的案例我們可以看到我們,創建了很多個執行緒執行,因為我測驗的電腦是12執行緒的,所以這里實際是創建了12個執行緒,也側面說明了充分呼叫了每個處理的執行緒處理能力
- 上面案例其實我們發現很熟悉的味道,那就是以前接觸過的遞回思想,將上面的案例影像化如下,更直觀的看到,
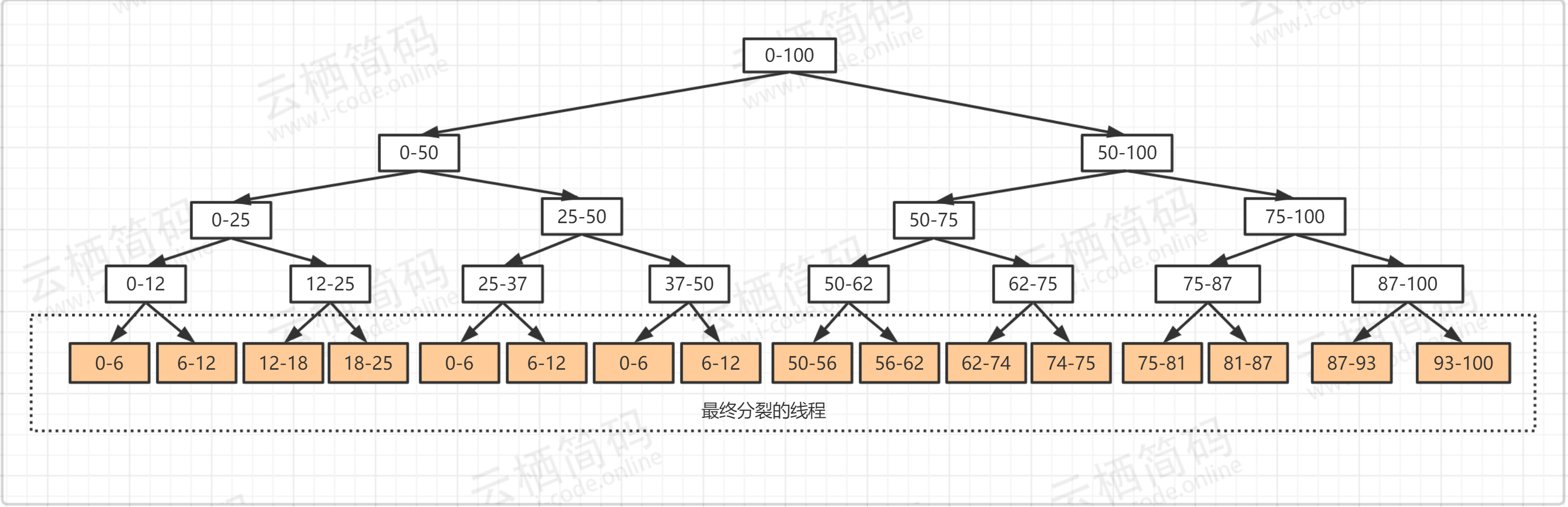
- 上面的例子是無回傳值的案例,下面我們來看一個典型的有回傳值的案例,相信大家都聽過及很熟悉斐波那契數列,這個數列有個特點就是最后一項的結果等于前兩項的和,如:
0,1,1,2,3,5...f(n-2)+f(n-1), 即第0項為0 ,第一項為1,則第二項為0+1=1,以此類推,我們最初的解決方法就是使用遞回來解決,如下計算第n項的數值:
private int num(int num){
if (num <= 1){
return num;
}
num = num(num-1) + num(num -2);
return num;
}
- 從上面簡單代碼中可以看到,當
n<=1時回傳n, 如果n>1則計算前一項的值f1,在計算前兩項的值f2, 再將兩者相加得到結果,這就是典型的遞回問題,也是對應我們的ForkJoin的作業模式,如下所示,根節點產生子任務,子任務再次衍生出子子任務,到最后在進行整合匯聚,得到結果,
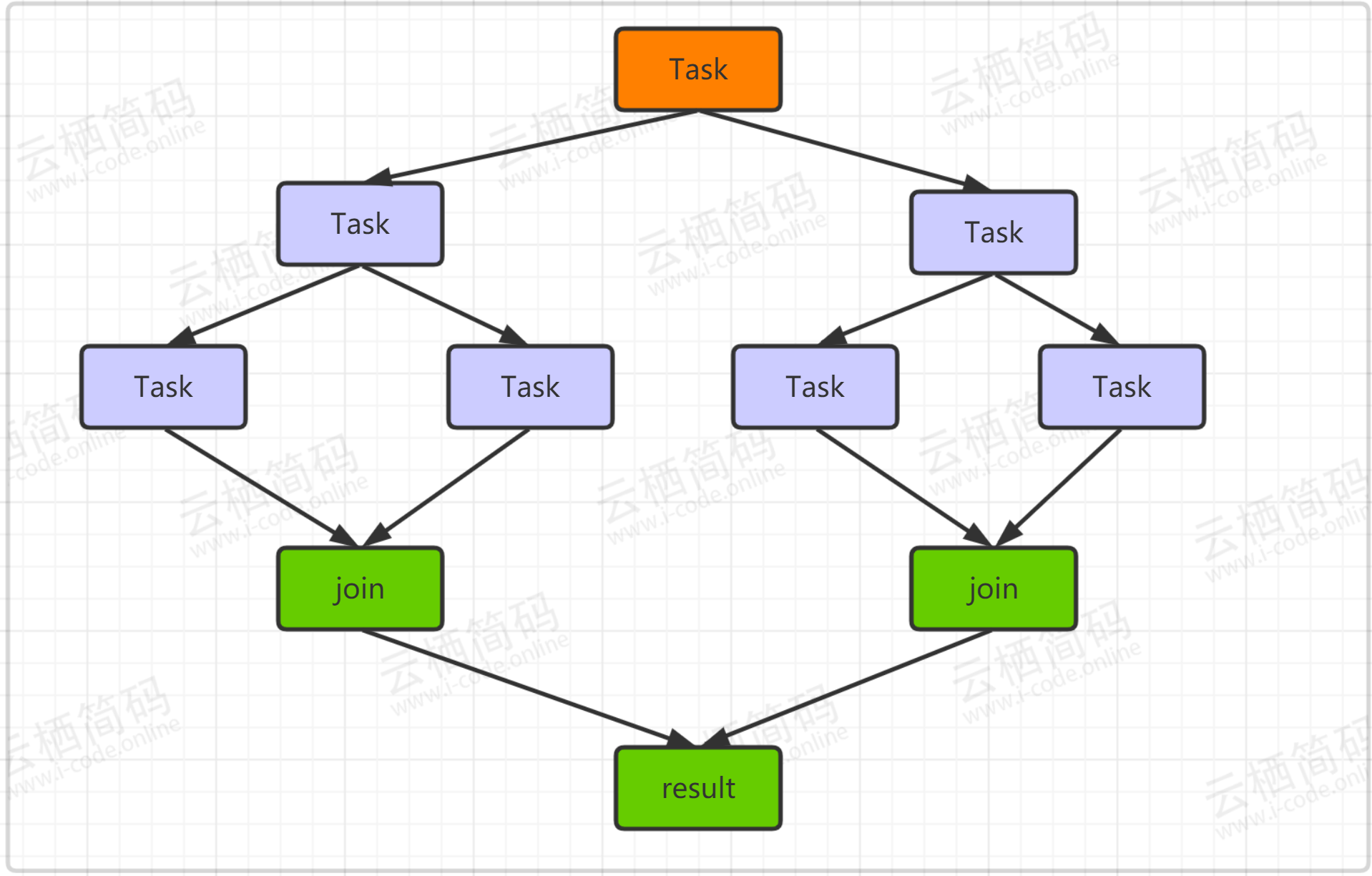
- 我們通過
ForkJoinPool來實作斐波那契數列的計算,如下展示:
/**
* @url: i-code.online
* @author: AnonyStar
* @time: 2020/11/2 10:01
*/
public class ForkJoinApp3 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool pool = new ForkJoinPool();
//計算第二是項的數值
final ForkJoinTask<Integer> submit = pool.submit(new Fibonacci(20));
// 獲取結果,這里獲取的就是異步任務的最終結果
System.out.println(submit.get());
}
}
class Fibonacci extends RecursiveTask<Integer>{
int num;
public Fibonacci(int num){
this.num = num;
}
@Override
protected Integer compute() {
if (num <= 1) return num;
//創建子任務
Fibonacci subTask1 = new Fibonacci(num - 1);
Fibonacci subTask2 = new Fibonacci(num - 2);
// 執行子任務
subTask1.fork();
subTask2.fork();
//獲取前兩項的結果來計算和
return subTask1.join()+subTask2.join();
}
}
- 通過
ForkJoinPool可以極大的發揮多核處理器的優勢,尤其非常適合用于遞回的場景,例如樹的遍歷、最優路徑搜索等場景, - 上面說的是
ForkJoinPool的使用上的,下面我們來說一下其內部的構造,對于我們前面說的幾種執行緒池來說,它們都是里面只有一個佇列,所有的執行緒共享一個,但是在ForkJoinPool中,其內部有一個共享的任務佇列,除此之外每個執行緒都有一個對應的雙端佇列Deque, 當一個執行緒中任務被Fork分裂了,那么分裂出來的子任務就會放入到對應的執行緒自己的Deque中,而不是放入公共佇列,這樣對于每個執行緒來說成本會降低很多,可以直接從自己執行緒的佇列中獲取任務而不需要去公共佇列中爭奪,有效的減少了執行緒間的資源競爭和切換,
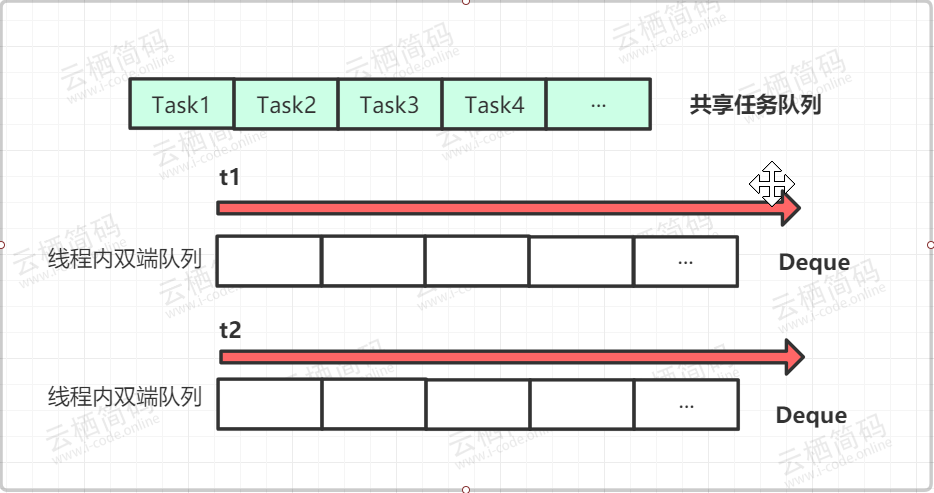
- 有一種情況,當執行緒有多個如
t1,t2,t3...,在某一段時間執行緒t1的任務特別繁重,分裂了數十個子任務,但是執行緒t0此時卻無事可做,它自己的deque佇列為空,這時為了提高效率,t0就會想辦法幫助t1執行任務,這就是“work-stealing”的含義, - 雙端佇列
deque中,執行緒t1獲取任務的邏輯是后進先出,也就是LIFO(Last In Frist Out),而執行緒t0在“steal”偷執行緒t1的deque中的任務的邏輯是先進先出,也就是FIFO(Fast In Frist Out),如圖所示,圖中很好的描述了兩個執行緒使用雙端佇列分別獲取任務的情景,你可以看到,使用 “work-stealing” 演算法和雙端佇列很好地平衡了各執行緒的負載,
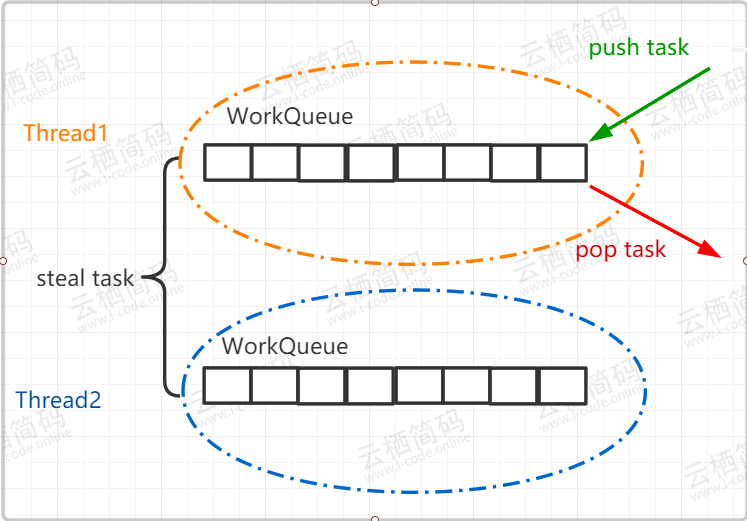
本文由AnonyStar 發布,可轉載但需宣告原文出處,
歡迎關注微信公賬號 :云棲簡碼 獲取更多優質文章
更多文章關注筆者博客 :云棲簡碼 i-code.online
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/200876.html
標籤:其他
上一篇:030_Java方法
下一篇:040_陣列