QQ群1070535031
跟隨上一篇的思路,本篇我們來實作整個流程,
實驗需求
跟隨本文進行學習和實驗,需要前面博文中的環境,以及提取出來的UK資料,(學習分享——基于深度學習的NILM負荷分解(二)電器資料提取)
本文的代碼思路在上一篇,本文著重介紹代碼實作相關,思路方面看一下(學習分享——基于深度學習的NILM負荷分解(三)深度學習處理,基礎思路)
實驗環境:
pycharm,python 3.6+,keras庫,numpy庫,matplotlib庫
以及UKData,
定義全域引數
首先參考所有需要的庫,如下:
import numpy as np
import os
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
from keras.models import load_model
然后是定義一些全域引數:
# 全域引數定義
dimension = 5 #電器的個數
#電器id定義
fridge_id = 0
tv_id = 1
kettle_id = 2
microwave_id = 3
washerdryer_id = 4
#電器開啟狀態閾值
fridge_threshold = 20
tv_threshold = 20
kettle_threshold = 20
microwave_threshold = 10
washerdryer_threshold = 0
#消噪音閾值
air_threshold = 5
挨個介紹一下上面的引數
dimension :是我們訓練的電器的類別個數,5個是當前初步試驗所設,
電器id:是我們選擇出的五種電器的自增長id,(這里我們選擇:冰箱,電視,水壺微波爐和洗衣烘干機)
電器開啟狀態閾值:這個的作用是屏蔽一些干擾,即,低于該值時認為電器不開啟,
消噪音閾值:總功的噪音去燥,將改值以下認為是噪音,忽略,
讀取電器資料
fridge_data = np.load('UKData/Fridge freezer0.npy')
print(fridge_data.shape)
fridge_data = fridge_data[:1600000]
print(fridge_data.shape)
fridge_data = np.where(fridge_data > air_threshold,fridge_data,0)
television_data = np.load('UKData/Television0.npy')
print(television_data.shape)
television_data = television_data[:1600000]
print(television_data.shape)
television_data = np.where(television_data > air_threshold, television_data,0)
kettle_data = np.load('UKData/Kettle0.npy')
print(kettle_data.shape)
kettle_data = kettle_data[0:1600000]
print(kettle_data.mean)
kettle_data = np.where(kettle_data > air_threshold, kettle_data,0)
microwave_data = np.load('UKData/Microwave0.npy')
print(microwave_data.shape)
microwave_data = microwave_data[:1600000]
print(microwave_data.shape)
microwave_data = np.where(microwave_data > air_threshold, microwave_data,0)
washerdryer_data = np.load('UKData/Washer dryer0.npy')
print(washerdryer_data.shape)
washerdryer_data = washerdryer_data[:1600000]
print(washerdryer_data.shape)
washerdryer_data = np.where(washerdryer_data > air_threshold, washerdryer_data,0)
上面的代碼,直接從之前我們讀取出來的各個電器中,選擇我們訓練用的電器,讀取出來,并取出相同長度(1600000)的資料(有用功),同時將低于閾值air_threshold的進行取0操作,目的是去燥,
制作標簽
def create_label(data, application_id, power_threshold, dimension):
labels = np.zeros((len(data), dimension))
for i, value in enumerate(data):
if value[0] > power_threshold:
labels[i,application_id] = 1
return labels
上面的方法,輸入為資料,電器id,開啟狀態閾值,電器個數,
輸出為,電器個數長度的一維陣列,某時刻,對應電器開啟時,對應id的位置為1,關閉時為0.
data是每一個時刻的負荷,label是每一個時刻的電器開啟狀態,
舉例:label默認每一時刻是 [0,0,0,0,0],假如某時刻id為1的電器開啟,則該時刻的label為 [0,1,0,0,0]
下面的代碼是分別生成五個電器,每個電器的label
fridge_labels = create_label(fridge_data,fridge_id,fridge_threshold,dimension)
tv_labels = create_label(television_data,tv_id,tv_threshold,dimension)
kettle_labels = create_label(kettle_data,kettle_id,kettle_threshold,dimension)
microwave_labels = create_label(microwave_data,microwave_id,microwave_threshold,dimension)
washerdryer_labels = create_label(washerdryer_data,washerdryer_id,washerdryer_threshold,dimension)
組合資料與標準化
我們將五個電器的資料進行整合,有用功直接加在一起,變成每一個時刻有用功的和,
label標簽也組合在一起,因為上面生成的標簽,每個電器對應一列,所以直接相加即可,
sum_label = fridge_labels + tv_labels + kettle_labels + microwave_labels + washerdryer_labels
sum_data_num = fridge_data + television_data + kettle_data + microwave_data + washerdryer_data
然后可以畫個圖看一下,我們的label
#畫圖查看資料
epochs = range(1,len(sum_label[:,0])+1)
plt.plot(epochs,sum_label[:,0],label='fridge_labels')
plt.plot(epochs,sum_label[:,1],label='tv_labels')
plt.plot(epochs,sum_label[:,2],label='kettle_labels')
plt.plot(epochs,sum_label[:,3],label='microwave_labels')
plt.plot(epochs,sum_label[:,4],label='washerdryer_labels')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
畫出來是這樣的,每個顏色就是開啟
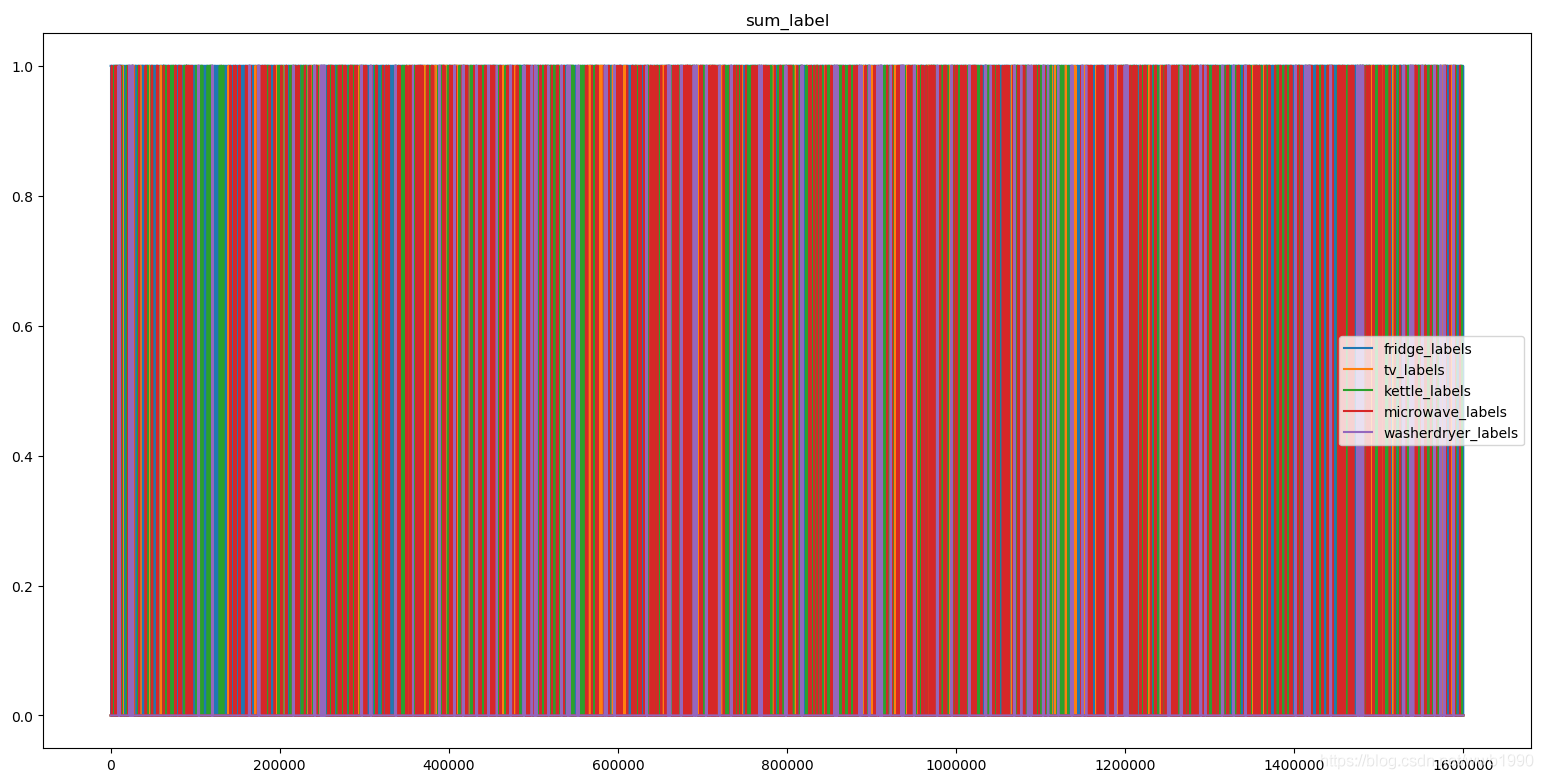
考慮到訓練效率和效果,我們對資料進行歸一化,如下:
mean = sum_data_num[:1600000].mean(axis=0)
sum_data = sum_data_num - mean
std = sum_data[:1600000].std(axis=0)
sum_data /= std
迭代器
我們只用了一個房間的16w的資料,但所用的資料量還是比較大的,為了之后更大量資料考慮,我們使用迭代器來進行資料輸入,以減小記憶體的使用,每次迭代器來取資料輸入訓練迭代,
def generator(data, label, lookback, delay, min_index, max_index, shuffle=False, batch_size=128, step=1):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),dimension))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = label[rows[j] + delay]
yield samples, targets
這一塊邏輯可能有點復雜,慢慢看,
引數:
data:資料,
label:標簽,
lookback:上一節提到的視窗大小,這里是往回看的視窗,
delay:預測后面幾幀的結果(這里我們默認為0,因為是預測分解當前幀的結果,不需要往未來看)
min_index:從資料的哪一幀開始看
max_index:從資料的哪一幀結束
shuffle:是否隨機
batch_size:迭代中每一個批量的個數
step:每取一次資料,向后跳幾幀
這個方法的意思,就是取總的資料中的min_index到max_index這段范圍中的資料,每個批量是batch_size,每次往回取lookback視窗大小的資料,取完一次向后跳step個再取下一次,shuffle為是否隨機開始取的位置,
delay可以忽略,
實在看不懂的,可以群里面私聊我,或者等我開直播講,
拆分資料迭代器
首先定義一些迭代器的超參
分別是視窗大小,向后跳的步伐,預測當前幀(delay=0),批量大小
lookback = 20
step = 1
delay = 0
batch_size = 128
具體每個引數的大小設定,我之后的文章,分析各個超參的作用和影響的時候,在做具體講解,
然后就是定義各個迭代器:
train_gen = generator(sum_data,
sum_label,
lookback=lookback,
delay=delay,
min_index=0,
max_index=800000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(sum_data,
sum_label,
lookback=lookback,
delay=delay,
min_index=800001,
max_index=1200000,
step=step,
batch_size=batch_size)
test_gen = generator(sum_data,
sum_label,
lookback=lookback,
delay=delay,
min_index=1200001,
max_index=None,
step=step,
batch_size=batch_size)
一共是160w幀資料,我用取前80w作為訓練,80-120w作為驗證,120-160w作為測驗,
訓練集資料使用隨機處理,
然后計算一下每次迭代運算批數
train_steps = 800000 // batch_size
val_steps = (1200000 - 800001 -lookback) // batch_size
test_steps = (len(sum_data) - 1200001 -lookback) // batch_size
建立簡單網路來測驗
#雙向回圈網路
model = Sequential()
model.add(layers.Bidirectional(
layers.GRU(32,dropout=0.1), input_shape=(None,sum_data.shape[-1])))
model.add(layers.Dense(dimension,activation='sigmoid'))
model.compile(optimizer=RMSprop(), loss='binary_crossentropy',metrics=['acc'])
history = model.fit_generator(train_gen,
steps_per_epoch=train_steps,
epochs=2,
validation_data=val_gen,
validation_steps=val_steps)
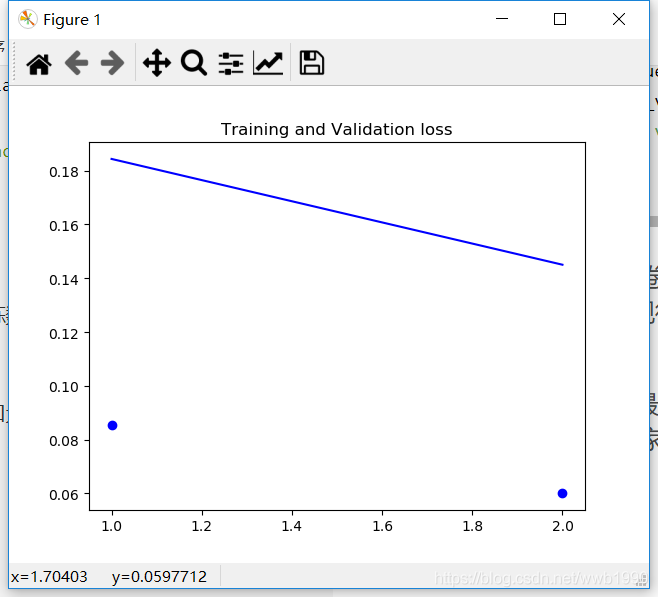
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
# plt.legend()
plt.show()
plt.clf() #清空圖表
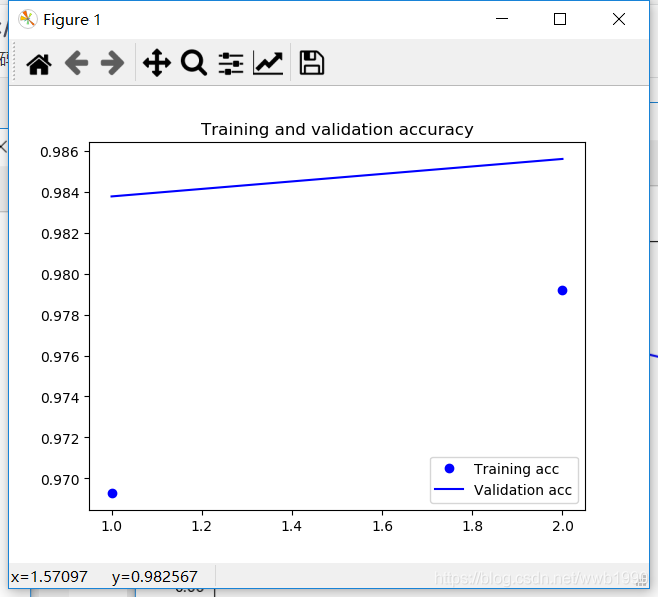
acc_values = history.history['acc']
val_acc_values = history.history['val_acc']
plt.plot(epochs,acc_values,'bo',label='Training acc') #bo是藍色圓點
plt.plot(epochs,val_acc_values,'b',label='Validation acc') #b是藍色實線
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
我這里使用的是keras的方式來做測驗,雙向GRU,鏈接一層全連接輸出,
然后設定一下引數,優化器,以及輸出,迭代2次,
訓練結束我并沒有存模型,因為上面這個網路只是測驗一下,并不是我們既定的完整網路結構,
可以跑一下,看看上面的流程有沒有問題,
跑完會繪制出兩個圖,一個是loss,一個是acc,
運行程序中如下:
靜靜等待2次迭代,
可以看到兩次迭代,loss在下降收斂,準確率acc在上升,看驗證acc會體現訓練中的模型的魯棒性,
建立網路進行訓練
下面我提供我進行了一系列驗證后,較優質的網路結構,供參考,
不過希望同學們,自行研究和實踐各種網路結構的組合,包括各種超參的調整,
例如全連接網路,卷積網路,回圈網路,以及上述網路的各種組合方式,
只有自己不斷嘗試,積累經驗,才能設計和訓練出更好的模型,
回圈網路+一維卷積
model = Sequential()
model.add(layers.Conv1D(32, 5, activation='relu', input_shape=(None,sum_data.shape[-1])))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32, 5, activation='relu'))
model.add(layers.LSTM(32, dropout=0.1))
# model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(dimension,activation='sigmoid'))
model.compile(optimizer=RMSprop(), loss='binary_crossentropy',metrics=['acc'])
history = model.fit_generator(train_gen,
steps_per_epoch=train_steps,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
# model.save('model.h5')
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
# plt.legend()
plt.show()
plt.clf() #清空圖表
acc_values = history.history['acc']
val_acc_values = history.history['val_acc']
plt.plot(epochs,acc_values,'bo',label='Training acc') #bo是藍色圓點
plt.plot(epochs,val_acc_values,'b',label='Validation acc') #b是藍色實線
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
我上述這個模型:一維卷積作用為提煉資料,LSTM(或雙向LSTM)來學習變化規律,全連接層輸出結果,
超參(例如每層的大小,卷積核,視窗大小等等等)和層數(可以兩層lstm,可以最后兩層全連接等地的的) 各種組合,需要嘗試,歡迎大家來群里共同探討實驗結果,
測驗集
最后跑測驗集,進行在未參與訓練的資料中進行預測,
測驗集測驗
test_loss, test_acc = model.evaluate_generator(test_gen,steps=test_steps)
print('test acc : ', test_acc)
有不懂的,或者想法問題,可以留言我,
或者QQ群1070535031
對于代碼中的很多引數和用法,沒有詳細描述,后面我單獨在寫一篇來詳說吧,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/200987.html
標籤:java
上一篇:Python入門基礎語法知識1