目錄
- 前言
- 類簽名
- 泛型
- Serializable和Cloneable
- Deque
- List和AbstractList
- RandomAccess介面(沒實作)
- 變數
- 建構式
- 常用方法
- List體系下的方法:
- add(E e)
- linkLast(E e)方法
- 雙向鏈表的基本形式
- 對于空鏈表的添加
- 對于非空鏈表的添加
- add(int index, E element)
- node(index)
- linkBefore
- 頭結點處添加:
- 中間位置添加
- get(int index)
- add(E e)
- Deque體系下的方法:
- 作為佇列
- 作為堆疊
- List體系下的方法:
- 總結
前言
本文基于jdk1.8
書接上回,在簡單介紹ArrayList的時候,提到了ArrayList實作了RandomAccess介面,擁有隨機訪問的能力,當時說到了這個介面配合LinkedList理解更容易,今天就來還愿了,開始閱讀LinkedList,
LinkedList也算我們比較常用的幾個集合之一了,對普通程式員來說,
List list1 = new ArrayList()
List list2 = new LinkedList(),
該怎么選擇?
其實二者最大的區別在于實作方式的不同,只看名稱我們也能知道, ArrayList基于陣列,而LinkedList基于鏈表,所以關鍵在于陣列和鏈表有啥區別,
說到這,是不是又說明了一個很重要的道理,基礎,基礎,基礎,如果想成為一個真正的程式員,不管你是科班還是半路出家,都要下功夫夯實基礎,
說回正題,ArrayList基于陣列,查找快(按索引查找),增刪慢;LinkedList基于鏈表,增刪快,查找慢,但這只是相對的,僅僅知道這兩點,遠遠不夠,所以,繼續往下看,
類簽名
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
鑒于前一篇有很多遺漏,這里多說明一下:
泛型
集合類在1.5開始的版本中都采用了泛型,也就是
不用泛型,List list1 = new LinkedList();此時默認型別是Object,也就是可以添加任意型別元素,在取出元素時,就需要強制型別轉換,增加了出錯幾率,
使用泛型,List
因為我們使用集合絕大部分情況都是希望存盤同一種型別,所以使用泛型(提前宣告型別)很重要,這里也體現了一種思想:錯誤越早暴露越好,
Serializable和Cloneable
實作Cloneable, Serializable介面,具有克隆和序列化的能力,
Deque
實作了Deque介面, 而Deque介面又繼承了Queue介面,這也意味著LinkedList可以當佇列使用,實作“先進先出”,
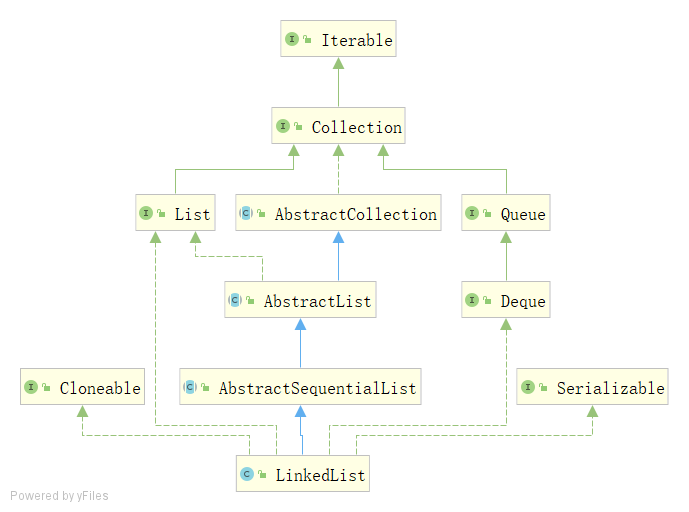
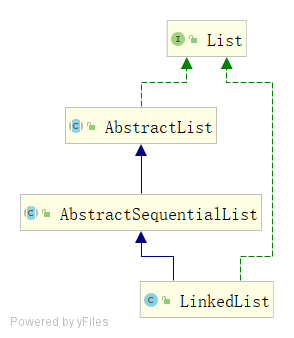
List和AbstractList
在上一篇文章中,有一個細節沒有說到,可能很多人也有疑問, 為啥抽象類AbstractList已經實作了List介面,ArrayList在繼承AbstractList的同時還要再次實作List介面?換到今天的主角,LinkedList繼承了AbstractSequentialList,而AbstractSequentialList繼承了AbstractList,為啥LinkedList還要單獨實作List介面?
在Stack Overflow上看到兩個回答:
一位網友說問過了設計這個類的作者本人,作者本人表示這是當時設計時的一個缺陷,就一直遺留下來了,(當然,我個人覺得這個說法有待考證),
第二位網友舉例表明了不直接再次實作List介面,使用代理時可能會出現意想不到的結果,(從實際的角度看有道理,但是細想之下集合類在jdk1.2已經出現,代理類出現在 1.3,邏輯上有點疑問,)
我個人的理解:
大神在設計集合類的時候充分考慮到了將來優化時的情況,
具體來講,這里主要在于如何理解介面和抽象類的區別,尤其是在java8之前,介面是一種規范,方便規劃體系,抽象類已經有部分實作,更多的是幫助我們減少重復代碼,換言之, 這里的抽象類就相當于一個工具類,只不過恰好實作了List介面,而且鑒于java單繼承,抽象類有被替換的可能,
在面向介面編程的程序中,List list= new LinkedList();如果將來LinkedList有了更好的實作,不再繼承AbstractSequentialList抽象類,由于本身已經直接實作了List介面,只要內部實作符合邏輯,上述舊代碼不會有問題,相反,如果不實作List,去除繼承AbstractSequentialList抽象類,上述舊代碼就無法編譯,也就無法“向下兼容”,
RandomAccess介面(沒實作)
LinkedList并沒有實作RandomAccess介面,實作這個介面的是ArrayList,之所以放在這里是為了對比,
注意,這里說的隨機訪問的能力指的是根據索引訪問,也就是list介面定義的E get(int index)方法,同時意味著ArrayList和LinkedList都必須實作這個方法,
回到問題的本質,為啥基于陣列的ArrayList能隨機訪問,而基于鏈表的LinkedList不具備隨機訪問的能力呢?
還是最基礎的知識:陣列是一塊連續的記憶體,每個元素分配固定大小,很容易定位到指定索引,而鏈表每個節點除了資料還有指向下一個節點的指標,記憶體分配不一定連續,要想知道某一個索引上的值,只能從頭開始(或者從尾)一個一個遍歷,
RandomAccess介面是一個標記介面,沒有任何方法,唯一的作用就是使用instanceof判斷一個實作集合是否具有隨機訪問的能力,
List list1 = new LinkedList();
if (list1 instanceof RandomAccess) {
//...
}
可能看到這里還是不大明白,不要緊,這個問題的關鍵其實就是ArrayList和LinkedList對List介面中get方法實作的區別,后文會專門講到,
變數
//實際存盤元素數量
transient int size = 0;
/**
* 指向頭節點,頭結點不存在指向上一節點的參考
*
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* 指向尾節點,尾節點不存在指向下一節點的參考
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
//節點型別,包含存盤的元素和分別指向下一個和上一個節點的指標
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
注意這里的節點型別,可以看出,LinkedList實作基于雙向鏈表,為啥用不直接用單向鏈表一鏈到底呢?最主要的原因是為了查找效率,前面說到鏈表的查找效率比較低,如果是單向鏈表,按索引查找時,不管索引處于哪個位置,只能從頭開始,平均需要N次;若是雙向鏈表,先判斷索引處于前半部分還是后半部分,再決定從頭開始還是從尾開始,平均需要N/2次,當然,雙向鏈表的缺點就是需要的存盤空間變大,這從另一個方面體現了空間換時間的思想,
上述兩個變數,first和last,其本質是指向物件的參考,和Student s=new Student()中的s沒有區別,只不過first一定指向鏈表頭節點,last一定指向鏈表尾節點,起到標記作用,讓我們能夠隨時從頭或者從尾開始遍歷,
建構式
//空參構造
public LinkedList() {
}
//通過指定集合構造LinkedList, 呼叫addAll方法
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
常用方法
常用方法比較多(多到一張圖截不下),這里主要分兩類,一類是List體系,一類是Deque體系.
List體系下的方法:
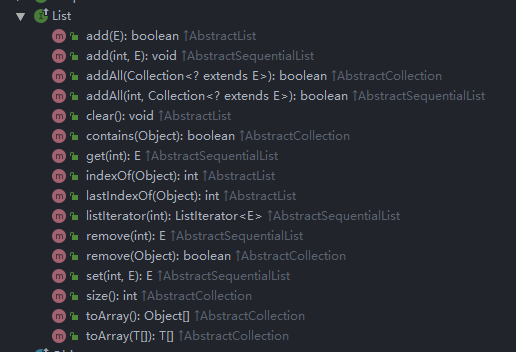
這里主要看兩個,add,get
add(E e)
添加元素到鏈表末尾,成功則回傳true
//添加元素到鏈表末尾,成功則回傳true
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
//1.復制一個指向尾節點的參考l
final Node<E> l = last;
//2.將待添加元素構造為一個節點,prev指向尾節點
final Node<E> newNode = new Node<>(l, e, null);
//3.last指向新構造的節點
last = newNode
//4.如果最初鏈表為空,則將first指向新節點
if (l == null)
first = newNode;
//5.最初鏈表不為空,則將添加前最后元素的next指向新節點
else
l.next = newNode;
//存盤的元素數量+1
size++;
//修改次數+1
modCount++;
}
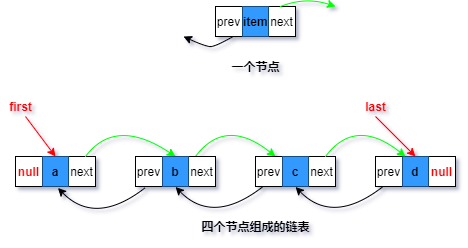
關鍵在于linkLast(E e)方法,分兩種情況,最初是空鏈表添加元素和最初為非空鏈表添加,
這里涉及到的知識很基礎,還是鏈表的基本操作,但是單純用語言很難描述清楚,所以畫個簡圖表示一下(第一次畫圖,沒法盡善盡美,將就一下吧)
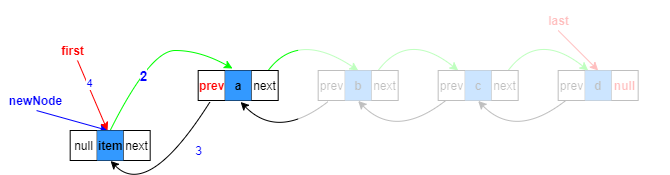
linkLast(E e)方法
雙向鏈表的基本形式
對于空鏈表的添加
對應linkLast(E e)方法注釋1、2、3、4
空鏈表,沒有節點,意味著first和last都指向null
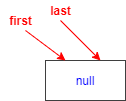
1.復制一個指向尾節點的參考l(藍色部分)
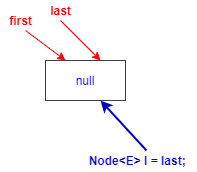
此時復制的參考l本質也指向了null
2.將待添加元素構造為一個節點newNode,prev指向l,也就是null
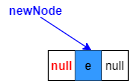
3.last指向新構造的節點(紅色部分)
4.最初鏈表為空,將first指向新節點
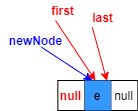
此時,first和last均指向唯一非空節點,當然參考newNode依然存在,但是已經沒有意義,
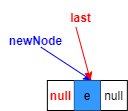
對于非空鏈表的添加
對應linkLast(E e)方法注釋1、2、3、5
1.復制一個指向尾節點的參考l(藍色部分)
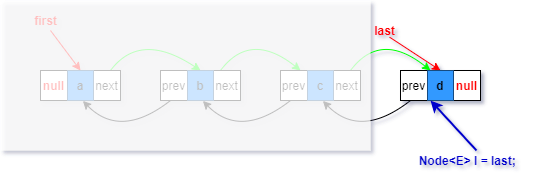
2.將待添加元素構造為一個節點newNode,prev指向尾節點(藍色部分)
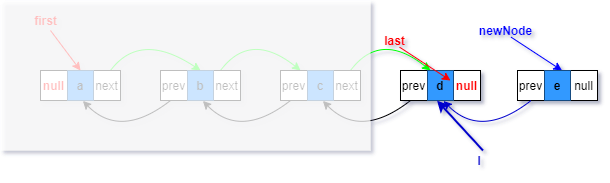
3.last指向新構造的節點(紅色部分)
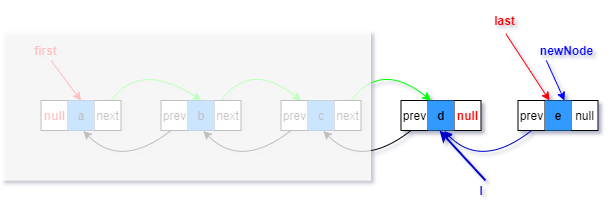
5.將添加前最后元素的next指向新節點(綠色部分)
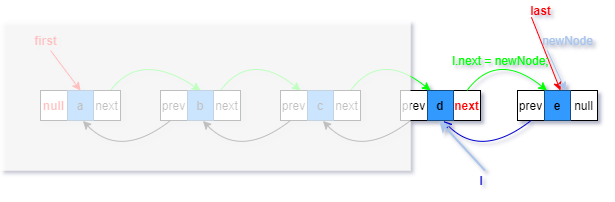
此時,參考newNode和l參考依然存在,但是已經沒有意義,
add(int index, E element)
將元素添加到指定位置
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
可以看出,該方法首先檢查指定索引是否符合規則,也就是在index >= 0 且 index <= size;
如果index==size,則相當于直接在鏈表尾部插入,直接呼叫linkLast方法;
以上不滿足,呼叫linkBefore方法,而linkBefore中呼叫了node(index),
node(index)
node(index)作用是回傳指定索引的節點,這里用到了我們前面說到的一個知識,先判斷索引在前半部分還是在后半部分,再決定從頭還是從尾開始遍歷,
Node<E> node(int index) {
// assert isElementIndex(index);
//如果索引在前半部分,則從頭結點開始往后遍歷
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//如果索引在后半部分,則從尾向前遍歷
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
linkBefore
回過頭來看linkBefore,引數分別為待插入的元素,以及指定位置的節點
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//1.復制指向目標位置的上一個節點參考
final Node<E> pred = succ.prev;
//2.構造新節點,prev指向目標位置的上一個節點,next指向原來目標位置節點
final Node<E> newNode = new Node<>(pred, e, succ);
//3.原來節點prev指向新節點
succ.prev = newNode;
//4.如果插在頭結點位置,則first指向新節點
if (pred == null)
first = newNode;
//5.非頭節點,目標位置上一節點的next指向新節點
else
pred.next = newNode;
size++;
modCount++;
}
上述程序可以看出,關鍵程序在于linkBefore方法,我們同樣畫圖表示:
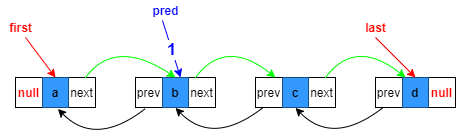
頭結點處添加:
1.復制指向目標位置的上一個節點參考
Node<E> pred = succ.prev;
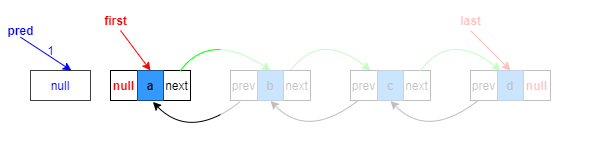
本質是指向null
2.構造新節點,prev指向目標位置的上一個節點,next指向原來目標位置節點
Node<E> newNode = new Node<>(pred, e, succ);
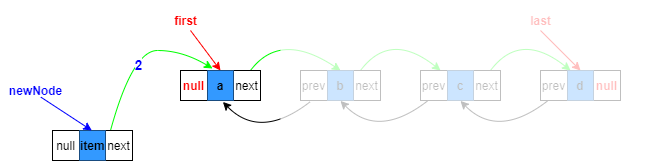
3.目標節點的prev指向待添加新節點
succ.prev = newNode;
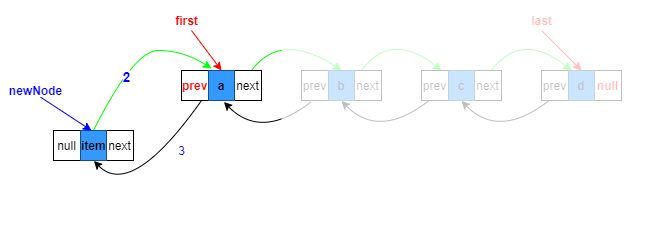
4.first指向新節點
first = newNode;
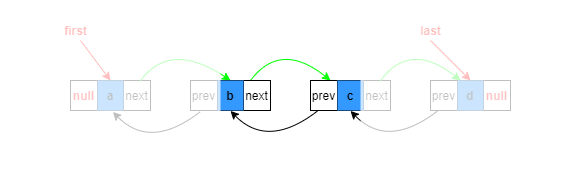
中間位置添加
如圖,假設指定添加到第三個節點,即index=2,則第二個和第三個節點之間必須有斷開的程序,
1.復制指向目標位置的上一個節點參考,也就是第二個節點
Node<E> pred = succ.prev;
2.構造新節點,prev指向復制的上一個節點,next指向原來目標位置上的節點
Node<E> newNode = new Node<>(pred, e, succ);
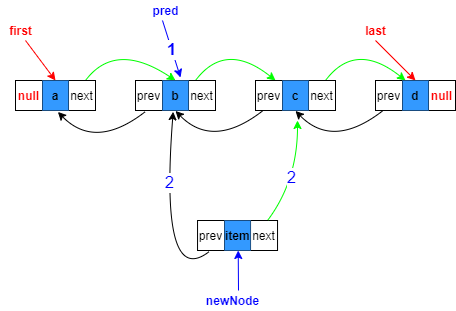
3.目標節點的prev指向待添加新節點
succ.prev = newNode;
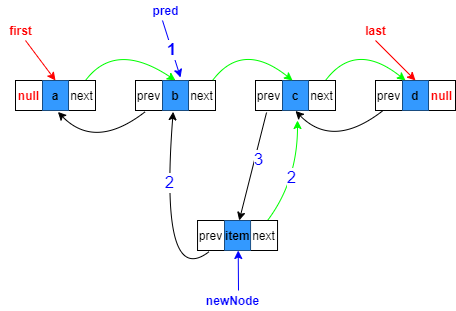
5.目標位置上一節點的next指向新節點
pred.next = newNode;
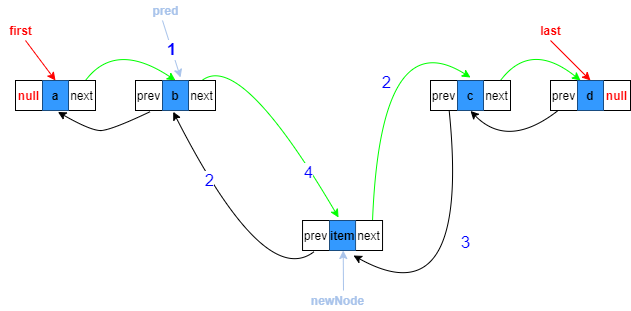
get(int index)
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
get方法是按索引獲取元素,本質呼叫node(index),上一部分已經提到了這個方法,雖然雙向鏈表在一定程度上提高了效率,由N減少到N/2,但本質上時間復雜度還是N的常數倍,所以輕易不要用這個方法,在需要隨機訪問的時候應當使用ArrayList,在需要遍歷訪問以及增刪多查找少的時候考慮LinkedList,之所以要有這個方法是由List介面指定,這個方法也是LinkedList沒有實作RandomAccess介面的原因之一,
Deque體系下的方法:
當我們把LinkedList當佇列和堆疊使用時,主要用到的就是Deque體系下的方法,
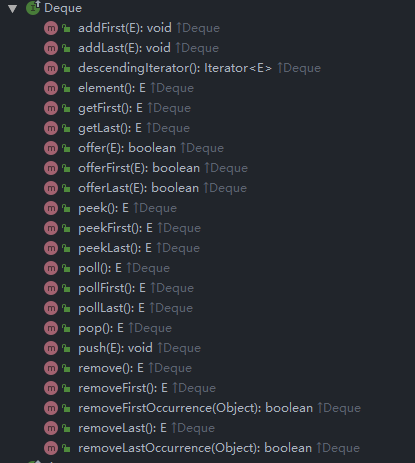
如果稍微細看一下,會發現上述很多方法基本是重復的,比如push(E e)其實就是呼叫了addFirst(e),
addFirst(e)也是直接呼叫了linkFirst(e);pop()就是直接呼叫了removeFirst();
為啥搞這么麻煩,一個方法起這么多名稱?
其實是因為從不同角度來看LinkedList時,它具有不同的角色,可以說它哪里都能添加,哪里都能洗掉,
具體使用時建議仔細看下對應注釋,
作為佇列
佇列的基本特點是“先進先出”,相當于鏈表尾添加元素,鏈表頭洗掉元素,
對應的方法是offer(E e),peek(),poll()
public boolean offer(E e) {
return add(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
可以看出offer方法的本質還是在鏈表末尾添加元素,linkLast(e)方法前面已經講到,
/**
* Retrieves, but does not remove, the head (first element) of this list.
*
* @return the head of this list, or {@code null} if this list is empty
* @since 1.5
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
peek()方法回傳佇列第一個元素,但是不洗掉元素,也就是說多次peek得到同一個元素,
/**
* Retrieves and removes the head (first element) of this list.
*
* @return the head of this list, or {@code null} if this list is empty
* @since 1.5
*/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
poll() 方法回傳佇列第一個元素的同時并將其從佇列中洗掉,也就是多次poll得到不同元素,
顯然poll方法更符合佇列的概念,
這里沒有詳細解說洗掉相關的方法,是因為如果前面的添加方法細看了,洗掉方法也很簡單,無非是越過被洗掉的元素連接指標,這里沒必要浪費篇幅,不妨自己畫一下,有助于理解,
作為堆疊
堆疊的基本特點是“先進后出”,相當于鏈表頭部添加元素,頭部洗掉元素,
對應的方法是push(E e)和pop(),
public void push(E e) {
addFirst(e);
}
public void addFirst(E e) {
linkFirst(e);
}
可以看出,push是在呼叫addFirst,進而呼叫linkFirst(e),而在頭部添加元素,add(int index, E element)方法處已經講到了,大體只是方法名不一樣而已,
public E pop() {
return removeFirst();
}
pop()方法回傳并洗掉第一個元素,
總結
這篇文章主要講了LinkedList相關的最基本的內容,更多的是回顧一些基礎知識,既有java相關的,也有最基礎資料結構的知識,比如鏈表相關的操作,第一次畫圖來說明問題,有時候真的是一圖勝千言,寫到這里最大的感受是基礎很重要,它決定了你能走多遠,
希望我的文章能給你帶來一絲幫助!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/201479.html
標籤:其他
上一篇:竟然可以這樣學python!
下一篇:下戶申請撞單