爬蟲百例專欄連載已經結束,歡迎訂閱 🙈100 篇爬蟲文章合計 29.9 元,每篇只需 2.9 毛錢 🙈
🌹 橡皮擦 叨叨 🌹
本專欄為爬蟲小課系列,周更 3+篇,專欄合計 9 篇文章,本專欄所有案例都將采用 requests 庫撰寫,通過 9 個案例,讓你深入理解 requests 庫,
以上就是本系列專欄的核心目標,
本系列課程需要一定的 Python 語法基礎,資料匹配將采用 Python 自帶的 re 模塊,故對正則運算式有一定的基礎要求,
關于爬取環境的需求,Python3.5 以上版本,安裝 requests 模塊,
爬蟲前的分析
類別頁面分析
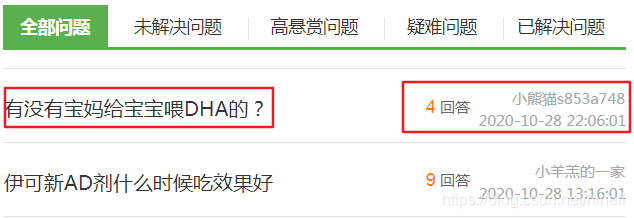
本次爬蟲小課要爬取的的網站為育兒網(http://ask.ci123.com/) 的問答模塊,我們要采集一下紅框內的資料,
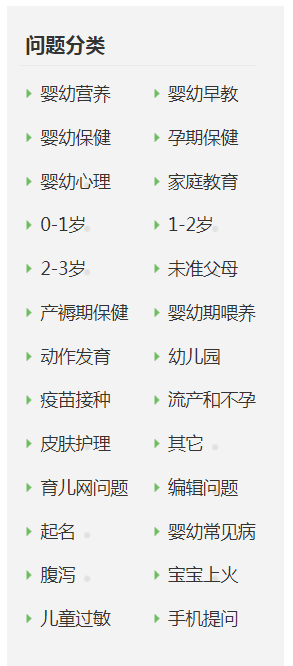
對于該網站涉及的問題型別非常多,具體分類可以通過上述鏈接左側的選單獲取到,如下圖所示區域:
在這里需要略微分析一下,分類地址的規律,如果沒有規律,那第一步就先獲取一下所有的分類地址,滑鼠點擊各鏈接發現,分類串列頁鏈接如下:
http://ask.ci123.com/categories/show/2
http://ask.ci123.com/categories/show/3
http://ask.ci123.com/categories/show/4
http://ask.ci123.com/categories/show/{類別ID}
在這里先不要下結論,說 ID 是依次遞增的,寫爬蟲程式如果過早的假定一定的規則,很容易出現資料丟失的情況,所以盡量都嘗試一遍,
在這里也可以直接通過查看網頁原始碼,看一下所有的地址,當然看完之后還是為了我們可以爬取到,最終查閱到所有的地址都為http://ask.ci123.com/categories/show/{類別ID} 形式,只是最后的類別 ID 不是連續的,到這里問題分類分析完畢,

問題串列頁面分析
下面需要尋找串列頁相關規律,點擊任意類別之后,可以查閱到,頁面資料樣式都如下圖所示:
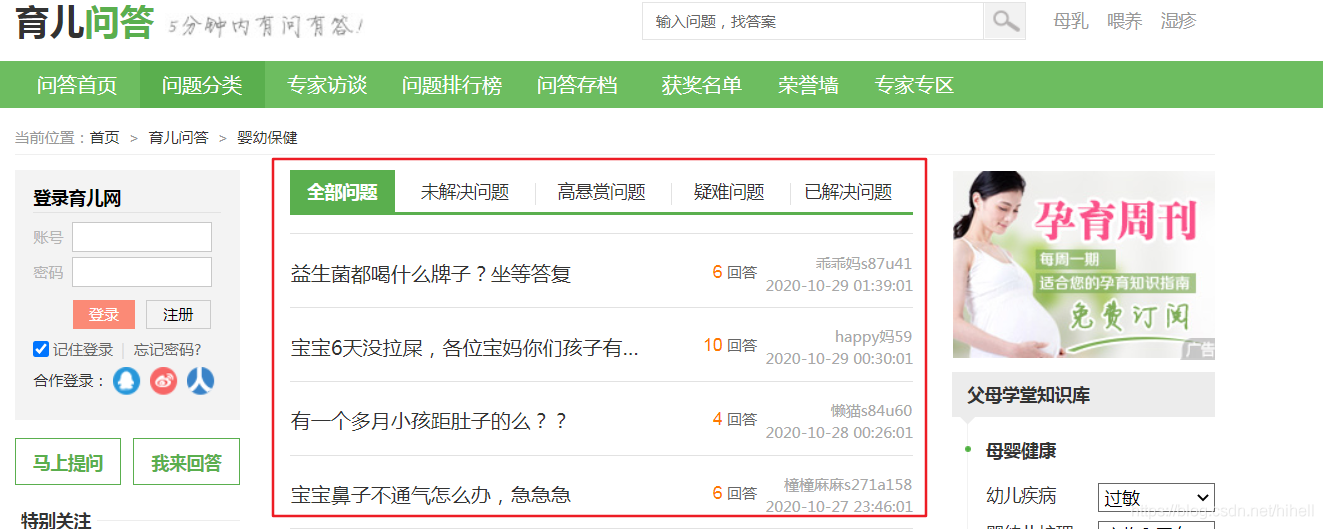
首先要做的第一件事請,就是查找分頁規律,找到分頁區域,滑鼠依次點擊分頁,獲取不同的分頁地址,

最后找到其規律鏈接地址如下:
http://ask.ci123.com/categories/show/4/all?p={頁碼}
有頁碼規律還不夠,還需要找到末頁,在原始碼中簡單檢索,找到末頁對應的頁碼即可,

到此爬蟲前的分析分析完畢了,下面開始進行爬蟲邏輯編碼環節,也就是整理自己的思路,
邏輯編碼(偽代碼)
育兒網爬蟲分為如下步驟:
- 通過 http://ask.ci123.com/ 頁面,獲取所有的分類頁面地址
- 回圈所有的分類頁面地址
- 獲取每個分類對應的串列頁面,并獲取總頁碼
- 從一開始回圈到總頁碼
- 上一步回圈程序中過去每一頁待爬取的資料
思路整理完畢,編碼環節其實就是一個簡單的實作程序,
爬蟲正式編碼
request 庫 get 方法說明
對于 requests 庫來說,匯入并快速應用是非常容易的,先通過抓取分類頁面原始碼來看一下基本使用,
import requests
url = "http://ask.ci123.com/"
# 抓取分類頁面
def get_category():
res = requests.get("http://ask.ci123.com/")
print(res.text)
if __name__ == "__main__":
get_category()
以上代碼中最核心的方法就是 requests.get()了,該方法為 requests 模塊通過 get 方式獲取網站原始碼,該方法中的引數說明如下:
必選引數 url
requests.get(url="http://ask.ci123.com/")
傳遞 URL 引數
通過該引數可以構造出如下格式 https://www.baidu.com/s?wd=你好&rsv_spt=1&rsv_iqid=0x8dd347e100002e04,
格式如下:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
res = requests.get(url="http://ask.ci123.com/", params=payload)
print(res.url)
key1 為鍵名,value1 為鍵值,
定制請求頭
在爬蟲爬取的程序中,我們將盡量將爬蟲模擬成真實的用戶通過瀏覽器訪問網站,所以很多時候需要定制瀏覽器請求頭,格式如下:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
headers = {
'user-agent': 'Baiduspider-image+(+http://www.baidu.com/search/spider.htm)'
}
res = requests.get(url="http://ask.ci123.com/",
params=payload, headers=headers)
print(res.url)
其中 headers 中可以配置更多的內容,本篇博客不做展開,只需要先記住 headers 引數即可,
Cookie
Cookie 在很多爬蟲程式中屬于必備內容,這里有時會存盤加密資訊,有時會存盤用戶資訊,格式如下:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
headers = {
'user-agent': 'Baiduspider-image+(+http://www.baidu.com/search/spider.htm)'
}
cookies = dict(my_cookies='nodream')
res = requests.get(url="http://ask.ci123.com/",
params=payload, headers=headers, cookies=cookies)
print(res.text)
禁用重定向處理
有些網站會攜帶重定向原始碼,在爬取的時候需要禁止網格員自動跳轉,代碼如下:
r = requests.get('http://github.com', allow_redirects=False)
超時
對于一個網路請求,有時會出現無法請求到的情況,這部分在官方手冊高級部分有相應的說明,不過對于初學者可以先進行忽略超時的高級用法,
為防止服務器不能及時回應,大部分發至外部服務器的請求都應該帶著 timeout 引數,在默認情況下,除非顯式指定了 timeout 值,requests 是不會自動進行超時處理的,如果沒有 timeout,你的代碼可能會掛起若干分鐘甚至更長時間,
常規代碼如下:
import requests
payload = {'key1': 'value1', 'key2': 'value2'}
headers = {
'user-agent': 'Baiduspider-image+(+http://www.baidu.com/search/spider.htm)'
}
cookies = dict(my_cookies='nodream')
res = requests.get(url="http://ask.ci123.com/",
params=payload, headers=headers, cookies=cookies, timeout=3)
print(res.text)
高級部分引數
對于 get 方法,還有一些引數,在后續的博客中我們可能會用到,例如:
- SSL 證書驗證 (verify)
- 客戶端證書(cert)
- 事件鉤子(hooks)
- 自定義身份驗證(auth)
- 流式請求(stream)
- 代理(proxies)
以上引數都會出現在 get 方法中,所以 requests 庫是一個非常非常強大的庫,
獲取所有的分類頁面地址
有了上述詳細的說明,在使用 requests 庫去獲取網頁中的內容就變得簡單一些了,這里需要有 Python 基礎知識中 re 模塊的使用與正則運算式的基礎,具體的爬取代碼如下:
import requests
import re
url = "http://ask.ci123.com/"
headers = {
'user-agent': 'Baiduspider-image+(+http://www.baidu.com/search/spider.htm)'
}
# 抓取分類頁面
def get_category():
res = requests.get("http://ask.ci123.com/", headers=headers)
pattern = re.compile(
r'<li><a href="/categories/show/(\d+)">', re.S)
categories_ids = pattern.findall(res.text)
print(f"獲取到的分類ID如下:",categories_ids)
if __name__ == "__main__":
get_category()
回圈所有的分類頁面地址
在上述代碼中通過re庫的 findall 方法獲取了所有的分類編號,用來拼接后續的待爬取頁面,獲取到 IDS 之后,就可以通過回圈的方式獲取到所有的串列頁面了,具體如下:
# 抓取分類頁面
def get_category():
res = requests.get("http://ask.ci123.com/", headers=headers)
pattern = re.compile(
r'<li><a href="/categories/show/(\d+)">', re.S)
categories_ids = pattern.findall(res.text)
print(f"獲取到的分類ID如下:", categories_ids)
for cate in categories_ids:
# 下述代碼中有get_list()函式對應的代碼
get_list(cate)
time.sleep(1)
上述代碼為了防止被反爬,需要增加一個延時處理,time.sleep(),
獲取每個分類對應的串列頁面,并獲取總頁碼
打開串列頁面,首要目的先獲取到總頁碼,本次實作的案例獲取的頁碼途徑比較簡單,在串列頁存在一項,資料直接在原始碼中可以看到,故直接抓取即可,
def get_list(cate):
# 獲取總頁碼,回圈抓取所有頁
res = requests.get(
f"http://ask.ci123.com/categories/show/{cate}", headers=headers)
pattern = re.compile(
r'<a class="list_last_page" href="/categories/show/\d+/all\?p=(\d+)"', re.S)
totle = pattern.search(res.text).group(1)
for page in range(1, int(totle)):
print(f"http://ask.ci123.com/categories/show/{cate}/all?p={page}")
time.sleep(0.2)
從 1 開始回圈到總頁碼
本部分代碼比較容易,已經在上述代碼實作,結果如圖所示:

本案例收尾環節
后續的內容就變得非常容易了,對每頁資料進行分析,并進行存盤資料操作,下述代碼未撰寫存盤部分,抓取部分代碼已經填寫完整,其中存在一個非常大的正則運算式,可以參考一下,如果爬取資料不是很嚴格,大量的使用.*\s這些常見元字符即可,
import requests
import re
import time
url = "http://ask.ci123.com/"
headers = {
'user-agent': 'Baiduspider-image+(+http://www.baidu.com/search/spider.htm)'
}
def get_detail(text):
# 該函式實作決議頁面資料,之后存盤資料
pattern = re.compile(r'<li>[.\s]*<a href="/questions/show/(\d+)/" title="(.*?)" class="list_title" target="_blank" >.*?</a>\s*<span class="list_asw">(\d+)<font>.*?</font></span>\s*<a class="list_author" href="/users/show/\d+" title=".*?">(.*?)</a>\s*<span class="list_time">(.*?)</span>\s*</li>')
data = pattern.findall(text)
print(data)
# 資料存盤代碼不在撰寫
def get_list(cate):
# 獲取總頁碼,回圈抓取所有頁
res = requests.get(
f"http://ask.ci123.com/categories/show/{cate}", headers=headers)
pattern = re.compile(
r'<a class="list_last_page" href="/categories/show/\d+/all\?p=(\d+)"', re.S)
totle = pattern.search(res.text).group(1)
for page in range(1, int(totle)):
print(f"http://ask.ci123.com/categories/show/{cate}/all?p={page}")
res = requests.get(
f"http://ask.ci123.com/categories/show/{cate}/all?p={page}", headers=headers)
time.sleep(0.2)
# 調取串列頁資料提取函式
get_detail(res.text)
# 抓取分類頁面
def get_category():
res = requests.get("http://ask.ci123.com/", headers=headers)
pattern = re.compile(
r'<li><a href="/categories/show/(\d+)">', re.S)
categories_ids = pattern.findall(res.text)
print(f"獲取到的分類ID如下:", categories_ids)
for cate in categories_ids:
get_list(cate)
time.sleep(1)
if __name__ == "__main__":
get_category()
廣宣時間
如果你想跟博主建立親密關系,可以關注博主,或者關注博主公眾號“
非本科程式員”,了解一個非本科程式員是如何成長的,
博主 ID:夢想橡皮擦,希望大家點贊、評論、收藏

爬蟲百例教程導航鏈接 : https://blog.csdn.net/hihell/article/details/86106916
 CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
CSDN認證博客專家
大學老師
高級產品經理
互聯網從業者
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/201579.html
標籤:python