宣告:轉載請附帶原文鏈接!
超長文章警告:耐心看下去肯定有識訓!
0.前言
提示:對于初識HashMap的小伙伴來說,不推薦直接硬啃,建議先看一下如下幾個視頻教程之后在回頭自己反復琢磨,(一遍不懂反復看,一小塊兒一小塊的找博客閱讀)
- 小劉老師講HashMap原始碼
- 黑馬程式員HashMap原始碼
- 小劉老師講紅黑樹
HashMap簡述:
- HashMap 基于哈希表的 Map 介面實作,是以 key-value 存盤形式存在,即主要用來存放鍵值對,HashMap 的實作不是同步的,這意味著它不是執行緒安全的,它的 key、value 都可以為 null,此外,HashMap 中的映射不是有序的,
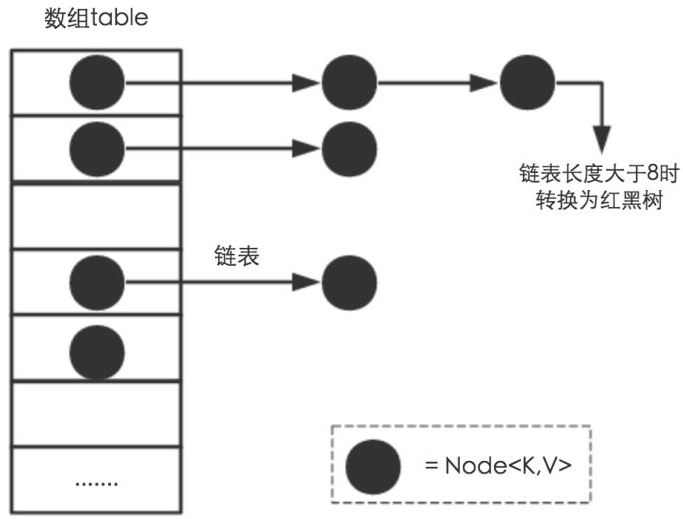
- jdk1.8 之前 HashMap 由 陣列 + 鏈表 組成,陣列是 HashMap 的主體,鏈表則是主要為了解決哈希沖突(兩個物件呼叫的 hashCode 方法計算的哈希值經哈希函式算出來的地址被別的元素占用)而存在的(“拉鏈法”解決沖突),jdk1.8 以后在解決哈希沖突時有了較大的變化,當鏈表長度大于閾值(或者紅黑樹的邊界值,默認為 8 )并且當前陣列的長度大于 64 時,此時此索引位置上的所有資料改為使用紅黑樹存盤,
HashMap擴容機制簡述:
HashMap == 陣列+散鏈表+紅黑樹
-
HashMap 默認初始桶位數16,如果某個桶中的鏈表長度大于8,則先進行判斷:
-
如果桶位數小于64,則先進行擴容(2倍),擴容之后重新計算哈希值,這樣桶中的鏈表長度就變短了(之所以鏈表長度變短與桶的定位方式有關,請接著往下看),
-
如果桶位數大于64,且某個桶中的鏈表長度大于8,則對鏈表進行樹化(紅黑樹,即自平衡的二叉樹)
-
如果紅黑樹的節點數小于6,樹也會重新變會鏈表,
所以得出樹化條件:鏈表閾值大于8,且桶位數大于64(陣列長度),才進行樹化,
元素放入桶(陣列)中,定位桶的方式:通過陣列下標 i 定位,添加元素時,目標桶位置 i 的計算公式,i = hash & (cap - 1),cap為容量,
為什么優先擴容桶位數(陣列長度),而不是直接樹化?
- 這樣做的目的是因為,當桶位數(陣列長度)比較小時,應盡量避開紅黑樹結構,這種情況下變為紅黑樹結構,反而會降低效率,因為紅黑樹需要逬行左旋,右旋,變色這些操作來保持平衡,同時陣列長度小于64時,搜索時間相對要快些,所以結上所述為了提高性能和減少搜索時間,底層閾值大于8并且陣列長度大于64時,鏈表才轉換為紅黑樹,具體可以參考下文要講述的 treeifyBin() 方法,
- 而當閾值大于 8 并且陣列長度大于 64 時,雖然增了紅黑樹作為底層資料結構,結構變得復雜了,但是,長度較長的鏈表轉換為紅黑樹時,效率也變高了,
HashMap 特點:
- 存盤無序;
- 鍵和值位置都可以是 null,但是鍵位置只能存在一個 null;
- 鍵位置是唯一的,是由底層的資料結構控制的;
- jdk1.8 前資料結構是鏈表+陣列,jdk1.8 之后是鏈表+陣列+紅黑樹;
- 閾值(邊界值)> 8 并且桶位數(陣列長度)大于 64,才將鏈表轉換為紅黑樹,變為紅黑樹的目的是為了高效的查詢;
1.HashMap存盤資料的程序
注意:相對于直接去讀HashMap原始碼來說,先debug一下其執行資料存盤的流程,更方便大家理解!
測驗代碼:
@Test
public void test01() {
HashMap<String, Integer> hashMap = new HashMap();
hashMap.put("a", 3);
hashMap.put("b", 4);
hashMap.put("c", 5);
hashMap.put("a", 88888);// 修改
System.out.println(hashMap);
}
輸出結果:
{a=88888, b=456, c=789}
執行流程分析:
-
首先,
HashMap<String, Integer> hashMap = new HashMap();當創建 HashMap 集合物件的時候,HashMap 的構造方法并沒有創建陣列,而是在第一次呼叫 put 方法時創建一個長度是16 的陣列(即,16個桶) ,Node[] table(jdk1.8 之前是 Entry[] table)用來存盤鍵值對資料, -
當向哈希表中存盤
put("a", 3)的資料時,根據"a"字串呼叫 String 類中重寫之后的 hashCode() 方法計算出哈希值,然后結合陣列長度(桶數量)采用某種演算法計算出向 Node 陣列中存盤資料的空間索引值(比如table[i],這里的i就是該Node陣列的空間索引),如果計算出的索引空間沒有資料(即,這個桶是空的),則直接將<"a", 3>存盤到陣列中,舉例:如果計算出的索引是 3,則存盤到如下桶位:
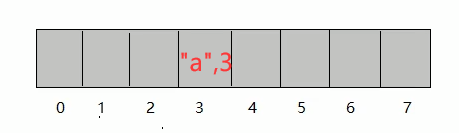
-
當向哈希表中存盤資料
<"b", 4>時,假設算出的 hashCode() 方法結合數祖長度計算出的索引值也是3,那么此時陣列空間不是 null(即,這個桶目前不為空),此時底層會比較"a"和"b"的 hash 值是否一致,如果不一致,則在空間上劃出一個結點來存盤鍵值對資料對<"b", 4>,這種方式稱為拉鏈法, -
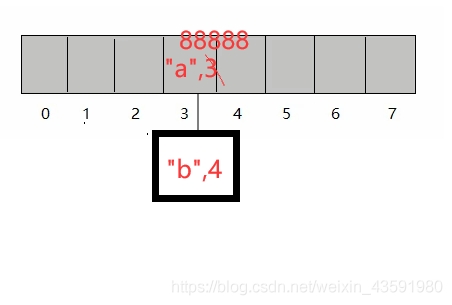
當向哈希表中存盤資料
<"a", 88888>時,那么首先根據"a"呼叫 hashCode() 方法結合陣列長度計算出索引肯定是 3,此時比較后存盤的資料"a"和已經存在的資料的 hash 值是否相等,如果 hash 值相等,此時發生哈希碰撞,那么底層會呼叫"a"所屬類 String 中的 equals() 方法比較兩個內容是否相等:-
相等:將后添加的資料的 value 覆寫之前的 value,
-
不相等:繼續向下和其他的資料的 key 進行比較,如果都不相等,則劃出一個結點存盤資料,如果結點長度即鏈表長度大于閾值 8 并且陣列長度大于 64 則將鏈表變為紅黑樹,
-
-
在不斷的添加資料的程序中,會涉及到擴容問題,當超出閾值(且要存放的位置非空)時,擴容,默認的擴容方式:擴容為原來容量的 2 倍,并將原有的資料復制過來,
-
綜上描述,當位于一個表中的元素較多,即 hash 值相等但是內容不相等的元素較多時,通過 key 值依次查找的效率較低,而 jdk1.8 中,哈希表存盤采用陣列+鏈表+紅黑樹實作,當鏈表長度(閾值)超過8且當前陣列的長度大于64時,將鏈表轉換為紅黑樹,這樣大大減少了查找時間,
簡單的來說,哈希表是由陣列+鏈表+紅黑樹(JDK1.8增加了紅黑樹部分)實作的,如下圖所示:
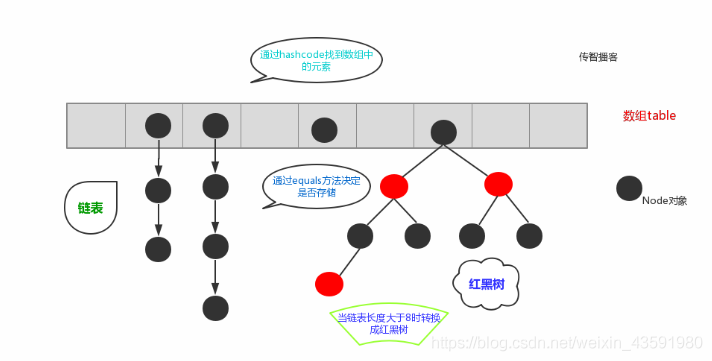
-
jdk1.8 中引入紅黑樹的進一步原因:
-
jdk1.8 以前 HashMap 的實作是陣列+鏈表,即使哈希函式取得再好,也很難達到元素百分百均勻分布,當 HashMap 中有大量的元素都存放到同一個桶中時,這個桶下有一條長長的鏈表,這個時候 HashMap 就相當于一個單鏈表,假如單鏈表有n個元素,遍歷的時間復雜度就是O(n),完全失去了它的優勢,
-
針對這種情況,jdk1.8 中引入了紅黑樹(查找時間復雜度為 O(logn))來優化這個問題,當鏈表長度很小的時候,即使遍歷,速度也非常快,但是當鏈表長度不斷變長,肯定會對查詢性能有一定的影響,所以才需要轉成樹,
-
-
總結:
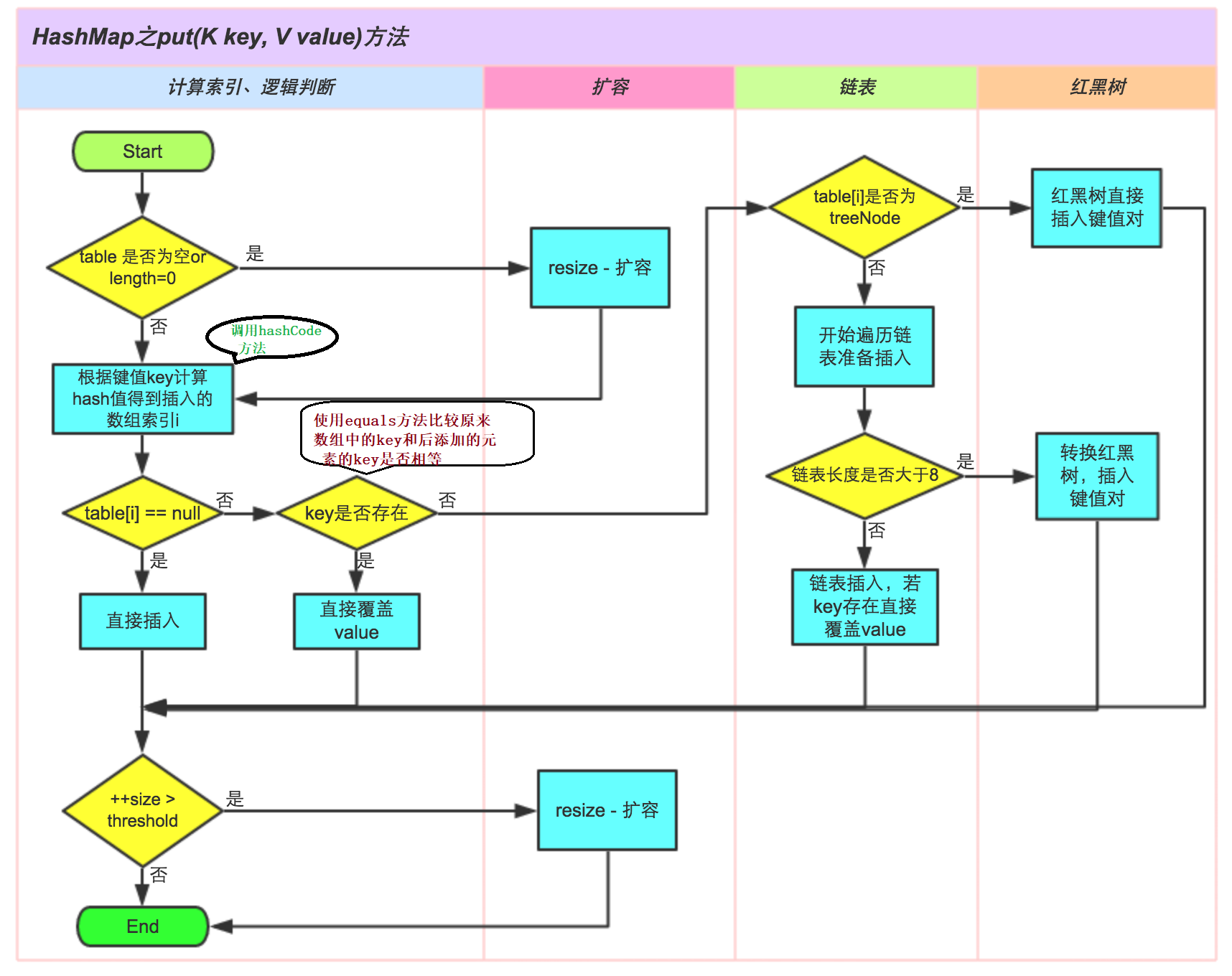
說明:
- size 表示 HashMap 中鍵值對的實時數量(即,所存盤元素的數量),注意這個不等于陣列的長度,
- threshold(臨界值)= capacity(容量)* loadFactor(負載因子),這個值是當前已占用陣列長度的最大值,size 超過這個值就重新 resize(擴容),擴容后的 HashMap 容量是之前容量的2倍,
2.HashMap相關面試題
具體原理我們下文會具體分析,這里先大概了解下面試的時候會問什么,帶著問題去讀原始碼,便于理解!
-
HashMap 中 hash 函式是怎么實作的?還有哪些hash函式的實作方式?
答:- 對 key 的 hashCode 做 hash 操作,如果key為null則直接賦哈希值為0,否則,無符號右移 16 位然后做異或位運算,如,代碼所示:
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); - 除上面的方法外,還有平方取中法,偽亂數法 和 取余數法,這三種效率都比較低,而無符號右移 16 位異或運算效率是最高的,
- 對 key 的 hashCode 做 hash 操作,如果key為null則直接賦哈希值為0,否則,無符號右移 16 位然后做異或位運算,如,代碼所示:
-
當兩個物件的 hashCode 相等時會怎么樣?
答:會產生哈希碰撞,若 key 值內容相同則替換舊的 value,不然連接到鏈表后面,鏈表長度超過閾值 8 就轉換為紅黑樹存盤, -
什么是哈希碰撞,如何解決哈希碰撞?
答:只要兩個元素的 key 計算的哈希碼值相同就會發生哈希碰撞,jdk8 之前使用鏈表解決哈希碰撞,jdk8之后使用鏈表 + 紅黑樹解決哈希碰撞, -
如果兩個鍵的 hashCode 相同,如何存盤鍵值對?
答:通過 equals 比較內容是否相同,-
相同:則新的 value 覆寫之前的 value,
-
不相同:遍歷該桶位的鏈表(或者樹):
- 如果找到相同key,則覆寫該key對應的value;
- 如果找不到,則將新的鍵值對添加到鏈表(或者樹)中;
-
3.HashMap繼承體系
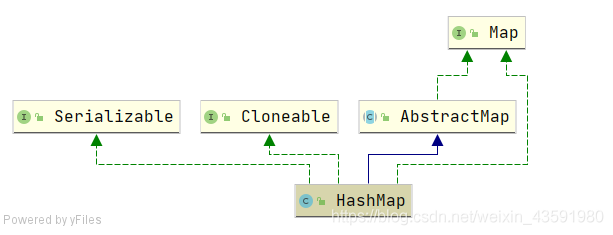
從繼承體系可以看出:
- HashMap 實作了Cloneable介面,可以被克隆,
- HashMap 實作了Serializable介面,屬于標記性介面,HashMap 物件可以被序列化和反序列化,
- HashMap 繼承了AbstractMap,父類提供了 Map 實作介面,具有Map的所有功能,以最大限度地減少實作此介面所需的作業,
知識擴展:
通過上述繼承關系我們發現一個很奇怪的現象,就是 HashMap 已經繼承了AbstractMap 而 AbstractMap 類實作了Map 介面,那為什么 HashMap 還要在實作 Map 介面呢?同樣在 ArrayList 中 LinkedLis 中都是這種結構,
據 Java 集合框架的創始人 Josh Bloch 描述,這樣的寫法是一個失誤,在 Java 集合框架中,類似這樣的寫法很多,最幵始寫 Java 集合框架的時候,他認為這樣寫,在某些地方可能是有價值的,直到他意識到錯了,顯然的,jdk 的維護者,后來不認為這個小小的失誤值得去修改,所以就這樣保留下來了,
存盤結構(再過一遍)
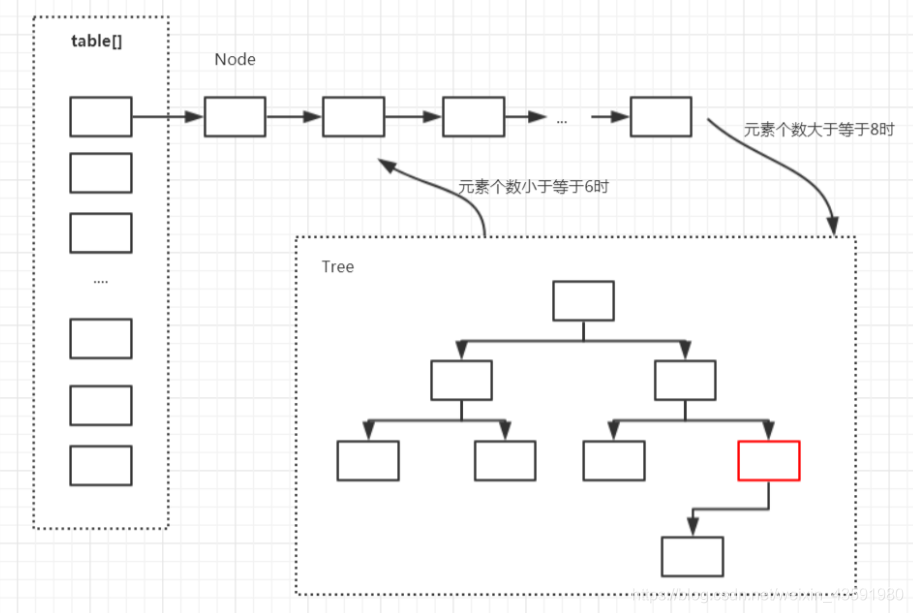
在Java中,HashMap的實作采用了(陣列 + 鏈表 + 紅黑樹)的復雜結構,陣列的一個元素又稱作桶,
在添加元素時,會根據hash值算出元素在陣列中的位置,如果該位置沒有元素,則直接把元素放置在此處,如果該位置有元素了,則把元素以鏈表的形式放置在鏈表的尾部,
當一個鏈表的元素個數達到一定的數量(且陣列的長度達到一定的長度)后,則把鏈表轉化為紅黑樹,從而提高效率,
陣列的查詢效率為O(1),鏈表的查詢效率是O(k),紅黑樹的查詢效率是O(log k),k為桶中的元素個數,所以當元素數量非常多的時候,轉化為紅黑樹能極大地提高效率,
2.HashMap基本屬性與常量
/*
* 序列化版本號
*/
private static final long serialVersionUID = 362498820763181265L;
/**
* HashMap的初始化容量(必須是 2 的 n 次冪)默認的初始容量為16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* 最大的容量為2的30次方
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 默認的裝載因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 樹化閾值,當一個桶中的元素個數大于等于8時進行樹化
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* 樹降級為鏈表的閾值,當一個桶中的元素個數小于等于6時把樹轉化為鏈表
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* 當桶的個數達到64的時候才進行樹化
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Node陣列,又叫作桶(bucket)
*/
transient Node<K,V>[] table;
/**
* 作為entrySet()的快取
*/
transient Set<Map.Entry<K,V>> entrySet;
/**
* 元素的數量
*/
transient int size;
/**
* 修改次數,用于在迭代的時候執行快速失敗策略
*/
transient int modCount;
/**
* 當桶的使用數量達到多少時進行擴容,threshold = capacity * loadFactor
*/
int threshold;
/**
* 裝載因子
*/
final float loadFactor;
(1)容量:容量為陣列的長度,亦即桶的個數,默認為16 ,最大為2的30次方,當容量達到64時才可以樹化,
(2)裝載因子:裝載因子用來計算容量達到多少時才進行擴容,默認裝載因子為0.75,
(3)樹化:樹化,當容量達到64且鏈表的長度達到8時進行樹化,當鏈表的長度小于6時反樹化,
2.1 DEFAULT_INITIAL_CAPACITY
集合的初始化容量(必須是 2 的 n 次冪):
// 默認的初始容量是16 1 << 4 相當于 1*2的4次方
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
面試問題:為什么必須是 2 的 n 次冪?如果輸入值不是 2 的冪比如 10 會怎么樣?
HashMap 構造方法可以指定集合的初始化容量大小,如:
// 構造一個帶指定初始容量和默認負載因子(0.75)的空 HashMap,
HashMap(int initialCapacity)
根據上述講解我們已經知道,當向 HashMap 中添加一個元素的時候,需要根據 key 的 hash 值,去確定其在陣列中的具體位置,HashMap 為了存取高效,減少碰撞,就是要盡量把資料分配均勻,每個鏈表長度大致相同,這個實作的關鍵就在把資料存到哪個鏈表中的演算法,
這個演算法實際就是取模,hash % length,而計算機中直接求余效率不如位移運算,所以原始碼中做了優化,使用 hash & (length - 1),而實際上 hash % length 等于 hash & ( length - 1) 的前提是 length 是 2 的 n 次冪,(這段話是摘抄傳智播客鎖哥的,這個解釋確實很完美!)
例如,陣列長度為 8 的時候,3 & (8 - 1) = 3,2 & (8 - 1) = 2,桶的位置是(陣列索引)3和2,不同位置上,不碰撞,
再來看一個陣列長度(桶位數)不是2的n次冪的情況:

從上圖可以看出,當陣列長度為9(非2 的n次冪)的時候,不同的哈希值hash, hash & (length - 1)所得到的陣列下標相等(很容易出現哈希碰撞),
小結一下HashMap陣列容量使用2的n次冪的原因:(面試也會問)

問題:如果創建HashMap物件時,輸入的陣列長度length是10,而不是2的n次冪會怎么樣呢?
HashMap<String, Integer> hashMap = new HashMap(10);
HashMap雙參建構式會通過tableSizeFor(initialCapacity)方法,得到一個最接近length且大于length的2的n次冪數(比如最接近10且大于10的2的n次冪數是16)
這一塊兒比較難理解,下文講構造方法的時候還會再舉例一個例子:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
說明:
當在實體化 HashMap 實體時,如果給定了 initialCapacity,由于 HashMap 的 capacity 必須是 2 的冪,因此這個方法tableSizeFor(initialCapacity);用于找到大于等于 initialCapacity 的最小的 2 的冪,
分析:
-
int n = cap - 1;為什么要減去1呢?
防止 cap 已經是 2 的冪,如果 cap 已經是 2 的冪,又沒有這個減 1 操作,則執行完后面的幾條無符號操作之后,回傳的 capacity 將是這個 cap 的 2 倍(后面還會再舉個例子講這個), -
最后為什么有個 n + 1 的操作呢?
如果 n 這時為 0 了(經過了cap - 1后),則經過后面的幾次無符號右移依然是 0,回傳0是肯定不行的,所以最后回傳
n+1最終得到的 capacity 是1, -
注意:容量最大也就是 32bit 的正數,因此最后
n |= n >>> 16;最多也就 32 個 1(但是這已經是負數了,在執行 tableSizeFor 之前,對 initialCapacity 做了判斷,如果大于MAXIMUM_CAPACITY(2 ^ 30),則取 MAXIMUM_CAPACITY,如果等于MAXIMUM_CAPACITY,會執行位移操作,所以這里面的位移操作之后,最大 30 個 1,不會大于等于 MAXIMUM_CAPACITY,30 個 1,加 1 后得 2 ^ 30),
完整例子:
所以由結果可得,當執行完tableSizeFor(initialCapacity);方法后,得到的新capacity是最接近initialCapacity且大于initialCapacity的2的n次冪的數,
2.2 DEFAULT_LOAD_FACTOR
默認的負載因子(默認值 0.75)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
2.3 MAXIMUM_CAPACITY
集合最大容量
static final int MAXIMUM_CAPACITY = 1 << 30; // 2的30次冪
2.4 TREEIFY_THRESHOLD
當鏈表的值超過8則會轉為紅黑樹(jdk1.8新增)
// 當桶(bucket)上的結點數大于這個值時會轉為紅黑樹
static final int TREEIFY_THRESHOLD = 8;
面試問題:為什么 Map 桶中結點個數超過 8 才轉為紅黑樹?
8這個閾值定義在HashMap中,針對這個成員變數,在原始碼的注釋中只說明了 8 是 bin( bucket 桶)從鏈表轉成樹的閾值,但是并沒有說明為什么是 8,
在 HashMap 中有一段注釋說明:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins
contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too
small (due to removal or resizing) they are converted back to plain bins. In usages with
well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes,
the frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution)
with a parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance,
the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)). The first values are:
翻譯:因為樹結點的大小大約是普通結點的兩倍,所以我們只在箱子包含足夠的結點時才使用樹結點(參見TREEIFY_THRESHOLD),
當它們變得太小(由于洗掉或調整大小)時,就會被轉換回普通的桶,在使用分布良好的用戶 hashCode 時,很少使用樹箱,
理想情況下,在隨機哈希碼下,箱子中結點的頻率服從泊松分布,
默認調整閾值為0.75,平均引數約為0.5,盡管由于調整粒度的差異很大,忽略方差,串列大小k的預朗出現次數是(exp(-0.5)*pow(0.5, k) / factorial(k)
第一個值是:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
TreeNodes(樹) 占用空間是普通 Nodes(鏈表) 的兩倍,所以只有當 bin(bucket 桶) 包含足夠多的結點時才會轉成 TreeNodes,而是否足夠多就是由 TREEIFY_THRESH〇LD 的值決定的,當 bin(bucket 桶) 中結點數變少時,又會轉成普通的 bin(bucket 桶),并且我們查看原始碼的時候發現,鏈表長度達到 8 就轉成紅黑樹,當長度降到 6 就轉成普通 bin(bucket 桶),
這樣就解釋了為什么不是一開始就將其轉換為 TreeNodes,而是需要一定結點數之后才轉為 TreeNodes,說白了就是權衡空間和時間,
這段內容還說到:當 hashCode 離散性很好的時候,樹型 bin 用到的概率非常小,因為資料均勻分布在每個 bin 中,幾乎不會有 bin 中鏈表長度會達到閾值,但是在隨機 hashCode 下,離散性可能會變差,然而 jdk 又不能阻止用戶實作這種不好的 hash 演算法,因此就可能導致不均勻的資料分布,不理想情況下隨機 hashCode 演算法下所有 bin 中結點的分布頻率會遵循泊松分布,我們可以看到,一個 bin 中鏈表長度達到 8 個元素的槪率為 0.00000006,幾乎是不可能事件,所以,之所以選擇 8,不是隨便決定的,而是裉據概率統計決定的,甶此可見,發展將近30年的 Java 每一項改動和優化都是非常嚴謹和科學的,
面試答案:hashCode 演算法下所有 桶 中結點的分布頻率會遵循泊松分布,這時一個桶中鏈表長度超過 8 個元素的槪率非常小,權衡空間和時間復雜度,所以選擇 8 這個數宇,
擴展補充:
-
Poisson 分布(泊松分布),是一種統計與概率學里常見到的離散[概率分布],泊松分布的概率函式為:
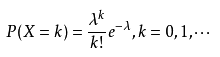
泊松分布的引數 A 是單位時間(或單位面積)內隨機事件的平均發生次數,泊松分布適合于描述單位時間內隨機事件發生的次數, -
以下是我在研究這個問題時,在一些資料上面翻看的解釋,供大家參考:
紅黑樹的平均查找長度是 log(n),如果長度為 8,平均查找長度為 log(8) = 3,鏈表的平均查找長度為 n/2,當長度為 8 時,平均查找長虔為 8/2 = 4,這才有轉換成樹的必要;鏈表長度如果是小于等于 6, 6/2 = 3,而 log(6) = 2.6,雖然速度也很快的,但是轉化為樹結構和生成樹的時間并不會太短,
2.5 UNTREEIFY_THRESHOLD
當鏈表的值小于 6 則會從紅黑樹轉回鏈表
// 當桶(bucket)上的結點數小于這個值,樹轉為鏈表
static final int UNTREEIFY_THRESHOLD = 6;
2.6 MIN_TREEIFY_CAPACITY
當 Map 里面的數量超過這個值時,表中的桶才能進行樹形化,否則桶內元素太多時會擴容,而不是樹形化為了避免進行擴容、樹形化選擇的沖突,這個值不能小于4*TREEIFY_THRESHOLD(8)
// 桶中結構轉化為紅黑樹對應的陣列長度最小的值
static final int MIN_TREEIFY_CAPACITY = 64;
2.7 table(重點)
table 用來初始化(必須是二的n次冪)
// 存盤元素的陣列
transient Node<K,V>[] table;
在 jdk1.8 中我們了解到 HashMap 是由陣列加鏈表加紅黑樹來組成的結構,其中 table 就是 HashMap 中的陣列,jdk8 之前陣列型別是 Entry<K,V> 型別,從 jdk1.8 之后是 Node<K,V> 型別,只是換了個名字,都實作了一樣的介面:Map.Entry<K,V>,負責存盤鍵值對資料的,
2.8 entrySet
用來存放快取
// 存放具體元素的集合
transient Set<Map.Entry<K,V>> entrySet;
2.9 size(重點)
HashMap 中存放元素的個數
// 存放元素的個數,注意這個不等于陣列的長度
transient int size;
size 為 HashMap 中 K-V 的實時數量,不是陣列 table 的長度,
2.10 modCount
用來記錄 HashMap 的修改次數
// 每次擴容和更改 map 結構的計數器
transient int modCount;
2.11 threshold(重點)
用來調整大小下一個容量的值計算方式為(容量*負載因子)
// 臨界值 當實際大小(容量*負載因子)超過臨界值時,會進行擴容
int threshold;
2.12 loadFactor(重點)
哈希表的負載因子
// 負載因子
final float loadFactor;// 0.75f
說明:
- loadFactor 是用來衡量 HashMap 滿的程度,表示HashMap的疏密程度,影響 hash 操作到同一個陣列位置的概率,計算 HashMap 的實時負載因子的方法為:size/capacity,而不是占用桶的數量去除以 capacity,capacity 是桶的數量,也就是 table 的長度 length,
- loadFactor 太大導致查找元素效率低,太小導致陣列的利用率低,存放的資料會很分散,loadFactor 的默認值為 0.75f 是官方給出的一個比較好的臨界值,
- 當 HashMap 里面容納的元素已經達到 HashMap 陣列長度的 75% 時,表示 HashMap 太擠了,需要擴容,而擴容這個程序涉及到 rehash、復制資料等操作,非常消耗性能,所以開發中盡量減少擴容的次數,可以通過創建 HashMap 集合物件時指定初始容量來盡量避免,
- 在 HashMap 的構造器中可以定制 loadFactor,
// 構造方法,構造一個帶指定初始容量和負載因子的空HashMap
HashMap(int initialCapacity, float loadFactor);
-
為什么負載因子loadFactor 設定為0.75,初始化臨界值threshold是12?
loadFactor 越趨近于1,那么 陣列中存放的資料(entry)也就越多,也就越密,也就是會讓鏈表的長度增加,loadFactor 越小,也就是趨近于0,陣列中存放的資料(entry)也就越少,也就越稀疏,
如果希望鏈表盡可能少些,要提前擴容,有的陣列空間有可能一直沒有存盤資料,負載因子盡可能小一些,
舉例:
例如:負載因子是0.4, 那么16*0.4--->6 如果陣列中滿6個空間就擴容會造成陣列利用率太低了,
負載因子是0.9, 那么16*0.9--->14 那么這樣就會導致鏈表有點多了,導致查找元素效率低,
所以既兼顧陣列利用率又考慮鏈表不要太多,經過大量測驗 0.75 是最佳方案,
-
threshold 計算公式:capacity(陣列長度默認16) * loadFactor(負載因子默認0.75)==12,
這個值是當前已占用陣列長度的最大值,當 Size >= threshold(12) 的時候,那么就要考慮對陣列的 resize(擴容),也就是說,這個的意思就是 衡量陣列是否需要擴增的一個標準, 擴容后的 HashMap 容量是之前容量的兩倍,
3.內部類
3.1Node內部類
Node是一個典型的單鏈表節點,其中,hash用來存盤key計算得來的hash值,
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// hash用來存盤key計算得來的hash值
final K key;// 鍵
V value;// 值
Node<K,V> next;// 下一個node節點
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {// 呼叫底層c++ 回傳Key/Value的哈希碼值,如果此物件為null,則回傳0
return Objects.hashCode(key) ^ Objects.hashCode(value);// 將Key/Vaule
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
3.2TreeNode內部類
TreeNode內部類,它繼承自LinkedHashMap中的Entry類,關于LInkedHashMap.Entry這個類之后會單獨發文章論述,TreeNode是一個典型的樹型節點,其中,prev是鏈表中的節點,用于在洗掉元素的時候可以快速找到它的前置節點,
// 位于HashMap中,文章接下來會逐步分析
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
// 位于LinkedHashMap中,典型的雙向鏈表節點,這個類之后會單獨發文章論述
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
4.HashMap構造方法
HashMap 中重要的構造方法,它們分別如下:
4.1 HashMap()
構造一個空的HashMap,默認初始容量(16)和默認負載因子(0.75),
public HashMap() {
// 將默認的負載因子0.75賦值給loadFactor,并沒有創建陣列
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
4.2 HashMap(int initialCapacity)
構造一個具有指定的初始容量和默認負載因子(0.75)HashMap ,
// 指定“容量大小”的建構式
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
4.3 HashMap(int initialCapacity,float loadFactor)構造方法
構造一個具有指定的初始容量和負載因子的 HashMap,
/*
指定“容量大小”和“負載因子”的建構式
initialCapacity:指定的容量
loadFactor:指定的負載因子
*/
public HashMap(int initialCapacity, float loadFactor) {
// 判斷初始化容量initialCapacity是否小于0
if (initialCapacity < 0)
// 如果小于0,則拋出非法的引數例外IllegalArgumentException
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 判斷初始化容量initialCapacity是否大于集合的最大容量MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
// 如果超過MAXIMUM_CAPACITY,會將MAXIMUM_CAPACITY賦值給initialCapacity
initialCapacity = MAXIMUM_CAPACITY;
// 判斷負載因子loadFactor是否小于等于0或者是否是一個非數值
if (loadFactor <= 0 || Float.isNaN(loadFactor))
// 如果滿足上述其中之一,則拋出非法的引數例外IllegalArgumentException
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 將指定的負載因子賦值給HashMap成員變數的負載因子loadFactor
this.loadFactor = loadFactor;// 一般不建議修改默認的負載因子
this.threshold = tableSizeFor(initialCapacity);
}
// 最后呼叫了tableSizeFor,來看一下方法實作:
/*
回傳比指定cap容量大的最小2的n次冪數:
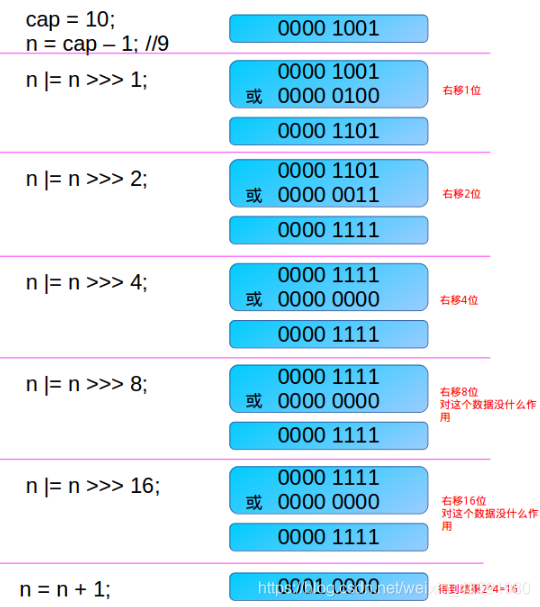
前面第一遍講述的應該有些小伙伴難以理解,這里我在舉例決議一下:
-------------------------------------------------------
首先假定傳入的cap = 10
則,n = 10 -1 => 9
n |= n >>> 1 就等同于 n = (n | n >>> 1),所以:
(位運算不懂的可以去看我的《Java基礎提高之位運算》這篇文章)
9 => 0b1001 9 >>> 1 => 0b0100
n |= n >>> 1; ===> 0b1001 | 0b0100 => 0b1101
n |= n >>> 2; ===> 0b1101 | 0b0011 => 0b1111
n |= n >>> 4; ===> 0b1111 | 0b0000 => 0b1111
n |= n >>> 8; ===> 0b1111 | 0b0000 => 0b1111
n |= n >>> 16; ===> 0b1111 | 0b0000 => 0b1111
得到:
0b1111 => 15
回傳:
return 15 + 1 => 16
-------------------------------------------------------
如果cap 不減去1,即直接使n等于cap的話,int n = cap;
我們繼續用上邊回傳的cap => 16 傳入tableSizeFor(int cap):
cap = 16
n = 16
16 => 0b10000 16 >>> 1 => 0b01000
n |= n >>> 1; ===> 0b10000 | 0b01000 => 0b11000
n |= n >>> 2; ===> 0b11000 | 0b00110 => 0b11110
n |= n >>> 4; ===> 0b11110 | 0b00001 => 0b11111
n |= n >>> 8; ===> 0b11111 | 0b00000 => 0b11111
n |= n >>> 16; ===> 0b11111 | 0b00000 => 0b11111
得到:
0b11111 => 31
回傳 return 31 +1 => 32
而實際情況是應該傳入cap = 16 , n = cap -1 = 15
15 => 0b1111
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
經過上面運算后得到:還是15
回傳結果:
return 15 + 1 = 16
所以我們得出結果:
防止 cap 已經是 2 的冪數情況下,沒有這個減 1 操作,
則執行完幾條無符號位移或位運算操作之后,回傳的cap(32)將是實際所需cap(16)的 2倍,
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
說明:
對于this.threshold = tableSizeFor(initialCapacity); 疑問?
**tableSizeFor(initialCapacity)**判斷指定的初始化容量是否是2的n次冪,如果不是那么會變為比指定初始化容量大的最小的2的n次冪,
但是注意,在tableSizeFor方法體內部將計算后的資料回傳給呼叫這里了,并且直接賦值給threshold邊界值了,有些人會覺得這里是一個bug,應該這樣書寫:
this.threshold = tableSizeFor(initialCapacity) * this.loadFactor;
這樣才符合threshold的意思(當HashMap的size到達threshold這個閾值時會擴容)
但是請注意,在jdk8以后的構造方法中,并沒有對table這個成員變數進行初始化,table的初始化被推遲到了put方法中,在put方法中會對threshold重新計算,
4.4 HashMap(Map<? extends K, ? extends V> m)
包含另一個 “Map” 的建構式
// 構造一個映射關系與指定 Map 相同的新 HashMap,
public HashMap(Map<? extends K, ? extends V> m) {
// 負載因子loadFactor變為默認的負載因子0.75
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
最后呼叫了 putMapEntries(),來看一下方法實作:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
//獲取引數集合的長度
int s = m.size();
if (s > 0) {//判斷引數集合的長度是否大于0
if (table == null) { // 判斷table是否已經初始化
// 未初始化,s為m的實際元素個數
float ft = ((float)s / loadFactor) + 1.0F;// 得到新的擴容閾值
int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY);// 新的擴容閾值float自動向下轉型為int
// 計算得到的t大于閾值,則初始化閾值,將其變為符合要求的2的n次冪數
if (t > threshold)
threshold = tableSizeFor(t);
}
// 如果table已初始化過了,并且m元素個數大于閾值,進行擴容處理
else if (s > threshold)
resize();
// 將m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
// 得到的key 和 value 放入 hashmap
putVal(hash(key), key, value, false, evict);
}
}
}
注意:
面試問題:float ft = ((float)s / loadFactor) + 1.0F; 這一行代碼中為什么要加 1.0F ?
(float)s/loadFactor 的結果是小數,加 1.0F 與 (int)ft 相當于是對小數做一個向上取整以盡可能的保證更大容量,更大的容量能夠減少 resize 的呼叫次數(為了效率,應當盡量減少擴容的次數),所以 + 1.0F 是為了獲取更大的容量,
例如:原來集合的元素個數是 6 個,那么 6/0.75 是8,由于8是 2 的n次冪,那么
if (t > threshold) threshold = tableSizeFor(t);執行過后,新的陣列大小就是 8 了,然后原來陣列的資料就會存盤到長度是 8 的新的陣列中了,這樣會導致在存盤元素的時候,容量不夠,還得繼續擴容,那么性能降低了,而如果 +1 呢,陣列長度直接變為16了,這樣可以減少陣列的擴容,
由于篇幅太長,不易閱讀,我分成兩篇文章:JDK集合原始碼之HashMap決議(下)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/204136.html
標籤:python