大家都知道硬碟的隨機IO很慢,但是比順序IO慢多少呢,不知道你是否有過數字上的直接對比,今天我來實際壓測對比一下磁盤在順序IO和隨機IO不同場景下的性能資料表現,通過今天的實驗資料,你將能深刻理解資料庫事務中為什么要用日志的方式來實作,為什么索引中要用節點更大的B+樹,
對于任何存盤系統,性能指標無非就是帶寬、延遲或IOPS,我的測驗機器的硬碟配置是一個由7塊300G萬轉機械磁盤組成的RAID5,壓測工具使用的fio,壓測程序中,我們固定幾個引數:
- IO引擎我們選擇libaio
- 為了避免作業系統管理的PageCache記憶體對測驗結果的干擾,使用direct引數繞開
- 打開unified_rw_reporting,讓結果中分別顯示讀和寫
- 為了保證測驗相對準確,我們運行時間設定為300s
- 由于服務器敏感性,壓測物件沒有選擇裸設備,用的檔案,會有一點檔案系統額外開銷
- 測驗檔案尺寸定義為100G,我的RAID卡快取是1G,目的就是讓它的命中率別太高
- 調度策略我們選擇最最常用的noop
- 打開refill_buffers,每次I/O提交后都重新生成測驗檔案資料片段,保證隨機性
- 按照RAID使用配置建議,關閉掉磁盤自帶快取
然后再對另外的引數進行動態調整,然后進行多次對比測驗
- 讀寫模式上,使用順序讀和隨機讀進行分別驗證
- 磁盤IO單位我們使用扇區的整數倍,512 1K 2K ...
- RAID卡預讀策略,分別設定NORA(不開啟預讀)和RA(開啟預讀)來獨立測驗
順序讀取測驗
我們先來看一下順序讀取情況下,在該磁盤陣列的帶寬表現,見圖1:

可以看到,當IO size比較小的時候,即使是順序發起連續IO請求,帶寬表現也不算給力,只有不到20MB/s,隨著IO size增加的時候,帶寬也上來了,最大能夠達到1.2GB多,
大家注意看下在NORA情況下,在128K增加到256K的時候,帶寬突然增加了很多,這是為啥呢?秘密在于我的RAID陣列里的條帶大小是128K,當IO size為256K的時候,磁盤陣列才開始真正并行作業了,IO size小的時候,并不能發揮多盤優勢,
/opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -aALL
......
Strip Size : 128 KB
另外就是對于順序IO的情況,RA預取也能起到一些作用,在IO size在64k的時候就能夠達到1.2GB的帶寬,
我們再來看延遲,見圖2:

我們圖中的單位是微秒-us,在《簡單聊聊磁盤磁區》中,我對磁盤耗時進行過理論上的估算,磁盤耗時主要在兩個地方:
- 尋道時間:3-15ms,這個耗時可以通過合理磁區優化
- 旋轉延遲:萬轉磁盤這個延遲大概0-6ms
為什么在圖2實驗結果里,延時卻都很低,在IO size為512的時候,平均竟然只有30us左右?其實順序IO的情況下,RAID卡快取命中率很高,其實絕大部分的讀請求并沒有穿透到讓磁盤的機械軸來作業,
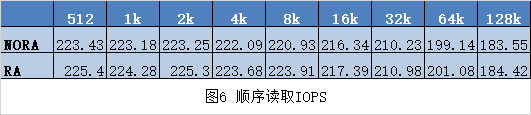
我們再來看IOPS,見圖3:

在IO請求size正好為1個扇區大小的時候,磁盤陣列的IOPS表現最高,達到了3W多次每秒,當IO size增加的時候,IOPS在逐步下降,但這時候,其實磁盤的吞吐是在增加的,
匯總一下,磁盤陣列在順序IO的情況下表現還是很不錯的,原因有三個:
- 順序IO的情況下,RAID卡的命中率高,尤其是設定了RAID預取
- 單盤本身順序IO也是磁盤作業最舒服的狀態,因為節約了尋道的延時
- 當IO超過RAID條狀大小的時候,IO會分散到多塊盤上并行處理
隨機讀取測驗
我們作為開發者使用磁盤的時候,可能不一定能保證永遠都能讓它作業在最舒服的狀態,有些時候可能也必須得讓它進行隨機訪問,所以我們今天也試一下我的磁盤陣列在隨機情況下的表現,對于fio工具來說只需要設定rw引數為randread既可,不過IO size我只測驗到了128就停了,因為再大了就越像順序IO了,
我們還是先來看帶寬,見圖4:

機械硬碟即使是組成了RAID陣列,而且還有快取,貌似對隨機IO也無可奈何,在隨機IO的情況下,帶寬吞吐糟糕透了,在IO size比較小的時候,竟然只有零點幾兆每秒,
我們再來看延時,見圖5:

隨機情況下延時基本都5ms左右,這就和我們前面理論上的計算結果對上了,隨機訪問導致更多的請求真正穿透到了機械軸上,
再來看IOPS,這個指標也很差,也就是200左右吧,這個資料和圖5的延遲形成了呼應,處理一次請求5ms左右,那么1秒可不就是只能處理200次左右么,所以硬碟廠家們天天給你吹風,說他家磁盤IOPS能達到幾萬幾萬,但是他們從來閉口不提隨機IO情況下,其實特么的只有200,
大家看到了我的萬轉機械硬碟組成RAID5陣列,在順序條件最好的情況下,帶寬可以達到1GB/s以上,平均延時也非常低,最低只有20多us,但是在隨機IO的情況下,機械硬碟的短板就充分暴露了,零點幾兆的帶寬,將近5ms的延遲,IOPS只有200左右,其原因是因為
- 隨機訪問直接讓RAID卡快取成了個擺設
- 磁盤不能并行作業,因為我的機器RAID寬度Strip Size為128 KB
- 機械軸也得在各個磁道之間跳來跳去,
理解了磁盤順序IO時候的幾十M甚至一個GB的帶寬,隨機IO這個真的是太可憐了,
結論
從上面的測驗資料中我們看到了機械硬碟在順序IO和隨機IO下的巨大性能差異,在順序IO情況下,磁盤是最擅長的順序IO,再加上Raid卡快取命中率也高,這時帶寬表現有幾十、幾百M,最好條件下甚至能達到1GB,IOPS這時候能有2-3W左右, 到了隨機IO的情形下,機械軸也被逼的跳來跳去尋道,RAID卡快取也失效了,帶寬跌到了1MB以下,最低只有100K,IOPS也只有可憐巴巴的200左右,
如果你真正理解了以上實驗中的資料,就能理解很多工程實踐中的許多的事情,
復制檔案夾:我們都知道,在復制一個檔案夾的時候,如果這個檔案夾里面包含了許多堆碎檔案,這時候復制起來非常慢,原因就是這時候機械硬碟大概率都是在隨機IO,怎么提高復制速度呢?很簡單,就是把它們先打一個包,打包之后這個檔案夾就變成一個大檔案了,這時候再復制的話,磁盤就是執行的最擅長的順序IO了,所以會快很多,
資料庫事務:所有的資料庫在實作事務的時候,都要保證寫資料落盤成功才能回傳,但為什么他們幾乎都是落盤到自己的事務日志檔案里去就回傳成功的,而不是直接寫入到資料表檔案里,這背后的原因還是磁盤讀寫性能問題,事務只需要保證資料落地成功就可以,至于寫到哪里并不重要,寫到資料檔案中的話大概率就變成隨機IO了,如果寫到一個日志檔案中,就是地地道道的順序IO,性能就發揮到極致,
Mysql的B+樹:在上面的資料中大家還可以看到,無論是順序IO還是隨機IO,只要增加每次IO的單位,性能都會上漲,理解了這個,你就能真正理解為什么Mysql是采用B+樹當索引,而不是用其它的樹了(比如二叉樹),因為B+樹的節點更大,IO起來會讓磁盤作業更舒服一些,
最后結尾我想分享一個5年前我在工程中實際性能優化的案例,當時接手了一個系統,要用數以百萬級的用戶imei,到Mysql中去查詢用戶的另一個字串id(clientid)資料,前開發的實作方式是傳統的分批進行Mysql陳述句查詢,這種實作下,且不說多次的網路RTT耗時,單說Mysql查詢,即使是有索引這時候也得需要進行大量的隨機IO,因為用戶imei是隨機分布的,我采用的優化方式也非常簡單,直接把Mysql用戶整張用戶表一次性通過順序IO的方式讀出來,load到記憶體中,在記憶體中用HashTable組織好,通過Hash的方式進行快速查詢,最終耗時優化掉了90%以上,

開發內功修煉之硬碟篇專輯:
- 1.磁盤開篇:扒開機械硬碟堅硬的外衣!
- 2.磁盤磁區也是隱含了技術技巧的
- 3.我們怎么解決機械硬碟既慢又容易壞的問題?
- 4.拆解固態硬碟結構
- 5.新建一個空檔案占用多少磁盤空間?
- 6.只有1個位元組的檔案實際占用多少磁盤空間
- 7.檔案過多時ls命令為什么會卡住?
- 8.理解格式化原理
- 9.read檔案一個位元組實際會發生多大的磁盤IO?
- 10.write檔案一個位元組后何時發起寫磁盤IO?
- 11.機械硬碟隨機IO慢的超乎你的想象
- 12.搭載固態硬碟的服務器究竟比搭機械硬碟快多少?
我的公眾號是「開發內功修煉」,在這里我不是單純介紹技術理論,也不只介紹實踐經驗,而是把理論與實踐結合起來,用實踐加深對理論的理解、用理論提高你的技術實踐能力,歡迎你來關注我的公眾號,也請分享給你的好友~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/204215.html
標籤:PHP
下一篇:理解記憶體對齊