目標
ZooKeeper 很流行,有個基本的疑問:
- ZooKeeper 是用來做什么的?
- 之前沒有ZK,為什么會誕生 ZK?
OK,解答一下上面的疑問:(下面是憑直覺說的)
- ZooKeeper 是用于簡化分布式應用開發的,對開發者屏蔽一些分布式應用開發程序中的底層細節
- ZooKeeper 對外暴露簡單的 API,用于支持分布式應用開發
- ZooKeeper 在提供上述功能的同時,其還是一個 高性能、高可用、高可靠的分布式集群
上面說這么多,總結一下,ZK 能解決分布式應用開發的問題,ZK 能很好的解決問題, 到這一步,疑問就更多了:
- 分布式應用開發,有哪些常見問題?ZK 是如何屏蔽這些底層細節的?
- ZooKeeper 對外暴露了那些 API?這些 API 如何支持分布式應用開發的?這些 API 還能簡化嗎?API 的語意性怎么樣?
- ZooKeeper 自身是一個高性能、高可用、高可靠的分布式集群,那有個簡單的問題:
- 高性能是指什么?ZooKeeper 為了達到高性能,做了哪些作業?
- 高可用同上
- 高可靠同上
Note:本篇 wiki 就是為了解決上述第一個疑問的,(其他疑問會在其他 blog 中逐步解答)
為什么有 ZooKeeper
一個應用程式,涉及多個行程協作時,業務邏輯代碼中混雜有大量復雜的行程協作邏輯,
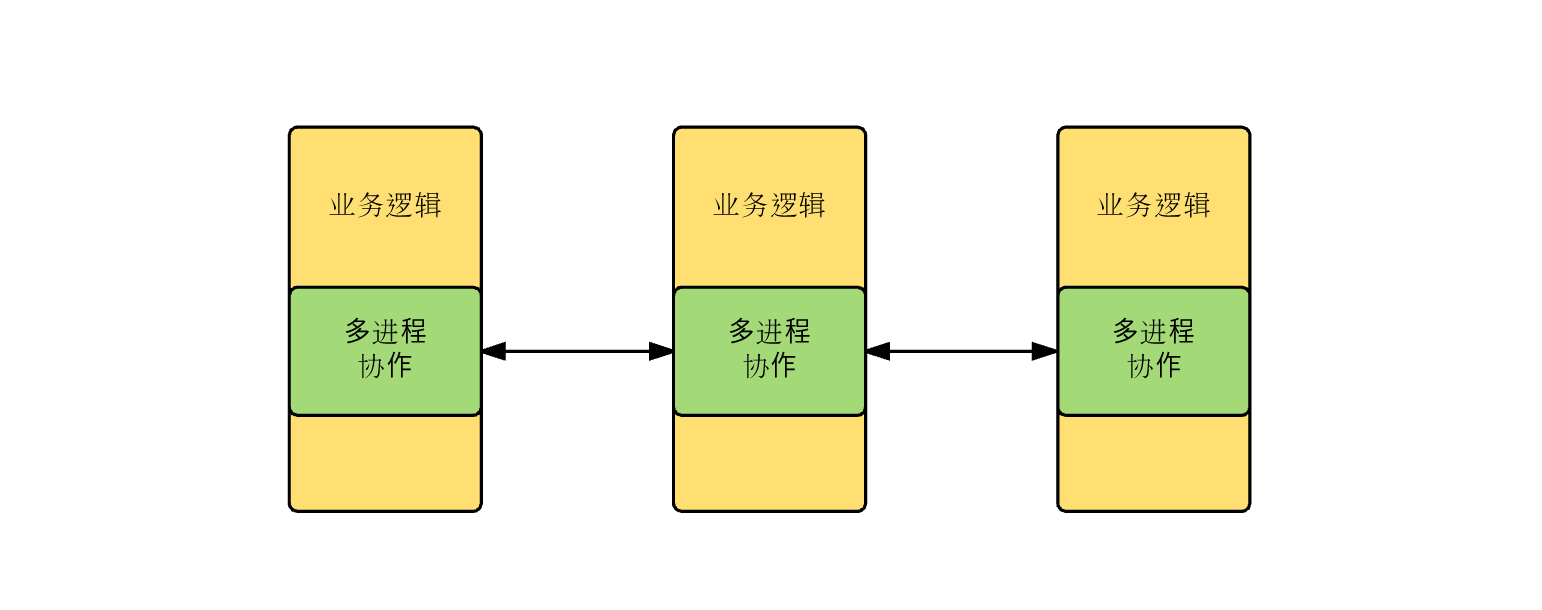
上述多行程協作邏輯,有 2 個特點:
- 處理復雜
- 處理邏輯可重用
因此,考慮將多行程協作的共性問題拎出,作為基礎設施,讓 RD 更加專注業務邏輯開發,即:
ZooKeeper 就是上述多行程協作基礎服務的一種,
ZooKeeper 的特點
ZooKeeper 有幾個簡單特點:
- ZooKeeper 的 API:從 檔案系統 API 得到的啟發,提供簡單的 API
- ZooKeeper 運行在專用服務器上,跟業務邏輯分離,保證了高容錯性和可擴展性
ZooKeeper 是存盤設施,但特別注意
- ZK上存盤的資料聚焦為:
協作資料(元資料),而不是應用資料,應用資料有自己的存盤方案,例如 HDFS 等 - ZK 本質上,可以看作一種
特殊的 FS
特別說明:
應用資料和元資料,由于使用場景不同,對一致性和持久性的要求有差異, 因此,架構設計、資料治理程序中,應將 2 類資料獨立看待、獨立存盤,
ZooKeeper 的使命
ZK 要解決的核心問題:
ZK 目標:簡化分布式應用開發中,多行程協作問題,為分布式應用,提供
高效、可靠的分布式協調服務(基礎服務),例如:
- 統一的命名服務
- 分布式鎖
- 行程崩潰檢測
- Leader 選舉
- 配置管理:配置變更時,及時下發到各個 Client,
一個簡單的問題:多行程的協作是什么?尼瑪呀,有完沒完,啥問題你都有,面對這個掉咋天的腦殼,還是回答一下,
多行程協作,整體分為 2 類:
- 協作:多行程需要一同處理某些事情,一些行程采取行動是的其他行程能夠正常作業,例如:主從結構,M 向 S 分配任務,S 才會執行,否則 S 就保持空閑狀態
- 競爭:兩個行程不能同時作業,一個行程必須等待另個行程執行完畢,例如:主從結構,M 節點失效后,很多 S 都想成為 M,這時,就需要互斥鎖,只有第一個獲得鎖的 S 成為 M
特別說明:
- 不跨網路協作:多行程,可以在同一臺物理主機上,同步原語很方便(比如?管道、共享記憶體、訊息佇列、信號量)
- 跨網路協作:多行程,分布在不同的物理主機上,ZK 關注這一類
跨網路多行程協作,行程通信,基本思路有 2 個:
- 訊息機制:通過網路,直接資訊交換,多訊息傳遞演算法,實作同步原語
- 共享存盤:利用外部共享存盤,實作多行程協作,要求
共享存盤提供有序訪問,ZK 采用這種方式
真實系統中,跨網路通信,有幾個共性問題:
- 訊息延遲:由于網路原因,后發送先到達
- 處理器性能:由于系統調度原因,訊息到達后,延遲處理
- 時鐘偏移:不同物理主機,時鐘發生偏移
ZK 精心設計用于屏蔽上述 3 個共性問題,使得這些問題在應用服務層面完全透明化,
ZooKeeper 特性
ZooKeeper 解決的本質問題
分布式系統的一致性問題:
- 訊息傳遞:延遲性,先發送的訊息,不一定先到達;
- 訊息傳遞:丟失性,發送的訊息,可能丟失;
- 節點崩潰:分布式系統內,任何一個節點都可能崩潰;
在這種情況下,如何保證資料的一致性?
- 提案投票:基于投票策略,2PC
- 選舉投票:基于投票策略,投出
優先級最高的節點(包含最新資料的節點)
Paxos 目標:解決
分布式一致性問題,提高分布式系統容錯性的一致性演算法,Paxos 本質:基于
訊息傳遞的高度容錯的一致性演算法
ZooKeeper 定位
ZooKeeper 是:
- 分布式協調服務
- 高效、可靠
- 方便應用程式,聚焦
業務邏輯開發,而不需要過多關注分布式行程間協作細節
ZooKeeper 不直接暴露原語,而是,暴露一部分呼叫方法組成的 API,類似檔案系統的 API,支持應用程式實作自己的原語,
ZooKeeper 特性
ZooKeeper 可以保證如下分布式一致性特性:
- 順序一致性:同一個 Client 發起的事務請求,嚴格按照發起順序執行
- 原子性:事務請求,要么應用到所有節點,要么一個節點都沒有應用
- 單一視圖:Client 無論連接到哪個節點,看到的服務端資料都是一致的(Note:不準確,其實是最終一致性)
- 可靠性:事務一旦執行成功,狀態永久保留
- 實時性:事務一旦執行成功,Client 并不能立即看到最新資料,但 ZooKeeper 保證最終一致性
ZooKeeper 設計目標
ZooKeeper 致力于提供高性能、高可用、順序一致性的分布式協調服務,保證資料最終一致性,
目標一:高性能(簡單的資料模型)
- 采用
樹形結構組織資料節點; - 全量資料節點,都存盤在記憶體中;
- Follower 和 Observer 直接處理非事務請求;
目標二:高可用(構建集群)
- 半數以上機器存活,服務就能正常運行
- 自動進行 Leader 選舉
目標三:順序一致性(事務操作的順序)
- 每個事務請求,都會轉發給 Leader 處理
- 每個事務,會分配全域唯一的遞增id(zxid,64位:epoch + 自增 id)
目標四:最終一致性
- 通過提議投票方式,保證事務提交的可靠性
- 提議投票方式,只能保證 Client 收到事務提交成功后,半數以上節點能夠看到最新資料
ZooKeeper 出現之前
ZK 出現之前,分布式系統常用兩種方式,實作多行程協作:
- 分布式鎖管理器
- 分布式資料庫
ZK 更專注于行程協作,而不提供任何鎖介面和通用的存盤資料介面,(疑問:ZK 也可以提供啊,我們不使用就行了)
應用服務器,常見的 2 種需求:
- Master-Slave Leader 選舉:要求提供Master節點選舉功能
- 行程回應跟蹤 崩潰檢測:要求提供行程存活狀態的跟蹤
- 分布式鎖:互斥排它鎖
ZK 為上述 2 種策略提供了基礎 API,
ZooKeeper 不適用的場景:
- 海量資料存盤:ZK 本質是
特殊的 FS,但 ZK 用于存盤元資料,需要單獨存盤應用資料
術語介紹
| 術語 | 解釋 |
|---|---|
| 分布式系統 | 跨多個物理主機,由多個獨立運行的節點組成的系統 |
| 原語 | 業務上不可分割的元素/程序,舉例:分布式鎖原語,可以暴露創建、查詢、釋放幾個方法 |
參考來源
- ZooKeeper-Distributed Process Coordination Chapter 1 簡介
- 從Paxos到Zookeeper分布式一致性原理與實踐 Chapter 4 初識 ZooKeeper
近期熱文推薦:
1.Java 15 正式發布, 14 個新特性,重繪你的認知!!
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.我用 Java 8 寫了一段邏輯,同事直呼看不懂,你試試看,,
4.吊打 Tomcat ,Undertow 性能很炸!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/205037.html
標籤:Java
上一篇:Java從零進階自學路線圖