大資料技術原理與應用
思維導圖
第一章 大資料概述
1、三次資訊化浪潮
| 資訊化浪潮 | 發生時間 | 標志 | 解決的問題 | 代表企業 |
|---|---|---|---|---|
| 第一次浪潮 | 1980年前后 | 個人計算機 | 資訊處理 | Intel、AMD、IBM |
| 第二次浪潮 | 1995年前后 | 互聯網 | 資訊傳輸 | 雅虎、谷歌、阿里巴巴 |
| 第三次浪潮 | 2010年前后 | 物聯網、云計算和大資料 | 資訊爆炸 | 亞馬遜、谷歌、阿里云 |
注:資訊化浪潮每15年一次,
2、資訊科技為大資料時代提供技術支持
-
存盤設備容量不斷增加
存盤單位:bit、Byte、KB、MB、GB、TB、PB、EB(ZB、YB、BB、NB、DB)
-
CPU處理能力大幅提升
-
網路帶寬不斷增加
3、大資料的特點(5個)
- 資料量大(Volume)
- 資料型別繁多(Variety)
- 處理速度快(Velocity)
- 價值密度低(Value)
- 真實性(Veracity)
4、大資料的影響
1、大資料對科學研究的影響
人類自古以來在科學研究上先后經歷了實驗、理論、計算和資料四種范式:
- 第一種范式:實驗科學
- 第二種范式:理論科學
- 第三種范式:計算科學
- 第四種范式:資料密集型科學
2、大資料對思維方式的影響
- 全樣而非抽樣
- 效率而非精確
- 相關而非因果
5、大資料關鍵技術
- 資料采集與預處理
- 資料存盤和管理
- 資料處理與分析
- 資料安全和隱私保護
6、大資料計算模式
| 大資料計算模式 | 解決問題 | 代表產品 |
|---|---|---|
| 批處理計算 | 針對大規模資料的批量處理 | MapReduce、Spark等 |
| 流計算 | 針對流資料的實時計算 | Strom、Stream、銀河流資料處理平臺等 |
| 圖計算 | 針對大規模圖結構資料的處理 | Pregel、GraphX、PowerGraph等 |
| 查詢分析計算 | 大規模資料的存盤管理和查詢分析 | Dremel、Hive等 |
7、云計算
1、概念
通過網路提供可伸縮的、廉價的分布式計算能力
2、云計算的關鍵技術
- 虛擬化:云計算基礎架構的基石
- 分布式存盤
- 分布式計算
- 多租戶
8、物聯網
1、概念
物物相連的互聯網
從技術架構上來看,物聯網可分為四層:感知層、網路層、處理層和應用層
2、物聯網關鍵技術
- 識別和感知技術(二維碼、RFID、傳感器等)
- 網路與通信技術
- 資料挖掘與融合技術
9、大資料與云計算、物聯網的關系
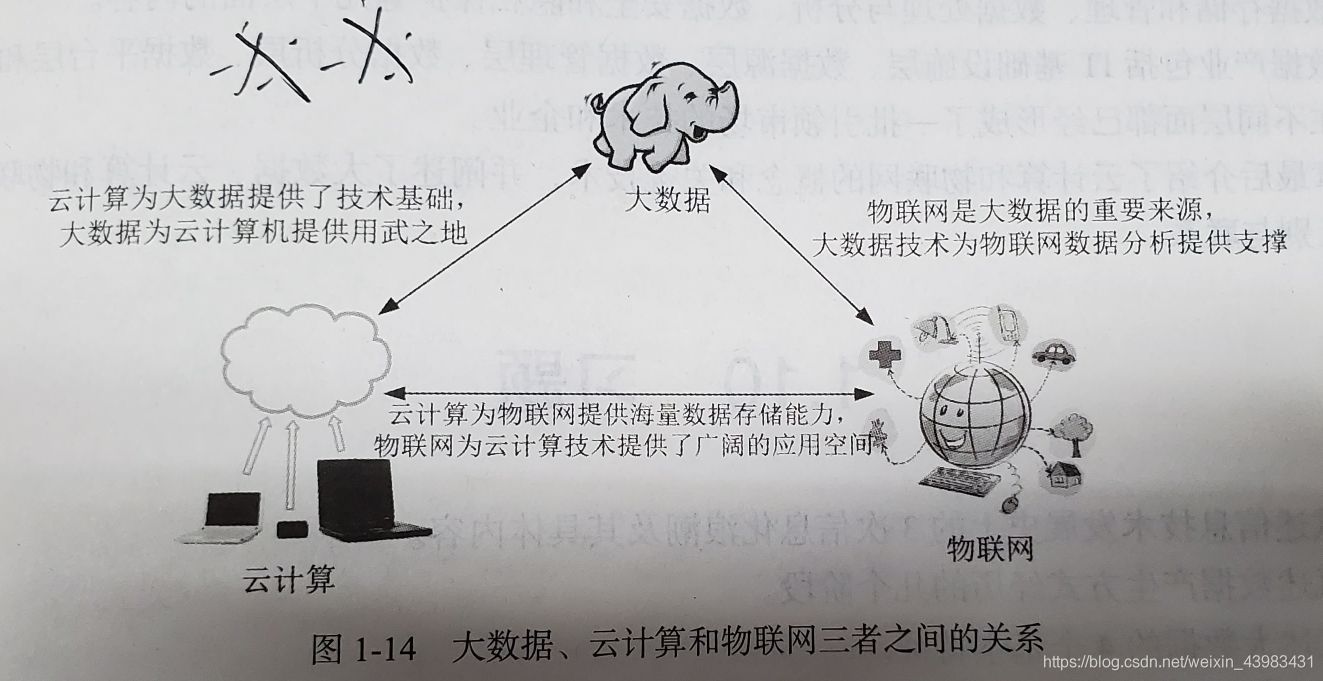
- 區別:大資料側重于海量資料的存盤、處理與分析,從海量資料中發現價值,服務于生產和生活;云計算本質上旨在整合和優化各種IT資源,并通過網路以服務的方式廉價地提供給用戶;物聯網的發展目標是實作物物相連,應用創新是物聯網發展的核心,
- 聯系:大資料、云計算和物聯網三者相輔相成,大資料根植于云計算,大資料分析的很多技術都來自于云計算,云計算的分布式資料存盤和管理系統提供了海量資料的存盤和管理能力,分布式并行處理框架MapReduce提供了海量資料的分析能力;大資料為云計算提供了“用武之地”;物聯網的傳感器源源不斷產生的大量資料,構成了大資料的重要來源,同時物聯網需要借助于云計算和大資料技術,實作物聯網大資料的存盤、分析和處理,
第二章 大資料處理框架Hadoop
1、Hadoop簡介
Hadoop是一個開源分布式計算平臺
Hadoop的核心包括:HDFS(前身:NDFS)和MapReduce,
2、Hadoop的特性
- 高可靠性
- 高效性
- 高擴展性
- 高容錯性
- 成本低
- 運行在Linux平臺上
- 支持多種編程語言
第三章 分布式檔案系統HDFS
1、HDFS含義
Hadoop分布式檔案系統,是GFS的開源實作
2、DFS含義
分布式檔案系統(DFS)是一種通過網路實作檔案在多臺主機上進行分布式存盤的檔案系統
3、分布式檔案系統的結構
- 主節點(Master Node):名稱節點(NameNode)
- 從節點(Slave Node):資料節點(DataNode)
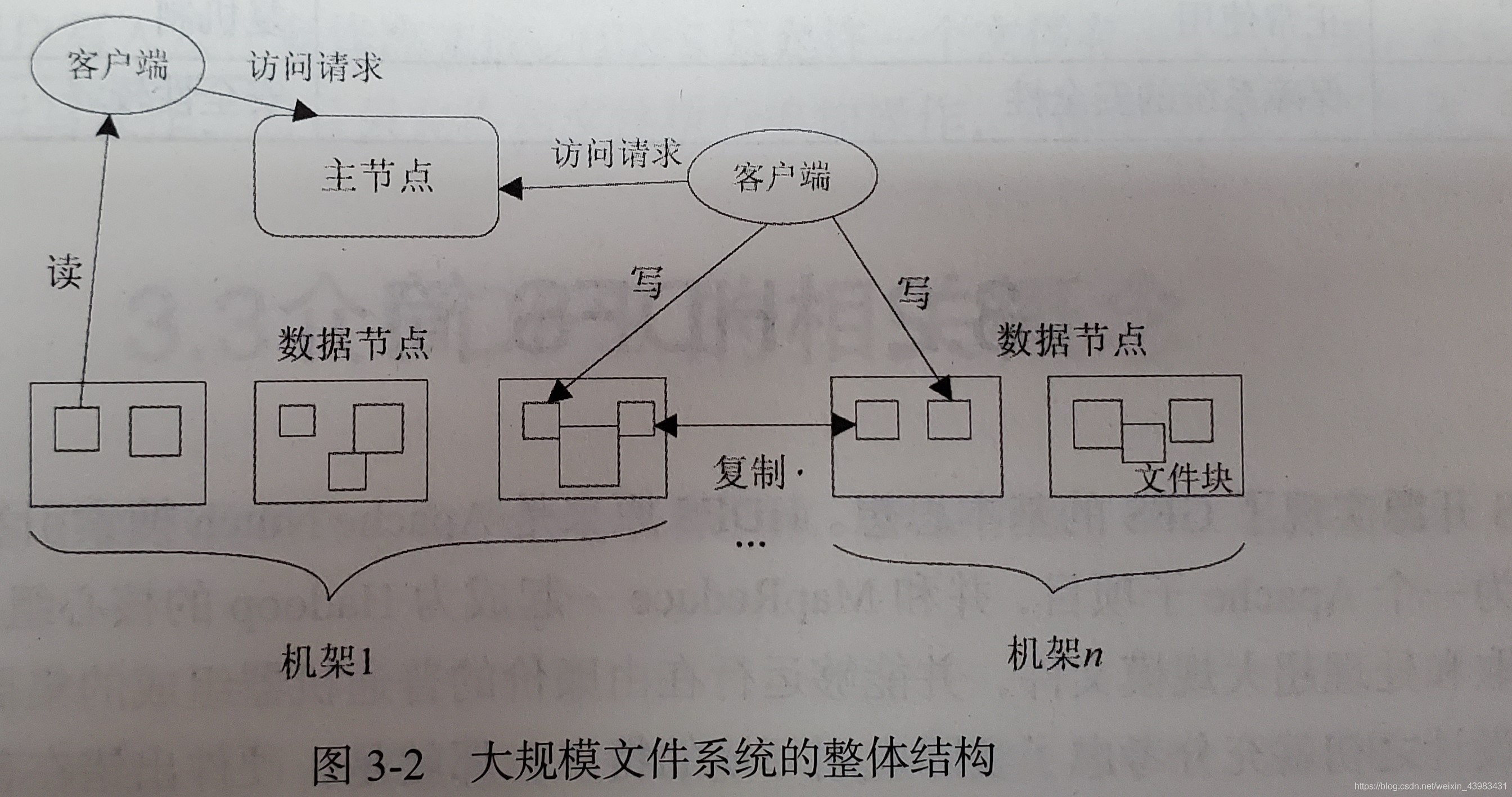
4、分布式檔案系統的設計需求
分布式檔案系統的設計目標主要包括:透明性、并發控制、可伸縮性、容錯以及安全需求等,
5、HDFS特性
1、目標
- 兼容廉價的硬體設備
- 流資料讀寫
- 大資料集
- 簡單的檔案模型
- 強大的跨平臺兼容性
2、局限性
- 不適合低延遲資料訪問
- 無法高效存盤大量小檔案
- 不支持多用戶寫入及任意修改檔案
6、HDFS相關概念
1、塊
以資料塊為單位進行存盤(1.0默認64MB)
**目的:**最小化尋址開銷
好處:
- 支持大規模檔案存盤
- 簡化系統設計
- 適合資料備份
2、名稱節點和資料節點
名稱節點的核心資料結構:FsImage和EditLog,
| NameNode | DataNode |
|---|---|
| 存盤元資料 | 存盤檔案內容 |
| 元資料存在記憶體中 | 檔案內容保存在磁盤中 |
| 保存檔案Block于DataNode間的映射關系 | 維護Block與DataNode本地檔案的映射關系 |
3、第二名稱節點
作用:
- Edit log與FsImage的合并操作
- 作為名稱節點的“檢查點”(冷備份)
7、HDFS體系結構
1、HDFS命名空間管理
HDFS的命名空間包含目錄、檔案和塊,
HDFS集群中只有一個命名空間,并且只有唯一一個名稱節點,
2、通信協議
- 構建在TCP/IP協議基礎之上
- 使用客戶端協議與名稱節點進行互動
- 名稱節點和資料節點之間使用資料節點協議進行互動
- 客戶端與資料節點的互動通過RPC實作
3、局限性
- 命名空間的限制
- 性能的瓶頸
- 隔離問題
- 集群的可用性
8、HDFS的存盤原理
資料的冗余存盤、資料存取策略、資料錯誤與恢復
1、資料的冗余存盤
優點:
- 加快資料傳輸速度
- 容易檢查資料錯誤
- 保證資料的可靠性
2、資料存取策略
1、資料存放
冗余因子默認為3,
**內部請求:**第一個副本放置在寫操作請求的資料節點上;
**外部請求:**挑一個不太忙的資料節點,第二個副本放置在不同于第一個副本的機架的資料節點上,第三個副本放置在第一個副本的機架的其他資料節點上,
2、資料讀取
當發現某個資料塊副本對應的機架ID與客戶端對應的ID一樣時,優先選擇該副本,否則就隨機,
3、資料復制
采用流水線復制的策略(4KB)
3、資料錯誤與恢復
9、HDFS常用命令
- hadoop fs -get
- hadoop fs -put
第四章 分布式資料庫HBase
1、HBase含義
Hadoop DataBase(HBase)是針對谷歌BigTable的開源實作,
2、HBase與傳統關系資料庫的對比分析
| 關系資料庫 | HBase | |
|---|---|---|
| 資料型別 | 具有豐富的資料型別和存盤方式 | 未經解釋的字串 |
| 資料操作 | 豐富的操作 | 不存在復雜的表與表之間的關系 |
| 存盤模式 | 基于行模式存盤 | 基于列存盤 |
| 資料索引 | 可以構建復雜的多個索引 | 只有一個索引——行鍵 |
| 資料維護 | 更新操作會用最新的當前值去替代舊值 | 生成一個新的版本,舊有版本依然保留 |
| 可伸縮性 | 很難實作橫向擴展,縱向擴展空間有限 | 可實作靈活的水平擴展 |
3、HBase資料模型
1、相關概念
HBase是一個稀疏、多維、持久化存盤的映射表,它采用行鍵、列族、列限定符和時間戳進行索引,
2、資料坐標
“四維坐標”:[行鍵,列族,列限定符,時間戳]
4、HBase實作原理
1、HBase的功能組件
- 庫函式
- 一個Master主服務器
- 許多個Region服務器
2、Region的定位
Region識別符號:“表名+開始主鍵、RegionID”
5、HBase運行機制
1、HBase系統架構
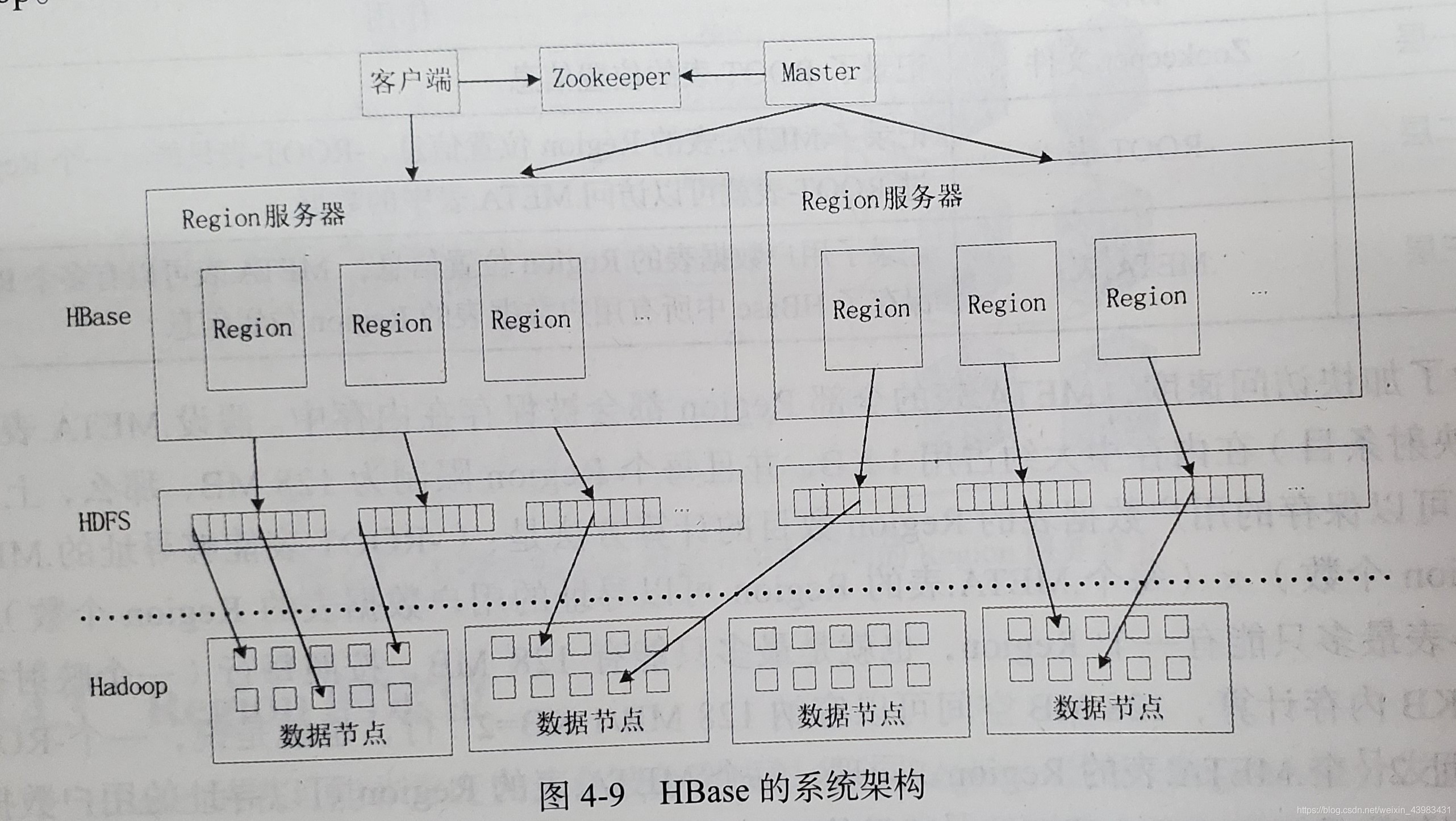
2、Region服務器的作業原理
每個Region物件又是由多個Store組成的,每個Store對應了表中的一個列族的存盤,
每個Store又包含了一個MemStore和若干個StoreFile,
6、HBase常用Shell命令
- create:創建表
- list:列出HBase中所有的表資訊
- put:向表、行、列指定的單元格添加資料
- get:通過指定表名、行、列、時間戳、時間范圍和版本號來獲得相應單元格的值
- scan:瀏覽表的相關資訊
第五章 NoSQL資料庫
1、NoSQL簡介
1、含義
Not Only SQL
2、特點
- 靈活的可擴展性
- 靈活的資料模型
- 與云計算緊密融合
2、NoSQL的四大型別
| 型別 | 代表 |
|---|---|
| 鍵值資料庫 | Redis、Memcached |
| 列族資料庫 | Cassandra、HBase |
| 檔案資料庫 | MongoDB |
| 圖資料庫 | Neo4j |
3、NoSQL的三大基石
1、CAP
- C(Consistency):一致性
- A(Availability):可用性
- P(Tolerance of Network Partition):磁區容忍性
CAP理論最多同時滿足三個中的兩個,
-
CA,強調一致性(C)和可用性(A),放棄磁區容忍性(P),
eg:傳統的關系資料庫(MySQL、SQL Server等),
-
CP,強調一致性(C)和磁區容忍性(P),放棄可用性(A),
eg:Neo4j、BigTable和HBase等,
-
AP,強調可用性(A)和磁區容忍性(P),放棄一致性(C),
eg:Cassandra、Dynamo等,
2、BASE
BASE
- BA(Basically Available):基本可用
- S(Soft-state):軟狀態
- E(Eventual consistency):最終一致性
ACID:一個資料庫事務具有ACID四性
- A(Atomicity):原子性
- C(Consistency):一致性
- I(Isolation):隔離性
- D(Durability):持久性
4、三個資料庫陣營
- OldSQL(傳統關系資料庫)
- NoSQL
- NewSQL
第六章 云資料庫
1、云資料庫概念
云資料庫是部署和虛擬化在云計算環境中的資料庫,
2、云資料庫的特性
- 動態可擴展
- 高可用性
- 較低的使用代價
- 易用性
- 高性能
- 免維護
- 安全
第七章 MapReduce
1、MapReduce簡介
MapReduce是一種分布式并行編程框架,以Map和Reduce為核心函式,
MapReduce的設計理念:計算向資料靠攏,
Map函式和Reduce函式都以<key,value>作為輸入,
2、MapReduce的作業流程
第八章 Hadoop再探討
1、針對Hadoop的改進與提升
| 組件 | 1.0的問題 | 2.0的改進 |
|---|---|---|
| HDFS | 單一名稱節點,存在單點失效問題 | 設計了HDFS HA,提供名稱節點熱備份機制 |
| HDFS | 第一命名空間,無法實作資源隔離 | 設計了HDFS聯邦,管理多個命名空間 |
| MapReduce | 資源管理效率低 | 設計理新的資源管理框架YARN |
2、HDFS 2.0的新特性
1、HDFS HA
2、HDFS聯邦
優勢:
- HDFS集群可擴展性
- 性能更高效
- 良好的隔離性
3、新一代資源管理調度框架YARN
1、YARN體系結構
YARN體系結構包含了三個組件:
- ResourceManager
- ApplicationMaster
- NodeManager
2、YARN的發展目標
YARN的目標就是實作“一個集群多個框架”,即在一個集群上部署一個統一的資源調度管理框架YARN,在YARN之上可以部署其他各種計算框架,
3、Hadoop生態系統中具有代表性的功能組件
1、Pig
提供了類似SQL的Pig Latin語言,
Pig會自動把用戶撰寫的腳本轉換成MapReduce作業在Hadoop集群上運行,
2、Tez
Tez是Apache開源的支持DAG作業的計算框架,
核心思想:將Map和Reduce兩個操作進一步拆分,
3、Kafka
一種分布式發表訂閱訊息系統,
滿足在線實時處理和批量離線處理,
第九章 Spark
1、Spark簡介
Spark是基于記憶體計算的大資料并行計算框架,
特點:
- 運行速度快
- 容易使用
- 通用性
- 運行模式多樣
2、Scala簡介
Scala是一門多范式編程語言,面向函式編程,
3、Spark運行架構
1、基本概念
- RDD:彈性分布式資料集
- DAG:有向無環圖
2、RDD
**概念:**分布式物件集合,
依賴關系:
- 窄依賴:一個父RDD的磁區對應于一個子RDD的磁區,或多個父RDD的磁區對應于一個子RDD的磁區;
- 寬依賴:存在一個父RDD的一個磁區對應于一個子RDD的多個磁區,
第十章 流計算
1、流計算概述
1、流計算概念
流計算即針對流資料的實時計算,
2、批量處理和實時處理
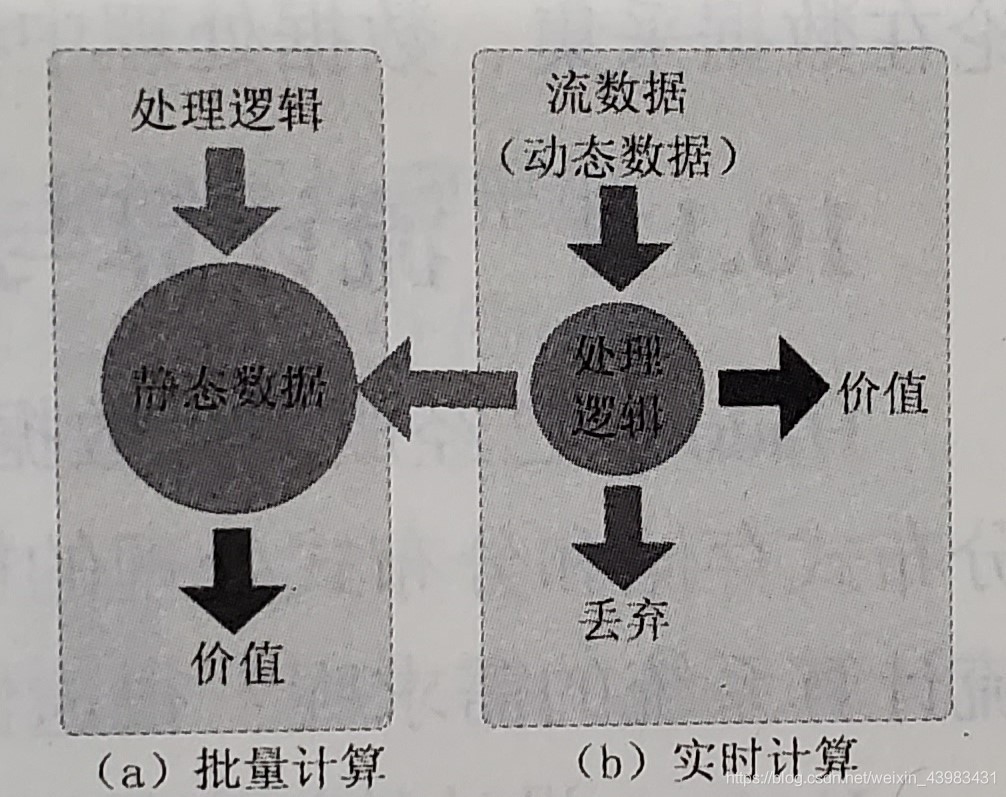
2、流計算的處理流程
- 資料實時采集
- 資料實時計算
- 實時查詢服務
3、開源流計算框架Storm
Storm的設計思想:
-
Streams
流資料(Streams)是一個無限的Tuple序列,
-
Spouts
Spouts是Stream的源頭,會從外部讀取流資料并持續發出Tuple,
-
Bolts
Bolts既可以處理Tuple,也可以將處理后的Tuple作為新的Streams發給其他Bolts,
-
Topology
Spouts和Bolts組成的網路,
-
Stream Groupings
用于告知Topology如何在兩個組件間進行Tuple的傳送,
4、Spark Streaming
Spark Streaming與Storm的對比
Spark Streaming無法實作毫秒級的流計算,而Storm則可以實作毫秒級回應,
第十一章 圖計算
1、圖計算概述
**含義:**對圖結構的計算,
**BSP模型:**整體同步并行計算模型,又名“大同步模型”,
一次BSP計算程序包括一系列全域超步(超步就是指計算中的一次迭代),每個超步包括3個組件:
- 區域計算
- 通信
- 柵欄同步
2、Pregel簡介
Pregel是一種基于BSP模型實作的并行圖處理系統,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/205167.html
標籤:python
上一篇:一份可以收割螞蟻、位元組、小米大廠offer的PDF檔案!
下一篇:不能讀入,請大佬分析一下