?Kali Linux 如何搭建 Hadoop平臺,Hadoop 偽分布安裝與使用
??大三的第一學期,用1~6周時間簡單的學習了解組成原理和計網,雖然結課的很匆忙,但是卻在第7周正式迎來了期待已久的 大資料專業課程,跟隨企業老師學習hadoop和spark,非常的有趣,
??課本是用Ubuntu講解的,但我個人并不喜歡Ubuntu,因為Ubuntu缺少不少東西,得重新安裝或者配置,可能是更適合初學者學習和使用吧,而我選擇的是 Kali Linux,一方面是因為這是我使用次數最多和最熟練的一款Linux了,另一方面是因為信仰,一種對資訊安全的信仰,也算最開始最純粹的初心吧(笑哭),
??好了,廢話不多說了,我們直奔主題!
??如下為我的搭建環境:kali的VMware虛擬機,版本:2020.3,
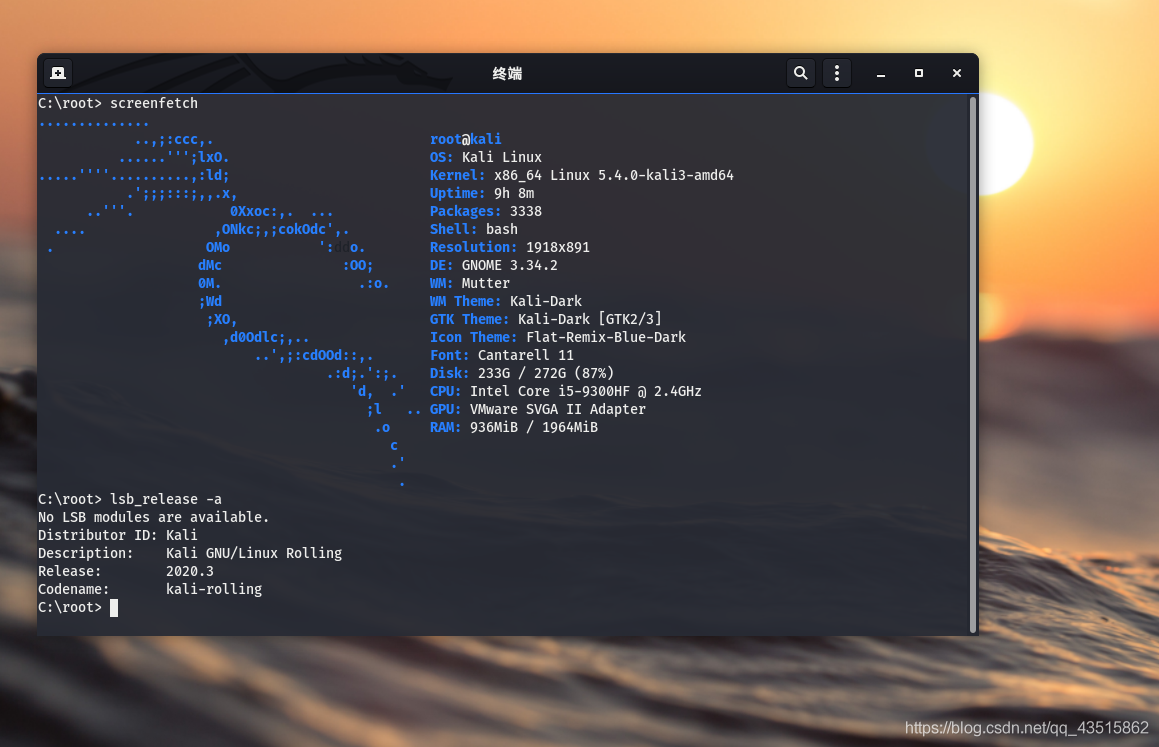
??首先,我們必須明確任務點:
?? ●擁有完善的java環境
?? ●ssh服務能夠正常運行
?? ●正式搭建Hadoop平臺
?? 一、Kali Linux安裝Java JDK :
??● 判斷是否安裝JDK:
?? kali默認是自帶了java的,如果不確定是否安裝了jdk,可以采用如下任意一條命令來檢測是否安裝java:
1.java -verson
2.whereis java(比which搜索范圍大一些,因為除查看PATH下可執行檔案外,還會查找源檔案和man檔案,適用于查找安裝好的命令,)
推薦前兩條命令,如何這兩條沒有出現java的結果,就已經說名沒有安裝jdk了,
3.$echo java (等同于which java命令,因為which也只是查找可直接執行的命令,可以查找別名,查找的就撰寫在系統PATH下的可執行檔案,which命令適用于查找安裝好的命令,)
當然也可以使用find和locate命令來查詢,不過這些都不是本文的重點,僅作簡單介紹,
??如果你的kali已經安裝了java,并且添加到了環境變數中,那么可以直接跳轉到第二大步驟了,
??● Kali 安裝Java JDK:
?? kali 安裝java的方法是和Ubuntu一樣的,有三種安裝方式,如果不懂朋友可以移步博主另一篇文章,有詳細的教程:Ubuntu Linux 安裝 java 的方法
??此處只為沒安裝的朋友提供解壓安裝的簡單教程:jdk-8u91-linux-x64百度網盤(提取碼:nqtg )
??(如果純小白不曉得如何把下載好的檔案移動到你的kali虛擬機內,我推薦三種方法:)
1.可以用kali自帶的火狐瀏覽器下載到你的kali;
2.了解如何使用vmwaretools,通過共享檔案夾來實作windows和Linux間的直接檔案傳輸;
3.百度kali如何使用Xftp 傳輸檔案,
??點到為止,不做過多贅述,
??xftp 6 百度網盤下載鏈接 ? 提取碼:n97a
??下載好jdk-8u91-linux-x64后,解壓和配置環境變數:
① 解壓:
tar zxvf jdk-8u91-linux-x64.tar.gz -C /opt
(opt是一個第三方軟體習慣安裝目錄,你也可以換其他的路徑解壓安裝,比如我習慣把第三方安裝在/home下)
tar -zxvf zxvf jdk-8u91-linux-x64.tar.gz -C /usr/lib/jvm
建議解壓在jvm目錄下,一般kali默認自帶的jdk也是在/usr/lib/jvm這個路徑的下,
② 配置環境變數:
1)執行vim /root/.bashrc,并添加以下內容:
# install JAVA JDK
export JAVA_HOME=/被解壓檔案所在路徑/jdk1.8.0_91
#例如,我的就是:
#export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_91
export CLASSPATH=.:${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
2)執行 source ~/.bashrc使環境變數生效,
③ 安裝并注冊:
update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_91
update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_91
update-alternatives --set java /usr/lib/jvm/jdk1.8.0_91
update-alternatives --set javac /usr/lib/jvm/jdk1.8.0_91
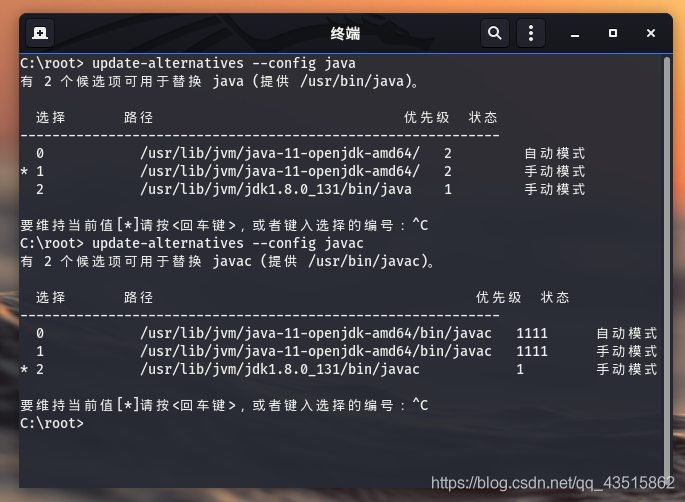
④ 檢測:
update-alternatives --config java
update-alternatives --config javac
java -version
#output
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
JDK成功無誤!
??當然,也可用根據我們課本這樣去安裝,或者是博主的另一篇更詳細的博文安裝:Debian系列Linux安裝JDK的三種方式,


?? 二、開啟SSH服務
?? ssh類似于遠程登陸,可從一臺Linux主機登陸到另一臺Linux主機,并且運行命令,SSH的在hadoop中的具體應用,讀者可以百度查閱集群免密登陸進一步學習了解,此處僅做簡要提示,
??在安裝hadoop之前需要配置ssh,因為集群和單節點模式都需要用到SSH登錄,Linux一般是默認自帶ssh的客戶端服務的,缺少的是服務端SSH server,如果不安裝SSH Server,已經、配置好的單節點SSH服務器和客戶端授權登錄,則無法啟動將要安裝的偽分布hadoop,
sudo apt-get install -y openssh-server #網路在線安裝
??● 判斷是否安裝SSH服務:
執行如下命令啟動ssh服務
sudo service ssh start
如果不能成功啟動,則說明未安裝ssh服務,
kali安裝ssh服務
# apt-get install ssh -y
啟用和開始使用 SSH
為了確保安全 shell 能夠使用,在重啟系統后使用systemctl命令來啟用它:
# reboot
# systemctl enable ssh
在當前對話執行中使用 SSH:
# service ssh start
??● 安裝SSH Server服務器:
# apt-get install openssh-server
配置SSH服務開機啟動
# update-rc.d -f ssh remove
# update-rc.d -f ssh defaults
# update-rc.d -f ssh enable 2 3 4 5
更改默認的SSH密鑰
# cd /etc/ssh
# mkdir ssh_key_backup
# mv ssh_host_* ssh_key_backup
創建新密鑰:
# dpkg-reconfigure openssh-server
允許 SSH Root 訪問
默認情況下 SSH 不允許以 root 用戶登錄,因此將會出現下面的錯誤提示資訊:
Permission denied, please try again.
??為了通過 SSH 進入你的 Kali Linux 系統,你可以有兩個不同的選擇,第一個選擇是創建一個新的非特權用戶然后使用它的身份來登錄,第二個選擇,你可以以 root 用戶訪問 SSH ,為了實作這件事,需要在SSH 組態檔 /etc/ssh/sshd_config 中插入下面這些行內容或對其進行編輯:
將
#PermitRootLogin prohibit-password
改為:
PermitRootLogin yes
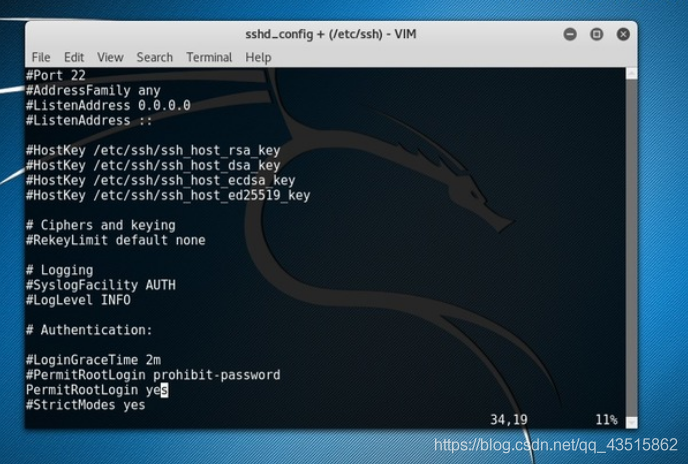
對 /etc/ssh/sshd_config 進行更改以后,需在以 root 用戶登錄 SSH 前重啟 SSH 服務:
# service ssh restart
查看是否安裝成功:
ssh -V
出現如下類似資訊,表示你很順利的安裝成功了!

SSH服務安裝開啟成功!
??● ssh登陸本機:
ssh localhost
??首次登陸SSH會提示,輸入"yes",按提示輸入密碼就登陸本機了,
如果此時報這種錯:
root@localhost's password:localhost:permission denied,please try again
就更改密碼后再次登陸:
# sudo passwd root # 注意此處的root為當前登錄本機所在的用戶名,不一定是root
# 更改成功后重啟服務:
sudo service ssh restart
ssh localhost
此時能夠正常登陸了!
?? ssh安裝無誤后,有興趣的朋友可以嘗試一下登陸其他電腦玩玩,比如我用kali登陸另一臺虛擬機或者是我的Win10嘗試登陸kali虛擬機:
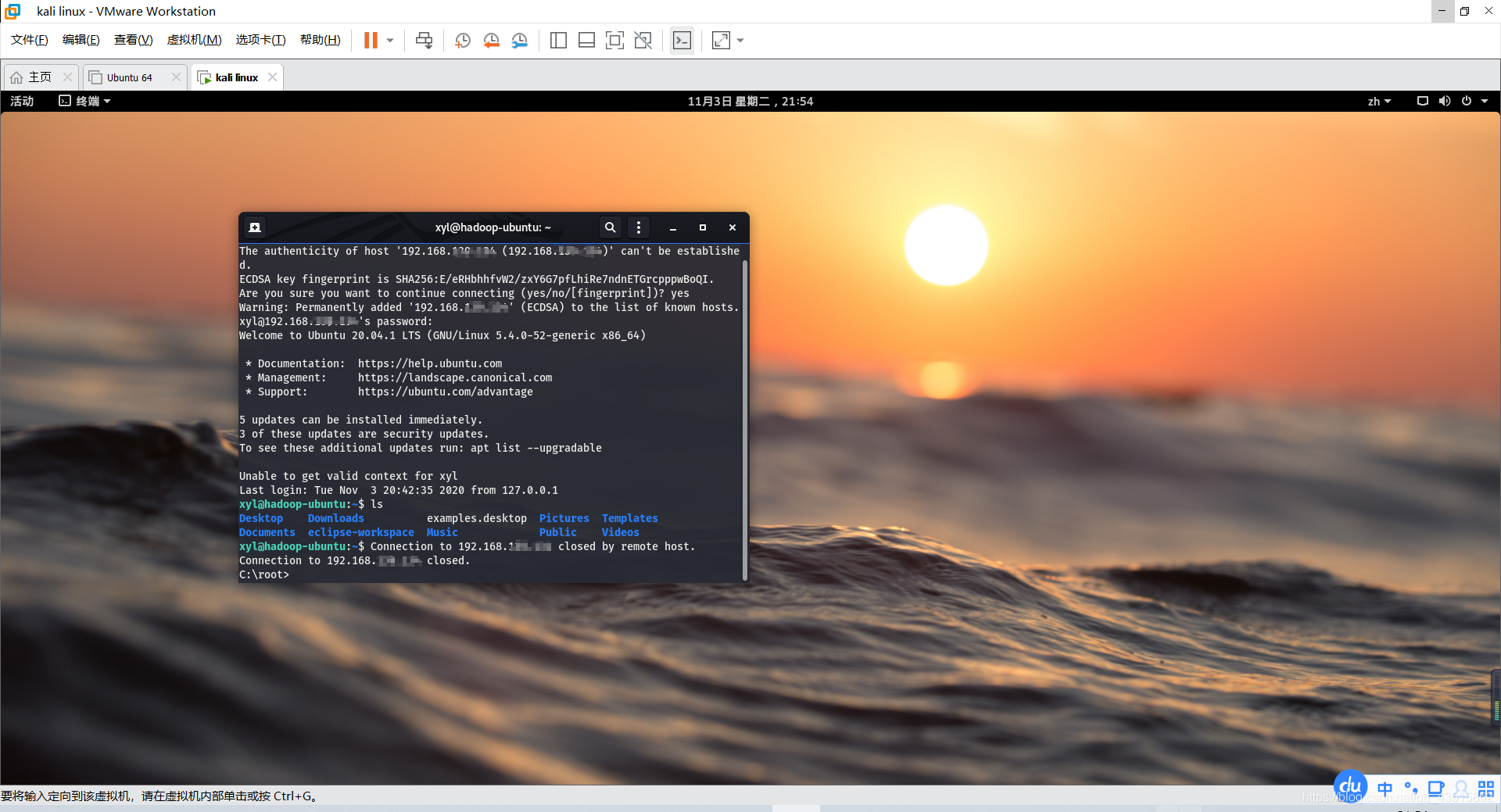
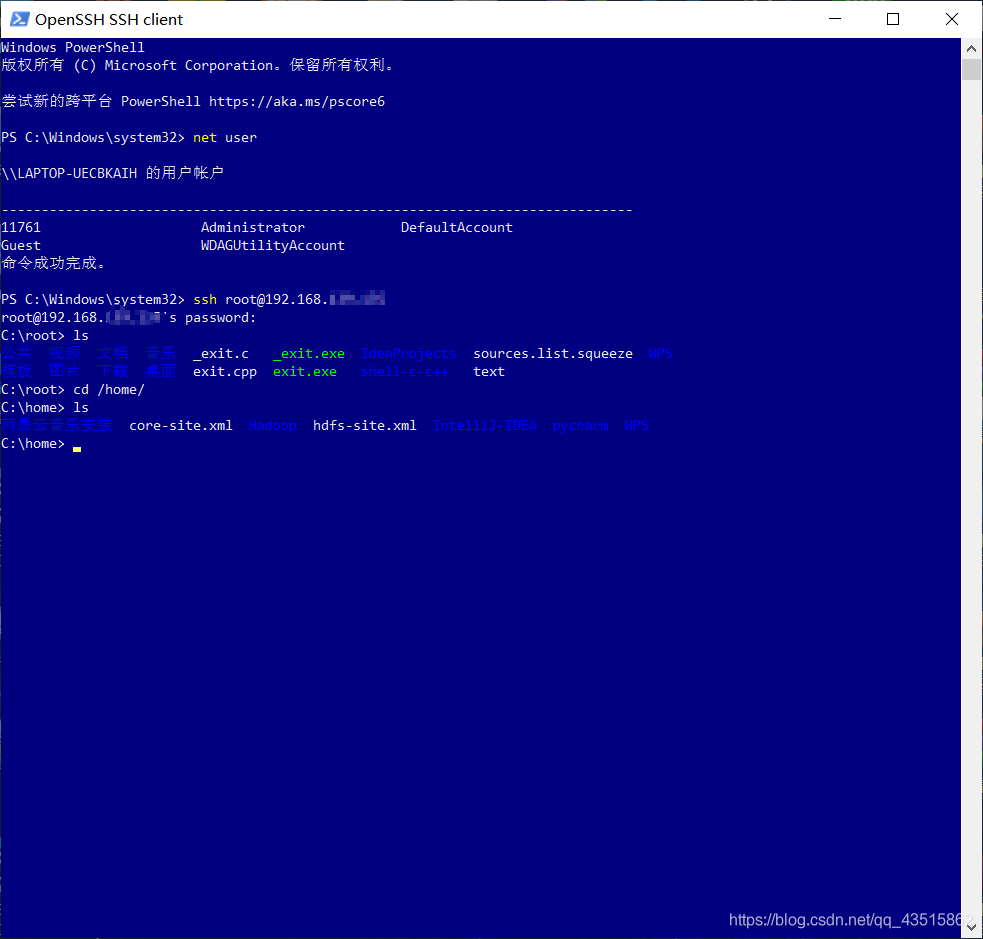
ssh遠程登陸:
ssh 用戶名@ip地址
從上圖可以看到,Linux在登錄成功之后,會有一些問候資訊 balabala,這些文字資訊是可以自定義的:
# vim /etc/motd
寫入你想要的問候文字,
重啟SSH:
# service ssh restart
??● 無密登陸設定:
??但是這樣每次登入均要輸入密碼,設成無密登陸更方便,
具體操作如下:
# exit # 先退出剛才的ssh localhost
# cd ~/.ssh/ # 若無該目錄,先執行一次ssh localhost創建
# ssh-keygen -t rsa # 全部回車即可
# cat ~/.ssh/id_rsa.pub >> ./authorized_keys # 加入授權
?? 命令 “ssh-keygen -t rsa” 會生成 公鑰和私鑰,默認在該目錄(~/.ssh/)生成id_rsa(私鑰)和id_rsa.pub(公鑰)倆檔案, 而 "cat ~/.ssh/id_rsa.pub >> ./authorized_keys" 命令則是將公鑰密碼匯入認證檔案 authorized_keys 中,
?? 最后,SSH授權完成,再次ssh localhost 則不再需要密碼了,也不再影響偽分布hadoop啟動,
?? 三、正式搭建hadoop ,偽分布安裝
① 安裝Hadoop:
??hadoop有著三種安裝模式,分別是:
??(1)單機模式;
??(2)偽分布模式;
??(3)分布模式,
??由于,博主時間緊張,這里就只給讀者介紹偽分布的安裝,也是本文的全篇側重點,
??首先,下載Hadoop
??(1)官網下載地址:Hadoop官方下載 可能下載速度會很慢
?? (2) 不過博主在這給讀者提供了自己的網盤下載:hadoop2.7和hadoop3.3百度網盤
??下載完成后便是安裝和配置了,
??● Hadoop安裝檔案并解壓:
??因為,我是實作在win10下載好后,移動到vmtools指定的共享檔案夾開始操作的,所以,博主的初始化目錄便是在/mnt/hgfs目錄下,當然你也可以用前文中提到的xftp或kali自帶火狐,
注意博主是在root賬號下開始搭建的!
??你可以創建一個新的用戶,或者跟著博主在root下安裝
先創建一個空的檔案夾,用來解壓hadoop,你可以創建在/opt路徑下,或者像博主一樣放在自己喜歡的路徑下,
# mkdir /home/Hadoop
解壓,-C 指定解壓路徑到創建的檔案夾路徑
# tar zxvf hadoop-3.3.0.tar.gz -C /home/Hadoop/
授權,具有讀寫檔案的權利,否則直接影響其他相關操作,必須要執行!!
# chown -R root /home/Hadoop/hadoop-3.3.0/
檢測Hadoop是否解壓安裝正確:
# cd /home/Hadoop/hadoop-3.3.0/
# ./bin/hadoop version
如出現如下則 恭喜你安裝無誤!!
Hadoop 3.3.0
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r aa96f1871bfd858f9bac59cf2a81ec470da649af
Compiled by brahma on 2020-07-06T18:44Z
Compiled with protoc 3.7.1
From source with checksum 5dc29b802d6ccd77b262ef9d04d19c4
否則,采用 rm -rf /home/Hadoop 命令洗掉掉,回到上一步,耐心的重來,
② 配置Hadoop環境變數:
??與java環境變數的配置類似,用編輯器打開.bashrc檔案保存修改后,執行source ~/.bashrc命令使其生效:
export HADOOP_HOME=/home/Hadoop/hadoop-3.3.0 # 注意,這里是你的hadoop解壓安裝路徑
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存并生效后,便可在任何路徑下使用hadoop命令了
??執行生效命令:
# source /root/.bashrc
??出現此前執行./bin/hadoop version命令時所出現的資訊,則證明環境變數修改無誤
# hadoop version
??一定要確定寫對后再執行生效,避免不必要的麻煩,如果有朋友操作不當,導致命令幾乎失效的話,請執行該命令恢復:
export PATH=/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/bin
??整個如上執行程序,請參考下圖:
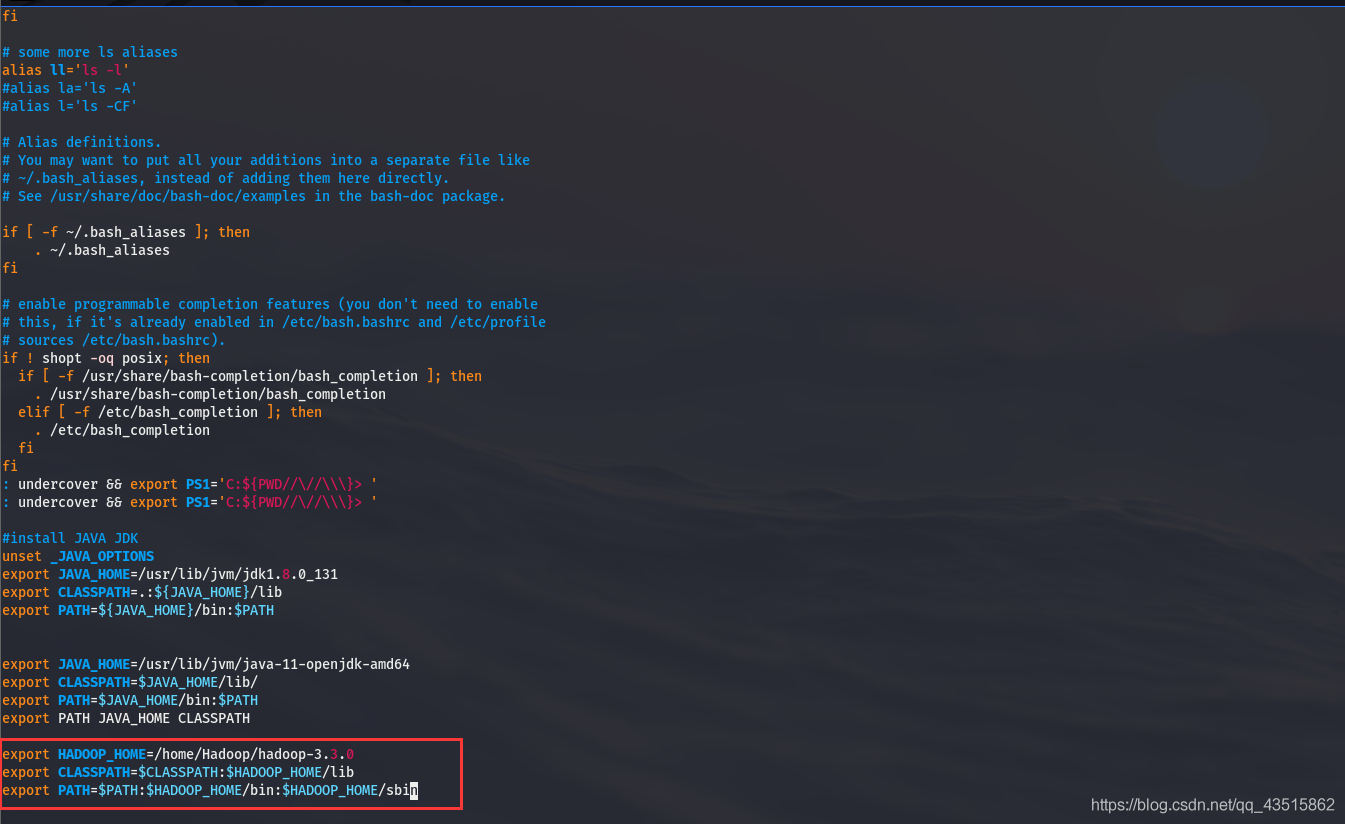
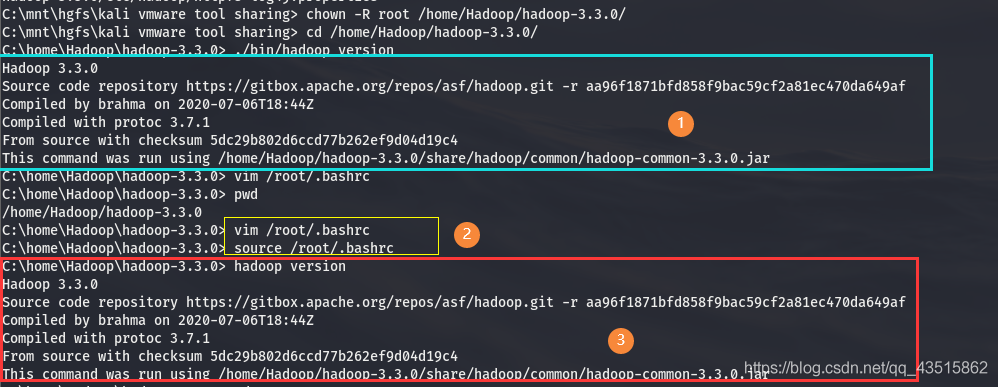
③ 偽分布模式配置:
?? 首先,得清楚概念,什么是hadoop的偽分布運行?
??Hadoop的偽分布運行是指,同一個節點既是名稱節點(Name Node),也是資料節點(Data Node),讀取分布式檔案系統HDFS的檔案,安裝不同模式Hadoop,就是修改其組態檔符合模式要求,
??Hadoop有倆組態檔,一個是core-site.xml檔案,另一個是hdfs-site.xml,其相對路徑是在 hadoop-3.3.0/etc/hadoop/ 下,
首先,修改core-site.xml組態檔
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml
修改添加的內容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/Hadoop/hadoop-3.3.0/tmp</value>
# 注意,這里的/home/Hadoop/hadoop-3.3.0是指你的hadoop安裝路徑
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
??詳解:
??引數fs.defaultFS為默認檔案系統名稱,其值為Hadoop的Name Node地址和埠號,如hdfs://localhost:9000,即表示Name Node是本機,埠9000是HDFS的RPC埠,是HDFS的默認埠,
??引數hadoop.tmp.dir用于確定Hadoop檔案系統的原資訊與資料保存在哪個目錄下,是Hadoop檔案系統依賴的基礎配置,很多路徑都依賴,如果hdfs-site.xml檔案中不配置Name Node和Data Node的存放位置,默認放在此路徑中,
??引數dfs.permissions的值如果是true則檢查權限,否則不檢查權限(每個人都可以存取檔案),該引數NameNode上設定,
如圖: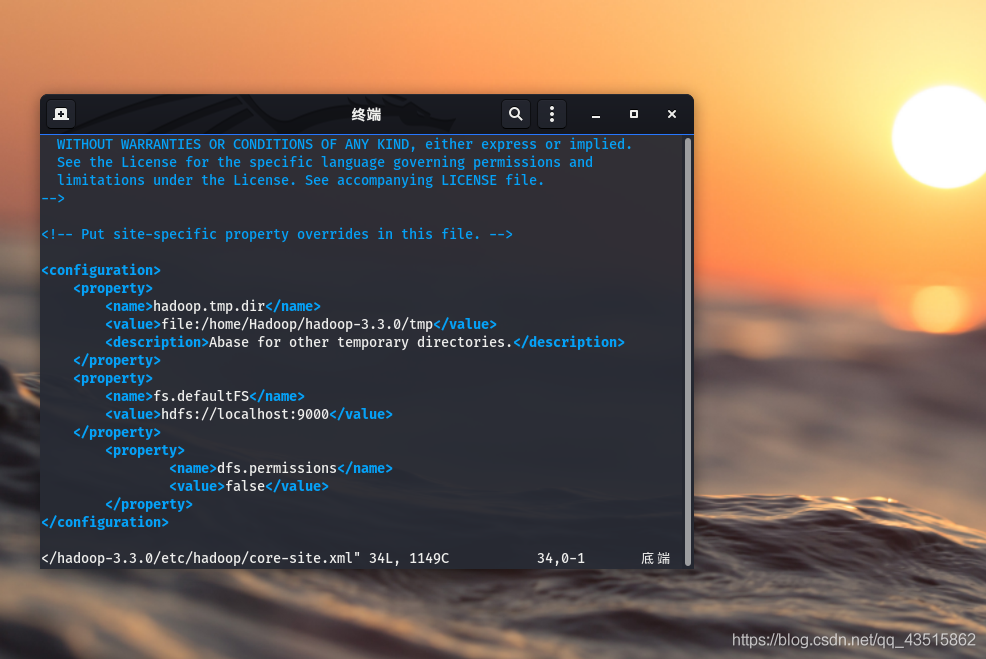
其次,修改hdfs-site.xml組態檔
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/hdfs-site.xml
修改添加的內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/Hadoop/hadoop-3.3.0/tmp/dfs/name</value>
# 注意,這里的/home/Hadoop/hadoop-3.3.0是指你的hadoop安裝路徑
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/Hadoop/hadoop-3.3.0/tmp/dfs/data</value>
# 注意,這里的/home/Hadoop/hadoop-3.3.0仍然是指你的hadoop安裝路徑
</property>
??詳解:
??引數dfs.replication指明設定hdfs副本數,因為是偽分布模式,所以設定為“1”,默認備份3個副本,
??引數dfs.namenode.name.dir 對應的value是存放名稱節點的路徑,引數dfs.datanode.data.dir 對應的value是存放資料節點的路徑,這倆路徑也可自行設定,但最好與臨時檔案路徑一致,在初期實驗時,遇到問題可以一并處理,
??Hadoop的運行方式是由組態檔決定的,因為運行Hadoop時會讀取組態檔,如果需要切換模式,只需要重新增加,洗掉或者修改core-site.xml和hdfs-site.xml檔案中的配置項,
④ Name Node的格式化:
??配置完成,執行Name Node的格式化:
# hdfs namenode -format # 由于,hadoop生效了環境變數,所以在任何路徑下均可執行,
??一定要注意,在前面的作業完成無誤之后再執行格式化,格式化只能一次,多次執行或許會出錯,
??出現"successfully formatted"和"Exiting with status 0"的字樣,則證明格式化成功!!祝賀你!
??否則,出現"Exiting with status 1"那么非常不幸!格式化出錯了,建議執行"rm -rf /home/Hadoop/hadoop3.3"命令刪掉hadoop,重新解壓安裝和配置吧!!
??除此之外,需要特別強調的一點是首次格式化不必洗掉dfs及其子檔案,此處引入我們課本:
??以及Java沒有配置正確后出現的報錯,也在上述圖中了,
⑤ 啟動和關閉Hadoop
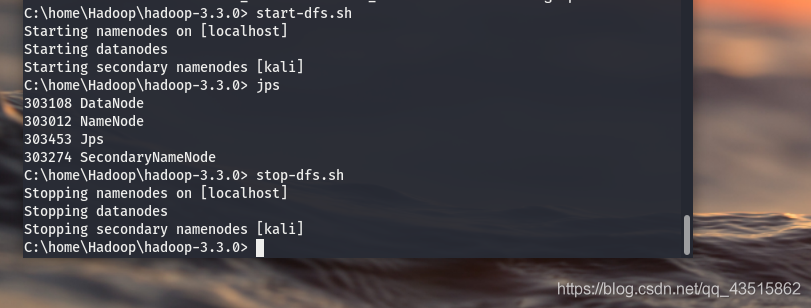
??1)start-dfs.sh
?? start-dfs.sh只啟動Name Node和Data Node,啟動命令如下:
# start-dfs.sh
??第一次啟動Hadoop會出現SSH提示:“Are you sure you want to continue connecting(yes/no)?”,輸入"yes"回車!
??成功開啟后會有如下資訊:
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
??啟動Hadoop成功后,可以通過jps查看行程:
C:\home\Hadoop\hadoop-3.3.0> jps
303108 DataNode
303012 NameNode
303453 Jps
303274 SecondaryNameNode
??關閉Hadoop的命令:
# stop-dfs.sh
??成功開啟后會有如下資訊:
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
??如上是正確的執行程序顯示!如果 沒有"SecondaryNameNode" ,需先運行stop-dfs.sh,再嘗試啟動,
??如果沒有Name Node或Data Node,就是配置不成功!
?? 請仔細檢查之前的操作,或者查看啟動日志排除來原因,或者刪掉hadoop重新解壓安裝和配置,的確是靠耐心,仔細認真的操作!
?? 如果到這里你執行的相當順利,那么博主對你表示祝賀 !!
從開啟到關閉的執行程序圖:
??當然也有像博主一樣,歷經坎坷的朋友(笑哭),遇到問題就想辦法解決吧,害,在瞎折騰中變禿也變強(手動滑稽 ing~,哈哈哈)
?? 或許有朋友會在開啟hadoop的時候就遇到如下報錯:
C:\home\Hadoop\hadoop-3.3.0> start-dfs.sh
Starting namenodes on [localhost]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [kali]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
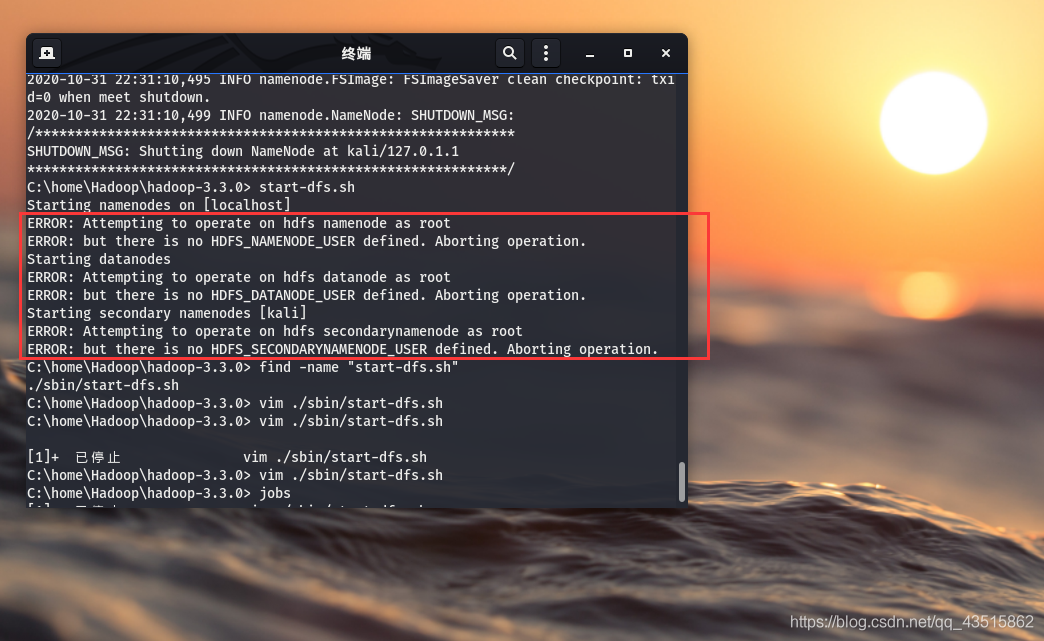
?? 解決方法如下:
??對hadoop的sbin下start-dfs.sh和stop-dfs.sh檔案均進行修改:
# vim /home/Hadoop/hadoop-3.3.0/sbin/start-dfs.sh
# vim /home/Hadoop/hadoop-3.3.0/sbin/stop-dfs.sh
倆檔案增添內容全部如下:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
注意添加位置是這兩行之后:
# See the License for the specific language governing permissions and
# limitations under the License.
??保存并退出vim,再次執行重啟:
# start-dfs.sh
??理論是不會有什么錯了,如果修改這倆檔案后,你又遇到和博主一樣新的報錯,博主也提供了新的解決方法:
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [localhost]
ERROR: JAVA_HOME is not set and could not be found.
Starting datanodes
ERROR: JAVA_HOME is not set and could not be found.
Starting secondary namenodes [kali]
ERROR: JAVA_HOME is not set and could not be found.
仍然是修改start-dfs.sh和stop-dfs.sh檔案這兩檔案,將之前的修改內容全部更改成:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
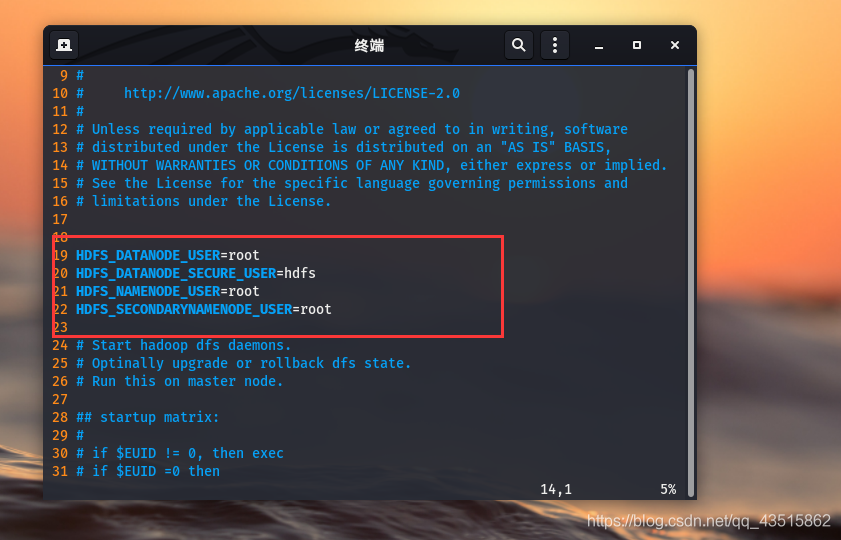
??而面對另外一個報錯,你可能會很懵逼,我明明是在之前添加了Java的環境變數啊,為什么還會報錯說:“java沒有設定并且也找不到”呢?
JAVA_HOME is not set and could not be found
??起初,我郁悶了會,而且又回過去查看了環境變數配置,琢磨過來又細想過去,環境變數是沒有問題的,后來曉得是得修改hadoop-env.sh來解決,
# vim /home/Hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
??在這個檔案中你會發現JAVA_HOME的確是沒有被添加的!
??解決方法:手動添加一個環境變數中的Java JDK 路徑,保存并退出即可解決,
如圖: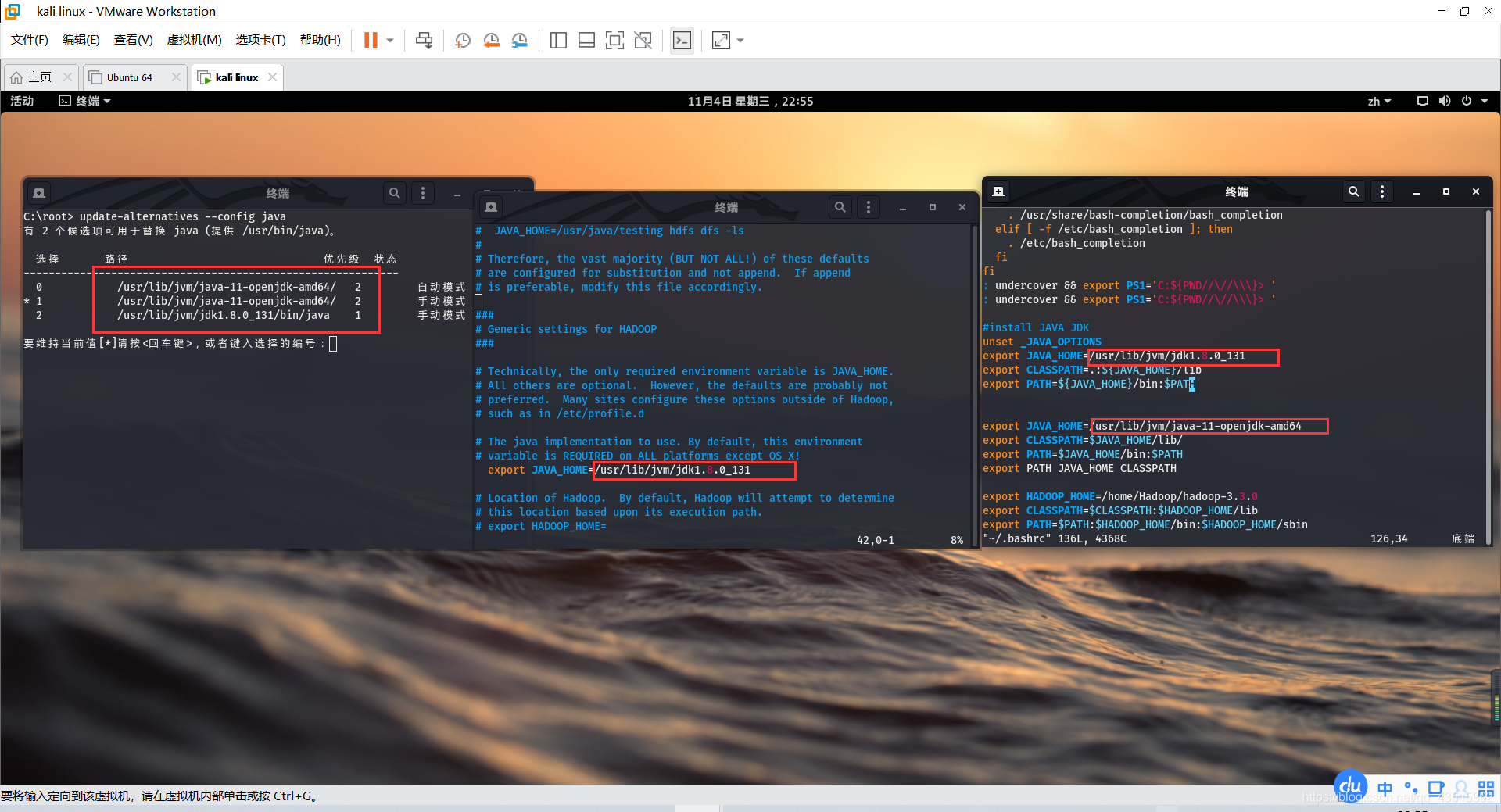
此處報錯全圖展覽:
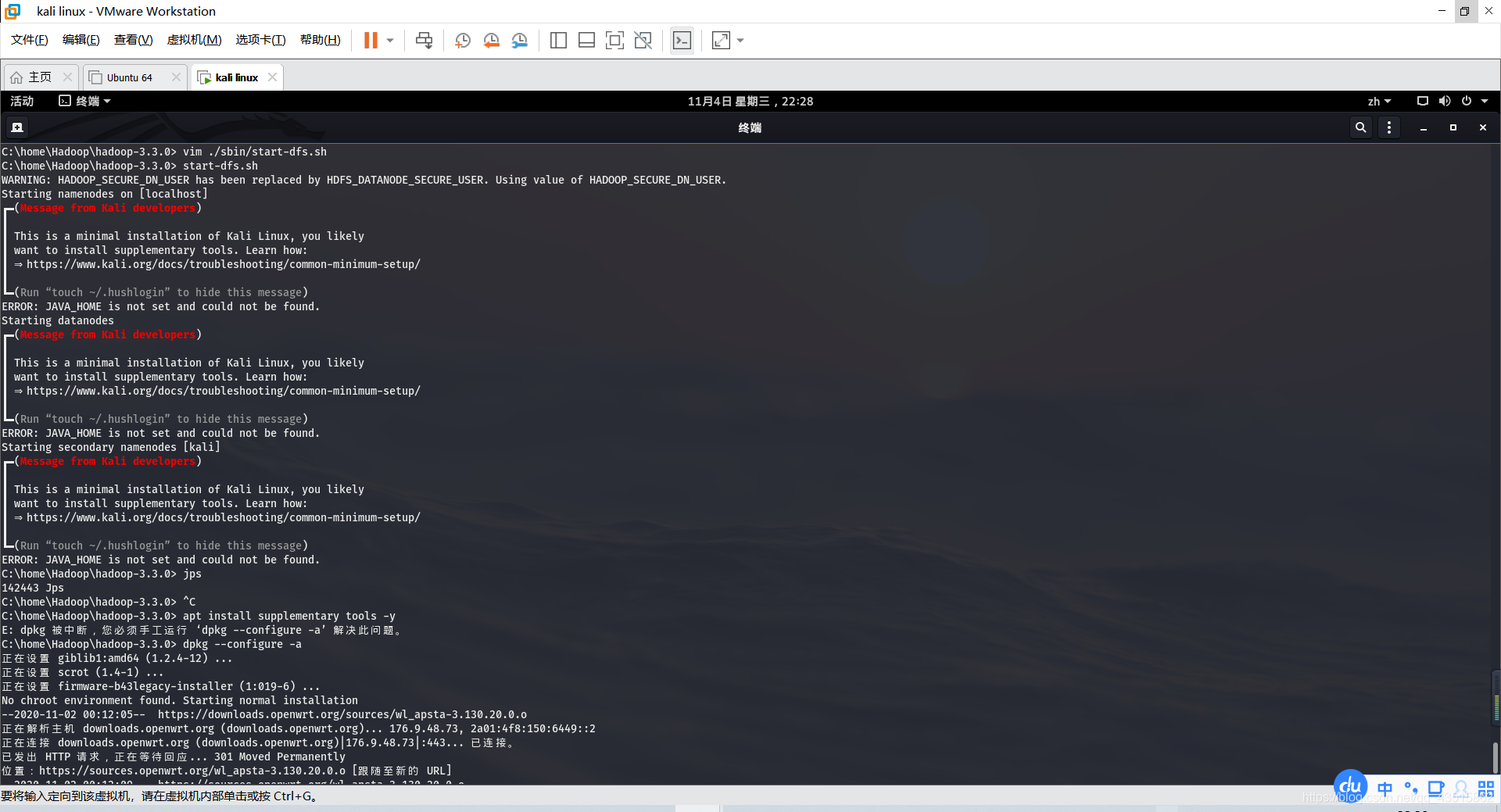
??再次嘗試啟動和關閉Hadoop和jps行程查看,查看是否正常:
C:\home\Hadoop\hadoop-3.3.0> start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
C:\home\Hadoop\hadoop-3.3.0> jps
147891 NameNode
148192 SecondaryNameNode
147985 DataNode
148287 Jps
C:\home\Hadoop\hadoop-3.3.0> stop-dfs.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
??恭喜你,基本完成了Hadoop的偽分布搭建 !
如果你還和博主一樣悲催,仍然殘留著小問題:
━(Message from Kali developers)
┃
┃ This is a minimal installation of Kali Linux, you likely
┃ want to install supplementary tools. Learn how:
┃ ? https://www.kali.org/docs/troubleshooting/common-minimum-setup/
┃
┗━(Run “touch ~/.hushlogin” to hide this message)
??別著急,博主也為你寫了解決方案:
報錯意思是說缺少了輔助工具,我們安裝即可:
# apt install supplementary tools -y # 記得更換國內源和保證kali linux網路的正常運營
如果中途又報錯提示:
E: dpkg 被中斷,您必須手工運行 ‘dpkg --configure -a’ 解決此問題,
那么就根據報錯的提示執行:
# dpkg --configure -a
等運行結束后,再執行該命令,隱藏提示即可:
# touch ~/.hushlogin
??2)start-all.sh
?? start-all.sh不僅啟動Name Node和Data Node,還啟動YARN的ResourceManager和NodeManger,啟動命令如下:
# start-all.sh
# jps # 查看全啟動的Hadoop行程
??關閉命令如下:
# stop-all.sh
??注意,養成好習慣,開啟不用時就關閉退出,避免其他錯誤的發生,
??當然,在這里博主又遇到了報錯,好悲催,不過熱心的博主也為你解決了,哈哈(笑哭):
報錯代碼如下:
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
Stopping resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
??我們只需要根據報錯在start-yarn.sh和stop-yarn.sh檔案的第二行中添加資訊即可:
# vim /home/Hadoop/hadoop-3.3/sbin/start-yarn.sh
# vim /home/Hadoop/hadoop-3.3/sbin/stop-yarn.sh
添加內容如下:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
如下圖:
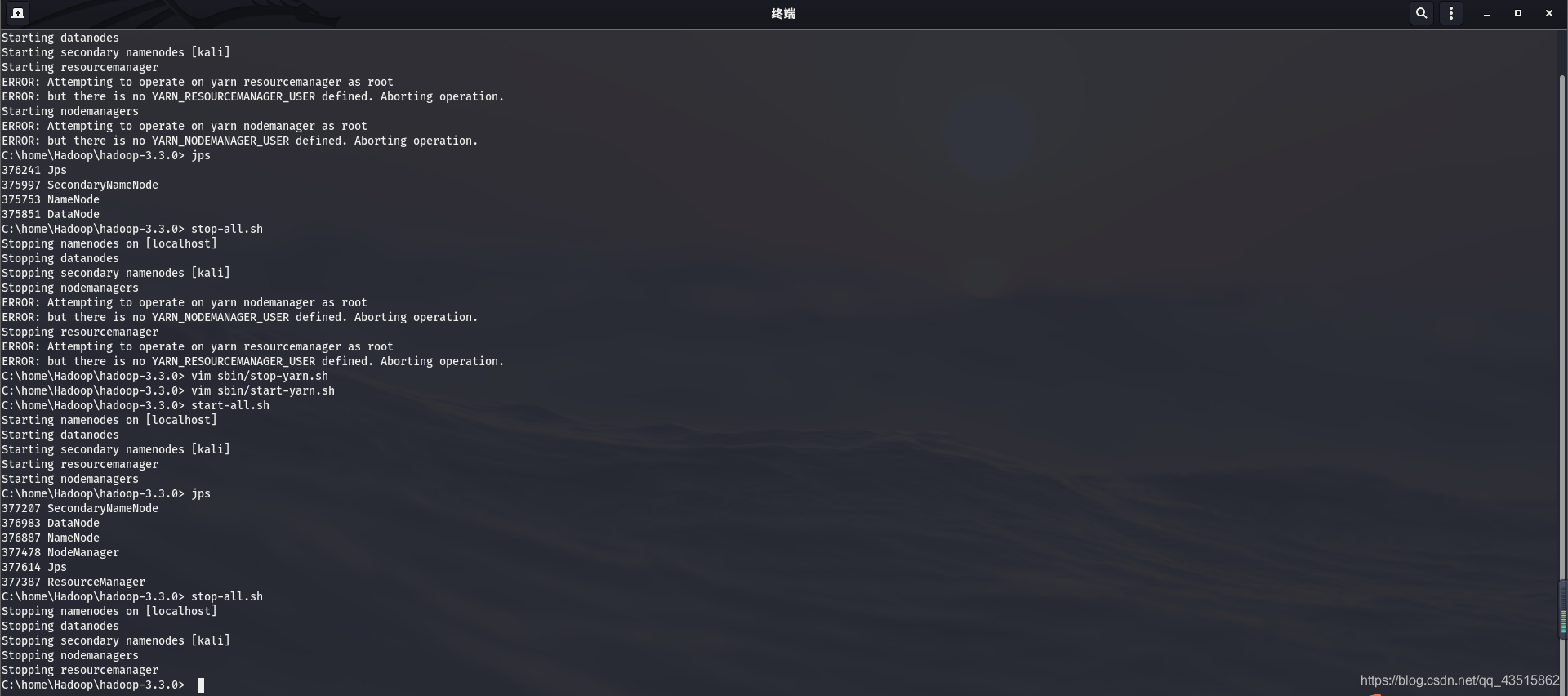
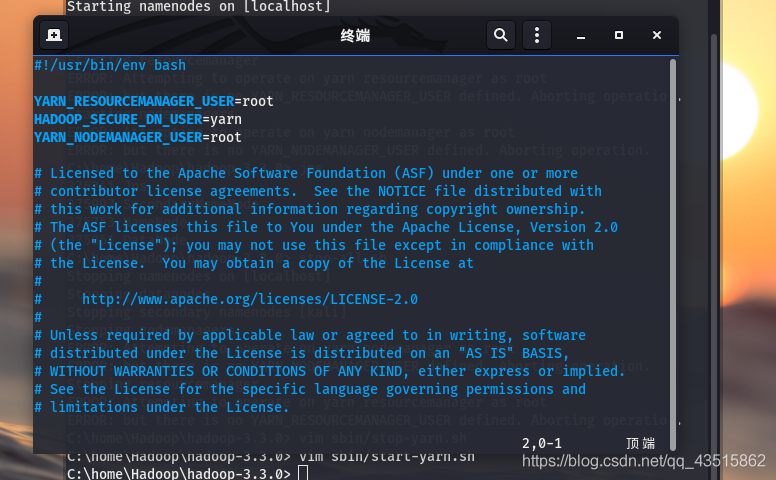
??最后,重啟關閉Hdoop和jps行程查看來檢驗:
C:\home\Hadoop\hadoop-3.3.0> start-all.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [kali]
Starting resourcemanager
Starting nodemanagers
C:\home\Hadoop\hadoop-3.3.0> jps
377207 SecondaryNameNode
376983 DataNode
376887 NameNode
377478 NodeManager
377614 Jps
377387 ResourceManager
C:\home\Hadoop\hadoop-3.3.0> stop-all.sh
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [kali]
Stopping nodemanagers
Stopping resourcemanager
C:\home\Hadoop\hadoop-3.3.0>
?? 完美!
??到這里,kali 搭建Hadoop偽分布就告一段落,能夠解決你的問題,博主非常的榮幸 !!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/205177.html
標籤:python