一. 格式化輸出
只需要把要列印的格式先準備好, 由于里面的 一些資訊是需要用戶輸入的,你沒辦法預設知道,因此可以先放置個占位符,再把字串里的占位符與外部的變數做個映射關系就好啦
name = input("Name:") age = input("Age:") job = input("Job:") hobbie = input("Hobbie:") info = ''' ------------ info of %s ----------- #這里的每個%s就是一個占位符,本行的代表 后面拓號里的 name Name : %s #代表 name Age : %s #代表 age job : %s #代表 job Hobbie: %s #代表 hobbie ------------- end ----------------- ''' %(name,name,age,job,hobbie) # 這行的 % 號就是 把前面的字串 與拓號 后面的 變數 關聯起來 print(info)
%s就是代表字串占位符,除此之外,還有%d,是數字占位符, 如果把上面的age后面的換成%d,就代表你必須只能輸入數字啦
input接收的所有輸入默認都是字串格式!
問題:現在有這么行代碼
msg = "我是%s,年齡%d,目前學習進度為80%"%('金鑫',18) print(msg)
這樣會報錯的,因為在格式化輸出里,你出現%默認為就是占位符的%,但是我想在上面一條陳述句中最后的80%就是表示80%而不是占位符,怎么辦?
msg = "我是%s,年齡%d,目前學習進度為80%%"%('金鑫',18) print(msg)
這樣就可以了,第一個%是對第二個%的轉譯,告訴Python解釋器這只是一個單純的%,而不是占位符,
二. 流程控制之--while回圈
2.1,基本回圈
while 條件: # 回圈體 # 如果條件為真,那么回圈體則執行 # 如果條件為假,那么回圈體不執行
2.2 演示生活中回圈聽歌
while True: print('癢') print('社會搖') print('喜洋洋') print('我要這鐵棒有何用')
2.3 如何終止回圈?
- 改變條件(根據上面的流程,只要改變條件,就會終止回圈),
- 關鍵字:break,
- 呼叫系統命令:quit(),exit() 后面會講到,不建議大家使用,
- 關鍵字:continue(終止本次回圈),
2.3.1 終止回圈的第一個方法:利用改變條件,終止回圈,給大家引入標志位的概念,
flag = True while flag: print('癢') print('社會搖') print('喜洋洋') flag = False print('我要這鐵棒有何用')
2.3.2 終止回圈的第二方法:break
break:很簡單,就是Python給大家提供的關鍵字,什么是關鍵字?就是python中具有一定特殊意義的單詞,比如if,str,int等,這些不能用作變數對吧?
那么break的用法是什么? 即:回圈中,只要遇到break馬上退出回圈,舉例說明:
flag = True print(111) while flag: print('癢') print('社會搖') print('喜洋洋') break print('我要這鐵棒有何用') print(222)
2.3.3 continue:continue 用于終止本次回圈,繼續下一次回圈,舉例說明:
flag = True print(111) while flag: print('癢') print('社會搖') print('喜洋洋') continue print('我要這鐵棒有何用') print(222)
2.4,while ... else ..
與其它語言else 一般只與if 搭配不同,在Python 中還有個while ...else 陳述句
while 后面的else 作用是指,當while 回圈正常執行完,中間沒有被break 中止的話,就會執行else后面的陳述句
1 count = 0 2 while count <= 5 : 3 count += 1 4 print("Loop",count) 5 6 else: 7 print("回圈正常執行完啦") 8 print("-----out of while loop ------")
輸出
1 Loop 1 2 Loop 2 3 Loop 3 4 Loop 4 5 Loop 5 6 Loop 6 7 回圈正常執行完啦 8 -----out of while loop ------
如果執行程序中被break啦,就不會執行else的陳述句啦
1 count = 0 2 while count <= 5 : 3 count += 1 4 if count == 3:break 5 print("Loop",count) 6 7 else: 8 print("回圈正常執行完啦") 9 print("-----out of while loop ------")
輸出
Loop 1 Loop 2 -----out of while loop ------
三. 基本運算子
運算子
計算機可以進行的運算有很多種,可不只加減乘除這么簡單,運算按種類可分為算數運算、比較運算、邏輯運算、賦值運算、成員運算、身份運算、位運算,今天我們暫只學習算數運算、比較運算、邏輯運算、賦值運算、成員運算
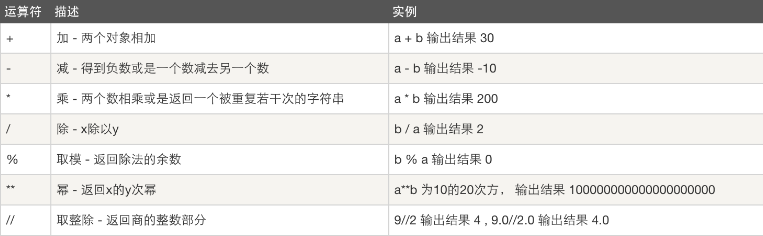
算數運算
以下假設變數:a=10,b=20
比較運算
以下假設變數:a=10,b=20

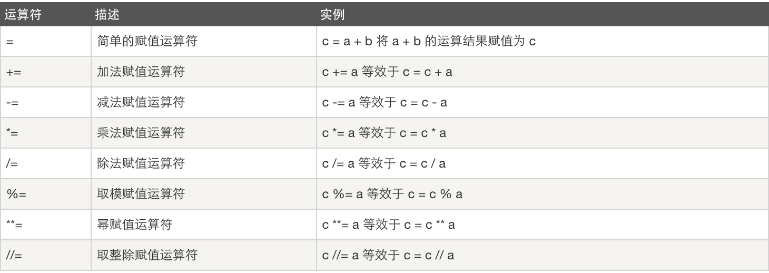
賦值運算
以下假設變數:a=10,b=20
邏輯運算

針對邏輯運算的進一步研究:
1,在沒有()的情況下not 優先級高于 and,and優先級高于or,即優先級關系為( )>not>and>or,同一優先級從左往右計算,
例題:
判斷下列邏輯陳述句的True,False,
1,3>4 or 4<3 and 1==1 2,1 < 2 and 3 < 4 or 1>2 3,2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 4,1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 5,1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 6,not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 , x or y , x為真,值就是x,x為假,值是y;
x and y, x為真,值是y,x為假,值是x,

例題:求出下列邏輯陳述句的值,
8 or 4 0 and 3 0 or 4 and 3 or 7 or 9 and 6
成員運算:
除了以上的一些運算子之外,Python還支持成員運算子,測驗實體中包含了一系列的成員,包括字串,串列或元組,

判斷子元素是否在原字串(字典,串列,集合)中:
例如:
1 #print('喜歡' in 'dkfljadklf喜歡hfjdkas') 2 #print('a' in 'bcvd') 3 #print('y' not in 'ofkjdslaf')
Python運算子優先級
以下表格列出了從最高到最低優先級的所有運算子:
| 運算子 | 描述 |
|---|---|
| ** | 指數 (最高優先級) |
| ~ + - | 按位翻轉, 一元加號和減號 (最后兩個的方法名為 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法減法 |
| >> << | 右移,左移運算子 |
| & | 位 'AND' |
| ^ | | 位運算子 |
| <= < > >= | 比較運算子 |
| <> == != | 等于運算子 |
| = %= /= //= -= += *= **= | 賦值運算子 |
| is is not | 身份運算子 |
| in not in | 成員運算子 |
| not and or | 邏輯運算子 |
四. 編碼的初識
計算機是需要存盤資料和通過網路傳輸資料的,計算機存盤在磁盤中的資料或者通過網路發送的資料本質發送的都是bit流也就是所謂的01010101101,那么這些010010是需要與咱們熟知的文字有標準的對應關系,這樣咱們才可以識別這些資料,
計算機起初使用的密碼本是:ASCII碼(American Standard Code for Information Interchange,美國標準資訊交換代碼)是基于拉丁字母的一套電腦編碼系統ASCII碼中只包含英文字母,數字以及特殊字符與二進制的對應關系,主要用于顯示現代英語和其他西歐語言,其最多只能用 8 位來表示(一個位元組),即:2**8 = 256,所以,ASCII碼最多只能表示 256 個符號,
ASCII碼:包含英文字母,數字,特殊字符與01010101對應關系,


在計算機中,所有的資料在存盤和運算時都要使用二進制數表示(因為計算機用高電平和低電平分別表示1和0),例如,像a、b、c、d這樣的52個字母(包括大寫)以及0、1等數字還有一些常用的符號(例如*、#、@等)在計算機中存盤時也要使用二進制數來表示,而具體用哪些二進制數字表示哪個符號,當然每個人都可以約定自己的一套(這就叫編碼),而大家如果要想互相通信而不造成混亂,那么大家就必須使用相同的編碼規則,于是美國有關的標準化組織就出臺了ASCII編碼,統一規定了上述常用符號用哪些二進制數來表示, 美國標準資訊交換代碼是由美國國家標準學會(American National Standard Institute , ANSI )制定的,標準的單位元組字符編碼方案,用于基于文本的資料,起始于50年代后期,在1967年定案,它最初是美國國家標準,供不同計算機在相互通信時用作共同遵守的西文字符編碼標準,它已被國際標準化組織(International Organization for Standardization, ISO)定為國際標準,稱為ISO 646標準,適用于所有拉丁文字字母,ASCII碼產生原因以及時間
下面是具體的ASCII碼:
| Bin(二進制) | Oct(八進制) | Dec(十進制) | Hex(十六進制) | 縮寫/字符 | 解釋 |
| 0000 0000 | 0 | 0 | 00 | NUL(null) | 空字符 |
| 0000 0001 | 1 | 1 | 01 | SOH(start of headline) | 標題開始 |
| 0000 0010 | 2 | 2 | 02 | STX (start of text) | 正文開始 |
| 0000 0011 | 3 | 3 | 03 | ETX (end of text) | 正文結束 |
| 0000 0100 | 4 | 4 | 04 | EOT (end of transmission) | 傳輸結束 |
| 0000 0101 | 5 | 5 | 05 | ENQ (enquiry) | 請求 |
| 0000 0110 | 6 | 6 | 06 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 7 | 7 | 07 | BEL (bell) | 響鈴 |
| 0000 1000 | 10 | 8 | 08 | BS (backspace) | 退格 |
| 0000 1001 | 11 | 9 | 09 | HT (horizontal tab) | 水平制表符 |
| 0000 1010 | 12 | 10 | 0A | LF (NL line feed, new line) | 換行鍵 |
| 0000 1011 | 13 | 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 0000 1100 | 14 | 12 | 0C | FF (NP form feed, new page) | 換頁鍵 |
| 0000 1101 | 15 | 13 | 0D | CR (carriage return) | 回車鍵 |
| 0000 1110 | 16 | 14 | 0E | SO (shift out) | 不用切換 |
| 0000 1111 | 17 | 15 | 0F | SI (shift in) | 啟用切換 |
| 0001 0000 | 20 | 16 | 10 | DLE (data link escape) | 資料鏈路轉義 |
| 0001 0001 | 21 | 17 | 11 | DC1 (device control 1) | 設備控制1 |
| 0001 0010 | 22 | 18 | 12 | DC2 (device control 2) | 設備控制2 |
| 0001 0011 | 23 | 19 | 13 | DC3 (device control 3) | 設備控制3 |
| 0001 0100 | 24 | 20 | 14 | DC4 (device control 4) | 設備控制4 |
| 0001 0101 | 25 | 21 | 15 | NAK (negative acknowledge) | 拒絕接收 |
| 0001 0110 | 26 | 22 | 16 | SYN (synchronous idle) | 同步空閑 |
| 0001 0111 | 27 | 23 | 17 | ETB (end of trans. block) | 結束傳輸塊 |
| 0001 1000 | 30 | 24 | 18 | CAN (cancel) | 取消 |
| 0001 1001 | 31 | 25 | 19 | EM (end of medium) | 媒介結束 |
| 0001 1010 | 32 | 26 | 1A | SUB (substitute) | 代替 |
| 0001 1011 | 33 | 27 | 1B | ESC (escape) | 換碼(溢位) |
| 0001 1100 | 34 | 28 | 1C | FS (file separator) | 檔案分隔符 |
| 0001 1101 | 35 | 29 | 1D | GS (group separator) | 分組符 |
| 0001 1110 | 36 | 30 | 1E | RS (record separator) | 記錄分隔符 |
| 0001 1111 | 37 | 31 | 1F | US (unit separator) | 單元分隔符 |
| 0010 0000 | 40 | 32 | 20 | (space) | 空格 |
| 0010 0001 | 41 | 33 | 21 | ! | 嘆號 |
| 0010 0010 | 42 | 34 | 22 | " | 雙引號 |
| 0010 0011 | 43 | 35 | 23 | # | 井號 |
| 0010 0100 | 44 | 36 | 24 | $ | 美元符 |
| 0010 0101 | 45 | 37 | 25 | % | 百分號 |
| 0010 0110 | 46 | 38 | 26 | & | 和號 |
| 0010 0111 | 47 | 39 | 27 | ' | 閉單引號 |
| 0010 1000 | 50 | 40 | 28 | ( | 開括號 |
| 0010 1001 | 51 | 41 | 29 | ) | 閉括號 |
| 0010 1010 | 52 | 42 | 2A | * | 星號 |
| 0010 1011 | 53 | 43 | 2B | + | 加號 |
| 0010 1100 | 54 | 44 | 2C | , | 逗號 |
| 0010 1101 | 55 | 45 | 2D | - | 減號/破折號 |
| 0010 1110 | 56 | 46 | 2E | . | 句號 |
| 00101111 | 57 | 47 | 2F | / | 斜杠 |
| 00110000 | 60 | 48 | 30 | 0 | 數字0 |
| 00110001 | 61 | 49 | 31 | 1 | 數字1 |
| 00110010 | 62 | 50 | 32 | 2 | 數字2 |
| 00110011 | 63 | 51 | 33 | 3 | 數字3 |
| 00110100 | 64 | 52 | 34 | 4 | 數字4 |
| 00110101 | 65 | 53 | 35 | 5 | 數字5 |
| 00110110 | 66 | 54 | 36 | 6 | 數字6 |
| 00110111 | 67 | 55 | 37 | 7 | 數字7 |
| 00111000 | 70 | 56 | 38 | 8 | 數字8 |
| 00111001 | 71 | 57 | 39 | 9 | 數字9 |
| 00111010 | 72 | 58 | 3A | : | 冒號 |
| 00111011 | 73 | 59 | 3B | ; | 分號 |
| 00111100 | 74 | 60 | 3C | < | 小于 |
| 00111101 | 75 | 61 | 3D | = | 等號 |
| 00111110 | 76 | 62 | 3E | > | 大于 |
| 00111111 | 77 | 63 | 3F | ? | 問號 |
| 01000000 | 100 | 64 | 40 | @ | 電子郵件符號 |
| 01000001 | 101 | 65 | 41 | A | 大寫字母A |
| 01000010 | 102 | 66 | 42 | B | 大寫字母B |
| 01000011 | 103 | 67 | 43 | C | 大寫字母C |
| 01000100 | 104 | 68 | 44 | D | 大寫字母D |
| 01000101 | 105 | 69 | 45 | E | 大寫字母E |
| 01000110 | 106 | 70 | 46 | F | 大寫字母F |
| 01000111 | 107 | 71 | 47 | G | 大寫字母G |
| 01001000 | 110 | 72 | 48 | H | 大寫字母H |
| 01001001 | 111 | 73 | 49 | I | 大寫字母I |
| 01001010 | 112 | 74 | 4A | J | 大寫字母J |
| 01001011 | 113 | 75 | 4B | K | 大寫字母K |
| 01001100 | 114 | 76 | 4C | L | 大寫字母L |
| 01001101 | 115 | 77 | 4D | M | 大寫字母M |
| 01001110 | 116 | 78 | 4E | N | 大寫字母N |
| 01001111 | 117 | 79 | 4F | O | 大寫字母O |
| 01010000 | 120 | 80 | 50 | P | 大寫字母P |
| 01010001 | 121 | 81 | 51 | Q | 大寫字母Q |
| 01010010 | 122 | 82 | 52 | R | 大寫字母R |
| 01010011 | 123 | 83 | 53 | S | 大寫字母S |
| 01010100 | 124 | 84 | 54 | T | 大寫字母T |
| 01010101 | 125 | 85 | 55 | U | 大寫字母U |
| 01010110 | 126 | 86 | 56 | V | 大寫字母V |
| 01010111 | 127 | 87 | 57 | W | 大寫字母W |
| 01011000 | 130 | 88 | 58 | X | 大寫字母X |
| 01011001 | 131 | 89 | 59 | Y | 大寫字母Y |
| 01011010 | 132 | 90 | 5A | Z | 大寫字母Z |
| 01011011 | 133 | 91 | 5B | [ | 開方括號 |
| 01011100 | 134 | 92 | 5C | \ | 反斜杠 |
| 01011101 | 135 | 93 | 5D | ] | 閉方括號 |
| 01011110 | 136 | 94 | 5E | ^ | 脫字符 |
| 01011111 | 137 | 95 | 5F | _ | 下劃線 |
| 01100000 | 140 | 96 | 60 | ` | 開單引號 |
| 01100001 | 141 | 97 | 61 | a | 小寫字母a |
| 01100010 | 142 | 98 | 62 | b | 小寫字母b |
| 01100011 | 143 | 99 | 63 | c | 小寫字母c |
| 01100100 | 144 | 100 | 64 | d | 小寫字母d |
| 01100101 | 145 | 101 | 65 | e | 小寫字母e |
| 01100110 | 146 | 102 | 66 | f | 小寫字母f |
| 01100111 | 147 | 103 | 67 | g | 小寫字母g |
| 01101000 | 150 | 104 | 68 | h | 小寫字母h |
| 01101001 | 151 | 105 | 69 | i | 小寫字母i |
| 01101010 | 152 | 106 | 6A | j | 小寫字母j |
| 01101011 | 153 | 107 | 6B | k | 小寫字母k |
| 01101100 | 154 | 108 | 6C | l | 小寫字母l |
| 01101101 | 155 | 109 | 6D | m | 小寫字母m |
| 01101110 | 156 | 110 | 6E | n | 小寫字母n |
| 01101111 | 157 | 111 | 6F | o | 小寫字母o |
| 01110000 | 160 | 112 | 70 | p | 小寫字母p |
| 01110001 | 161 | 113 | 71 | q | 小寫字母q |
| 01110010 | 162 | 114 | 72 | r | 小寫字母r |
| 01110011 | 163 | 115 | 73 | s | 小寫字母s |
| 01110100 | 164 | 116 | 74 | t | 小寫字母t |
| 01110101 | 165 | 117 | 75 | u | 小寫字母u |
| 01110110 | 166 | 118 | 76 | v | 小寫字母v |
| 01110111 | 167 | 119 | 77 | w | 小寫字母w |
| 01111000 | 170 | 120 | 78 | x | 小寫字母x |
| 01111001 | 171 | 121 | 79 | y | 小寫字母y |
| 01111010 | 172 | 122 | 7A | z | 小寫字母z |
| 01111011 | 173 | 123 | 7B | { | 開花括號 |
| 01111100 | 174 | 124 | 7C | | | 垂線 |
| 01111101 | 175 | 125 | 7D | } | 倍訓括號 |
| 01111110 | 176 | 126 | 7E | ~ | 波浪號 |
| 01111111 | 177 | 127 | 7F | DEL (delete) | 洗掉 |
隨著計算機的發展. 以及普及率的提高. 流?到歐洲和亞洲. 這時ASCII碼就不合適了. 比如: 中?漢字有幾萬個. 而ASCII 多也就256個位置. 所以ASCII不行了. 怎么辦呢? 這時, 不同的國家就提出了不同的編碼用來適用于各自的語言環境(每個國家都有每個國家的GBK,每個國家的GBK都只包含ASCII碼中內容以及本國自己的文字). 比如, 中國的GBK, GB2312, BIG5, ISO-8859-1等等. 這時各個國家都可以使用計算機了.
GBK:只包含本國文字(以及英文字母,數字,特殊字符)與0101010對應關系,
GBK全稱《漢字內碼擴展規范》(GBK即“國標”、“擴展”漢語拼音的第一個字母,英文名稱:Chinese Internal Code Specification) ,中華人民共和國全國資訊技術標準化技術委員會1995年12月1日制訂,國家技術監督局標準化司、電子工業部科技與質量監督司1995年12月15日聯合以技監標函1995 229號檔案的形式,將它確定為技術規范指導性檔案,這一版的GBK規范為1.0版, GBK 向下與 GB 2312 編碼兼容,向上支持 ISO 10646.1國際標準,是前者向后者過渡程序中的一個承上啟下的產物,ISO 10646 是國際標準化組織 ISO 公布的一個編碼標準,即 Universal Multilpe-Octet Coded Character Set(簡稱UCS),大陸譯為《通用多八位編碼字符集》,臺灣譯為《廣用多八位元編碼字元集》,它與 Unicode 組織的 Unicode 編碼完全兼容,ISO 10646.1 是該標準的第一部分《體系結構與基本多文種平面》,我國 1993 年以 GB 13000.1 國家標準的形式予以認可(即 GB 13000.1 等同于 ISO 10646.1), GBK編碼,是在GB2312-80標準基礎上的內碼擴展規范,使用了雙位元組編碼方案,其編碼范圍從8140至FEFE(剔除xx7F),共23940個碼位,共收錄了21003個漢字,完全兼容GB2312-80標準,支持國際標準ISO/IEC10646-1和國家標準GB13000-1中的全部中日韓漢字,并包含了BIG5編碼中的所有漢字,GBK編碼方案于1995年10月制定, 1995年12月正式發布,目前中文版的WIN95、WIN98、WINDOWS NT以及WINDOWS 2000、WINDOWS XP、WIN 7等都支持GBK編碼方案, 知識鏈接: 我們經常使用各種編碼標準的漢字,編碼到底是什么呢?所謂編碼,是以固定的順序排列字符,并以此做為記錄、存貯、傳遞、交換的統一內部特征,這個字符排列順序被稱為“編碼”,和中文字庫有關的編碼標準有:國標GB碼、GBK碼、港臺BIG-5碼等,不同編碼的漢字字庫都與漢字的應用有密切關系, 很多人在使用程序中,發現字不夠用,因為目前大家使用的主要是GB編碼字庫,此編碼標準只收錄了6763個常用漢字,而GB字庫以外大量漢字,只能通過方正女媧補字軟體拼字或其它造字程式補字,盡管補出的漢字在字形上滿足需要,但在字體風格、大小、結構方面難以協調統一,而采用手工貼圖的方式補字,更不雅觀,進而言之,如果用戶建立資訊系統,或需要查詢新聞、出版內容時,靠補字是無法實作的,方正開發的GBK字庫,將極大地緩解缺字現象, 從GB字庫擴充到GBK字庫,增加了1萬4千多字,北大方正從1996年投入大量人力,開始做黑、宋、仿、楷GBK字庫,并于1998年4月成為第一家通過國家權威部門組織的GBK字庫鑒定的專業廠商,到現在為止,北大方正已將全部字體轉換成GBK字庫,共46款,其中18款字數達21003個,是擁有GBK字庫款數最多的廠商, ISO 10646 是一個包括世界上各種語言的書面形式以及附加符號的編碼體系,其中的漢字部分稱為“CJK 統一漢字”(C 指中國,J 指日本,K 指朝鮮),而其中的中國部分,包括了源自中國大陸的 GB 2312、GB 12345、《現代漢語通用字表》等法定標準的漢字和符號,以及源自臺灣的 CNS 11643 標準中第 1、2 字面(基本等同于 BIG-5 編碼)、第 14 字面的漢字和符號,GBK的知識擴展
經實際測驗和查閱檔案,GBK是采用單雙位元組變長編碼,英文使用單位元組編碼,完全兼容ASCII字符編碼,中文部分采用雙位元組編碼,
對于ASCII碼中的內容,GBK完全沿用的ASCII碼,所以一個英文字母(數字,特殊字母)用一個位元組表示,而對于中文來說,一個中文用兩個位元組表示,
但是GBK只包含中文,不能包含其他文字,言外之意,GBK編碼是不能識別其他國家的文字的,舉個例子:如果你購買了一個日本的游戲盤,在用中國的計算機去玩,那么此時中國的計算機只有gbk編碼和ascii碼,那么你在玩游戲的程序中,只要出現日本字,那就會出錯或者出現亂碼.......
但是,隨著全球化的普及,由于網路的連通,以及互聯網產品的共用(不同國家的游戲,軟體,建立聯系等),各個國家都需要產生各種交集,此時急需一個密碼本:要包含全世界所有的文字與二進制0101010的對應關系,所以創建了萬國碼:
Unicode: 包含全世界所有的文字與二進制0101001的對應關系,
Unicode(統一碼、萬國碼、單一碼)是計算機科學領域里的一項業界標準,包括字符集、編碼方案等,Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一并且唯一的二進制編碼,以滿足跨語言、跨平臺進行文本轉換、處理的要求,1990年開始研發,1994年正式公布, 因為計算機只能處理數字,如果要處理文本,就必須先把文本轉換為數字才能處理,最早的計算機在設計時采用8個位元(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進制11111111=十進制255),0 - 255被用來表示大小寫英文字母、數字和一些符號,這個編碼表被稱為ASCII編碼,比如大寫字母A的編碼是65,小寫字母z的編碼是122, 如果要表示中文,顯然一個位元組是不夠的,至少需要兩個位元組,而且還不能和ASCII編碼沖突,所以,中國制定了GB2312編碼,用來把中文編進去, 類似的,日文和韓文等其他語言也有這個問題,為了統一所有文字的編碼,Unicode應運而生,Unicode把所有語言都統一到一套編碼里,這樣就不會再有亂碼問題了, Unicode通常用兩個位元組表示一個字符,原有的英文編碼從單位元組變成雙位元組,只需要把高位元組全部填為0就可以, 因為Python的誕生比Unicode標準發布的時間還要早,所以最早的Python只支持ASCII編碼,普通的字串'ABC'在Python內部都是ASCII編碼的, Unicode 是為了解決傳統的字符編碼方案的局限而產生的,例如ISO 8859所定義的字符雖然在不同的國家中廣泛地使用,可是在不同國家間卻經常出現不兼容的情況,很多傳統的編碼方式都有一個共同的問題,即容許電腦處理雙語環境(通常使用拉丁字母以及其本地語言),但卻無法同時支持多語言環境(指可同時處理多種語言混合的情況), Unicode 編碼包含了不同寫法的字,如“ɑ/a”、“戶/戶/戸”,然而在漢字方面引起了一字多形的認定爭議, 在文字處理方面,統一碼為每一個字符而非字形定義唯一的代碼(即一個整數),換句話說,統一碼以一種抽象的方式(即數字)來處理字符,并將視覺上的演繹作業(例如字體大小、外觀形狀、字體形態、文體等)留給其他軟體來處理,例如網頁瀏覽器或是文字處理器, 幾乎所有電腦系統都支持基本拉丁字母,并各自支持不同的其他編碼方式,Unicode為了和它們相互兼容,其首256字符保留給ISO 8859-1所定義的字符,使既有的西歐語系文字的轉換不需特別考量;并且把大量相同的字符重復編到不同的字符碼中去,使得舊有紛雜的編碼方式得以和Unicode編碼間互相直接轉換,而不會丟失任何資訊,舉例來說,全角格式區段包含了主要的拉丁字母的全角格式,在中文、日文、以及韓文字形當中,這些字符以全角的方式來呈現,而不以常見的半角形式顯示,這對豎排文字和等寬排列文字有重要作用, 在表示一個Unicode的字符時,通常會用“U+”然后緊接著一組十六進制的數字來表示這一個字符,在基本多文種平面(英文為 Basic Multilingual Plane,簡寫 BMP,它又簡稱為“零號平面”, plane 0)里的所有字符,要用四位十六進制數(例如U+4AE0,共支持六萬多個字符);在零號平面以外的字符則需要使用五位或六位十六進制數了,舊版的Unicode標準使用相近的標記方法,但卻有些微的差異:在Unicode 3.0里使用“U-”然后緊接著八位數,而“U+”則必須隨后緊接著四位數,Unicode的起源以及知識擴展
通用字符集:(Universal Character Set, UCS)是由ISO制定的ISO 10646(或稱ISO/IEC 10646)標準所定義的標準字符集,UCS-2用兩個位元組編碼,UCS-4用4個位元組編碼,
起初:Unicode規定一個字符用兩個位元組表示:
英文: a b c 六個位元組 一個英文2個位元組
中文 中國 四個位元組 一個中文用2個位元組
但是這種也不行,這種最多有65535種可能,可是中國文字有9萬多,所以改成一個字符用四個位元組表示:.
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
這樣雖然解決了問題,但是又引出一個新的問題就是原本a可以用1個位元組表示,卻必須用4個位元組,這樣非常浪費資源,所以對Uniocde進行升級,
UTF-8:包含全世界所有的文字與二進制0101001的對應關系(最少用8位一個位元組表示一個字符),


UTF-8(8-bit Unicode Transformation Format)是一種針對Unicode的可變長度字符編碼,又稱萬國碼,由Ken Thompson于1992年創建,現在已經標準化為RFC 3629,UTF-8用1到6個位元組編碼Unicode字符,用在網頁上可以統一頁面顯示中文簡體繁體及其它語言(如英文,日文,韓文),UTF-8的簡單介紹
UTF-8:是對Unicode編碼的壓縮和優化,他不再使用最少使用2個位元組,而是將所有的字符和符號進行分類:ascii碼中的內容用1個位元組保存、歐洲的字符用2個位元組保存,東亞的字符用3個位元組保存... UTF-16: 每個字符最少占16位. GBK: 每個字符占2個位元組, 16位.
UTF-8 :最少用8位數,去表示一個字符.
英文: 8位,1個位元組表示.
歐洲文字: 16位,兩個位元組表示一個字符.
中文,亞洲文字: 24位,三個位元組表示.

以上就是編碼的大致發展歷程,相信大家對編碼有了一定的了解,接下來普及一下單位之間的轉換:
8bit = 1byte 1024byte = 1KB 1024KB = 1MB 1024MB = 1GB 1024GB = 1TB 1024TB = 1PB 1024TB = 1EB 1024EB = 1ZB 1024ZB = 1YB 1024YB = 1NB 1024NB = 1DB 常?到TB就夠了
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/21000.html
標籤:Python